
手把手教你使用curl2py自动构造爬虫代码并进行网络爬虫
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
前言
前几天给大家分享了小小明大佬的两篇文章,分别是盘点一个小小明大佬开发的Python库,4个超赞功能和手把手教你用Python网络爬虫获取B站UP主10万条数据并用Pandas库进行趣味数据分析,这两篇文章里边都有说到curl2py命令,这个命令十分的神奇,通过curl2py命令将网页请求参数直接转换为python代码。
curl2py命令是小小明大佬开发的filestools库下四大神器之一,filestools目前包含四个工具包,分别是树形目录显示、文件差异比较、图片加水印和curl请求转python代码。关于其他三个神器的介绍,在上面那个超链接里边也有,这里给出源地址出处,直击小小明大佬开发的库。
https://pypi.org/project/filestools/ 前几天有粉丝在问这个curl2py命令不知道怎么使用,今天这篇文章就是一个手把手教程,希望大家后面都可以用上,下面一起来看看吧!
一、安装
你可以选择在命令提示符使用pip安装filestools库,安装命令:
pip install filestools或者pip install filestools -i http://pypi.douban.com/simple/ --trusted-host=pypi.douban.com
二、传统方法
1、目标网站
安装之后,我们就可以进行使用了。这里我们以小小明大佬之前介绍过的这个网站为例,进行说明。
小小数据网站:https://xxkol.cn/kol【注意】:如果是初次登录这个网站,需要进行微信扫码登录,才能有浏览权限噢!
2、网页请求
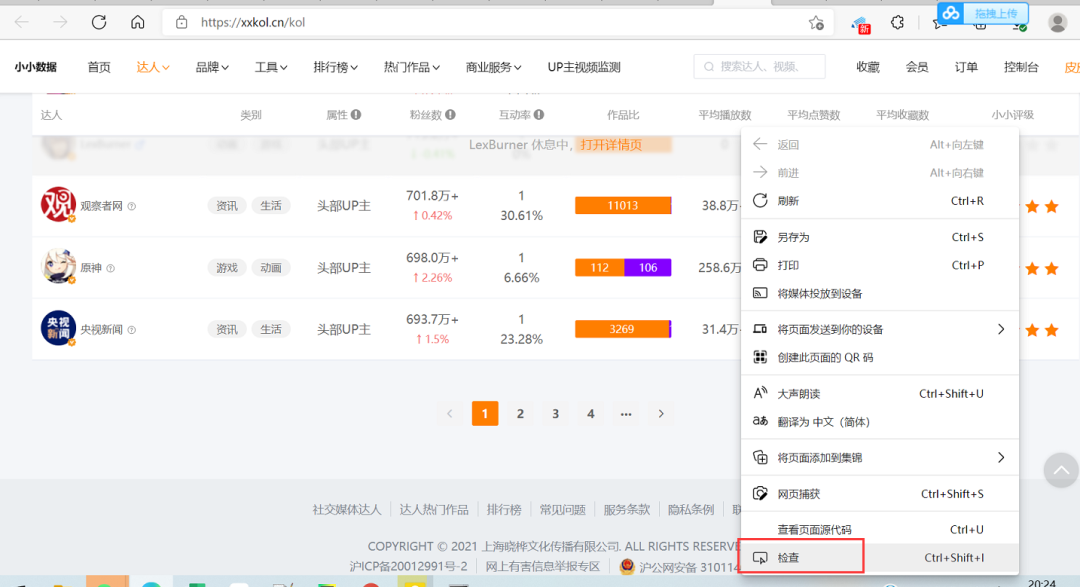
那么现在我们需要获取这个网站的数据,就需要对改网站进行请求。老规矩,右键选择“检查”(如下图所示)或者直接按下鼠标快捷键F12,可以进入开发者模式。
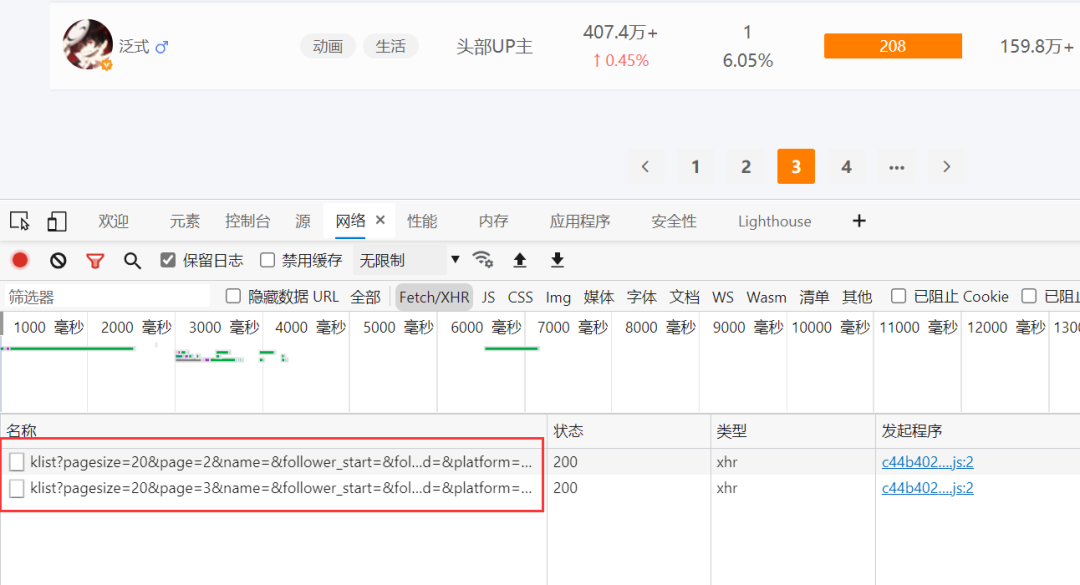
进入到开发者模式,如下图所示。依次选择网络-->Fetch/XHR

我们尝试进行翻页查看数据的话,发现这个网站其实是JS加载的,那么就需要构造请求头,如下图所示。
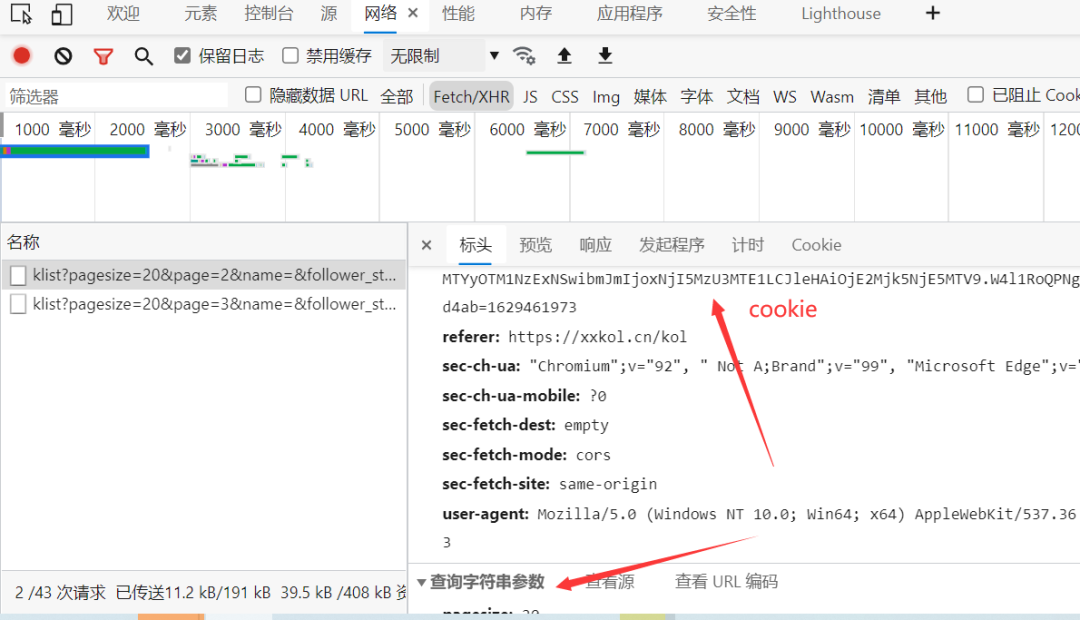
按照以往的做法,我们肯定是需要手动的去把这些cookies、headers和params参数挨个的去复制粘贴到我们的代码文件里边。这么做肯定是可以的,但是容易出现出错或者漏了某一个参数,而且费时费力,万一出错了,你还得挨个从头到尾去检查,十分的头大。
那现在小小明大佬给我们开发的这个curl2py工具呢,就直接解放了我们的双手,我直呼小小明yyds!下面一起来看看如何使用吧。
三、curl2py工具
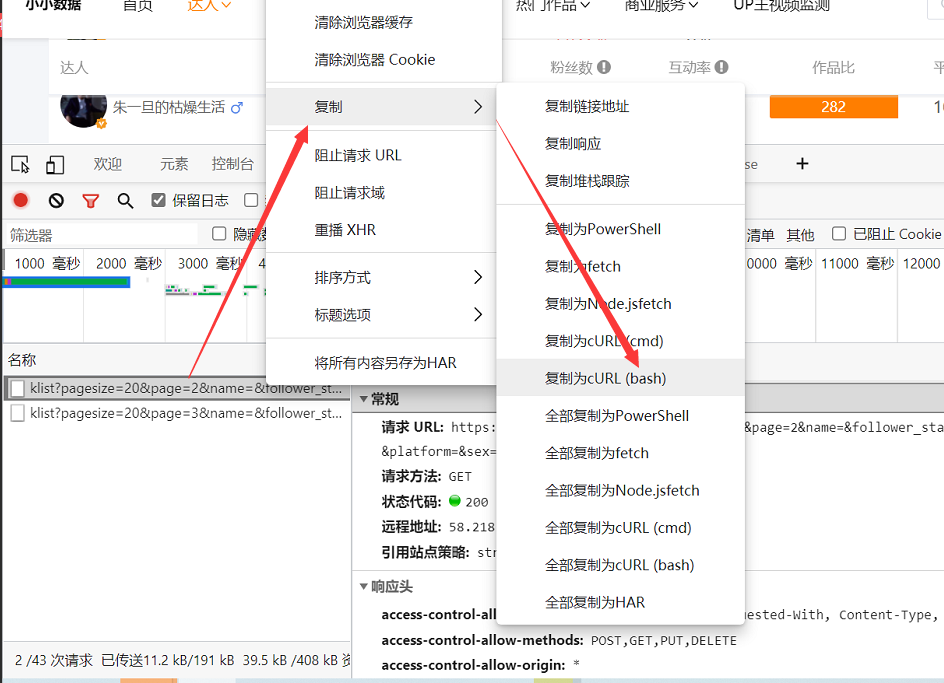
1、复制为cURL(bash)
继续沿用上一步的网站和分析情况,我们只需要在JS网址上进行右键,然后依次选择复制-->复制为cURL(bash),如下图所示。
2、使用curl2py工具转换代码
复制好之后,我们只需要在Pycharm中运行以下代码,其中代码中的xxx,就是上面复制到的curl命令,直接粘贴替换下面的xxx即可。
from curl2py.curlParseTool import curlCmdGenPyScriptcurl_cmd = """xxx"""output = curlCmdGenPyScript(curl_cmd)print(output)
3、实列
下面来看实际操作,以刚刚这个网站为例,小编刚刚已经复制了,然后替换粘贴代码,代码如下所示。
from curl2py.curlParseTool import curlCmdGenPyScriptcurl_cmd = '''curl 'https://xxkol.cn/api/klist?pagesize=20&page=2&name=&follower_start=&follower_end=&inter_start=&inter_end=&xxpoint_start=&xxpoint_end=&platform=&sex=&attribute=&category=&sort_type=' \-H 'authority: xxkol.cn' \-H 'sec-ch-ua: "Chromium";v="92", " Not A;Brand";v="99", "Microsoft Edge";v="92"' \-H 'accept: application/json, text/plain, */*' \-H 'authorization: eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyaW5mbyI6eyJvcGVuaWQiOiJvcEowYzB0V2p4RmJ4bTMwQ1FyZE9QSXNaWmlJIiwiaWQiOjEzMzc2fSwiaXNzIjoiaHR0cHM6XC9cL2JhY2sueHhrb2wuY24iLCJhdWQiOiJodHRwczpcL1wvYmFjay54eGtvbC5jbiIsImlhdCI6MTYyOTM1NzExNSwibmJmIjoxNjI5MzU3MTE1LCJleHAiOjE2Mjk5NjE5MTV9.W4l1RoQPNgCXBBBobO49QcfMjgYsM4nuKNtCmKshhHA' \-H 'sec-ch-ua-mobile: ?0' \-H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.73' \-H 'sec-fetch-site: same-origin' \-H 'sec-fetch-mode: cors' \-H 'sec-fetch-dest: empty' \-H 'referer: https://xxkol.cn/kol' \-H 'accept-language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6' \-H 'cookie: Hm_lvt_d4217dc2524e360ff487588dd84ad4ab=; xxtoken=eyJ0eXGciOiJIUzI1NiJ9.eyJ1c2VyaW5mbyI6eyJvcGVuaWQiOiJvcEowYzB0V2p4RmJ4bTMwQ1FyZE9QSXNaWmlJIiwiaWQiOjEzMzc2fSwiaXNzIjoiaHR0cHM6XC9cL2JhY2sueHhrb2wuY24iLCJhdWQiOiJodHRwczpcL1wvYmFjay54eGtvbC5jbiIsImlhdCI6MTYyOTM1NzExNSwibmJmIjoxNjI5MzU3MTE1LCJleHAiOjE2Mjk5NjE5MTV9.W4l1RoQPNgCXBBBobO49QcfMjgYsM4nuKNtCmKshhHA; Hm_lpvt_d4217dc2524e360ff487588dd84ad4ab=1629212' \--compressed'''output = curlCmdGenPyScript(curl_cmd)print(output)
运行代码之后,我们在控制台会得到具体的爬虫代码,如下图所示。
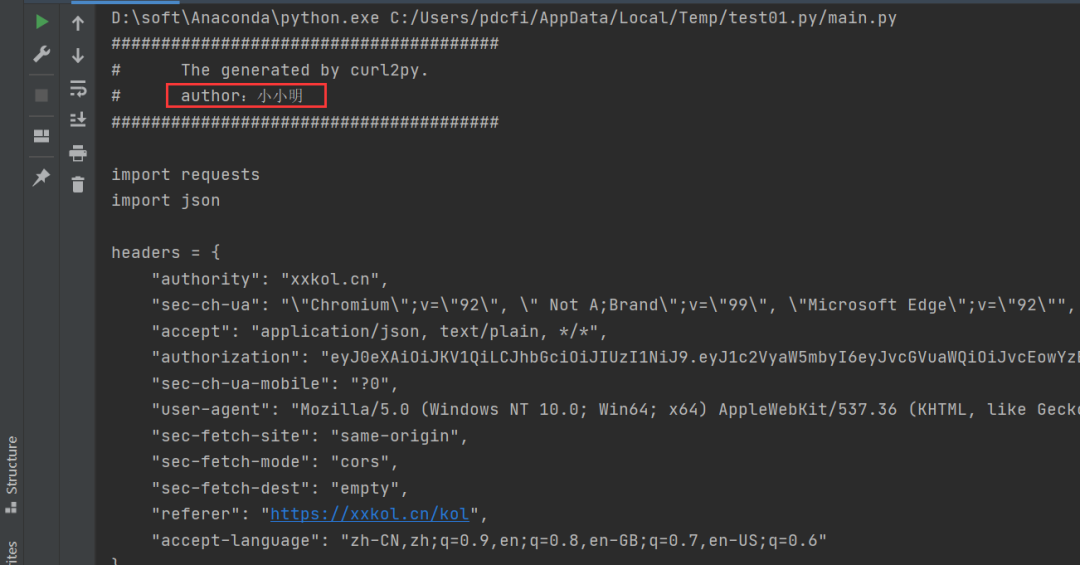
也就是说,都不需要你动手,小小明大佬直接给你把代码都构造出来了,是不是个狠人?
这里我把控制台输出的代码直接拷贝出来,粘贴到这里,这样大家看得可能会更直观一些。
######################################## The generated by curl2py.# author:小小明#######################################import requestsimport jsonheaders = {"authority": "xxkol.cn","sec-ch-ua": "\"Chromium\";v=\"92\", \" Not A;Brand\";v=\"99\", \"Microsoft Edge\";v=\"92\"","accept": "application/json, text/plain, */*","authorization": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyaW5mbyI6eyJvcGVuaWQiOiJvcEowYzB0V2p4RmJ4bTMwQ1FyZE9QSXNaWmlJIiwiaWQiOjEzMzc2fSwiaXNzIjoiaHR0cHM6XC9cL2JhY2sueHhrb2wuY24iLCJhdWQiOiJodHRwczpcL1wvYmFjay54eGtvbC5jbiIsImlhdCI6MTYyOTM1NzExNSwibmJmIjoxNjI5MzU3MTE1LCJleHAiOjE2Mjk5NjE5MTV9.W4l1RoQPNgCXBBBobO49QcfMjgYsM4nuKNtCmKshhHA","sec-ch-ua-mobile": "?0","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.73","sec-fetch-site": "same-origin","sec-fetch-mode": "cors","sec-fetch-dest": "empty","referer": "https://xxkol.cn/kol","accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6"}cookies = {"Hm_lvt_d4217dc2524e36588dd84ad4ab": "1629232919","xxtoken": "eyJ0eXAiOiJKVhbGciOiJIUzI1NiJ9.eyJ1c2VyaW5mbyI6eyJvcGVuaWQiOiJvcEowYzB0V2p4RmJ4bTMwQ1FyZE9QSXNaWmlJIiwiaWQiOjEzMzc2fSwiaXNzIjoiaHR0cHM6XC9cL2JhY2sueHhrb2wuY24iLCJhdWQiOiJodHRwczpcL1wvYmFjay54eGtvbC5jbiIsImlhdCI6MTYyOTM1NzExNSwibmJmIjoxNjI5MzU3MTE1LCJleHAiOjE2Mjk5NjE5MTV9.W4l1RoQPNgCXBBBobO49QcfMjgYsM4nuKNtCmKshhHA","Hm_lpvt_d4217dc2524e360ff488dd84ad4ab": "16292212"}params = {"pagesize": "20","page": "2","name": "","follower_start": "","follower_end": "","inter_start": "","inter_end": "","xxpoint_start": "","xxpoint_end": "","platform": "","sex": "","attribute": "","category": "","sort_type": ""}res = requests.get("https://xxkol.cn/api/klist",params=params,headers=headers,cookies=cookies)print(res.text)
哟嚯,这代码,直接给你呈现出来了,讲真,这代码比我们自己写出来的还要好呢,真是tql!
有的吃瓜群众可能就要问了,小编啊,这个代码能跑嘛?当然可以了!下面一起来运行下吧!直接在Pycharm里边复制控制台的代码,将首尾两行Pycharm自带的提示去除,就可以跑了,右键运行,得到下图的结果。
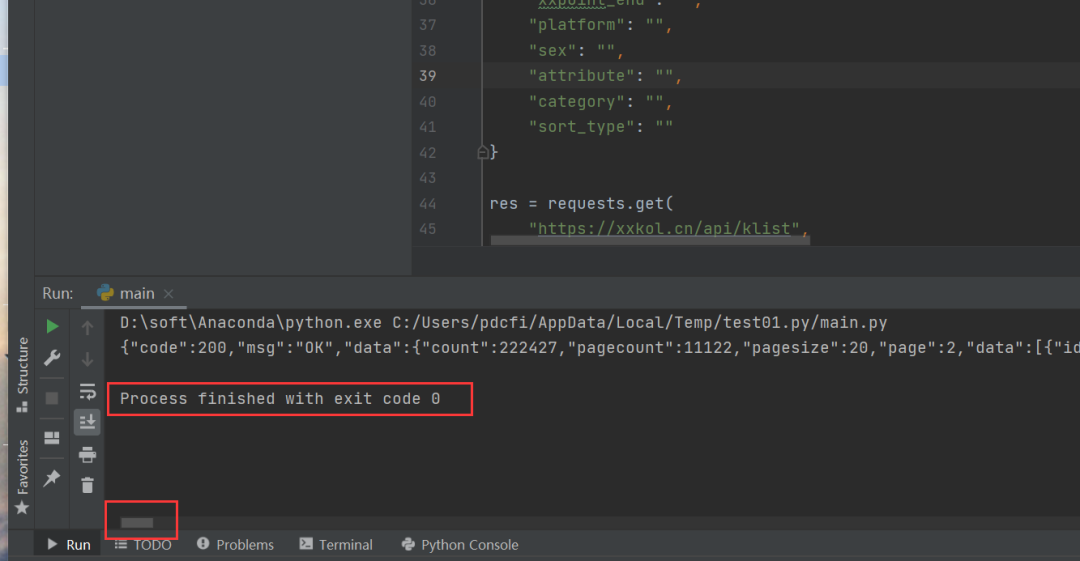
可以看到返回code 0,说明程序运行成功,而且可以看到滚动条那么小,可以想象数据量还是蛮大的,这个数据一看就是json格式的,直接将结果放到在线json网站中去看看。
json在线解析网址:https://www.sojson.com/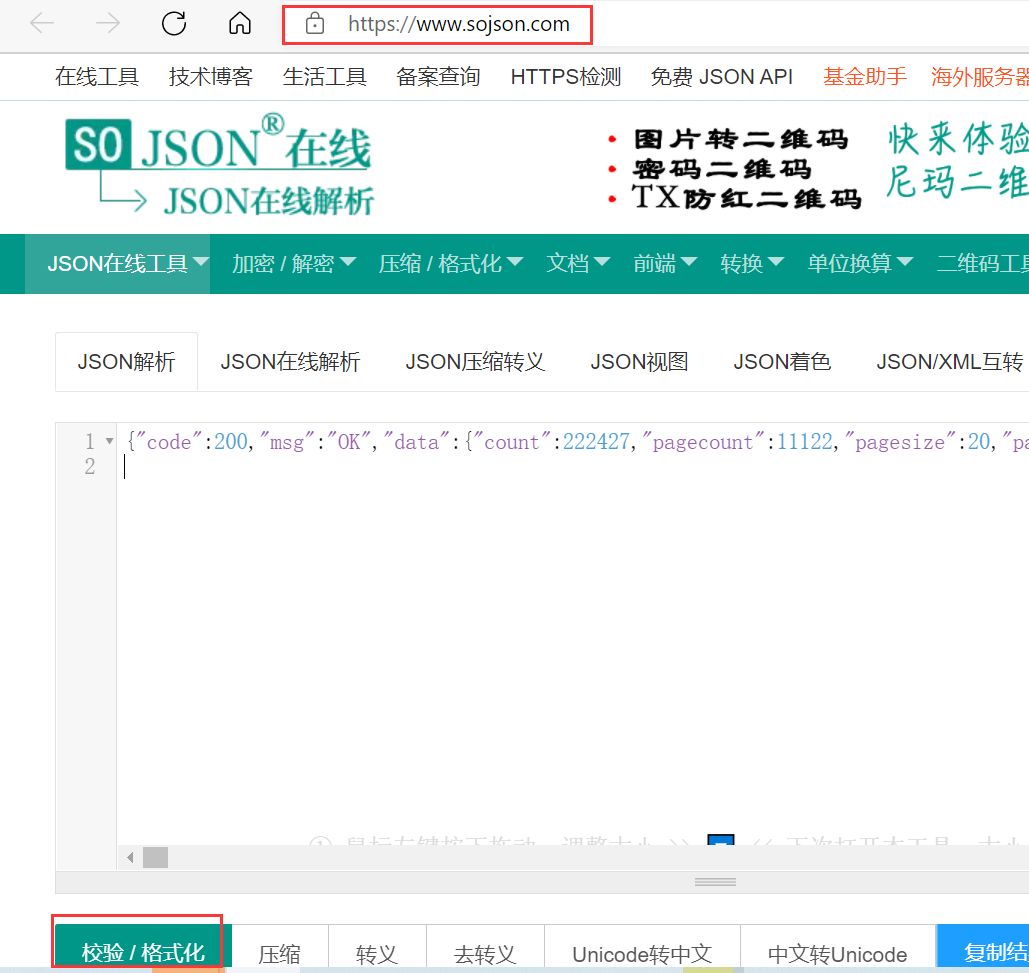
然后点击红色框框中的校验/格式化,可以看到json格式的数据,如下图所示。
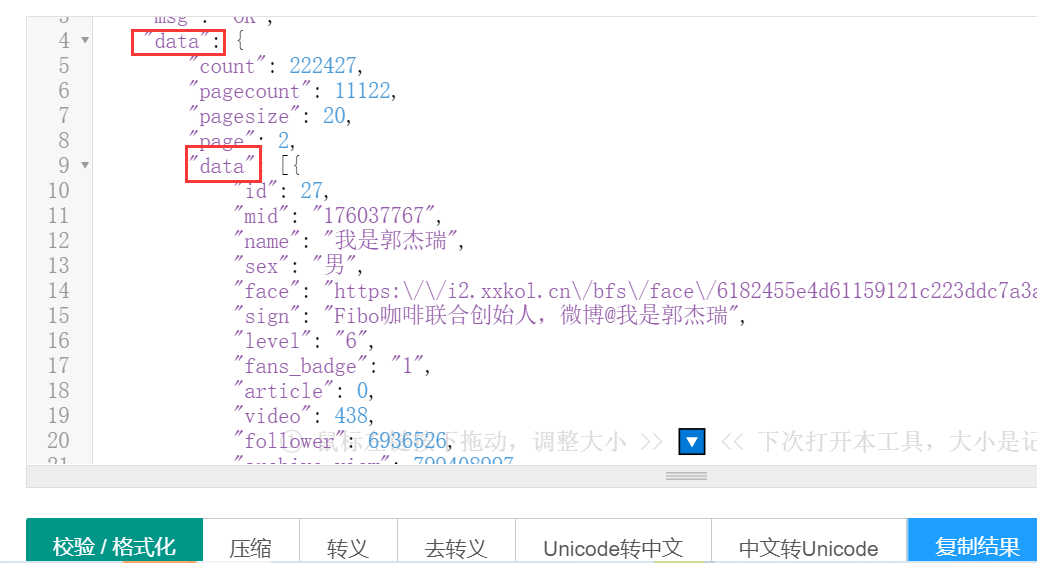
这下看上去是不是清爽很多了呢?
四、总结
我是Python进阶者,这篇文章主要给大家介绍了curl2py工具及其用法。curl2py工具的确是一个神器,功能强大,而且十分方便,有了它,基本上网页请求数据的复制、粘贴等传统方式都通通帮你搞定了,而且省事省心省力,还不用担心翻车。小伙伴们,你学会了嘛?快快用起来吧!
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~