
手把手教你使用Python网络爬虫获取王者荣耀英雄出装说明并自动化生成markdown文件
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
一、前言
玩过王者荣耀游戏的小伙伴们都知道英雄出装是十分重要的事情,一个合理的出装,再加上铭文,可以让你在王者战场上势如破竹,unstoppable!
前几天在【明佬】群里看到他分享了一个使用Python网络爬虫获取王者荣耀英雄出装说明,并使用线程池的方式下载了出装图片,之后还自动化生成了markdown文件,干货内容很多,这里拿出来分享给大家,欢迎大家积极尝试。
二、数据获取
这里我们的目标网站是王者荣耀官网,如下图所示。
之后依次点击首页右侧中的【英雄/皮肤】的【更多】按钮,可以进入到详情页,如下图所示,点击【局内道具】就可以看到出装信息了,里边包含了我们想要的目标信息。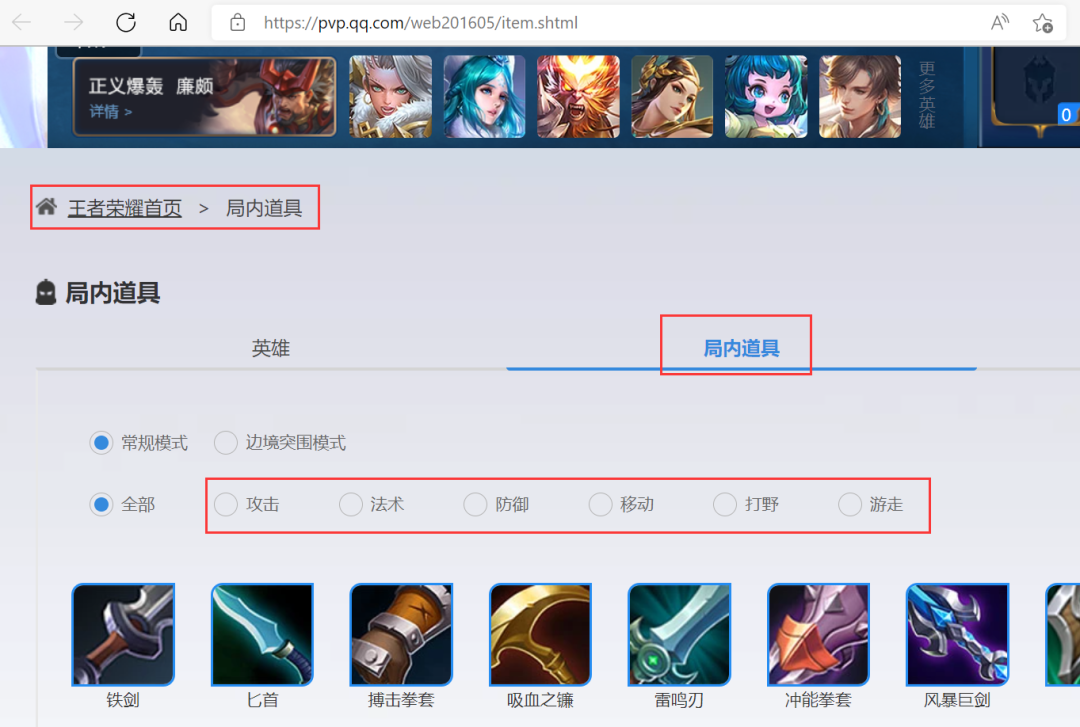
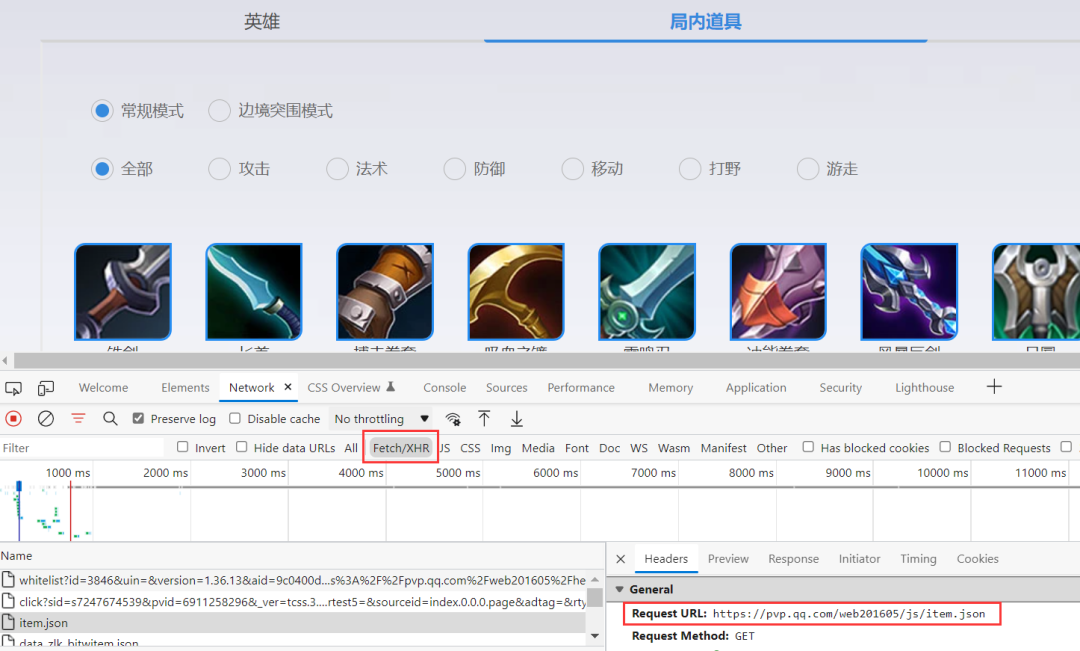
通过浏览器抓包,可以获取到具体的信息,可以看到存放在json格式中。
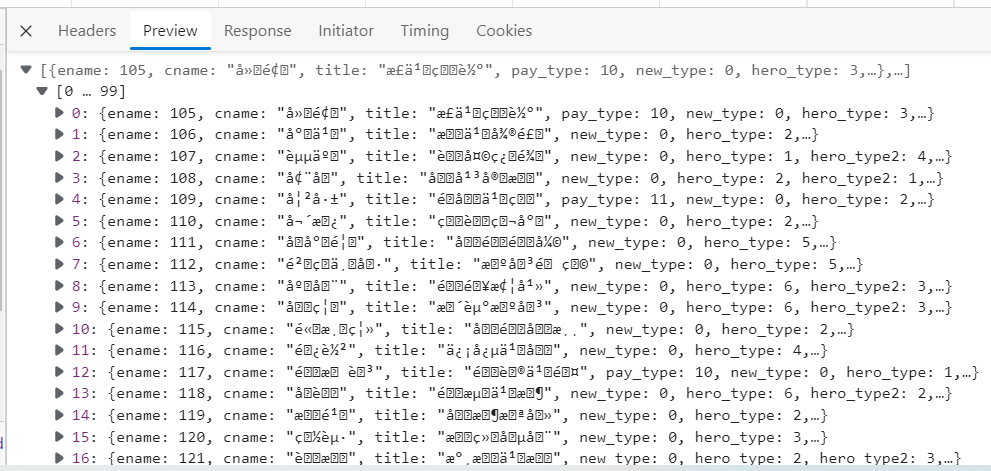
 下图是数据详情截图,可以看到有中文乱码,这个不影响,起码数据是可以拿到的。
下图是数据详情截图,可以看到有中文乱码,这个不影响,起码数据是可以拿到的。
代码实现过程
找到数据源之后,接下来就是代码实现了,一起来看看吧,这里直接套用【明佬】代码,在jupyter notebook中跑的。
获取装备数据
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.104 Safari/537.36 '
}
target = 'https://pvp.qq.com/web201605/js/item.json'
item_list = requests.get(target, headers=headers).json()
item_df = pd.DataFrame(item_list)
item_df.sort_values(["item_type", "price", "item_id"], inplace=True)
item_df.fillna("", inplace=True)
item_df.des1 = item_df.des1.str.replace("", "", regex=True)
item_df.des2 = item_df.des2.str.replace("", "", regex=True)
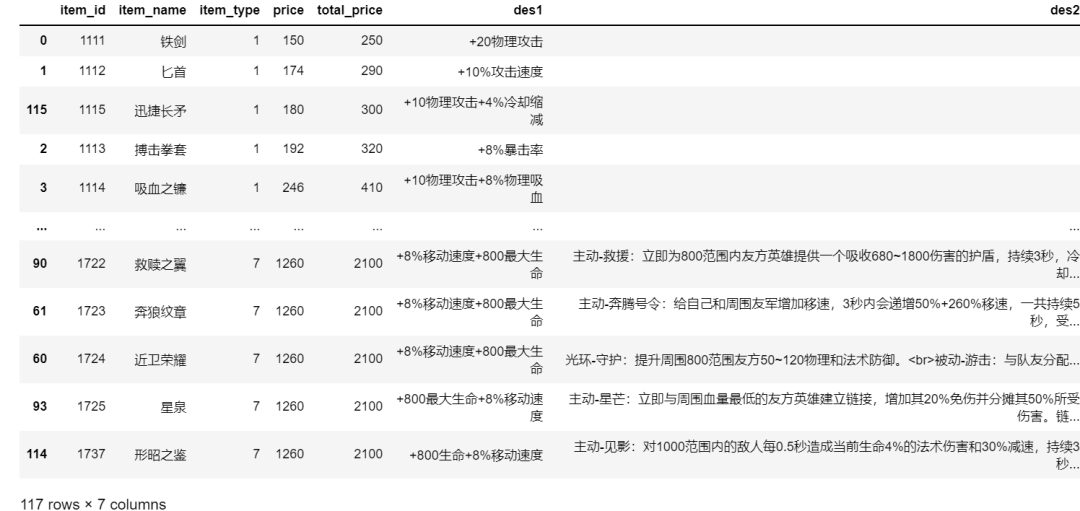
item_df
结果如下图所示:
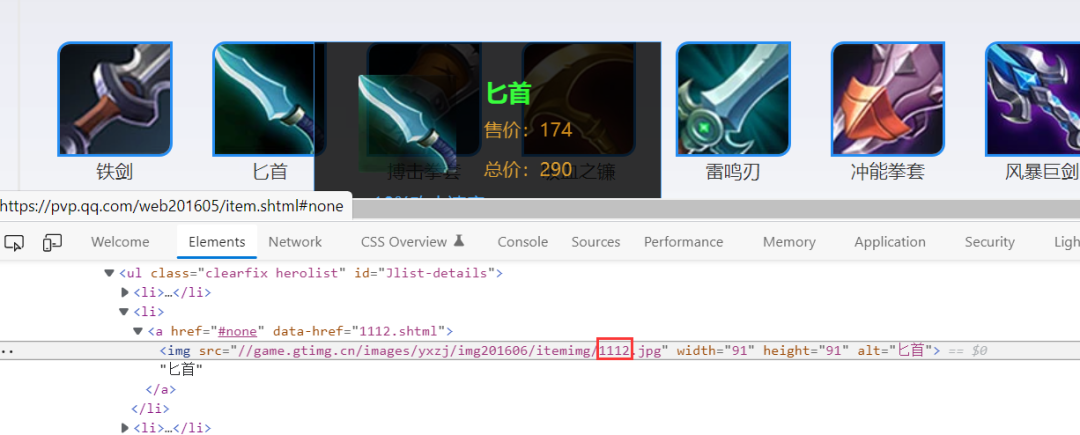
多线程下载图片
接下来使用线程池的方法下载图片,图片的拼接方法也很简单,看下图就一目了然了。
 下面是代码实现:
下面是代码实现:
import os
from concurrent.futures import ThreadPoolExecutor
def download_img(item_id):
if os.path.exists(f"imgs/{item_id}.jpg"):
return
imgurl = f"http://game.gtimg.cn/images/yxzj/img201606/itemimg/{item_id}.jpg"
res = requests.get(imgurl)
with open(f"imgs/{item_id}.jpg", "wb") as f:
f.write(res.content)
os.makedirs("imgs", exist_ok=True)
with ThreadPoolExecutor(max_workers=8) as executor:
nums = executor.map(download_img, item_df.item_id)
下载速度很快,几秒钟的事情,结果如下图所示:
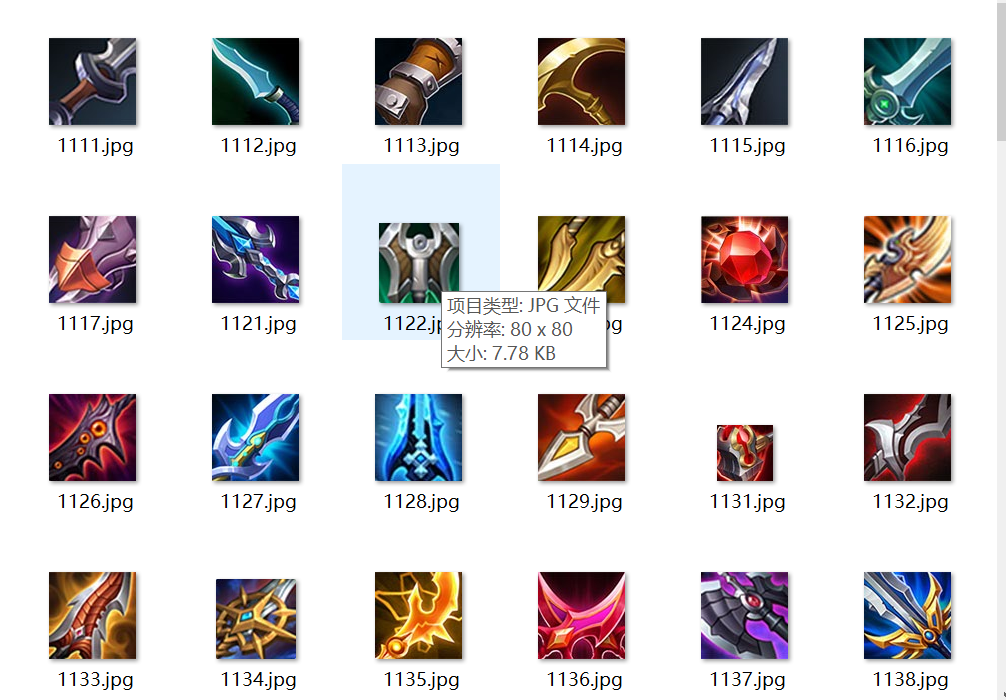
接下来,我们将数据自动化生成Markdown文档,一起来看看吧。
生成Markdown文档
代码如下,前面部分是数据的预处理,后面是写入文件:
item_type_dict = {1: '攻击', 2: '法术', 3: '防御', 4: '移动', 5: '打野', 7: '游走'}
item_ids = item_df.item_id.values
item_df.item_id = item_df.item_id.apply(
lambda item_id: f"")
item_df.item_type = item_df.item_type.map(item_type_dict)
item_df.columns = ["图片", "装备名称", "类型", "售价", "总价", "基础描述", "扩展描述"]
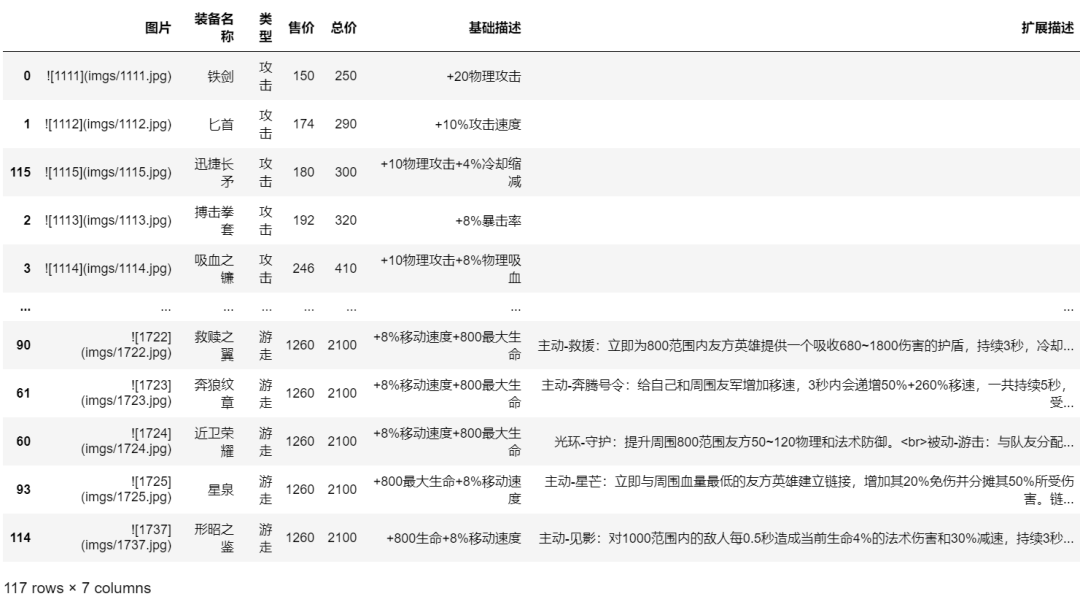
item_df
写入文件的代码,生成Markdown文档:
with open("王者装备说明.md", "w") as f:
for item_type, item_split in item_df.groupby("类型", sort=False):
f.write(f"# {item_type}\n")
item_split.drop(columns="类型", inplace=True)
f.write(item_split.to_markdown(index=False))
f.write("\n\n")
结果如下图所示:
之后在本地还会生成一个名为【王者装备说明.md】的Markdown文档,双击文件打开,内容如下图所示:
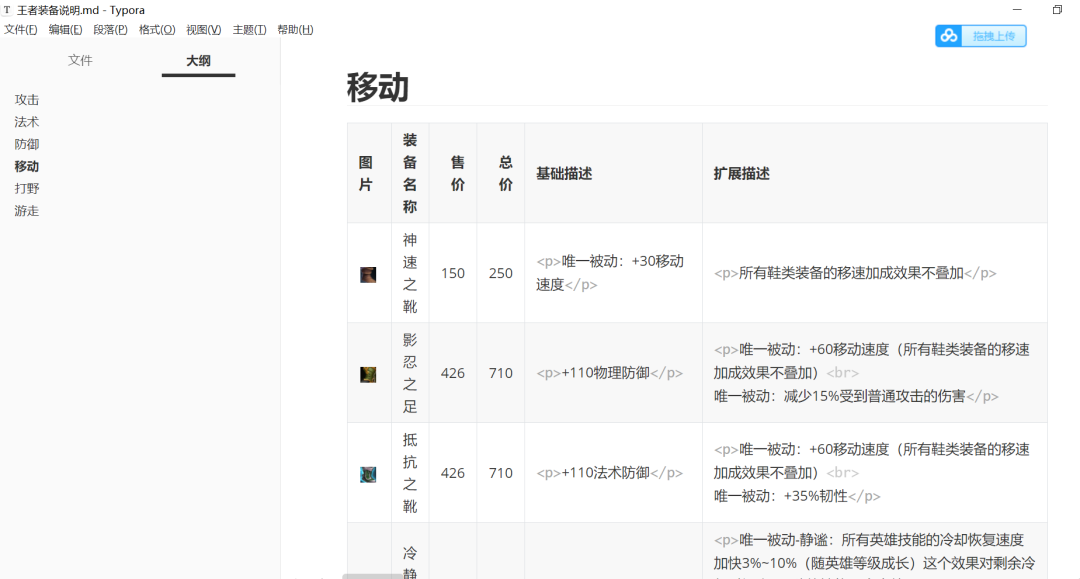 真是直呼好家伙!我在这一步实现的时候,遇到了一个报错,如下所示:
真是直呼好家伙!我在这一步实现的时候,遇到了一个报错,如下所示:
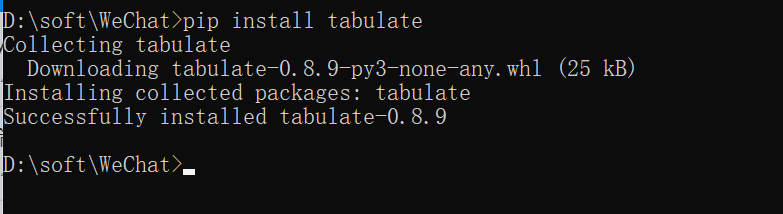
Missing optional dependency 'tabulate'. Use pip or conda to install tabulate.
提示却少依赖库,只需要在cmd下进行安装即可pip install tabulate,之后就可以正常运行了。
生成Excel表格
不过Markdown的表格无法任意调整,图片需要点击后才会放大,下面我们考虑生成Excel表格:首先需要整理数据,代码如下:
item_df.图片 = ""
item_df.基础描述 = item_df.基础描述.str.replace("
", "\n")
item_df.扩展描述 = item_df.扩展描述.str.replace("
", "\n")
item_df
生成结果如下图所示:
 之后将结果写入到
之后将结果写入到Excel中去,代码如下所示:
# 写入Excel表格
from openpyxl.drawing.image import Image
from openpyxl.styles import Alignment
with pd.ExcelWriter("王者装备说明.xlsx", engine='openpyxl') as writer:
item_df.to_excel(writer, sheet_name='装备说明', index=False)
worksheet = writer.sheets['装备说明']
worksheet.column_dimensions["A"].width = 11
for item_id, (cell,) in zip(item_ids, worksheet.iter_rows(2, None, 1, 1)):
worksheet.row_dimensions[cell.row].height = 67
worksheet.add_image(Image(f"imgs/{item_id}.jpg"), f'A{cell.row}')
worksheet.column_dimensions["F"].width = 15
worksheet.column_dimensions["G"].width = 35
writer.save()
打开文件,效果图如下图所示:

当然了,大家也可以根据自己想要的效果生成HTML和Word等等。
三、总结
大家好,我是Python进阶者。这篇文章主要分享了一个使用Python网络爬虫获取王者荣耀英雄出装说明,并使用线程池的方式下载了出装图片,之后还自动化生成了markdown文件,干货内容很多,欢迎大家积极尝试,如果有遇到问题,请添加我好友,我帮助解决。
最后感谢粉丝【明佬】分享的代码喝王者荣耀出装攻略,真是太强了,上王者指日可待!
最后放上【明佬】的csdn链接:https://xxmdmst.blog.csdn.net/article/details/124035041,点击阅读原文可以直达噢!
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何Python问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行