
HyperPocket:生成点云网络
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


使用现代配准设备扫描真实场景通常会给出不完整的点云表示,这主要是由于扫描过程和3D遮挡的限制。因此,完成这样的部分表示仍然是许多计算机视觉应用的基本挑战。大多数现有的方法都是为了解决这个问题,通过学习在一个整洁的环境中重建单个3D对象的合成设置,这与现实生活中的场景相距甚远。在这项工作中,作者将点云的完成问题重新表述为物体幻觉任务。因此,作者引入了一种名为HyperPocket的基于自动编码器的新型架构,该架构可以解开潜在表示,从而能够生成已完成的3D点云的多个变体。作者将点云处理分成两个不相交的数据流,并利用超网络范式来填补缺失的对象部分留下的空间,即所谓的“口袋”。因此,生成的点云不仅是平滑的,而且是可信的和几何一致的场景。作者的方法提供了竞争性能的其他最先进的模型,并使大量的新应用。
作者的贡献总结如下:
作者将点云完成问题重新规划为物体幻觉任务,其灵感来自于人类如何将复杂的3D场景中被遮挡的物体分解成独立的物体,
作者介绍了一种基于超网络范式设计的自编码器的生成式超口袋架构,
作者的方法完成了一个真实的场景,对象遵循场景几何,同时适应现有环境的世代。
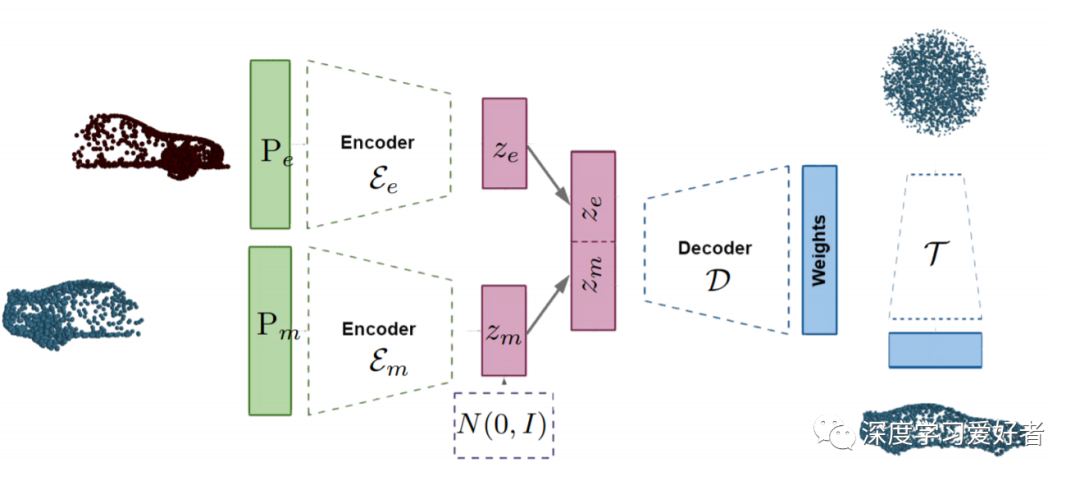
作者的HyperPocket模型使用两个编码器为对象的现有部分和缺失部分生成单独的潜在表示。通过在代表缺失部分(架构的底部部分)的潜在空间上强制使用高斯分布,作者可以产生不同的点云补全。然后,这两种表示被连接并通过一个解码器,输出一个目标网络的权值用于产生一个完整的3D对象。

HyperPocket模型在现实生活场景中的椅子重建。在第一栏中,作者呈现一个原始场景。在下一列中,作者可以看到各种可能的幻觉。
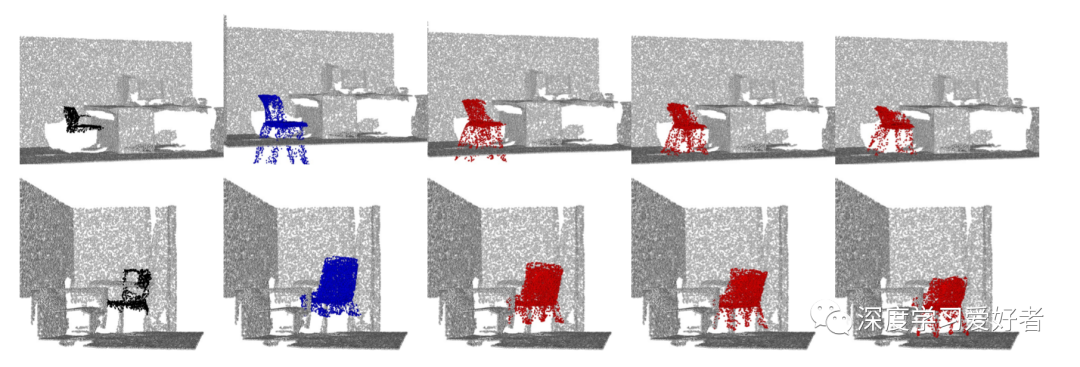
HyperPocket模型在场景中创建的椅子重建示例。第一列显示的场景与不完整的椅子(黑色)。第二列包含由HyperPocket模型创建的椅子的初始重建(蓝色)。接下来的三栏介绍了适应的过程。
本文对点云补全问题提出了新的看法,并考虑了点云补全问题在物体幻觉任务中的生成扩展。作者的目标是产生完成一个给定点云的多种可能性,而不是提供一个单一的重建。为了解决这一问题,作者提出了一种基于超网络范式设计的自编码器的生成式超口袋结构。这样的解决方案可以在一个场景中产生许多不同的、不可见的物体的幻觉输出,就像人类在分解包含遮挡物体的复杂场景时直观地做的那样。作者表明,作者的方法提供了竞争性能的最先进的方法,并可以成功地应用到现实世界的场景。
论文链接:https://arxiv.org/pdf/2102.05973.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~