
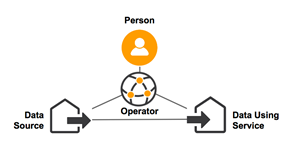
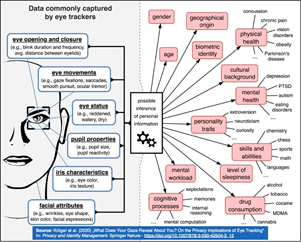
原创 | 浅议个人数据开发利用新范式



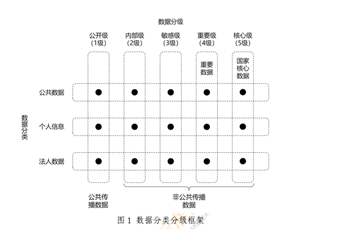
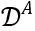 ,的数据核包括三个大类,4个等级的数据
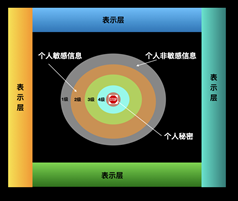
,的数据核包括三个大类,4个等级的数据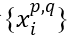 ,其中p表示类别,q表示等级;以及在表示层中数量不等的表示类
,其中p表示类别,q表示等级;以及在表示层中数量不等的表示类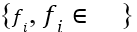 。外部应用使用的个人数据资产
。外部应用使用的个人数据资产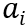 是数据核元素的一种表示,即
是数据核元素的一种表示,即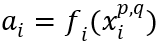 。
。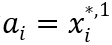 ;而对于需要隐私计算后,才能使用的数据,则
;而对于需要隐私计算后,才能使用的数据,则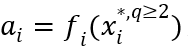 ,这里
,这里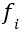 为某种隐私算法。
为某种隐私算法。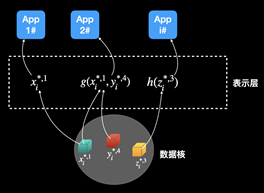
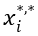 数据,经过审核
数据,经过审核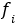 算法安全,则可以表示。但如果App想联合使用
算法安全,则可以表示。但如果App想联合使用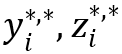 数据,则表示层识别到这种情况,设定了特别的阻止表示类
数据,则表示层识别到这种情况,设定了特别的阻止表示类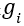 ,限制外部任何应用联合使用这两个数据。
,限制外部任何应用联合使用这两个数据。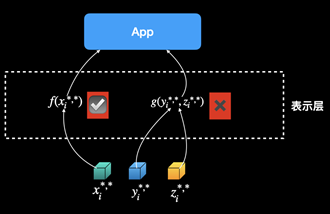
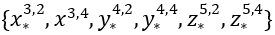 的请求。
的请求。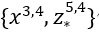 使用;
使用;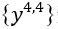 数据的算法g和f,代理人对算法进行审计或验证后,通过了。
数据的算法g和f,代理人对算法进行审计或验证后,通过了。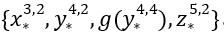 。
。评论