
拒了16k的外包,来了国企!
大家好,我是二哥呀。
今天给大家分享一个二哥编程星球里的主题:一位球友,二线城市,去年拒了一家 16k 的外包,去了国企,不过薪资低一些。以为可以躺一躺,结果太“躺”了,不是核心业务组,每天的开发工作感觉贼无聊。

这。。。都是围城啊(😂)!
说实话,二线城市 16k,真的很香了。我见过阿里 P7 的回二线城市,也就 20k 多一点。球友后悔也是情有可原的。
事已至此,我只能劝这位球友先安下心,既来之则安之,国企的坑位不多了,你占一个就少一个。可能选择去了外包,也会发现不如意,又开始后悔当初没有选择国企了。
至少国企稳定,五险一金都是正常缴纳的,就当带薪学习了,自己平常有时间可以多琢磨一些副业,比如说考研辅导啊、学学全栈做独立开发者啊。等技术学扎实了,再往好的公司跳。
这些年,选择国企的小伙伴是越来越多了,因为大家都想明白了,与其卷自己,真不如消费降级,别买贵的房,别买贵的车,玩好睡好就挺好(😁)。
国企面经
来,背个牛顿的名言警句吧,“如果我比别人看得更远,那是因为我站在巨人的肩膀上”。因此,如果小伙伴们也想冲国企的话,可以多看看师兄师姐们的面经,省事省心省力啊。
截止到目前,《Java 面试指南》已经收录了 600 多份优质面经,我甚至觉得它有点资治通鉴的味道了,“读史使人明智啊”,form 培根。
这次我们就以同学 1 的面经为例,来看看如果你在面试中遇到这些题目的话,该如何作答,我们不求吊打面试官,但求和面试官极限拉扯和对线(😂)。
先来看看这次的题目大纲(围绕 Java 后端四大件展开,都是非常基础的八股啊):
- sprinqmvc的流程
- String,StringBuffer,StringBuilder的区别
- mysql底层数据结构,说说B树,B+树区别
- hashmap底层数据结构,链表和红黑树的转换,hashmap的长度
- 文本文件存储是用字节流还是字符流,视频文件是用字节流和字符流
接下来,我会给出详细答案,参考星球嘉宾三分恶的面渣逆袭。
- 面渣逆袭在线版:https://javabetter.cn/sidebar/sanfene/nixi.html
- 面渣逆袭 PDF 版:https://t.zsxq.com/04FuZrRVf
内容较长,撰写硬核面经不容易,建议大家先收藏起来,我会尽量用通俗易懂+手绘图的方式,让大家不仅能背会,还能理解和掌握。总之,是时候喊出我们那句大言不惭的口号了:让天下没有难背的八股 😂
01、说说 SpringMVC 的流程吧
Spring MVC 是基于模型-视图-控制器的 Web 框架,它的工作流程也主要是围绕着 Model、View、Controller 这三个组件展开的。
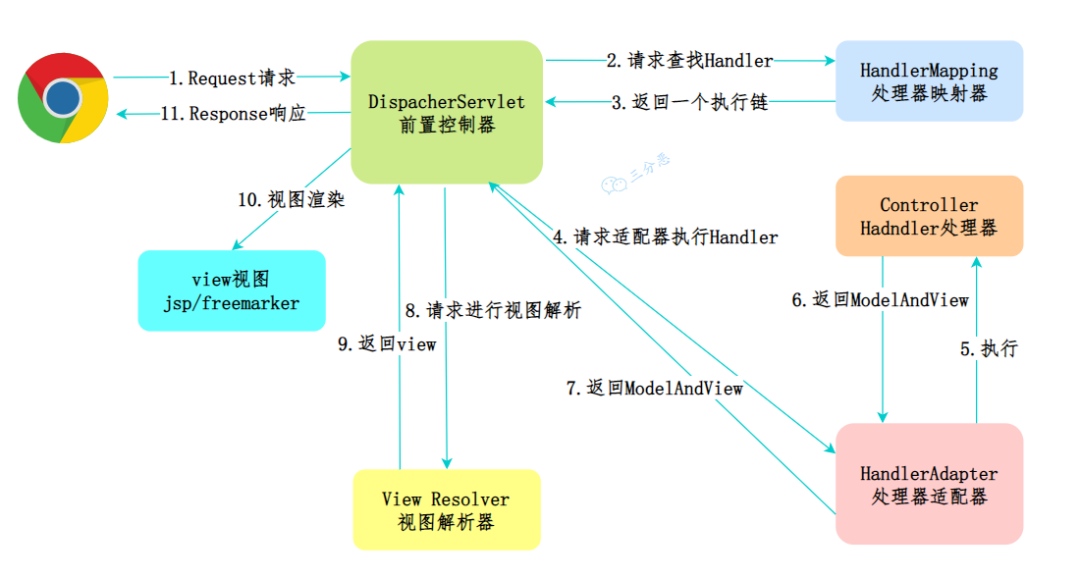 三分恶面渣逆袭:Spring MVC的工作流程
三分恶面渣逆袭:Spring MVC的工作流程①、发起请求:客户端通过 HTTP 协议向服务器发起请求。
②、前端控制器:这个请求会先到前端控制器 DispatcherServlet,它是整个流程的入口点,负责接收请求并将其分发给相应的处理器。
③、处理器映射:DispatcherServlet 调用 HandlerMapping 来确定哪个 Controller 应该处理这个请求。通常会根据请求的 URL 来确定。
④、处理器适配器:一旦找到目标 Controller,DispatcherServlet 会使用 HandlerAdapter 来调用 Controller 的处理方法。
⑤、执行处理器:Controller 处理请求,处理完后返回一个 ModelAndView 对象,其中包含模型数据和逻辑视图名。
⑥、视图解析器:DispatcherServlet 接收到 ModelAndView 后,会使用 ViewResolver 来解析视图名称,找到具体的视图页面。
⑦、渲染视图:视图使用模型数据渲染页面,生成最终的页面内容。
⑧、响应结果:DispatcherServlet 将视图结果返回给客户端。
Spring MVC 虽然整体流程复杂,但是实际开发中很简单,大部分的组件不需要我们开发人员创建和管理,真正需要处理的只有 Controller 、View 、Model。
在前后端分离的情况下,步骤 ⑥、⑦、⑧ 会略有不同,后端通常只需要处理数据,并将 JSON 格式的数据返回给前端就可以了,而不是返回完整的视图页面。
02、String,StringBuffer,StringBuilder的区别
String、StringBuilder和StringBuffer在 Java 中都是用于处理字符串的,它们之间的区别是,String 是不可变的,平常开发用得最多,当遇到大量字符串连接时,就用 StringBuilder,它不会生成很多新的对象,StringBuffer 和 StringBuilder 类似,但每个方法上都加了 synchronized 关键字,所以是线程安全的。
String
-
String类的对象是不可变的。也就是说,一旦一个String对象被创建,它所包含的字符串内容是不可改变的。 - 每次对
String对象进行修改操作(如拼接、替换等)实际上都会生成一个新的String对象,而不是修改原有对象。这可能会导致内存和性能开销,尤其是在大量字符串操作的情况下。
StringBuilder
-
StringBuilder提供了一系列的方法来进行字符串的增删改查操作,这些操作都是直接在原有字符串对象的底层数组上进行的,而不是生成新的 String 对象。 -
StringBuilder不是线程安全的。这意味着在没有外部同步的情况下,它不适用于多线程环境。 - 相比于
String,在进行频繁的字符串修改操作时,StringBuilder能提供更好的性能。Java 中的字符串连+操作其实就是通过StringBuilder实现的。
StringBuffer
StringBuffer和StringBuilder类似,但StringBuffer是线程安全的,方法前面都加了synchronized关键字。
使用场景总结
- String:适用于字符串内容不经常改变的场景。在使用字符串常量或进行少量的字符串操作时使用。
- StringBuilder:适用于单线程环境下需要频繁修改字符串内容的场景,比如在循环中拼接或修改字符串。
- StringBuffer:适用于多线程环境下需要频繁修改字符串内容的场景,保证了字符串操作的线程安全。
03、说说 MySQL 索引的底层数据结构,B 树和 B+树的区别
- 推荐阅读:终于把B树搞明白了
- 推荐阅读:一篇文章讲透MySQL为什么要用B+树实现索引
MySQL 的默认存储引擎是 InnoDB,它采用的是 B+树索引,换句话说,InnoDB 的索引是基于 B+树实现的。
那在说 B+树之前,我先说一下 B 树(B-tree)。
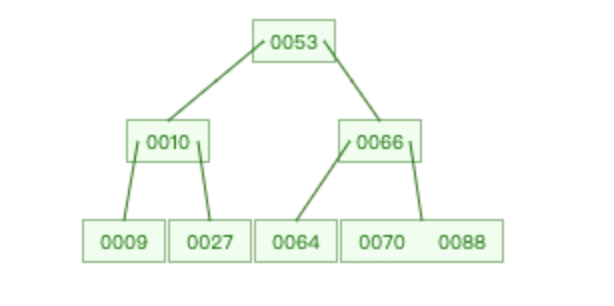
B 树是一种自平衡的多路查找树,和红黑树、二叉平衡树不同,B 树的每个节点可以有 m 个子节点,而红黑树和二叉平衡树都只有 2 个。
换句话说,红黑树、二叉平衡树是细高个,而 B 树是矮胖子。
好,继续。内存和磁盘在进行 IO 读写的时候,有一个最小的逻辑单元,叫做页(Page),页的大小一般是 4KB。
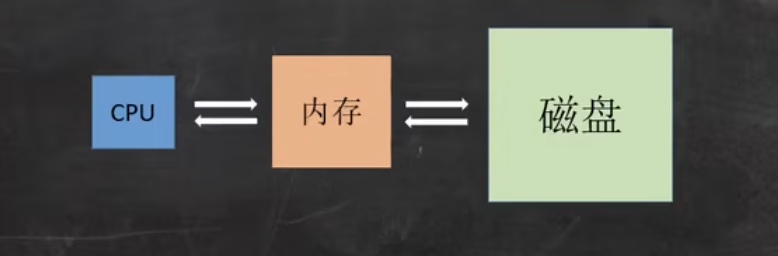
那为了提高读写效率,从磁盘往内存中读数据的时候,一次会读取至少一页的数据,比如说读取 2KB 的数据,实际上会读取 4KB 的数据;读取 5KB 的数据,实际上会读取 8KB 的数据。我们要尽量减少读写的次数。
因为读的次数越多,效率就越低。就好比我们在工地上搬砖,一次搬 10 块砖肯定比一次搬 1 块砖的效率要高,反正我每次都搬 10 块(😁)。
对于红黑树、二叉平衡树这种细高个来说,每次搬的砖少,因为力气不够嘛,那来回跑的次数就越多。
是这个道理吧,树越高,意味着查找数据时就需要更多的磁盘 IO,因为每一层都可能需要从磁盘加载新的节点。
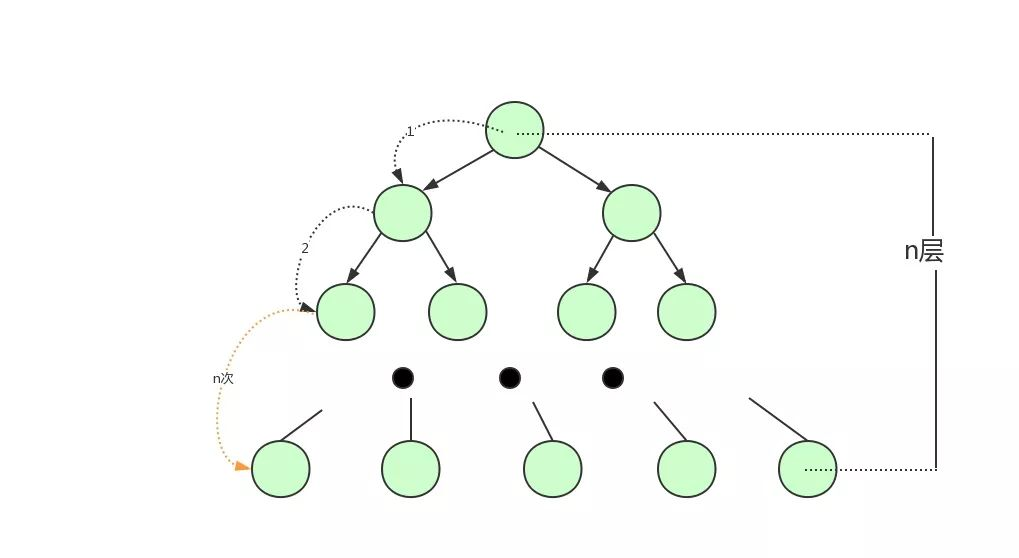 用户1260737:二叉树
用户1260737:二叉树B 树的节点大小通常与页的大小对齐,这样每次从磁盘加载一个节点时,可以正好是一个页的大小。因为 B 树的节点可以有多个子节点,可以填充更多的信息以达到一页的大小。
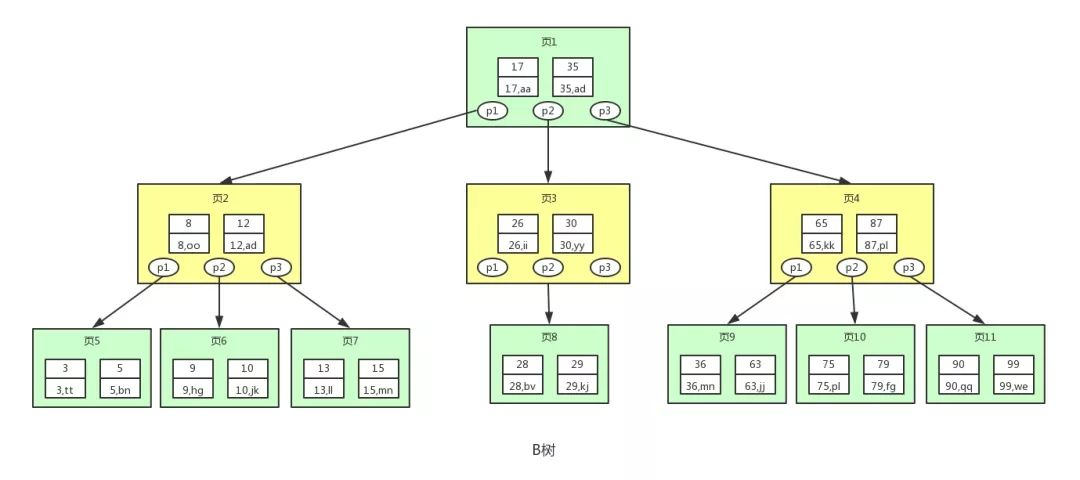 用户1260737:B 树
用户1260737:B 树B 树的一个节点通常包括三个部分:
- 键值:即表中的主键
- 指针:存储子节点的信息
- 数据:表记录中除主键外的数据
不过,正所谓“祸兮福所倚,福兮祸所伏”,正是因为 B 树的每个节点上都存了数据,就导致每个节点能存储的键值和指针变少了,因为每一页的大小是固定的,对吧?
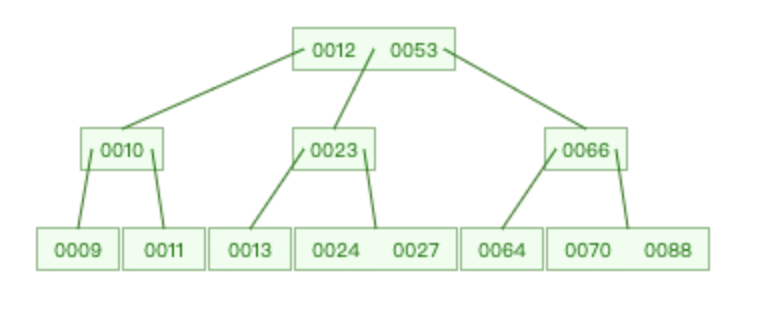
于是 B+树就来了,B+树的非叶子节点只存储键值,不存储数据,而叶子节点存储了所有的数据,并且构成了一个有序链表。
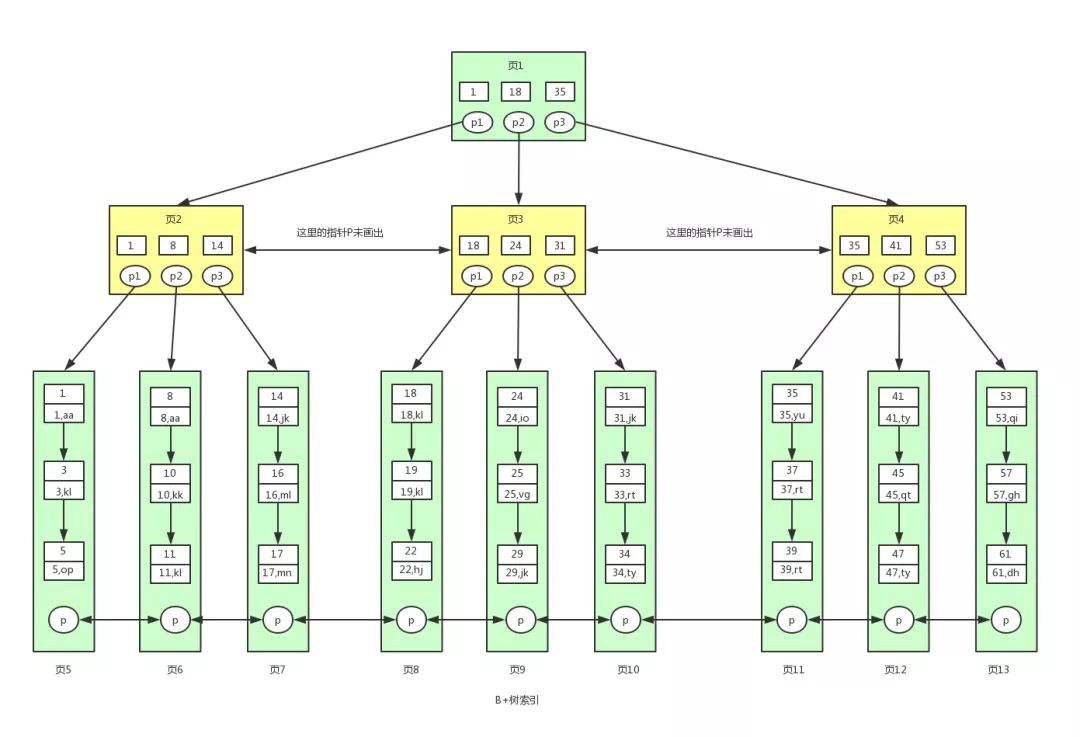 用户1260737:B+树
用户1260737:B+树这样做的好处是,非叶子节点上由于没有存储数据,就可以存储更多的键值对,树就变得更加矮胖了,于是就更有劲了,每次搬的砖也就更多了(😂)。
由此一来,查找数据进行的磁盘 IO 就更少了,查询的效率也就更高了。
再加上叶子节点构成了一个有序链表,范围查询时就可以直接通过叶子节点间的指针顺序访问整个查询范围内的所有记录,而无需对树进行多次遍历。
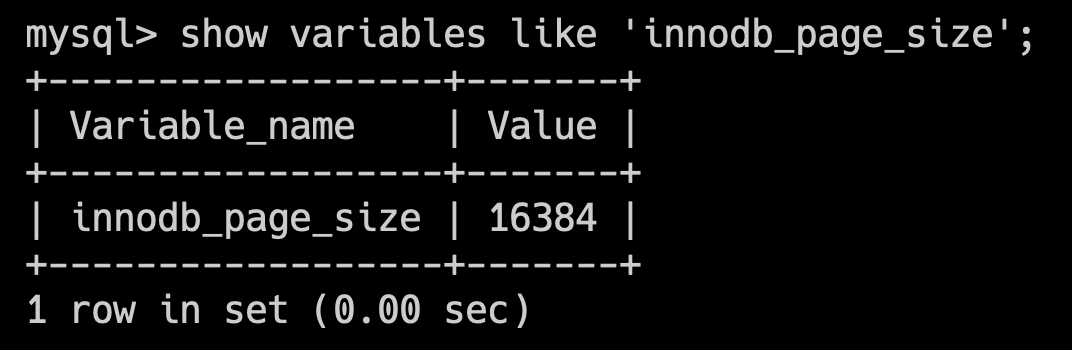
注:在 InnoDB 存储引擎中,默认的页大小是 16KB。可以通过 show variables like 'innodb_page_size'; 查看。
04、说说 HashMap 的底层数据结构,链表和红黑树的转换,HashMap 的长度
JDK 8 中 HashMap 的数据结构是数组+链表+红黑树。
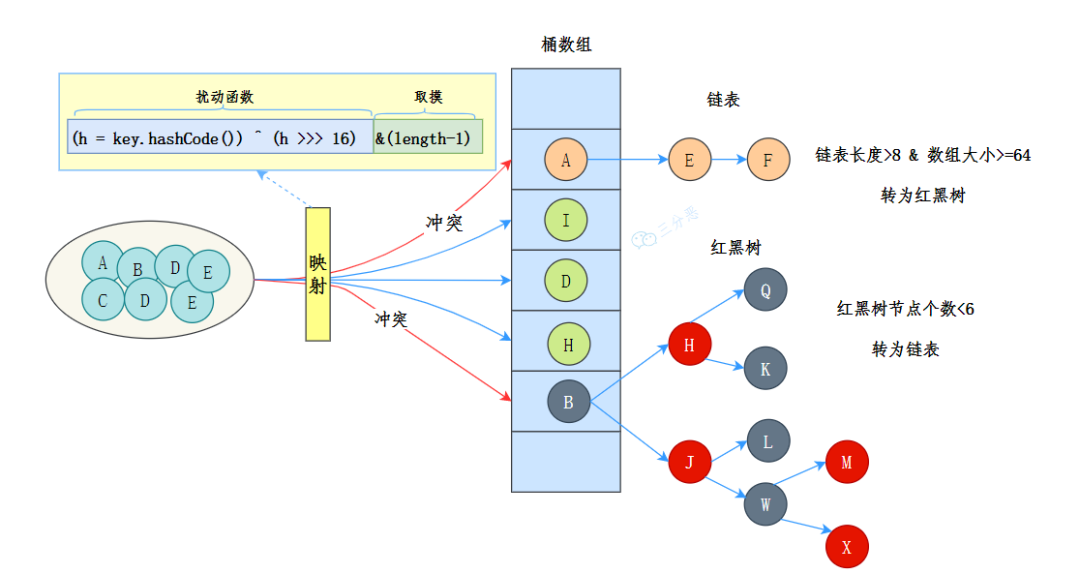 三分恶面渣逆袭:JDK 8 HashMap 数据结构示意图
三分恶面渣逆袭:JDK 8 HashMap 数据结构示意图也就是说,HashMap 的底层数据结构最主要的还是数组,当发生哈希冲突的时候就用链表来解决;不过,如果链表过长时,查询效率会比较低,于是当链表的长度超过 8 时(数组的长度大于 64),链表就会转换为红黑树。红黑树的查询效率是 O(logn),比链表的 O(n) 要快。
HashMap 的初始容量是 16,随着元素的不断添加,HashMap 的容量(也就是数组大小)可能不足,于是就需要进行扩容,阈值是capacity * loadFactor,capacity 为容量,loadFactor 为负载因子,默认为 0.75。扩容后的数组大小是原来的 2 倍,然后把原来的元素重新计算哈希值,放到新的数组中。
05、文本存储是字节流还是字符流,视频文件呢?
在计算机中,文本和视频都是按照字节存储的,只是如果是文本文件的话,我们可以通过字符流的形式去读取,这样更方面的我们进行直接处理。
比如说我们需要在一个大文本文件中查找某个字符串,可以直接通过字符流来读取判断。
处理视频文件时,通常使用字节流(如 Java 中的FileInputStream、FileOutputStream)来读取或写入数据,并且会尽量使用缓冲流(如BufferedInputStream、BufferedOutputStream)来提高读写效率。
在技术派实战项目项目中,对于文本,比如说文章和教程内容,是直接存储在数据库中的,而对于视频和图片等大文件,是存储在 OSS 中的。
因此,无论是文本文件还是视频文件,它们在物理存储层面都是以字节流的形式存在。区别在于,我们如何通过 Java 代码来解释和处理这些字节流:作为编码后的字符还是作为二进制数据。
参考链接
- 1、星球嘉宾三分恶的面渣逆袭,可微信搜索三分恶关注他的公众号:https://javabetter.cn/sidebar/sanfene/nixi.html
- 2、二哥的Java进阶之路:https://javabetter.cn
- 3、PDF 版面渣逆袭:https://t.zsxq.com/04FuZrRVf
ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 4800 多名球友加入了,如果你也需要一个良好的学习环境,戳链接 🔗 加入我们吧。这是一个编程学习指南 + Java 项目实战 + LeetCode 刷题的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。

两个置顶帖「球友必看」和「知识图谱」里已经沉淀了非常多优质的学习资源,相信能帮助你走的更快、更稳、更远。
欢迎点击左下角阅读原文了解二哥的编程星球,这可能是你学习求职路上最有含金量的一次点击。

最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。