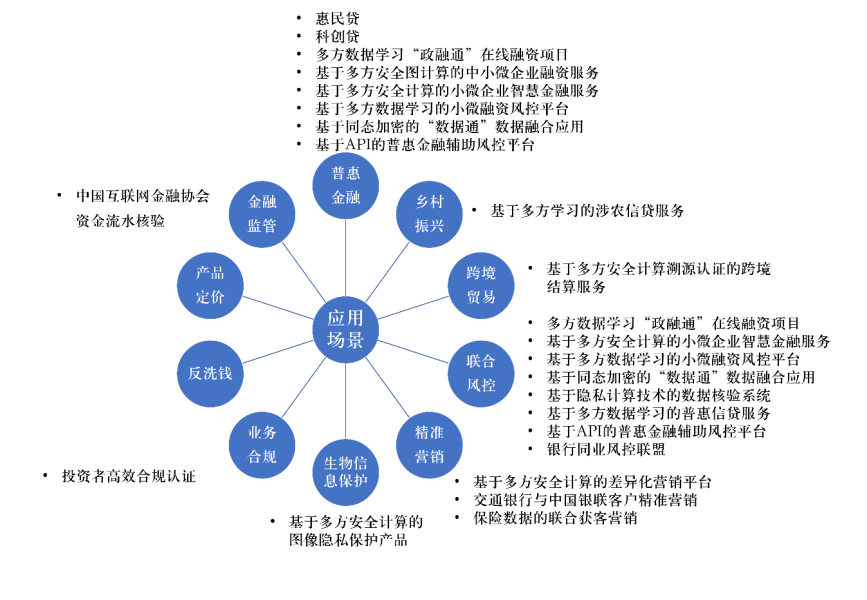
华为腾讯抢跑隐私计算,金融业先行中智观察关注共 4912字,需浏览 10分钟 ·2021-12-29 21:52 《中智观察》第1567篇推送作者:海比研究院编辑:小瑞瑞头图来源:摄图网中小微企业融资中的金融欺诈问题日益严重。基于隐私计算中的各自管控的多方安全计算系统平台,交行确保银行和运营商在数据不出库的前提下联合建模,用于小微企业普惠金融业务中,精准防范和打击伪冒审贷的行为。 在惠民就医场景中,通过隐私计算,银行联合政务数据中心和银行的数据,共同建立风险模型,在惠民就医应用中对申请客户进行精确画像及风险预测,通过智能算法实现就医客户的综合增信,既有效提升对就诊人员授信额度及授信覆盖率,又保障了个人的隐私。 隐私计算正在金融、政府、医疗等行业众多场景中应用,并产生了良好的效果。而工行和交行在最近各自推出的有关隐私计算的白皮书,就全面展示了中国金融业在隐私计算方面的进展和发展前景。 在数据融合、数据流通中,既要发挥数据的价值,又要保护个人隐私,满足法律法规的合规要求,让隐私计算在有场景、有技术和资金的金融业首先开花结果。‖灵魂拷问:要隐私安全,还是业务发展?大数据发展常会面临这样的灵魂拷问:隐私安全与业务发展,如何抉择? 在相当长的一段时间内,这都是一个充满矛盾的难题。以前,不少互联网企业选择业务发展,放弃了隐私安全,以谋取最大的利益。现在,企业依然不得不面对这样的抉择。 对于每一家企业,其信息系统所产生的数据规模越来越大,大量高价值信息隐藏在其中。提高数据共享能力,并以此为基础提升数据的发掘利用水平是不可逆转的发展趋势。 在这种情况下,一方面要高度共享数据,有效发掘利用数据;另一方面,有效控制数据,保护用户隐私等安全需求,二者之间存在明显的冲突。 另一种情况是在同一行业中,两家或多家企业各自拥有自己的业务数据,这些数据的规模和标签特征维度都很有限,于是大家都希望能够通过数据共享和整合,来获得规模更大、覆盖更全的数据,以对算法模型进行更好的训练。 但是,出于隐私和安全的考虑,通常大家都不可能将自己的数据完全共享出来,这就造成了行业内的信息孤岛和数据隔离的问题,制约了行业的数字化和智能化发展。 解决这一矛盾的技术就是在国内方兴未艾的隐私计算技术,有望让数据的利用告别这种“二选一”的难题。 大数据环境下隐私保护与管控技术发展的法律基础和合规要求日益完善。 2021年《数据安全法》与《个人信息保护法》陆续出台,与之前推出的《网络安全法》一起形成了数据合规领域的“三架马车”,标志着数据合规的基本法律架构已初步搭建完成。 也就意味着,数据利用监管强度将日渐收紧、合规压力日益凸显。 因此,不同行业、不同主体间的数据融合流通面临较大的合规压力,平衡数据价值挖掘需求和满足合规要求成为数据流通产业急需解决的问题。 这就为隐私计算等既保护个人隐私,又能综合利用数据的技术提供了一个广阔的舞台。 隐私保护主要面临三个方面的技术挑战。 一是用户身份匿名保护难。大数据场景下,用户数据来源与形式多样化,攻击者可通过链接多个数据源,发起身份重识别攻击,识别用户真实身份。 二是敏感信息保护难。可以通过共同好友、弱连接等发现用户之间隐藏的社交关系,发现用户社交关系隐私。可以通过以往轨迹分析预测目的地、用户隐藏的敏感位置,也可以根据其社交关系推测其可能出现的位置,透露用户位置隐私。可以通过社交网络中的群组发现识别出用户的宗教、疾病等敏感属性,发现用户属性隐私等等。 三是隐私信息安全管控难。用户隐私信息被采集后,数据控制权转落到网络服务商,而网络服务商往往缺乏足够的技术手段保证隐私数据的安全存储、受控使用与传播,从而导致用户隐私数据被非授权使用、传播或滥用。‖隐私计算,让数据流通起来隐私计算技术百花齐放,其定义与特征日渐清晰。 隐私计算联盟和中国信息通信研究院对隐私计算给出一个定义: 隐私计算(Privacy-preserving computation)是指在保证数据提供方不泄露原始数据的前提下,对数据进行分析计算的一系列信息技术,实现数据在流通与融合过程中的“可用不可见”。 以智能医疗领域为例,通过隐私计算,可以把多家医院的数据汇总到一起,联合对一个AI模型来进行训练,这样在保护病人个人隐私的前提下,又能够提升算法对病例的分析能力。 因此,从应用的角度,隐私计算涵盖了信息在收集、存储、使用、加工、传输、提供、公开等处理过程中,各信息处理方基于隐私评估,保护所拥有的数据内容。 从技术角度讲,隐私计算不是单一的技术,往往综合应用了大数据、人工智能、区块链、密码学、集成电路等多领域技术,以达到隐私保护的全部或部分目的。 从流通上看,隐私计算有助于在不对数据现有控制状态产生影响的基础上,满足数据流通的现实需求。数据的“可用不可见”能够有效防止数据明文在使用时被复制而导致的数据滥用, 保证数据的机密性和完整性。 从目标来看,能实现隐私保护的同时,支持数据价值分析的技术方案都可被列入隐私计算的范畴。 目前,常见的隐私计算技术包括安全多方计算、联邦学习、可信计算等。 多方安全计算是多个参与方基于密码学技术共同计算一个目标函数,保证每一方仅获取自己的计算结果,无法通过计算过程中的交互数据推测出其他任意一方的输入和输出数据的技术。 从技术路线上来看,多方安全计算的复杂度高,开发难度大。华控清交、富数科技、矩阵元等隐私计算初创企业多致力于此,专注于打造以底层多方安全计算技术为基础的数据流通基础设施。 联邦学习是一种多个参与方在保证各自原始私有数据不出数据方定义的私有边界的前提下,协作完成某项机器学习任务的机器学习模式。联邦学习技术分为横向联邦学习、纵向联邦学习、联邦迁移学习三类。 Google AI团队在2016 年率先提出了“联邦学习”算法框架,2019年Google实现了第一个产品级的移动端联邦学习系统,并把该系统从联邦学习推广到联邦计算和联邦分析。 其后,Facebook、百度等均在其开源的机器学习框架中提供联邦学习支持,如 TensorFlow-Federated、PaddleFL 等。同时,微众银行、字节跳动、矩阵元等推出了联邦学习开源框架,如FATE、FedLearner等。 可信执行环境(TEE)是数据计算平台上由软硬件方法构建的一个安全区域,可保证在安全区域内部加载的代码和数据在机密性和完整性方面得到保护,其完整性包括数据完整性和代码完整性。 目前主流CPU厂商都提供了TEE实现,如Intel的Software Guard Extensions (SGX)、 ARM (Advanced RISC Machines)的TrustZone等,百度、阿里巴巴等互联网大厂和冲量在线、隔镜科技等初创企业也有相应的技术。‖金融业隐私计算布局领先国外 国内隐私计算金融应用已领先国际。 据中国工商银行发布的金融业首个隐私计算白皮书——《隐私计算推动金融业数据生态建设》,国外金融行业隐私计算应用目前尚处于试点阶段,暂未形成规模化应用,且成熟产品较少。 而我国在金融领域率先谋划隐私计算顶层设计,且国内隐私计算金融应用已领先国际。 中国在隐私计算技术与应用方面走到了前面。 一是隐私计算产业化的步伐明显加快。2019年,Gartner首次将隐私计算列为处于启动期的关键技术。2020年,Gartner又将隐私计算列为2021年企业机构九大重要战略科技之一,并预测隐私计算将迅速得到落地应用,预计到2025年应用范围将覆盖全球一半的大型企业机构。 近两年来,伴随着技术的不断成熟,国内外隐私计算产业化的步伐明显加快。未来几年将是技术产品加速迭代,应用场景快速升级,产业生态逐步成熟的重要阶段。 二是国外隐私计算技术研究创新活跃,但商业化进展稍缓。虽然谷歌、Intel等国际企业开创了隐私计算产业的时代潮流,但相比国内企业,重点在学术研究和开源生态的建设上,商业化的产品形态较为局限。 三是国内隐私计算专利申请快速上升,已赶超国外。隐私计算技术相关的专利申请数量整体呈快速上升趋势,我国隐私计算专利申请后发成长性突显,自2019年起专利申请数量已超过国外。 四是隐私计算发展如火如荼,金融业先行试水。隐私计算的核心优势在于能够分离数据所有权和使用权,为“数据特定用途使用权流通”开创了新范式。 金融业隐私计算应用已在多地试点。2019年12月,中国人民银行启动金融科技创新监管试点工作,截至2021年10月,全国19个地区共推出127项创新监管试点项目,其中有13项涉及隐私计算技术,应用场景包括金融消费者人脸信息保护、产品营销、跨境结算、小微企业融资和信贷风控等 金融行业隐私计算主要应用场景。 金融行业隐私计算应用,涉及普惠金融、乡村振兴、跨境贸易、联合风控等。资料来源:交行隐私计算蓝皮书 一是普惠金融和联合风控。因普惠金融对风险控制较为敏感, 普惠金融业务较多涉及风险控制, 因此较多案例同时涉及到普惠金融和风险控制。 二是精准营销。一方面通过隐私计算技术可提供多维度数据,在精准营销中实现客户画像;另一方面也可通过隐私求交实现特定客群匹配,进而实现特定客群推荐。 三反欺诈场景。部分机构采用隐私计算技术实现信贷业务黑名单共享、多头借贷查询等反欺诈场景。 四是信贷风控场景。商业银行普遍基于数据智能分析改善风险管理体系,以期实现风控流程自动化与决策智能化。例如,基于联邦学习的企业贷中监测、基于多方安全计算的贷款资金流向跨行追踪、基于多方安全计算的信贷产品联合风控等。 当然,隐私计算也在医疗、政府等行业也得到了应用。 如医学研究、临床诊断、医疗服务等对基于大数据的统计分析与应用挖掘有着强烈的需求,但其依赖的是众多病患的个人健康数据,这些数据规模大、价值含量高,共享流通就十分困难。 利用隐私计算,在建立分散存储的标准化数据库的基础上,可以实现分布式的联合统计分析,从而获得临床科研的研究成果。‖隐私计算技术也内卷?我国的隐私计算技术产业化快速启动,出现了大量隐私计算技术与产品提供商。 目前,隐私计算已经形成了几大阵营: 互联网巨头企业如阿里巴巴、蚂蚁集团、微众银行、腾讯集团、百度集团、京东集团、字节跳动等都互联网巨头,都已经开始在隐私计算方向发力,旗下多个业务板块都推出了隐私计算产品。 云服务商,目前阿里云、腾讯云、百度云、京东云、金山云、华为云、优刻得等云服务商都推出了隐私计算服务。 科技公司如第四范式、星环科技等均在隐私计算领域加快布局。 区块链、AI公司进入隐私计算领域。人工智能背景的公司如瑞莱智慧、医渡云、三眼精灵、渊亭科技等,区块链背景的公司如矩阵元、Oasis、ARPA、趣链科技、零幺宇宙、宇链科技、翼帆数科、熠智科技、算数力、同济区块链等。 大量用户的科研机构和银行也建立了隐私计算研究团队和公司,如同盾科技、百融云创、富数科技、天冕科技、金智塔科技、冰鉴科技、甜橙金融等。 未来各种技术的融合与发展将成为企业用户面临的一大挑战。 关注技术“孤岛”引致新的数据“群岛”问题。 《隐私计算推动金融业数据生态建设》就认为,要避免隐私计算不当使用或滥用。目前,较多机构为保护自身数据权益,纷纷研发隐私计算技术产品。 相关产品尚未成熟时,需避免名义上采用隐私计算技术,实质上明文共享数据,这将对数据生态健康造成根本性伤害。 目前,不少金融机构已部署隐私计算平台,作为企业数据生态建设基本支撑。但不同产品算法差异致使难以互联互通,技术“孤岛”引致新的数据“群岛”问题。 金融业要自下而上持续探索互联互通,须以终为始、自上而下全局规划,前瞻性选择社会整体最优路径。 大量数据安全法规的推出就是一个信号,数据利用的合规已经迫在眉睫。隐私计算虽然走得还跌跌撞撞,但是尽早布局、发掘应用场景,是收获数据红利最明智的选择。 浏览 31点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 隐私计算英雄传浅黑科技0隐语可信隐私计算框架隐语(SecretFlow)是蚂蚁集团开源的可信隐私计算技术框架,涵盖了当前几乎所有主流隐私计算技术。隐语内置MPC、TEE、同态等多种密态计算虚拟设备,提供多类联邦学习算法和差分隐私机制。通过分层设隐语可信隐私计算框架隐语 (SecretFlow) 是蚂蚁集团开源的可信隐私计算技术框架,涵盖了当前几乎所有主流隐私计算隐私计算中的联邦学习喔家ArchiSelf0华为云-云计算专注于云计算中公有云领域的技术研究与生态拓展隐私计算新方向,50K很稳!菜鸟学Python0隐私计算白皮书(附PDF下载)肉眼品世界0隐私计算究竟解决了什么问题?小张讲区块链0华为《计算2030》(附下载)智能计算芯世界0最近,我和隐私计算干上了。Hollis0点赞 评论 收藏 分享 手机扫一扫分享分享 举报












 下载APP
下载APP