
一种投影法的点云目标检测网络
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
文章导读
本文来源于早期的一篇基于投影法的三维目标检测文章《An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds》,网络结构简单清晰,由于将点云投影到图像空间借助了二维目标检测方法,所以在后期优化上可以参照二维目标检测的各种Tricks。
1
检测背景
三维目标检测网络从输入数据的形式上可以三类:
三维点云:PointNet,PointNet++等
体素空间:VoxelNet,Vovel-FPN等
投影空间:BirdNet,PIXOR,Complex-YOLO
本文是一篇将点云转换到投影空间做3D目标检测的文章,通常点云的投影形式有两种:
点云投影到鸟瞰图
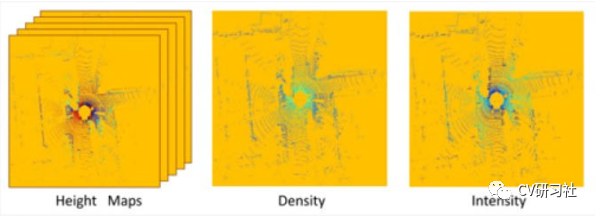
点云投影到前视图

将三维空间的数据投影到二维平面会造成信息的损失,所以在高度图的基础上,往往会添加强度信息、密度信息,深度信息等等。
2
核心思想
本文基于图像检测的YOLOv2版本,通过把3D点云降维到2D鸟瞰图的方式,将图像检测的网络用于点云的目标检测中。出于降维后信息的损失考虑,本文采用点云多种特征综合起来填充输入通道,以达到目标信息的弥补。
网络仍然以三通道作为输出,区别与图片中的RGB色系不同,这里先将三维点云进行栅格化,将点集分布到鸟瞰图空间的网格中,然后编码网格内点集的最大高度,最大强度,点云密度三种信息归一化后分别填充到R,G,B三个通道中形成RGB-Map,然后采用YOLOv2的Darknet19进行特征提取并回归出目标的相对中心点tx,ty ;相对宽高tw,tl ;复角tim,tre,以及类别p0...pn 。如下图所示:
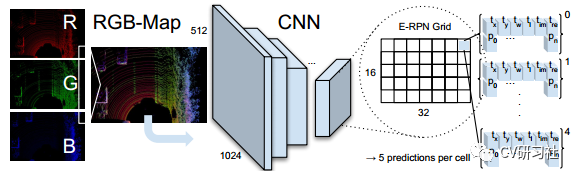
3
实现细节
点云预处理:本文将单帧三维点云转换成一张俯视的三通道图片,筛选出传感器正前方ROI区域(80米x 40米)高度限定3米以内,并将点云栅格化到网格分辨率为8cm的二维网格图中。
三通道分别由点云高度信息、点云强度信息、点云密度信息编码所得,编码方式如下:

其中Zg表示最大高度,Zb表示最大强度,Zr表示网格内归一化的密度,Sj每个网格内的点云映射函数,N表示每个网格中点的个数。
网络搭建:本文的网络结构在YOLOv2版本的基础上使用E-RPN进行扩展。基本同Darket-19,只是在最后的输出层增加了两个复数角度的回归。
特征提取采用darknet-19,如下图所示:

在单尺寸特征图上回归目标的类别、中心点、长宽、朝向角,网络特征图的解码输出如下:
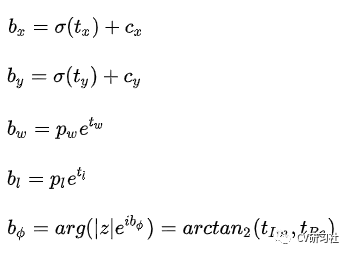
其中预测的中心点tx, ty通过sigmoid函数归一化到每个网格的相对位置,cx,cy为输出特征图上网格索引位置,预测的长宽tw,tl 通过对数函数表征的是相对于anchor长宽pw,pl的偏移,预测的复数实部和虚部通过反正切求得朝向角。
锚点设计考虑在鸟瞰图视角下,同一类目标的长宽尺寸变化不大,但是目标存在方向信息,所以在设计锚点的时候,根据数据集内的外接框分布,采用聚类的方式定义了三种不同尺寸和两个角度方向:
车辆尺寸(朝上)
车辆尺寸(朝下)
自行车尺寸(朝上)
自行车尺寸(朝下)
行人尺寸(朝左)
目标的朝向角可以通过相应的回归参数tim和tre计算得出,他们对应于复数的相位,角度只需使用arctan2即可求出。采用复数的方式主要考虑:
避免奇异性;
在一个封闭的数学空间,能对模型的推广产生有利影响;

损失函数:Complex-YOLO的损失函数在YOLOv2的基础上增加了欧拉角度回归损失:
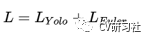
其中YOLOv2的损失如下,针对中心点和长宽分别采用L2对预测值和真实值求差的平方:

欧拉角的损失如下,针对角度的两个参数采用L2对预测值和真实值求差的平方:
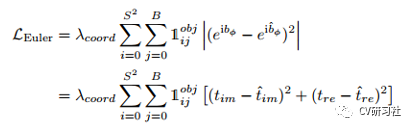
使用复数进行角度回归,总体上来说叠加的比较生硬,我们知道后面的版本将中心点和宽高放在一起保留bbox完整性然后计算IoU系列损失,如果能把旋转角也和bbox其他属性整合在一个定位损失中会更好。
3
要点分析
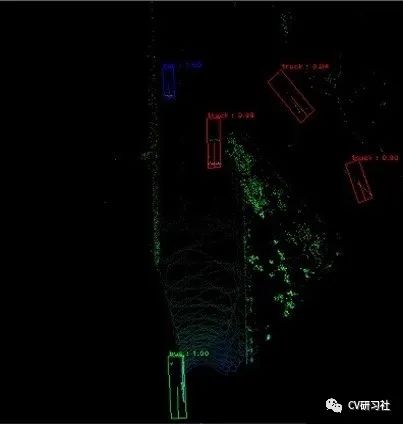
将图像检测网络YOLOv2应用到点云检测中,把三维点云转换成鸟瞰图的形式作为输入;
编码点云的高度,强度,密度信息到输入通道中;
在网络输出的位置信息,尺度信息,类别信息后增加了角度信息的输出;
采用复角的方式表征朝向角避免了单纯回归一个值所存在的奇异值问题(0°突变360°);
4
思考与展望
a. 点云检测网络在其预处理部分往往需要消耗大量时间,虽然基于投影的检测方法在网络前向传播的时效性比较好,但是对点云的预处理部分仍然拖累整体耗时。
b. 采用鸟瞰图形式的检测,由于点云近密远稀的特征,限制了其有效检测距离,所以本文只在40M以内的效果比较好。
c. 将俯视投影后,由于z方向上的特征压缩,对于行人等在x-y平面上占据分辨率较小的物体很难提取到丰富的特征进行检测任务,所以相比车辆,行人的检测精度较低。
基于上述几点问题,在延续投影法的大方向不变前提下,可以尝试进行以下优化:
Backbone,Neck,Head三块有很多好的选择;
Free anchor相比Fixed anchor对尺寸更加灵活;
引入ASPP,SPP等操作增大感受野;
引入注意力机制对稀疏目标关注其点云特征;
激活函数的优化,数据增广等等
基于工程的优化已经Tricks的叠加,该网络比较适合简单场景的嵌入式运行:
本文仅做学术分享,如有侵权,请联系删文。