
原理+代码|深入浅出Python随机森林预测实战
回复“书籍”即可获赠Python从入门到进阶共10本电子书
前言
组合算法也叫集成学习,在金融行业或非图像识别领域,效果有时甚至比深度学习还要好。能够理解基本原理并将代码用于实际的业务案例是本文的目标,本文将详细介绍如何利用Python实现集成学习中随机森林这个经典的方法来预测宽带客户的流失,主要将分为两个部分:
详细原理介绍
Python代码实战
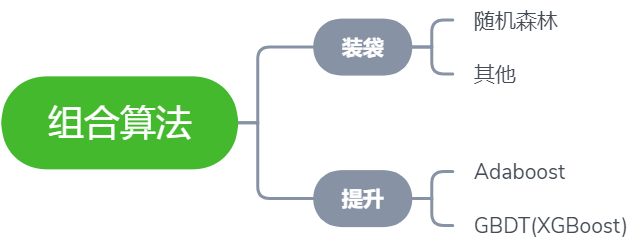
集成学习
本文的主角是随机森林,所以我们将以随机森林所属的分支 —— 装袋法 入手,深入浅出该集成学习方法的原理步骤。装袋法流程如下
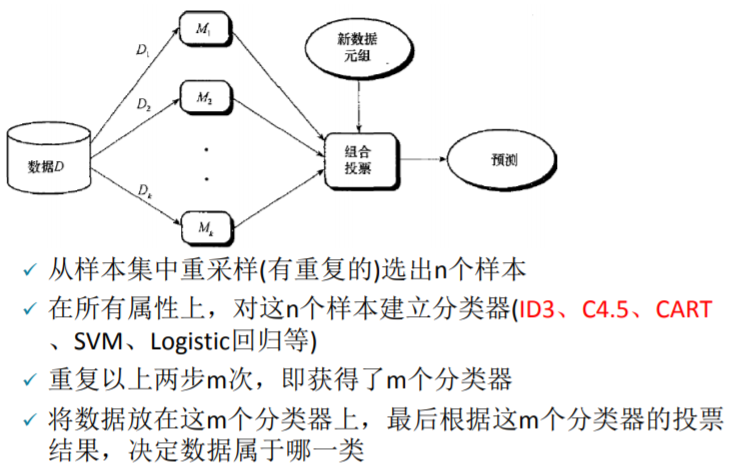
乍一看图中的步骤可能有些复杂,现在来逐步拆解。装袋法中的装袋二字是精髓,顾名思义即将多个模型装入同一个袋子后,让这个袋子作为一个新的模型来实现预测需求,仅此而已。换句话说,即把多个模型组合起来形成一个新的大模型,这个大模型最终给出的预测结果是由这多个小模型综合决定的,决定方式为少数服从多数。

假设有10万条原始数据,用这些数据来做十棵决策树(当然也可以是其他模型),最后这10棵树将被装进了同一个袋子中。这时候取其中一条数据放入这个袋子,便会得出10个预测值(每棵树各一个),假如其中三棵树给出的预测值为0,剩余的七棵给出的为1,那我们便可知道这个袋子对这个数据的预测结果为 0 的概率是 3/10。
为了更深入的理解装袋法,下面将回答三个与装袋法有关的常见问题:
问:袋子中的每个模型使用的样本量范围应为多少合适?
答:如果是上面的例子,袋子里面有十棵树,源数据总量为 10万 条,则每棵树取用的样本量的最小值为最少是1w个(10w/10棵 = 1w/棵),因为至少要保证不能浪费样本,但每棵树最多可取用多少样本呢?其实在样本量已知,同一袋子中模型个数为n的情况下,样本的选择比例为1/n ~ 0.8最好。每个小模型取用 100% 的样本是绝对没有意义的,那就跟没抽是一样的,这样也就没有体现出装袋,只有每个模型用到的数据都有一定的不同,组合起来后每个的投票(预测结果)也才有意义。
问:袋中模型们之间的相关性会影响最后的决策结果吗?
答:装袋法思路最重要的一点:袋子中每个模型之间不能相关,越不相关越好,这里的不相关主要体现在用于训练每个模型的样本不一样。其次,每个模型的精度越高越好,这样它的投票才更有价值。
PS:训练模型的样本不一样这一点可以理解为总统选举,抽 10 波选民来投票,这 10 波选民的差异性越大越好,这样一来,只有在选民千差万别的情况下你依然脱颖而出,才足以说明你的实力,如果这10波选民中每一波之间的差异性都很小,比如都是本来就偏袒于总统候选人,那投票结果的说服力就会大减。
问:上面所说的模型精度高是不是哪怕模型很复杂也可以,如果每个模型的精度高但都过度拟合怎么办?
答:在装袋法中,模型是越精确越好,哪怕是过度拟合的也没有关系。因为一个模型要想在训练集上做到越精确越好,而精确程度与模型的复杂度大多是成正比的,所以出现过拟合的情况也是正常且情有可原的。复杂和过度拟合只是对袋子中每个模型而言,因为最后都会被加权,所以整个袋子(整体)并不会出现过度拟合的情况。
随机森林
随机森林的实现步骤如下:
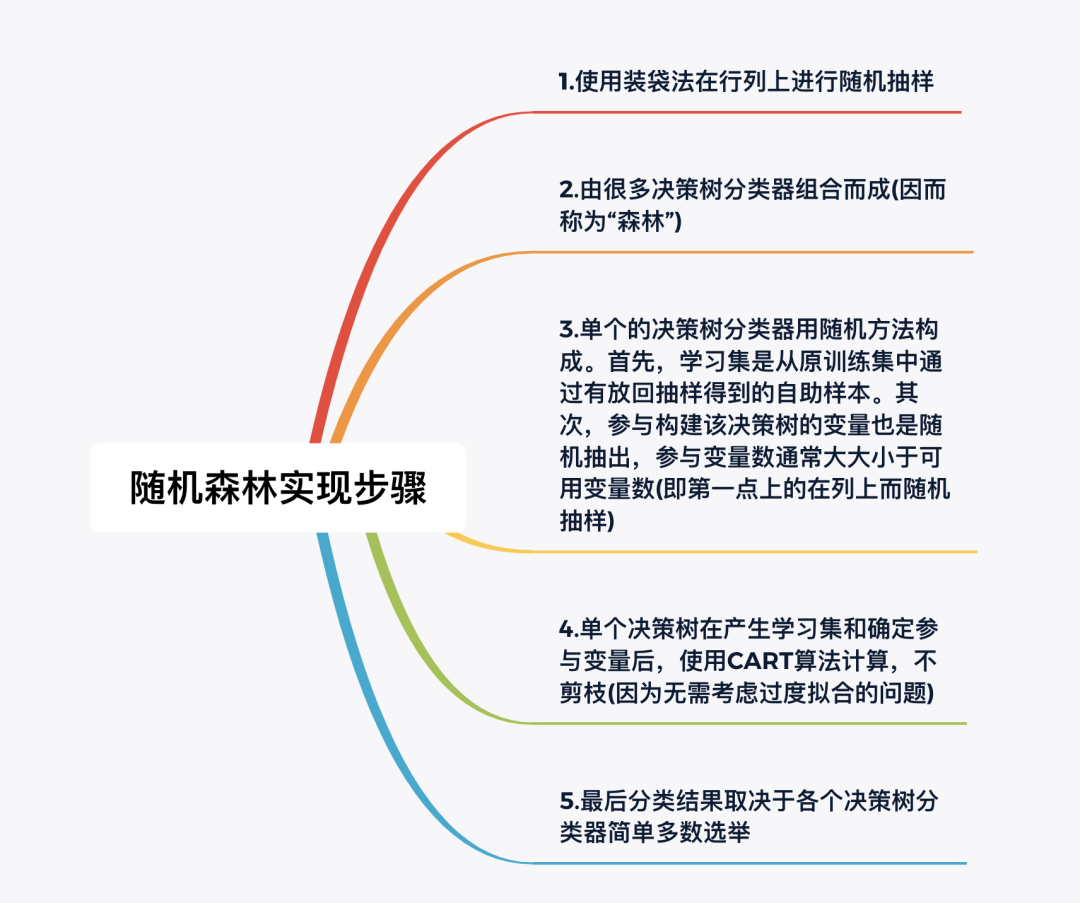
有关随机森林算法,本文说明以下几个问题
问:为什么在列上也要随机抽样?
答:在引入笔者最最喜欢的一个比喻之前,先来看一个实际的业务场景,来自某城市商业银行。我们有一大个电子表格存着大量的历史数据,大概50多个变量(50多列),变量们来自几个不同的公司如人行,电信等(同一个客户在不同公司),最后希望预测的是该客户是否会违约。电子表格组成如下:
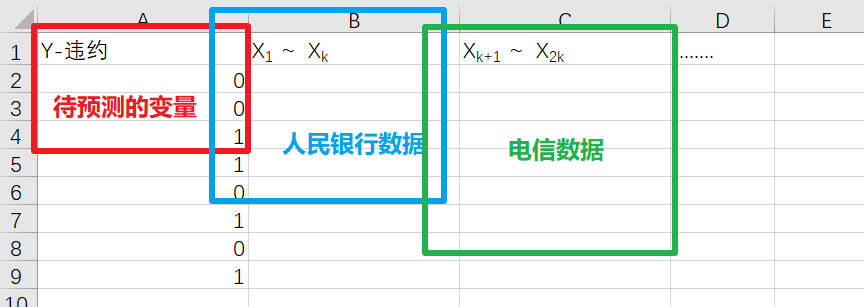
而根据基础的业务知识可知,与银行有关的数据中往往会存在许多缺失值,以上图为例,通常情况下只有待预测的变量这一列的数据是齐全的,毕竟客户们是否违约这个行为的历史数据很容易查找,但蓝框和绿框这两部分的缺失值往往较多,而且较随意,具体随意程度参见下图:
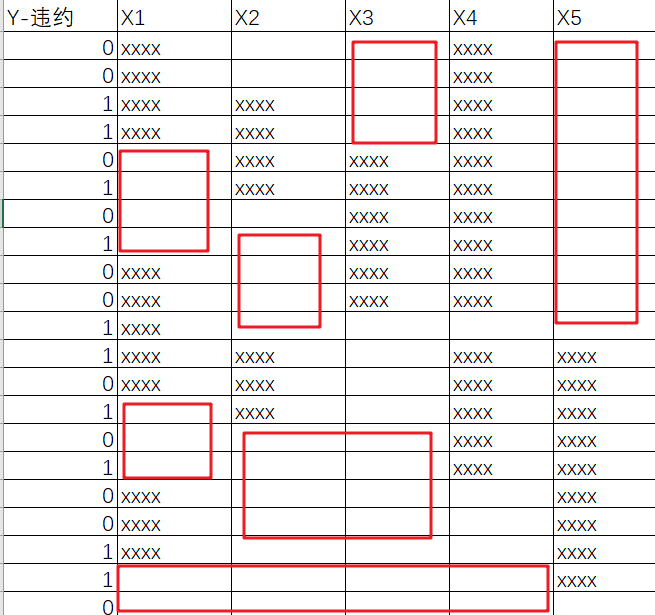
红框表示数据缺失,这里只展示了部分行和部分列数据,如果这份数据表的规模为 4万行 * 50列,那这数据缺失的分布得有多随意啊 ???所以,到底该如何充分利用这残次不齐的数据就成了呈待解决的关键问题。这时候就可以祭出超级生动形象的 “岛屿 - 湖泊 - 椰子树”比喻了:
整个表格看成一座巨大的岛屿,岛屿的长和宽分别对应电子表格横轴长和纵轴的长度
表中缺失的数据段看成一个个分布随意的小湖泊,有数据的地方看成陆地
整个小岛地底埋藏着巨大的价值(数据价值),通过在随意的种树(用装袋法在行列上进行随机抽样)来吸取地底的养分,毕竟湖泊上种不了树,所以只要足够随机,就总能充分的利用陆地。
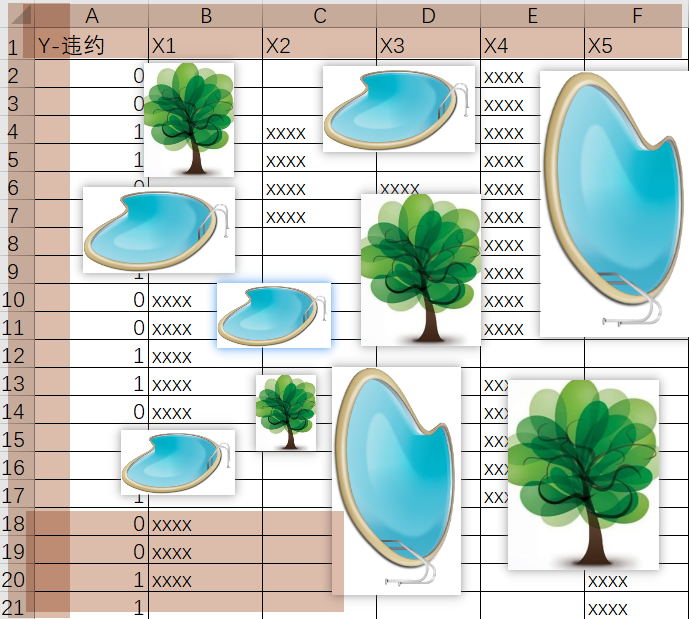
正因为是行列都随机,才能够做到真正的把整个数据表随机切分成多份,每个模型使用一份,只要模型的数量足够,总有模型能够在最大程度上获取数据集的价值。而且因变量的分类往往又是极不平衡的,可以参考原理+代码|手把手教你使用Python实战反欺诈模型。至于如何将这些种好的树的信息又再收集,便可以将陆地上比较近的几棵树上面再弄一个收集器,把这几棵树从陆地上收集到的养分再递进一层汇总,最终实现陆地养分汇总于树木,树木养分汇总于收集器,收集器养分汇总于更上层的另一个收集器,最终实现整片数据海洋中多个岛屿的信息汇总,这便是周志华团队和蚂蚁金服的合作的用分布式深度随机森林算法检测套现欺诈。
随机森林第一步之后的操作完全可以参照集成学习——装袋法中提及的步骤。
问:既然每个模型给出的预测结果最后都会被加权,所以随机森林中每棵决策树的权重是多少?
答:随机森林中每棵决策树的权重都是一样的,如果这个袋子中有 10 棵决策树(或者其他模型),那每棵树给出的预测结果的权重便是 1/10,这是随机森林的特性。如果权重不一样的话,便是后续推文会提及的Adaboost等集成学习中的提升分支了。
问:装袋法中袋子中的模型越多越好吗?袋中用来训练每个模型的源数据比例也是越多越好吗?
答:袋子中模型多一点好,袋中用来训练每个模型的源数据比例小一点好,但这并不代表越多越好与越小越好,还得结合数据集特性和一些深层次的模型算法知识。
装袋法的优势如下:
准确率明显高于组合中任何单个分类器
对于较大的噪音,表现不至于很差,并且具有鲁棒性
不容易过度拟合
随机森林算法的优点:
准确率有时可以和神经网络媳美,比逻辑回归高
对错误和离群点更加鲁棒性
决策树容易过度拟合的问题会随着森林的规模而削弱
大数据情况下速度快(分布式),性能好
Python实战
数据探索
本次实战目标为演示随机森林的用法和调优方法。因为集成学习与神经网络一样,都属于解释性较差的黑盒模型,所以我们无需过分探究数据集中每个变量的具体含义,只需关注最后一个变量broadband即可,争取通过如年龄,使用时长,支付情况以及流量和通话情况等变量对宽带客户是否会续费做出一个较准确的预测。
import pandas as pd
import numpy as np
df = pd.read_csv('broadband.csv') # 宽带客户数据
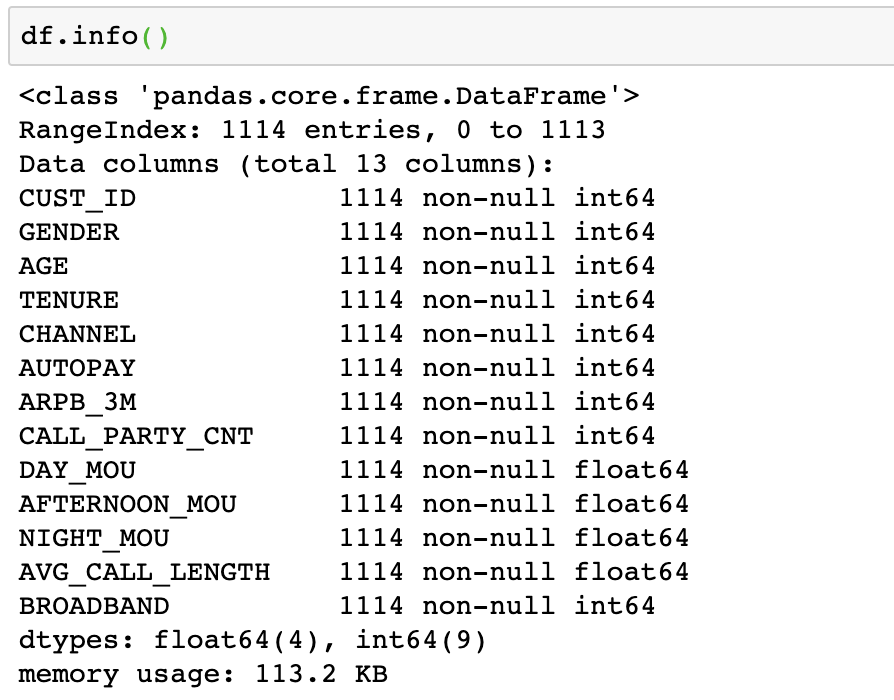
df.head(); df.info()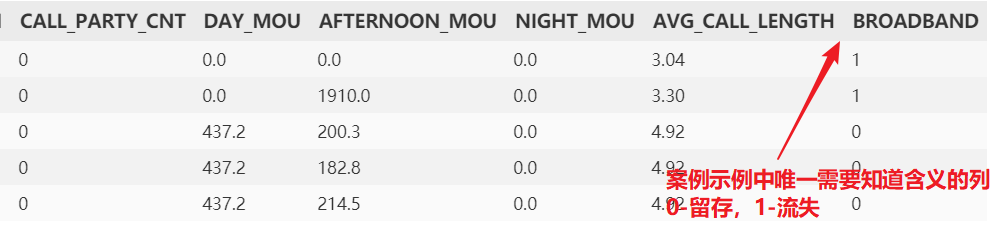
参数说明
本代码文件只为演示随机森林的用法和调优方法,所以数据参数我们只需关注最后一个broadband 即可0-离开,1-留存。其他自变量意思可不做探究,毕竟真实工作中的数据集也完全不一样,首先将列名全部小写
df.rename(str.lower, axis='columns', inplace=True)现在查看因变量broadband分布情况,看是否存在不平衡
from collections import Counter
print('Broadband: ', Counter(df['broadband']))
## Broadband: Counter({0: 908, 1: 206}) 比较不平衡。
## 根据原理部分,可知随机森林是处理数据不平衡问题的利器接着拆分测试集与训练集,客户id没有用,故丢弃cust_id,
y = df['broadband']
X = df.iloc[:, 1:-1]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.4, random_state=12345)决策树建模
我们先进行完整的决策树建模来和随机森林进行对比
import sklearn.tree as tree
# 直接使用交叉网格搜索来优化决策树模型,边训练边优化
from sklearn.model_selection import GridSearchCV
# 网格搜索的参数:正常决策树建模中的参数 - 评估指标,树的深度,
## 最小拆分的叶子样本数与树的深度
param_grid = {'criterion': ['entropy', 'gini'],
'max_depth': [2, 3, 4, 5, 6, 7, 8],
'min_samples_split': [4, 8, 12, 16, 20, 24, 28]}
# 通常来说,十几层的树已经是比较深了
clf = tree.DecisionTreeClassifier() # 定义一棵树
clfcv = GridSearchCV(estimator=clf, param_grid=param_grid,
scoring='roc_auc', cv=4)
# 传入模型,网格搜索的参数,评估指标,cv交叉验证的次数
## 这里也只是定义,还没有开始训练模型
clfcv.fit(X=X_train, y=y_train)
# 使用模型来对测试集进行预测
test_est = clfcv.predict(X_test)
# 模型评估
import sklearn.metrics as metrics
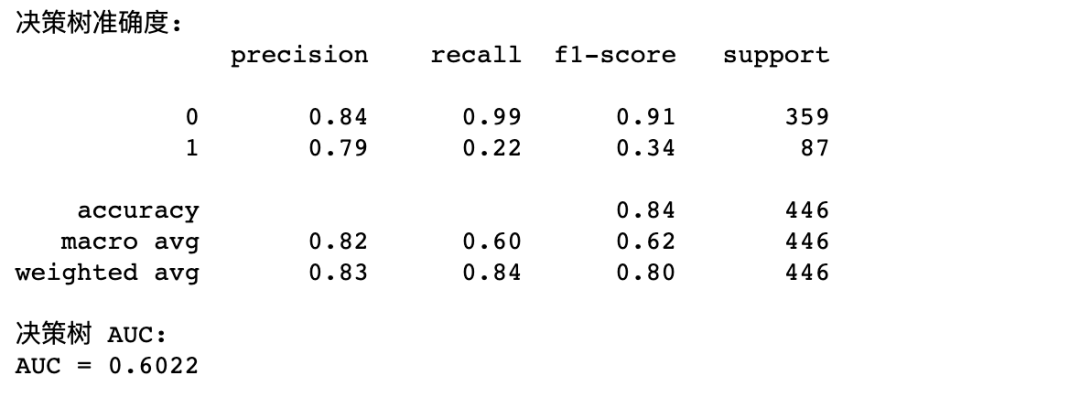
print("决策树准确度:")
print(metrics.classification_report(y_test,test_est))
# 该矩阵表格其实作用不大
print("决策树 AUC:")
fpr_test, tpr_test, th_test = metrics.roc_curve(y_test, test_est)
print('AUC = %.4f' %metrics.auc(fpr_test, tpr_test))
AUC 大于0.5是最基本的要求,可见模型精度还是比较糟糕的,决策树的调优技巧就不再过多展开,我们将在随机森林调优部分展示
随机森林建模
随机森林建模一样是使用网格搜索,有关Python实现随机森林建模的详细参数解释可以看代码的注释
param_grid = {
'criterion':['entropy','gini'],
'max_depth':[5, 6, 7, 8], # 深度:这里是森林中每棵决策树的深度
'n_estimators':[11,13,15], # 决策树个数-随机森林特有参数
'max_features':[0.3,0.4,0.5],
# 每棵决策树使用的变量占比-随机森林特有参数(结合原理)
'min_samples_split':[4,8,12,16] # 叶子的最小拆分样本量
}
import sklearn.ensemble as ensemble # ensemble learning: 集成学习
rfc = ensemble.RandomForestClassifier()
rfc_cv = GridSearchCV(estimator=rfc, param_grid=param_grid,
scoring='roc_auc', cv=4)
rfc_cv.fit(X_train, y_train)
# 使用随机森林对测试集进行预测
test_est = rfc_cv.predict(X_test)
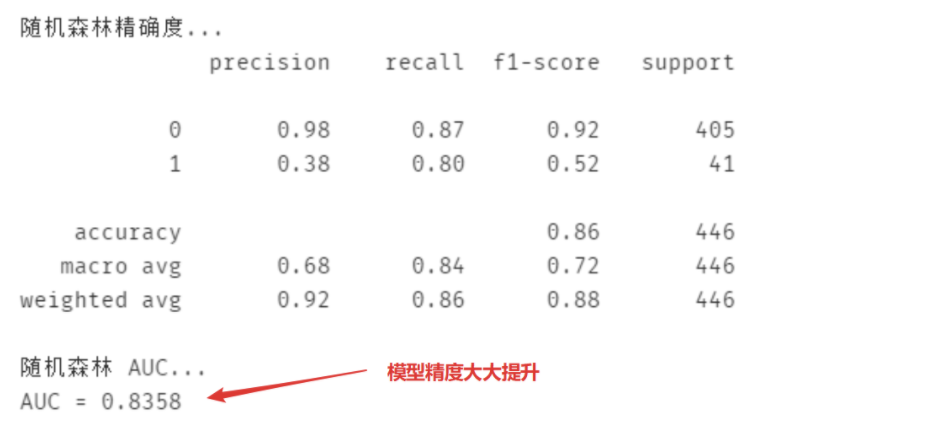
print('随机森林精确度...')
print(metrics.classification_report(test_est, y_test))
print('随机森林 AUC...')
fpr_test, tpr_test, th_test = metrics.roc_curve(test_est, y_test)
# 构造 roc 曲线
print('AUC = %.4f' %metrics.auc(fpr_test, tpr_test))可以看到,模型的精度大大提升
为什么要打印梯度优化给出的最佳参数?打印梯度优化结果的最佳参数的目的是为了判断这个分类模型的各种参数是否在决策边界上,简言之,我们不希望决策边界限制了这个模型的效果。(通常这时候会先把复杂度放一边)

不难发现,参数max_depth, min_samples_split, 和n_estimators 这三个参数的范围设置可能有限制模型精度的可能,所以需要适当调整
"""
{'criterion': 'gini',
'max_depth': 8, 在最大值边界上,所以这个参数的最大值范围应该再调大
'max_features': 0.5, 也在最大值边界上,说明这个参数的最小值范围应该再调大
'min_samples_split': 4, 同理,在最小边界上,可考虑把范围调小
'n_estimators': 15 同理,在最大边界上,可以适当调大范围
"""
# 调整结果
param_grid = {
'criterion':['entropy','gini'],
'max_depth':[7, 8, 10, 12],
# 前面的 5,6 也可以适当的去掉,反正已经没有用了
'n_estimators':[11, 13, 15, 17, 19], #决策树个数-随机森林特有参数
'max_features':[0.4, 0.5, 0.6, 0.7],
#每棵决策树使用的变量占比-随机森林特有参数
'min_samples_split':[2, 3, 4, 8, 12, 16] # 叶子的最小拆分样本量现在来查看再次建模的结果

此时都在决策边界内了,但其实调整参数是门技术活,并不只是通过决策边界这一单一指标来调整,后续推文会陆续更新。
小结
最后总结一下:随机森林是集成学习中非常经典的一种方法,基础原理简单,实现优雅,可即学即用。而且随机森林应用十分广泛,并不只是局限于常见的金融领域,只要数据不平衡或者随机缺失严重,都值得尝试。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~