
不正经人爱写日志
第零篇简单介绍了austin项目做什么用的,这两个月我重点会实现哪一块内容。
第一篇用Maven+SpringBoot搭好了项目的架子,以及聊了下我对SpringBoot和Maven的看法。
总的来说,我感觉这次的反响是不错的,虽然阅读量不高。但留言的人多了很多,也有很多人都担心我会不会鸽掉(更新一半中途就断了)
我只能说:别慌,绝对不鸽,你只管追更就好。

我已经决定每个周末都扛着电脑回家,有空就往附近的图书馆里跑(图书馆是学习的YYDS,在家的效率就是要比图书馆要低不少)
不多BB了,今天继续聊个话题:日志
01、什么是日志
所谓日志,在我理解下就是:记录程序运行时的信息

在Java最初期又或是我们初学阶段,打印日志全凭System.out.println();
这好用吗?有待商榷。
对于大部分初学者来说,好用!我想看的信息,直接在console就能看到了,这是多么地方便阿。学习Java的第一个运行结果都是由System.out.println();出来的,不需要有任何的学习成本。
对于大部分工作者来说,本地调试可以,但如果程序部署到服务器以后,那就算了。
生产环境跟本地环境是有区别的:
生产环境需要记录的日志会更多(毕竟是作为一个系统/项目在线上运行,不可能只打印一点点内容) 生产环境的日志内容需要保留至文件(作为留存,线上不会说第一时间发现问题,很多需要查找历史日志数据) 生产环境的日志内容需要有一定的规范格式(至少日志记录的时间需要有吧) ...
上面这些要求,System.out.println();都是不具备的。
所以,我们可以看到在公司里写的项目,是没有用System.out.println();记录日志的

02、Java日志体系
工作了以后,你会发现每次引入一个框架,这个框架下几乎都有对应的日志包。
我之前在公司里曾经整合过几个项目(将原有的几个工程合并到一个项目内)。
系统分久必合合久必分,当时是认为以前的同事把项目拆得过于细,造成一定的资源浪费(毕竟每个工程跑在线上至少都会部署两台线上机器),所以有段时间公司就希望我们把一些细小的项目进行合并。
至于这做得对与错,这块我就不谈了。
在合并的过程中,最最最麻烦的就是解决依赖冲突的问题(都是Maven项目,会有Maven仲裁的问题),而这里边,最明显的就是Java日志包的问题。
如果你有那么一丢丢了解Java日志,你就应该多多少少听说过以下的名字:Log4j(log for java)、JUL(Java Util Logging)、JCL(Jakarta Commons Logging)、Slf4j(Simple Logging Facade for Java)、Logback、Log4j2

如果你比较细心,你会发现,不同的技术框架所采用的Java日志实现都很有可能不一样的。
既然实现不一样,那对应的API调用是不是就不一样?(毕竟它还不像是JDBC,定义了一套接口规范,各个数据库厂商去实现JDBC规范,程序员面向JDBC接口编程就完事了)
那这这这不是乱套呢?想到这里,血压就逐渐就上来了?这别慌,上面提到的Java日志Slf4j(Simple Logging Facade for Java)干的就类似JDBC做的事情。
它定义了日志的接口(门面模式),当项目使用别的日志框架时,那就适配它!(注意:JDBC是定义接口,数据库厂商实现。Slf4j也定义了接口,但是它适配其他的Java日志实现,骚不骚?)
我们看Slf4j官网的一张图,应该就挺好理解了:
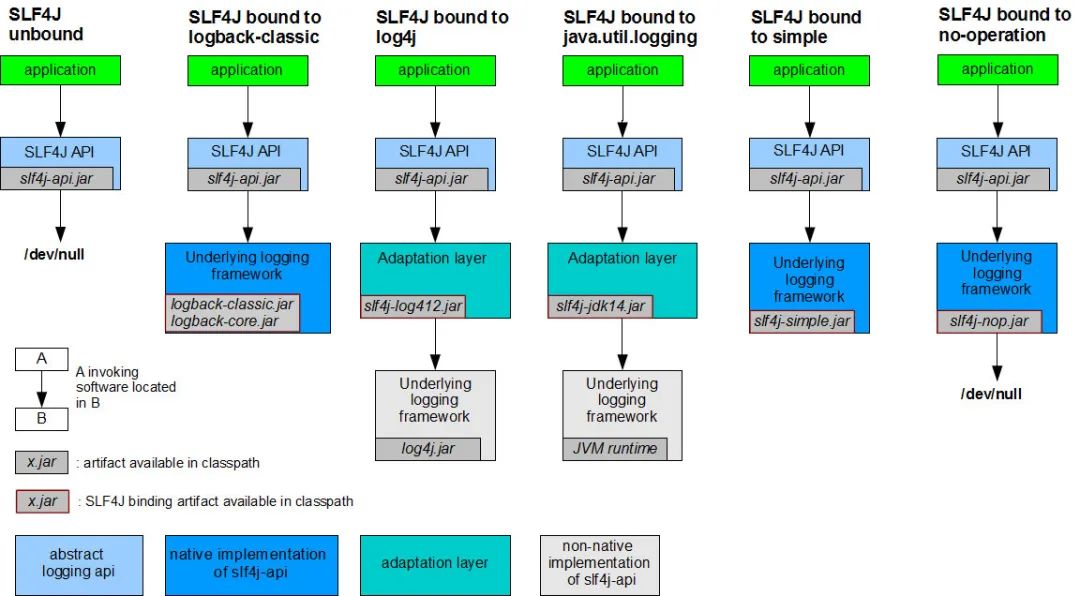
扯了这么久,我想表达的是:我们在项目中,最好是使用Slf4j提供的API,至于真实的LOG实现,都可以用Slf4j进行桥接(这样一来,或许将来有一天说要从log4j改为logback,那程序代码也不用改动)
03、日志有什么用?
还没有过生产环境的开发的同学可能认为记录日志就是用来定位问题的,其实并不完全是。
日志一方面我们用它来定位问题,一方面我们很多的数据也是来源于日志
不要觉得存在数据库里的数据才是重要的,我们程序运行时记录下的日志数据也同样重要。
在大数据领域里,数据来源有很多:关系型数据库、爬虫、日志等等
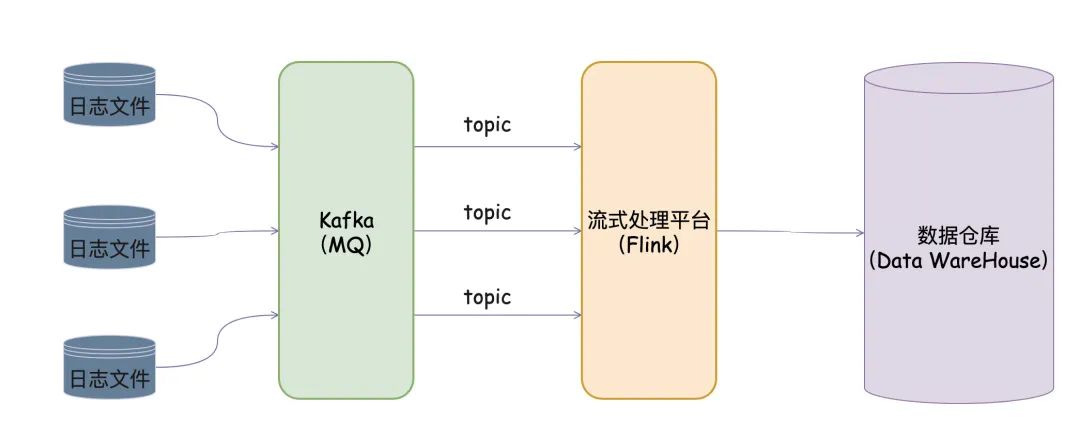
举个例子,我以前的公司就有处理日志的一套框架:
我们正常把日志信息输出到文件下 框架提供后台给予我们配置(文件的路径以及Kafka Topic Name)
该框架做的事情说白了就是:把我们的日志文件内容转成Kafka消息(如果使用方需要将哪个日志文件的内容转为MQ消息,那在平台上配置下就完事了)
有了Kafka消息,那配合流式处理平台(Storm/Spark/Flink)再对日志进行清洗,是不是就能产生有价值的数据
04、Austin 日志
扯了这么久的日志基础,只是想让还不了解日志的同学有个认知。
不扯别的了,还是回到我们还在「新建文件夹」阶段的austin项目吧。
austin项目的搭建技术框架使用的是SpringBoot,SpringBoot默认的日志组合是:Slf4j + logback
我在公司接触到的项目几乎都是这个组合,所以我就不打算动了,就直接用logback作为austin的日志实现框架了(要是真有那么一天要改成别的日志实现,理论上只要引入对应的桥接包就完事了)。
05、logback日志初体验
在无任何配置的前提下,只要我们引入了SpringBoot的包,就能直接使用日志的功能了。具体效果入下图
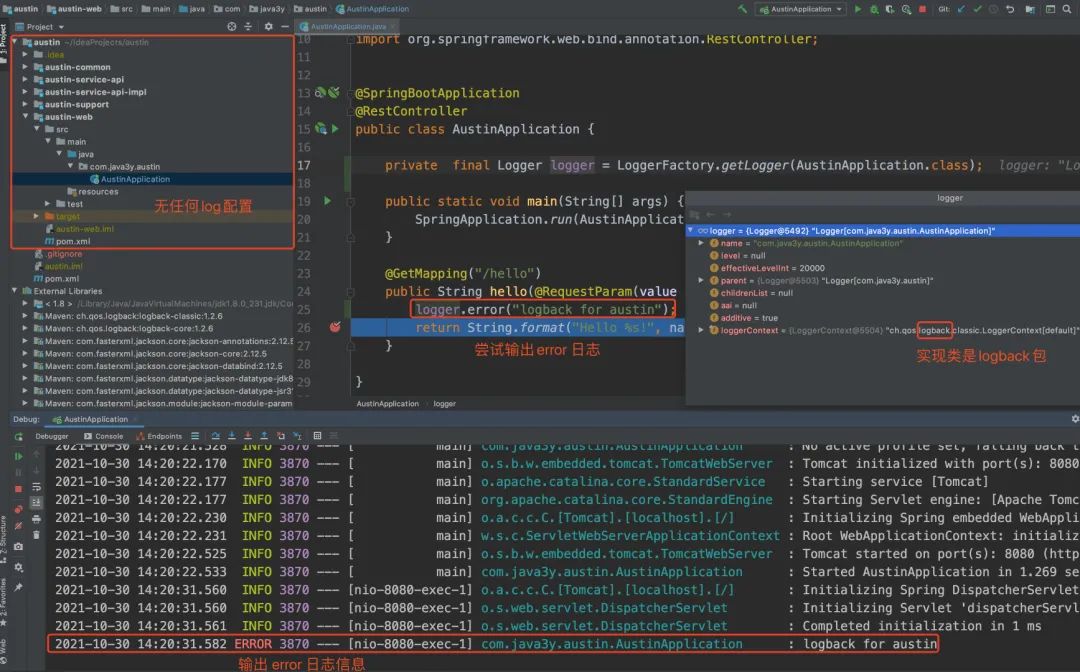
SpringBoot是约定大于配置的一个框架
SpringBoot会默认去加载resources下名为logback.xml 或者 logback-spring.xml的配置文件( xml 格式也可以改为 groovy 格式)
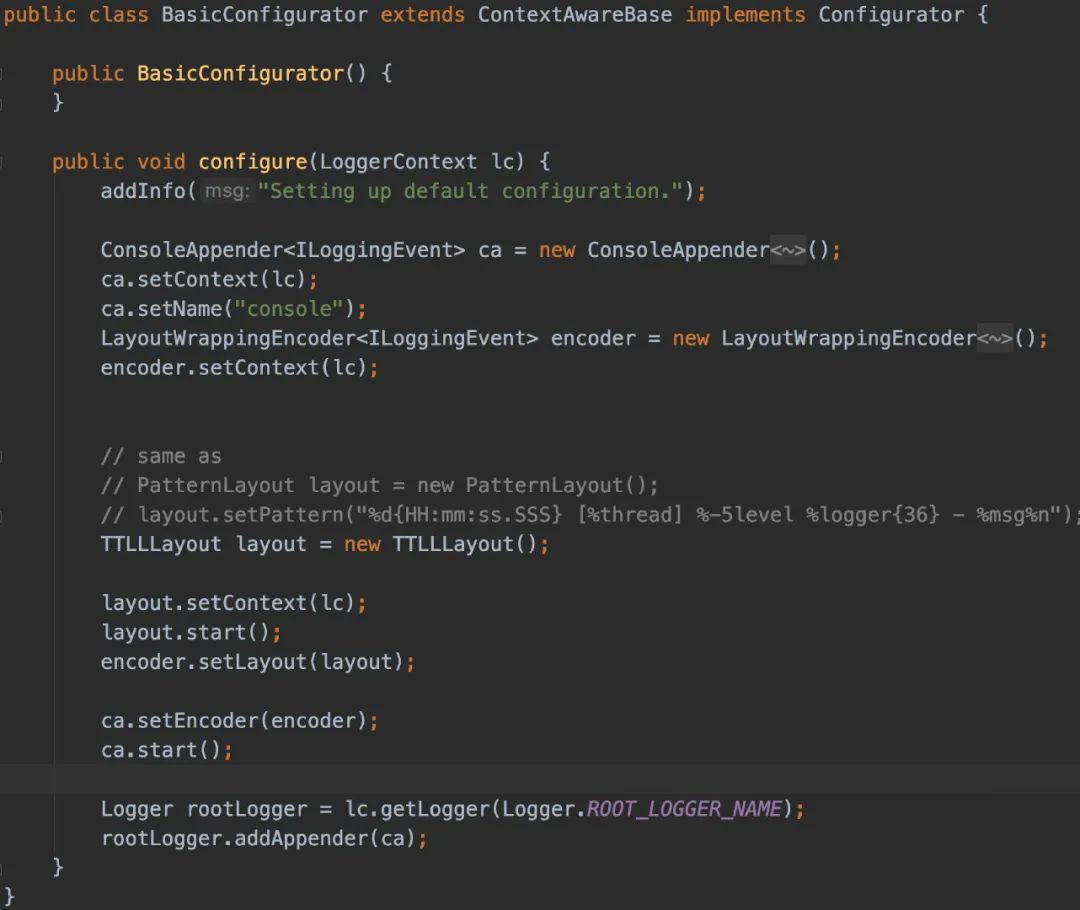
如果都不存在,那么 logback 默认地会调用BasicConfigurator ,创建一个最小化配置。
最小化配置由一个关联到根 logger 的ConsoleAppender 组成。输出用模式为%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n 的 PatternLayoutEncoder 进行格式化
06、logback配置
从上面可以发现的是,默认的logback配置是不符合我们的要求的(它是打印在console的),我们是希望把日志记录在文件下的。
所以,我们会在resources下新建一个logback配置。常见的配置内容如下:
<configuration scan="true" scanPeriod="10 seconds">
<contextName>austincontextName>
<property name="log.path" value="logs"/>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%npattern>
<charset>UTF-8charset>
encoder>
appender>
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/austin-info.logfile>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%npattern>
<charset>UTF-8charset>
encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}/logs/austin-info-%d{yyyy-MM-dd}.%i.logfileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>1000MBmaxFileSize>
timeBasedFileNamingAndTriggeringPolicy>
<maxHistory>15maxHistory>
rollingPolicy>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>infolevel>
<onMatch>ACCEPTonMatch>
<onMismatch>DENYonMismatch>
filter>
appender>
<appender name="ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/austin-error.logfile>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%npattern>
<charset>UTF-8charset>
encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}/austin-error-%d{yyyy-MM-dd}.%i.logfileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>1000MBmaxFileSize>
timeBasedFileNamingAndTriggeringPolicy>
<maxHistory>15maxHistory>
rollingPolicy>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERRORlevel>
<onMatch>ACCEPTonMatch>
<onMismatch>DENYonMismatch>
filter>
appender>
<root level="info">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="INFO_FILE"/>
<appender-ref ref="ERROR_FILE"/>
root>
configuration>
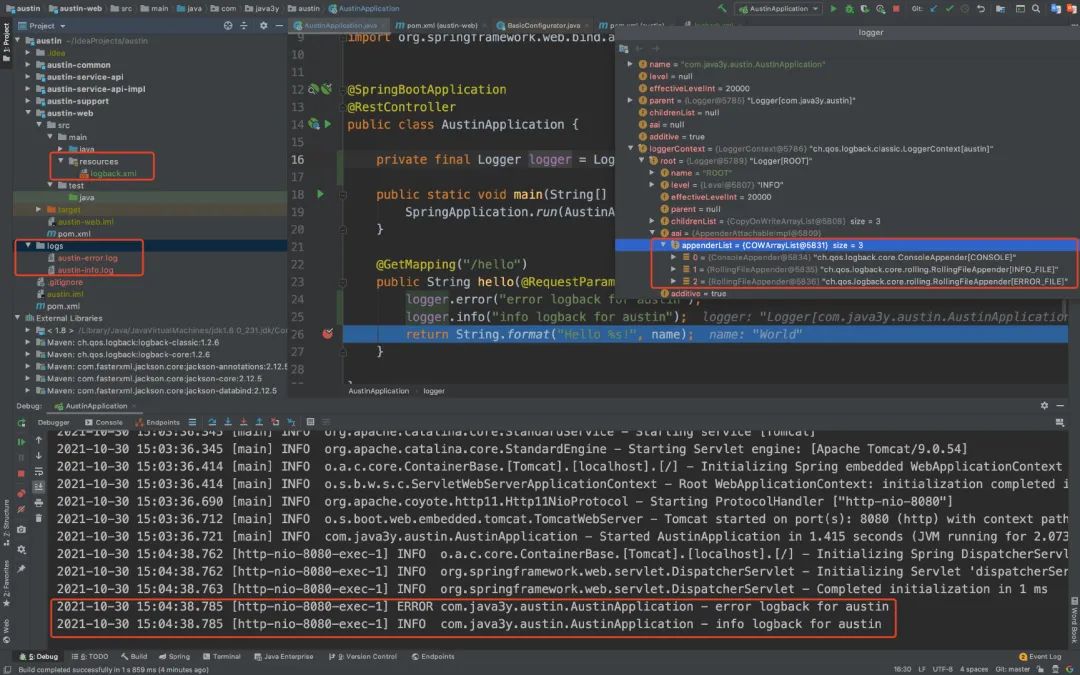
日志的配置不会是一成不变的,现在项目刚搭建出来,就怎么简单怎么来。
07、彩蛋
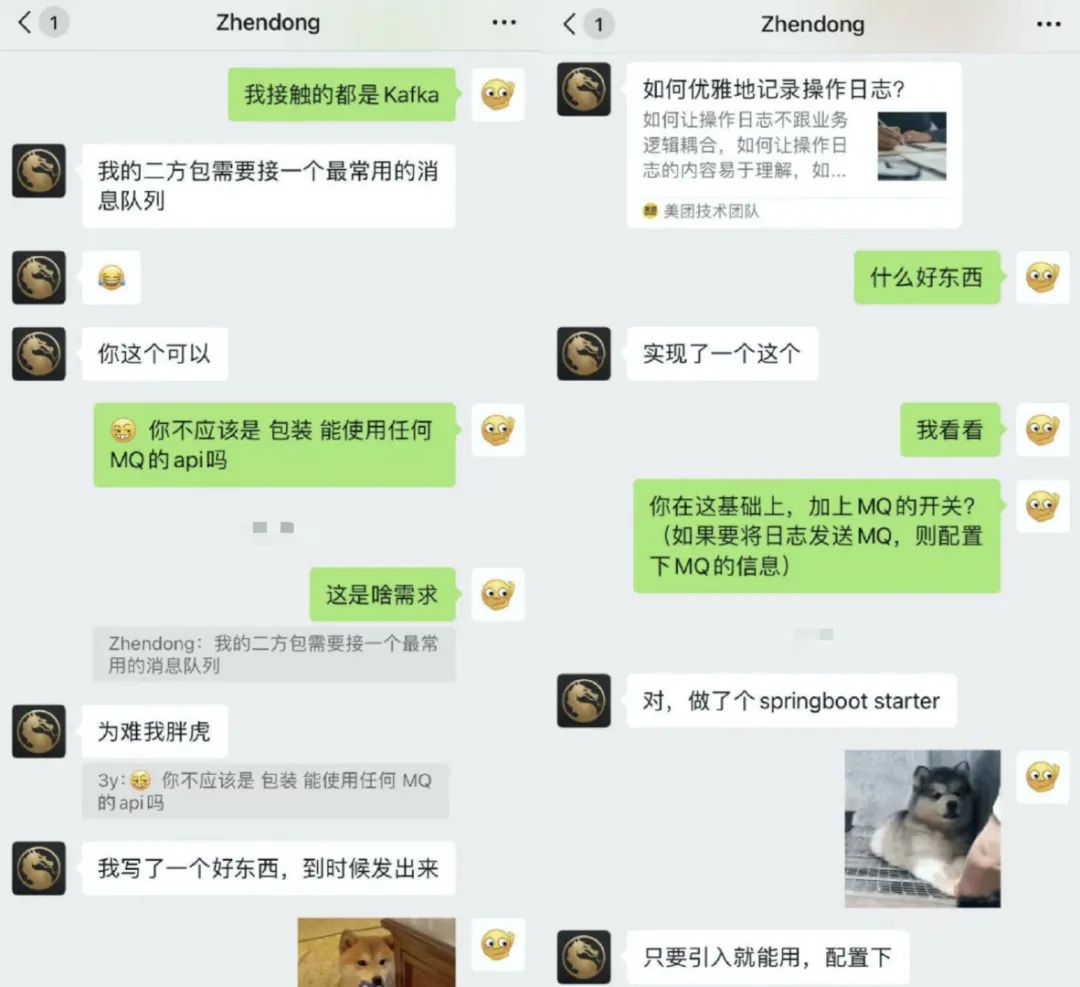
这篇文章发布的前一个晚上,ZhenDong突然问我现在用的什么MQ比较多,我随口一答:Kafka吧,我接触MQ基本都是Kafka
他说在写一个好东西,到时候发出来。我这一听,就肯定感兴趣了啊。
ZhenDong发的文章链接:https://mp.weixin.qq.com/s/JC51S_bI02npm4CE5NEEow
文章大概就是美团大佬们他们用AOP+动态模板封装了一套SDK,进而优雅地记录操作日志(说人话就是:大佬不想日志写在业务代码上,难以管理。将写日志这个动作抽象出来,用注解来统一记录日志)
文章还是很精彩的,我推荐阅读一遍。
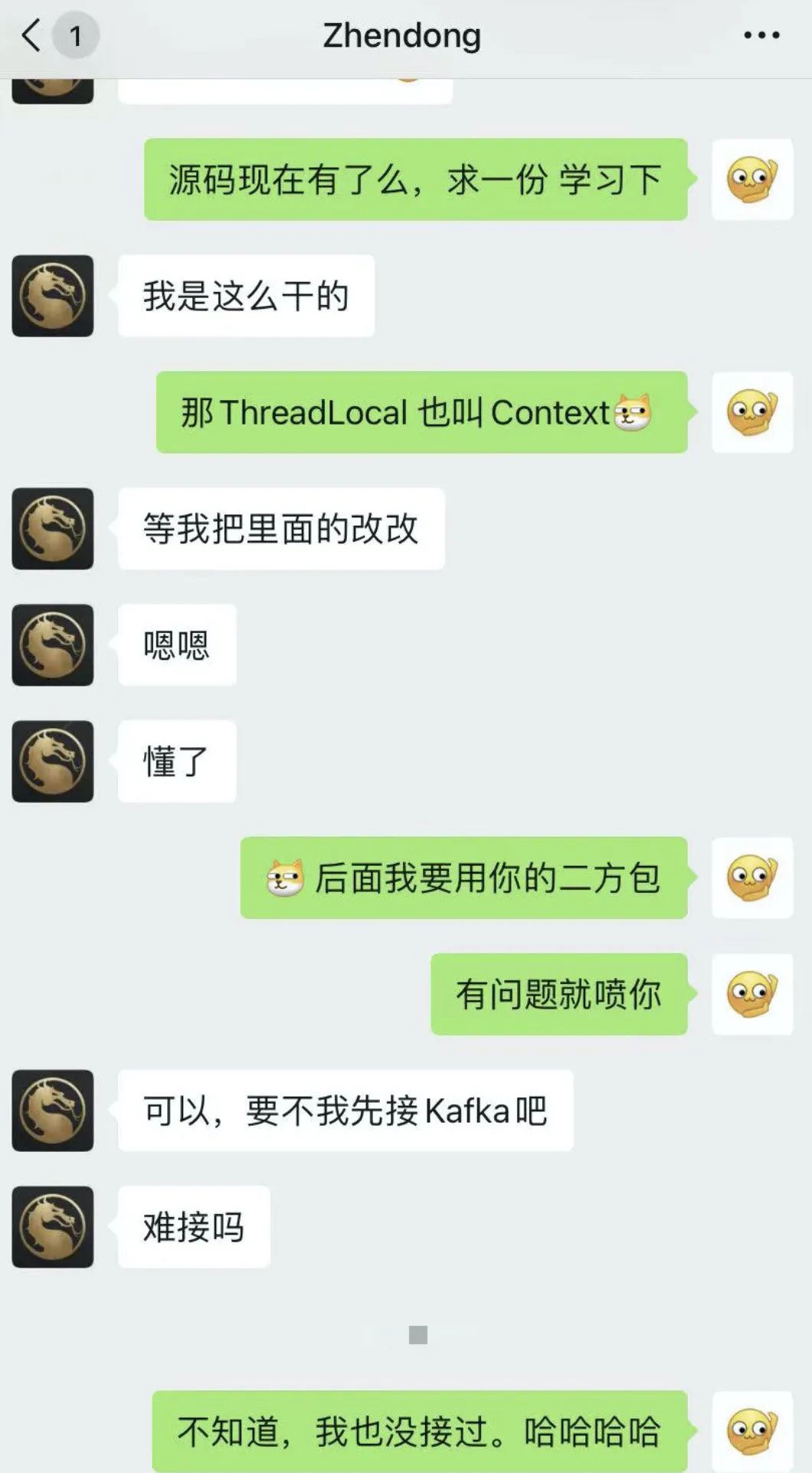
ZhenDong大佬看完文章后,自己实现了一套,已经差不多快要完成了。顺便我跟他讨论了下使用场景,感觉我的项目也可以用那一套东西(有优雅的打日志方式,谁不爱呢)
我已经预定了,到时候他给我发源码,我就学习下实现思路(后面项目也用他提供的SDK来打日志,有问题就开喷🐶[狗头.jpg])。等他忙完写好文章,我也转载下跟大家一起学习下。
像这种轮子或者说是经验思路,自己学会了以后,就可以在面试的时候吹了。就说自己对项目系统改造了一把,从原来的破鬼样(介绍背景),变成现在如此优雅(得到的结果),并这个过程中穿插自己的实现思路以及遇到的坑(艰辛的过程),这种亮点哪个面试官又不爱呢?
08、总结
日志在一个项目里,我认为是在一个比较重要的位置上的。我们的数据和定位问题都离不开日志,有的项目的日志相当混乱,那维护起来就特别特别麻烦。
其实我完全可以自己写个logback配置就把这块给忽略了,但我还是坚持梳理出来,这篇文章按照「项目」的维度从头梳理了一遍日志的知识,希望对大家有帮助吧。
另外,《对线面试官》公众号还在持续分享面试题,没关注的同学可以关注一波(近期我想把文字版上传上去了)
