
手把手教你使用Python网络爬虫获取亚马逊商品页面的m3u8格式视频
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
一、前言
前几天在Python最强王者交流群有个叫【顽皮Dolly】的粉丝问了一个Python网络爬虫的问题,抓取亚马逊商品视频,这里拿出来给大家分享下,一起学习下。
二、解决过程
这里【皮皮】给出了解答,一起来看看吧。
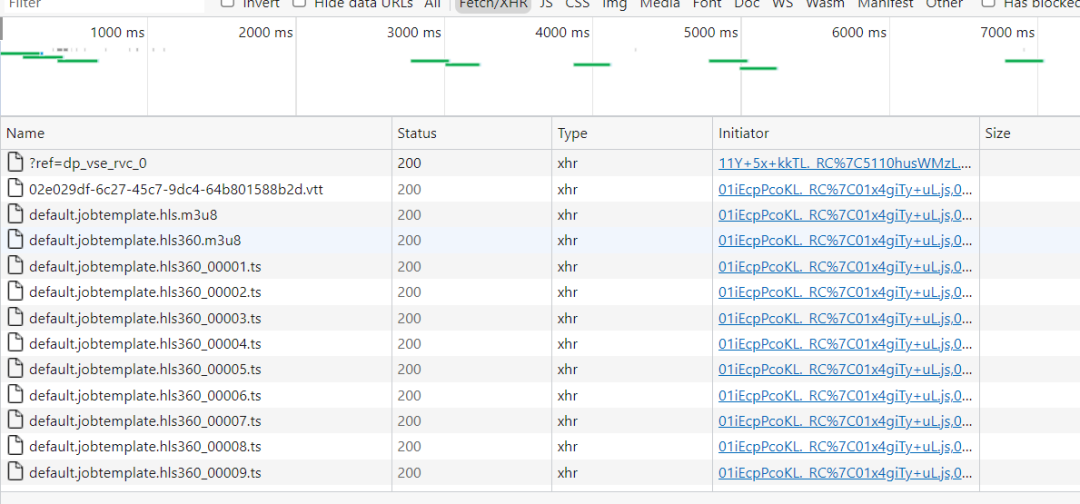 使用浏览器抓包发现,这个视频是
使用浏览器抓包发现,这个视频是m3u8格式的。m3u8是苹果公司推出的视频播放标准,是m3u的一种,只是编码格式采用的是UTF-8。
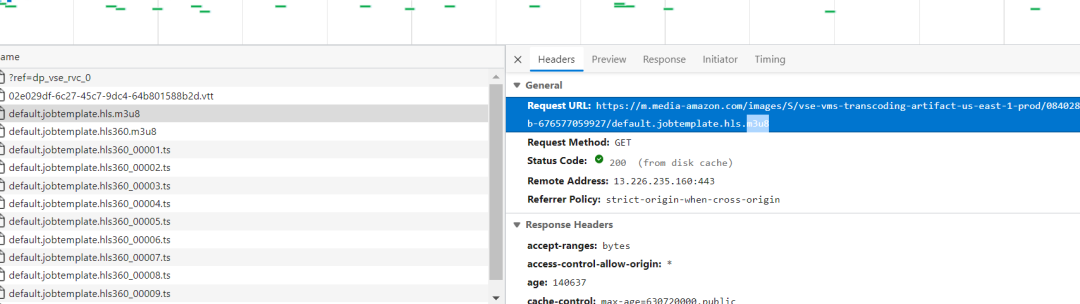 找到Url,就可以处理了。
找到Url,就可以处理了。
其实关于m3u8格式的视频下载,网上已经有很多教程了,也有人做出了小工具,可以直接拿过来用,也是非常卷了!这里使用【吴老板】写的小教程来演示。
【吴老板】的小教程链接:https://github.com/PY-GZKY/python-automation-docs/blob/master/docs/%E7%88%AC%E8%99%AB/m3u8%E9%9F%B3%E8%A7%86%E9%A2%91%E6%8B%BC%E6%8E%A5.md
里边的代码可以直接拿过来用,核心代码如下:
import datetime
import time
import os
import requests
# m3u8是本地的文件路径
def get_ts_urls(m3u8_path):
urls = []
with open(m3u8_path, "r") as file:
lines = file.readlines()
for line in lines:
if line.endswith(".ts\n"):
print(line)
urls.append("https://m.media-amazon.com/images/S/vse-vms-transcoding-artifact-us-east-1-prod/084028a2-9a64-485f-a55b-676577059927/"+line.strip("\n"))
return urls
def download(ts_urls, download_path):
for i in range(len(ts_urls)):
ts_url = ts_urls[i]
file_name = ts_url.split("/")[-1]
print("开始下载 %s" % file_name)
try:
response = requests.get(ts_url, stream=True, verify=False)
except Exception as e:
print("异常请求:%s" % e.args)
return
ts_path = download_path + "/{0}.ts".format(i)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
time.sleep(.56)
def file_walker(path):
file_list = os.listdir(path)
# file_list.sort()
file_list.sort(key=lambda x: int(x[:-3]))
file_list_ = []
for fn in file_list:
# print(fn)
p = str("tsfiles" + '/' + fn)
file_list_.append(p)
print(file_list_)
return file_list_
def combine(ts_path, file_name):
file_list = file_walker(ts_path)
file_path = file_name + '.MP4'
with open(file_path, 'wb+') as fw:
for i in range(len(file_list)):
fw.write(open(file_list[i], 'rb').read())
if __name__ == '__main__':
urls = get_ts_urls("./data.txt")
download(urls, "tsfiles")
combine("tsfiles", "大理")
这个是依次下载的ts文件,都是一个个几秒的小文件。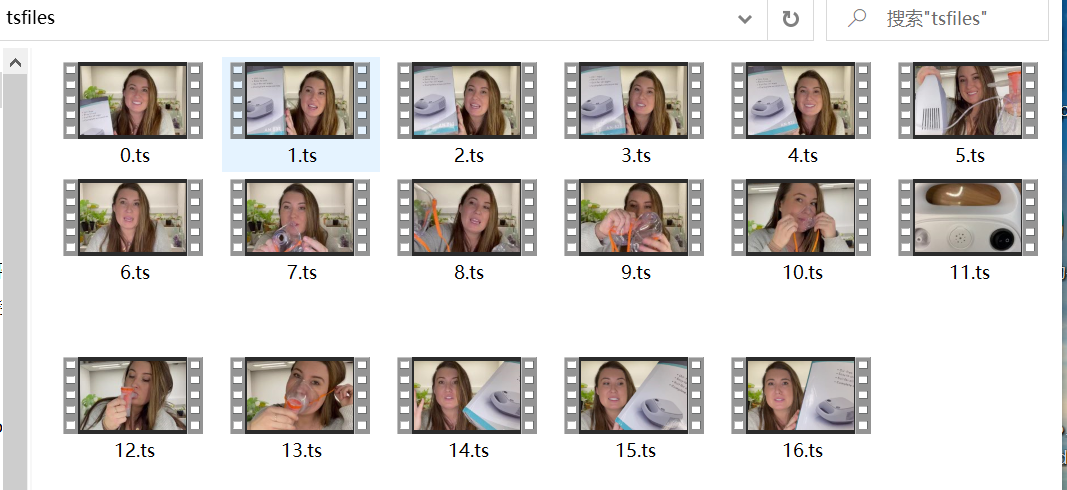
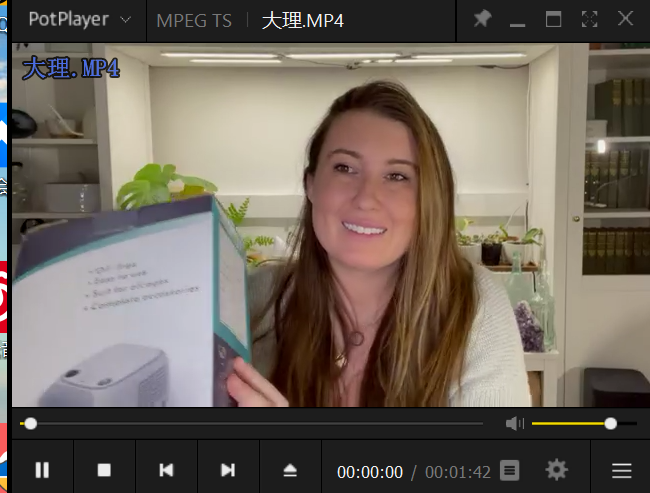
之后使用【吴老板】小教程上的合并combine()函数对这些ts文件进行合并,得到一个mp4文件,如下图所示。
后来【孤独】大佬提出还可以使用ffmpeg库进行下载,使用命令:ffmpeg -allowed_extensions ALL -i m3u8链接 -c copy 输出视频,感兴趣的小伙伴们也可以试试看,方法还是很多的。
三、总结
大家好,我是Python进阶者。这篇文章主要分享了Python下载m3u8格式视频的问题,针对该问题给出了具体的解析和代码演示,帮助粉丝顺利解决了问题。
最后感谢粉丝【顽皮Dolly】提问,感谢【皮皮】、【吴老板】、【孤独】给出的具体解析和代码演示,感谢【dcpeng】、【冯诚】、【冷喵】、【阿策~】、【瑜亮老师】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何Python问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行