
日志中台不重不丢实现浅谈
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
一 简述
1.1 中台定位
日志中台是针对打点数据的一站式服务,实现打点数据的全生命周期管理,只需简单开发就能快捷完成日志数据采集、传输、管理以及查询分析等功能,适用于产品运营分析、研发性能分析、运维管理等业务场景,帮助APP端、服务端等客户探索数据、挖掘价值、预见未来。
1.2 接入情况
日志中台已覆盖了厂内大多数重点产品,其中包括:百度APP全打点、小程序、矩阵APP等,接入方面收益如下:
接入情况:几乎覆盖了厂内已有APP,小程序,创新孵化APP,以及厂外收购APP 服务规模:日志条数 几千亿 条/天,高峰QPS 几百万/秒,服务稳定性 99.9995 %
1.3 名词解释
1.4 服务全景图
基础层:支持了APP-SDK、JS-SDK,性能SDK、通用SDK,满足各类打点需求的快速接入场景。依托大数据基础服务,将打点数据分发至各个应用方。 平台层:管理平台支持数据元信息管理、维护,并控制打点生命全周期环节。在线层面支持数据的实时、离线转发、并依托合理的流量控制、监控保证服务稳定性在99.995%。 业务能力:日志打点数据输出至数据中心、性能平台、策略中台、增长中台等,有效助力产品决策分析、端质量监控、策略增长等领域。 业务支持:覆盖重点APP、新孵化矩阵APP,横向通用组件方面。 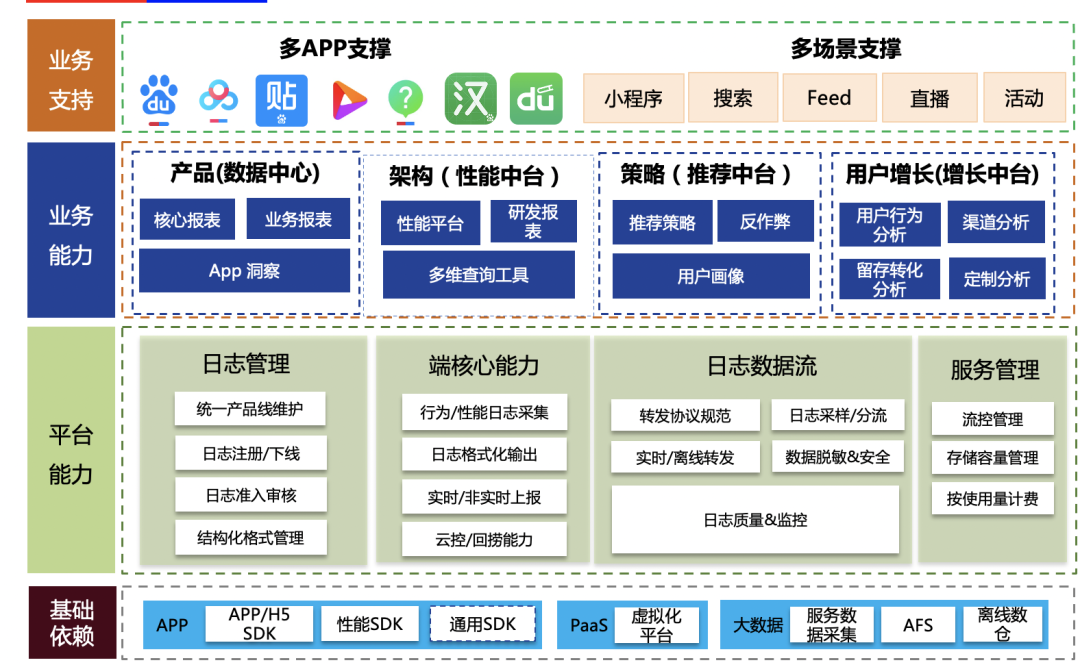
二、日志中台核心目标
不重:保证数据严格意义的不重复。需要防止系统层面的各种重试、架构异常恢复导致的数据重复问题; 不丢:保证数据严格意义的不丢失。需要防止系统层面的故障、代码层面bug等导致的数据丢失问题。
2.1 日志中台架构

数据应用方式不同,有以下集中类型: 实时 准实时流(消息队列):供下游数据分析使用,特点:较高(min)时效性,需要严格意义的数据准确。典型应用:研发平台、trace平台; 纯实时流(RPC代理):供下游策略应用,特点:秒级时效性,允许一定程度的数据丢失。典型应用:推荐架构。 离线:离线大表,所有日志全集,特点:天级/小时级时效性,需要严格意义的数据准确。 其他:需要一定时效性和准确率
2.2 面临的问题
巨型模块:打点server承载了所有的数据处理逻辑,功能耦合严重: 功能多:接入&持久化、业务逻辑处理、各种类型转发(rpc、消息队列、pb落盘); 扇出多:有10+个业务扇出流,通过打点server转发。 直接对接消息队列:从业务视角看,存在发送消息队列消息丢失风险,且无法满足业务不重不丢要求。 业务无等级划分: 核心业务与非核心业务架构部署耦合 相互迭代、相互影响
三、不重不丢实现
3.1 数据不丢的理论基础

3.1.1 唯2丢失数据理论
端:由于移动端的客观环境影响,如白屏、闪退、无法常驻进程、启动周期不确定等因素,导致客户端消息会存在一定概率丢失 接入层:由于服务器不可避免的存在故障(服务重启、服务器故障)的可能性,也存在一定的数据丢失概率 计算层:接入点之后,基于流式框架,建设需要严格意义的保证数据不重不丢。
3.1.2 日志中台架构优化方向
先持久化数据,后业务处理的原则 降低逻辑复杂度
实时流类:严格意义不丢失 高时效类:保证数据时效,允许可能存在的部分丢失 资源隔离:将不同业务的部署进行物理隔离,避免不同业务相互影响 区分优先级:按照业务对不同数据诉求,区分不同类型
3.2 架构拆解
3.2.1 打点server服务拆解(优化接入层数据丢失)
日志优先持久化:尽可能降低接入点因服务器故障等原因导致的数据丢失问题; 巨型服务拆解:接入点应该秉承简单、轻量的思路建设,避免过多业务属性导致的服务稳定性问题; 灵活&易用:在不重不丢的同时,基于业务需求特点,设计合理的流式计算架构。
3.2.1.1 日志优先持久化
持久化:接入层在真正业务处理之前,优先将数据持久化处理,“尽可能”先保证数据不丢失。 实时流:避免直接对接消息队列,优先采用落盘+minos转发消息队列方式,保证数据至多分钟级延迟的情况下,尽量不丢。
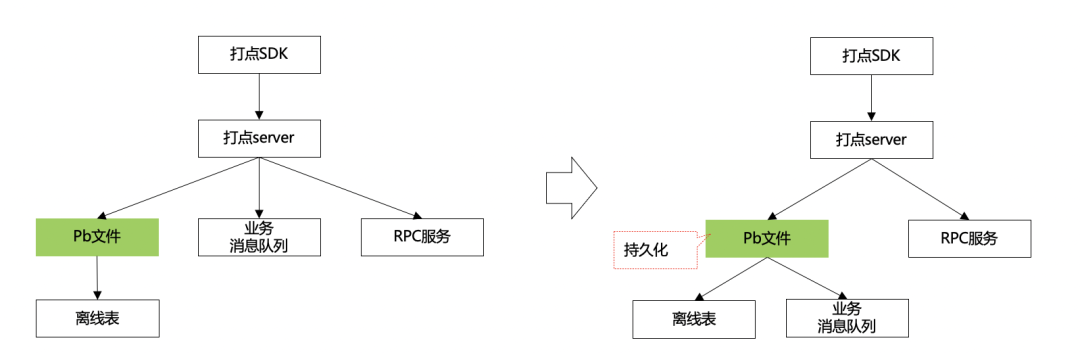
3.2.1.2 巨型服务拆解&功能下沉
实时流类业务:打点消息流转经过接入层→ 扇出层→ 业务层→ 业务。 接入层:功能单一,设计目标为数据尽可能不丢,保证数据第一时间持久化; 扇出层:保证下游灵活的订阅方式,进行数据拆分&重组(目前基于打点id维度扇出); 业务层:组合订阅扇出层数据,完成业务自有的需求实现,负责将打点数据生产并转发至下游; 高时效类业务: 策略实时推荐类的业务,单独抽离服务,支撑rpc类的数据转发,保证超高时效并保证数据转发SLA达到99.95%以上; 其他类业务: 数据监控、vip、灰度等业务,对时效、丢失率要求进一步降低,可将这部分业务抽离至单独服务; 技术选型:针对数据流式计算特点,我们选用了streamcompute架构,保证数据在经过接入层之后,全流程的“不重不丢”。
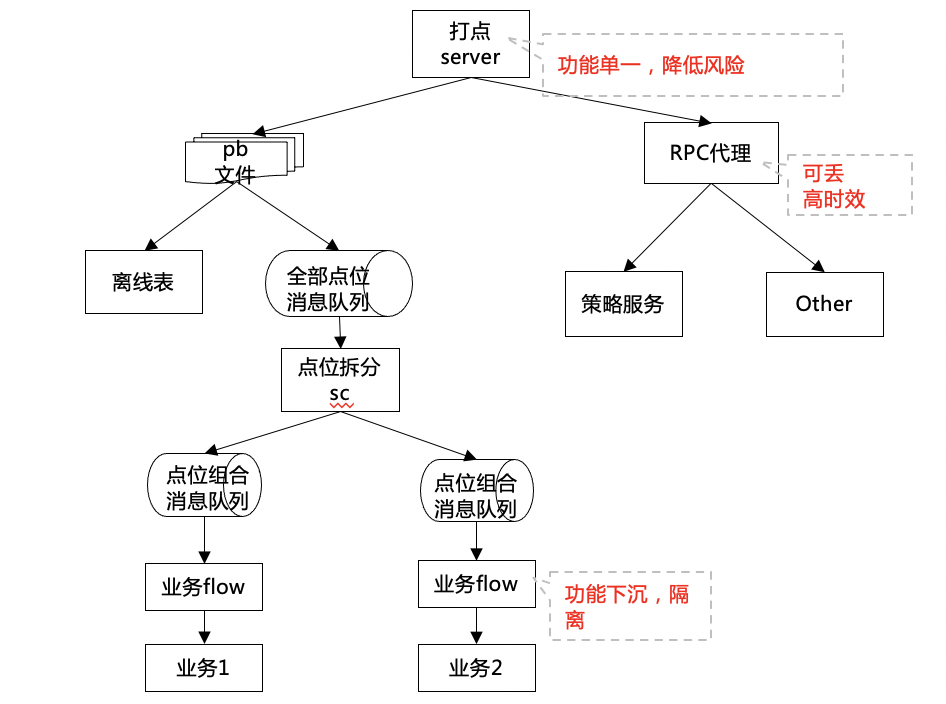
3.2.1.3 流式计算思考
打点server:将实时流通过消息队列,单独扇出至流式框架(分流flow入口) 分流flow:将不同点位信息,基于流量大小,进行拆分输出至不同消息队列。这样做的好处是兼顾了数据灵活扇出要求,下游可以灵活订阅; QPS小于某些阈值 or 横向点位等:单独消息队列输出,达到灵活扇出; QPS较小点位,进行聚合输出至聚合队列,以便节省资源; 业务flow:如果业务有自己的数据流式处理需求,可以单独部署作业,以便各个作业资源隔离。 输入:组合订阅分流flow的不同扇出数据,进行数据计算; 输出:数据混合计算后,输出至业务消息队列,业务方自行订阅处理; 业务filter:作为发送至业务层的终极算子,负责各个数据流在端到端层面。(打点server、端的系统重试数据)的不重。打点server将每一条打点数据生成唯一标识(类似一条数据md5),业务flow filter算子进行全局的去重。
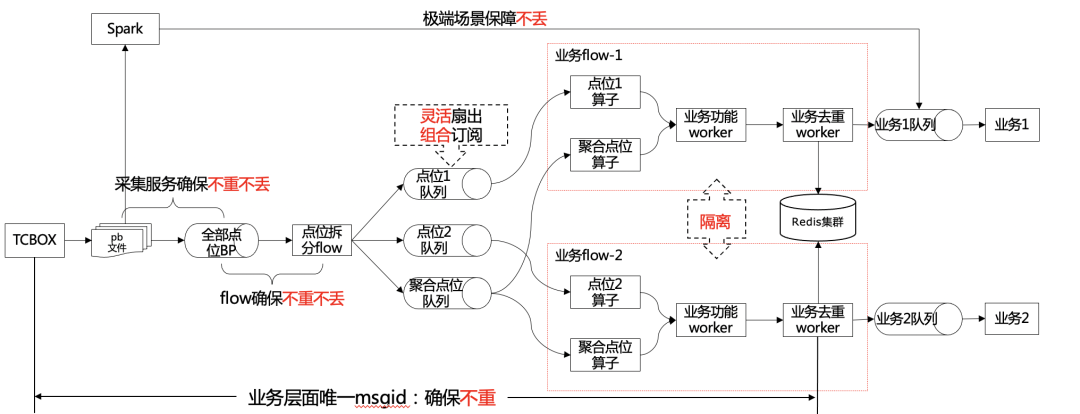
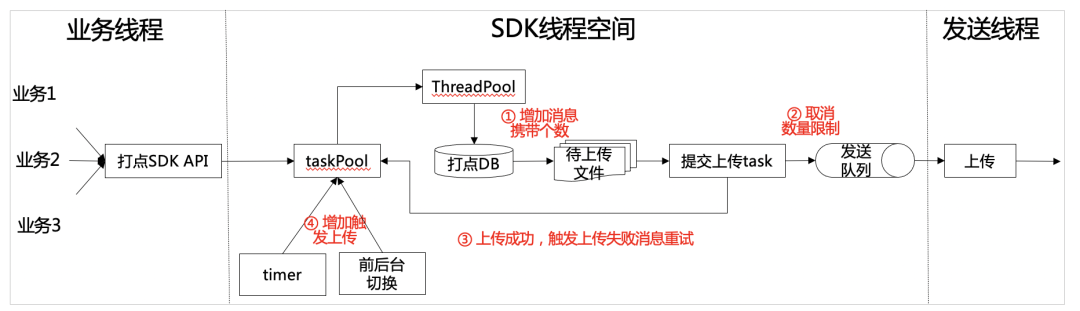
3.2.2 打点SDK数据上报优化(解决端上报数据丢失)
增加上报时机:单独定时任务轮询、业务打点时触发携带缓存数据、缓存消息达到阈值触发(实验获得)等手段,提高缓存数据的上报的时机,尽量降低消息在本地缓存时间。 增加上报消息个数:在保证数据上报大小、条数(实验对比得到阈值),将上报消息的条数进行调整,取得合理上报个数,达到消息第一时间到达服务端的最大收益。
四、展望
磁盘故障导致数据丢失:接入层后续针对磁盘故障,基于公司的数据持久化能力,建设数据的严格不丢失基础
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈

评论