
【数据分析】Python数据分析学习路线个人总结
数据分析人人都有必要掌握一点,哪怕只是思维也行。下面探讨Python数据分析需要学习的知识范畴,结合自己的经历和理解,总结的学习大纲,有些章节带有解释,有些没有。当然,关于学习范畴,可能每个人的理解都不太一样,以下仅供参考。

1 数据分析思维
数据分析属于分析思维的一个子类,有专门的数据方法论。只有先养成正确的分析思维,才能使用好数据。
大多数人的思维方式都依赖于生活和经验做出直觉性的判断,最直观的体现是,在数据和业务分析中有时无从下手。
什么是好的分析思维?
用两张在网络上流传甚广的图片说明
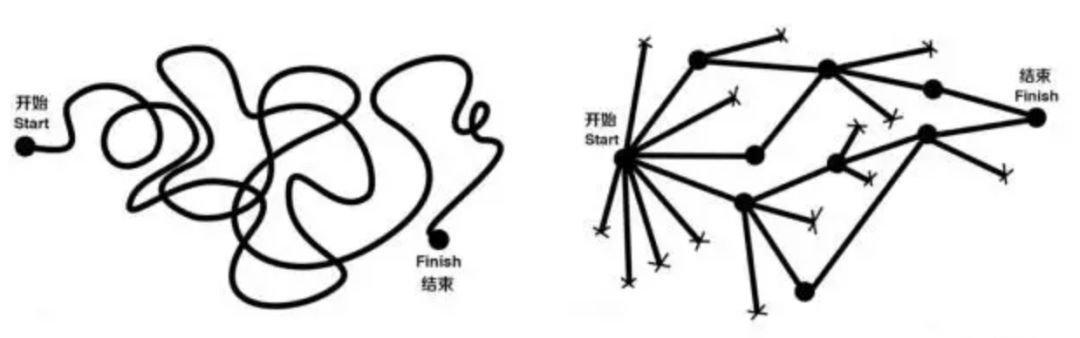
思维模式(图片来源网络)
对应以下两种思维:
我们12月的销售额度下降,我想是因为年终的影响,我问了几个销售员,他们都说年终生意不太好做,各家都收紧了财务预算,谈下的几家费用也比以前有缩水。我对他们进行了电话拜访,厂家都说经济不景气,希望我们价格方面再放宽点。
我们12月的销售额度下降,低于去年同期和今年平均值,可以排除掉大环境的因素。其中A地区下降幅度最大,间接影响了整体销售额。通过调查发现,A地区的市场因为竞争对手涌入,进行了低价销售策略。除此之外,B地区的经济发展低于预期发展,企业缩减投入。
第一个分析思维是依赖经验和直觉的线性思维,第二个分析思维则注重逻辑推导,属于结构化的思维。两种思维往往会导致不同的结果。
1.1 金子塔原理
麦肯锡思维中很重要的一条原理叫做金字塔原理,它的核心是层次化思考、逻辑化思考、结构化思考。
1.1.1 什么是金字塔?
任何一件事情都有一个中心论点,中心论点可以划分成3~7个分论点,分论点又可以由3~7个论据支撑。层层拓展,这个结构由上至下呈金字塔状。
1.1.2 结构化思维

1.1.3 核心法则:MECE
金字塔原理有一个核心法则MECE,全称 Mutually Exclusive Collectively Exhaustive,论点相互独立,尽可能多的列举。
1.1.4 假设先行
首先得有一个思考作为开始。这是什么意思?因为金字塔是从上而下,需要有一个中心论点,也就是塔尖。我们可以先提出一个问题,比如此产品的核心功能是某某功能吗?
1.2 二八法则
1.2.1 20%的分析过程决定80%的分析结果
1.2.2 抓住关键因素
以上节选的两个分析思维,都能在麦肯锡问题分析与解决技巧中找到原型,感兴趣的可查看下面这本书。
2 数据获取
2.1 大数据平台提取
各个公司都可能有自己专属的大数据平台,进入公司要首先掌握如何从这上面拿去我们需要的业务数据
2.2 第三方服务接口
合作企业或公司购买的服务接口,我们可以直接调用拿到数据。
2.3 开源公开数据集
2.4 爬虫爬取网站数据
python的常用包:
requests
json
BeautifulSoup
requests库就是用来进行网络请求的,说白了就是模拟浏览器来获取资源。
由于我们采集的是api接口,它的格式为json,所以要用到json库来解析。
BeautifulSoup是用来解析html文档的,可以很方便的帮我们获取指定div的内容。
3 数据存储
3.1 SQL分组,聚合,多表join操作
groupby, aggregate,join操作
join操作可参考 Python与算法社区 公众号
3.2 大数据平台Hadoop
大数据架构,分布式存储,详细自行查阅
3.3 Mysql
这个大家应该都不陌生
3.4 hive 拉链表
拉链表的知识大家需要好好理解体会,dp 的状态 active 和 history
4 数据清理知识
4.1 理解数据背后的业务,千万不要忽视!
我们在拿到需要分析的数据后,千万不要急于立刻开始做回归、分类、聚类分析。
第一步应该是认真理解业务数据,可以试着理解去每个特征,观察每个特征,理解它们对结果的影响程度。
然后,慢慢研究多个特征组合后,它们对结果的影响。
4.2 明确各个特征的类型
如果这些数据类型不是算法部分期望的数据类型,你还得想办法编码成想要的。比如常见的数据自增列 id 这类数据,是否有必要放到你的算法模型中,因为这类数字很可能被当作数字读入。
某些列的取值类型,虽然已经是数字了,它们的取值大小表示什么含义你也要仔细捉摸。因为,数字的相近相邻,并不一定代表另一种层面的相邻。
4.3 找出异常数据
统计中国家庭人均收入时,如果源数据里面,有王建林,马云等这种富豪,那么,人均收入的均值就会受到极大的影响,这个时候最好,绘制箱形图,看一看百分位数。
4.4 处理缺失值
现实生产环境中,拿到的数据恰好完整无损、没有任何缺失数据的概率,和买彩票中将的概率差不多。
数据缺失的原因太多了,业务系统版本迭代, 之前的某些字段不再使用了,自然它们的取值就变为 null 了;再或者,压根某些数据字段在抽样周期里,就是没有写入数据……
4.5 头疼的数据不均衡问题
理论和实际总是有差距的,理论上很多算法都存在一个基本假设,即数据分布总是均匀的。这个美好的假设,在实际中,真的存在吗?很可能不是!
算法基于不均衡的数据学习出来的模型,在实际的预测集上,效果往往差于训练集上的效果,这是因为实际数据往往分布得很不均匀,这时候就要考虑怎么解决这些问题。下面是一本数据清洗不错的书籍:
5 Python核心知识
5.1 理解Python的解释性
Python 是解释型语言,对于 Python 刚刚入门的小伙伴,可能对解释性有些疑惑。不过,没关系,我们可以通过大家已经熟悉的编译型语言,来帮助我们理解 Python 的解释性。
编译型语言,如 C++、Java,它们会在编译阶段做类型匹配检查等,因此,数据类型不匹配导致的编译错误,在编译阶段就会被检查出来,例如:
Intger a = 0;
Double b = 0.0;
a = b; // Double类型的变量 b 试图赋值给 Integer 型的变量 a, 编译报错
// 因为 Integer 类型 和 Double 类型 不存在继承关系,
// 类型不能互转
但是,Python 就不会在编译阶段做类型匹配检查,比如,Python 实现上面的几行语句,会这样写:
a = 0 # 不做任何类型声明
b = 0.
a = b # 这种赋值,Python 会有问题吗?
答案是不会的。此处就体现了 Python 的解释特性,当我们把 0 赋值给 a 时,Python 解释器会把它 a 解释为 int 型,可以使用内置函数 type(variable) 显示地检查 variable 的类型:
In [70]: type(a)
Out[70]: int
In [69]: type(b)
Out[69]: float
In [71]: a = b # 在把 float 型 b 赋值给 a 后, # a 就被解释为float
In [72]: type(a)
Out[72]: float
在把 float 型 b 赋值给 a 后, a 就被解释为 float.
5.2 list,dict,tuple,set
深拷贝和浅拷贝的区别
5.3 Python列表生成式
如何灵活使用
5.4 Python函数式编程
闭包问题
5.5 位置参数和关键字参数
如果介绍 Python 入门,不介绍函数的位置参数 ( positional argument ) 和关键字参数( keyword argument ) ,总是感觉缺少点什么,它们在 Python 函数中到处可见,理解和使用它们,为我们日后深入 Python 打下坚实的根基。
6 Excel数据分析
6.1 Excel处理10万条以内数据
6.2 以SUM函数为首的求和家族
6.3 以VLOOKUP函数为首的查找家族
6.4 以IF函数为首的逻辑函数家族
大家自行查阅学习
7 Pandas数据预处理
7.1 基于Python的向量化增强
7.2 必须掌握的传播机制
广播发生的条件
7.3 一维Series和二维DataFrame
7.4 Pandas中的20个统计学函数

7.5 Pandas三个函数搞定缺失值
7.6 1个函数搞定数据透视
8 数据建模分析
8.1 统计学基础知识
首先,入门数据分析需要必备一些统计学的基本知识,在这里我们简单列举几个入门级的重要概念。概率,平均值,中位数,众数,四分位数,期望,标准差,方差。在这些基本概念上,又衍生出的很多重要概念,比如协方差,相关系数等。
这一些列常用的统计指标,都在强大的数据分析包 Pandas 中实现了,非常方便。
8.2 统计量描述
说统计学是一种基于事实的演绎学问,它是严谨的,可以给出确切解释的。
不过,机器学习就不一样了,它是一门归纳思想的学问,比如深度学习得出的模型,你就很难解释其中的具体参数为什么取值为某某某。它的应用在于可以提供一种预测,给我们未来提供一种建设性的指导。
数据分析师需要了解机器学习的基本理论、常见的那十几种算法,这样对于我们做回归、分类、聚类分析,都是不可缺少的。
8.3 机器学习回归分析
三 个假定是?
如何建立线性回归模型?
最大似然估计求参数?
梯度下降求解优化问题?
手写不调包实现的 5 个算子
手写不调包实现的整体算法框架
8.4 基本的分类、聚类算法
8.5 特征工程提高分析精度
一般来说,特征工程大体上可以分为三个方面,一是特征构造,二是特征选择,三是特征生成。
9 数据可视化
9.1 必备的绘图原理知识
拿使用较多的 matplotlib 为列,整个图像为一个Figure 对象,在 Figure 对象中可以包含一个或多个 Axes对象,每个Axes对象都是一个拥有自己坐标系统的绘图区域。
Axes 由 xaxis, yaxis, title, data 构成,xaxis 由坐标轴的线 ,tick以及label构成。
9.2 matplotlib绘图

9.3 绘图必备100行代码
参考:关于数据分析的学习路线,我准备写一篇 2 万+的 chat
10 数据挖掘分析
10.1 正则表达式
学习正则表达式语法,主要就是学习元字符以及它们在正则表达式上下文中的行为。常见的元字符比如普通字符、标准字符、特殊字符、限定字符(又叫量词)、定位字符(也叫边界字符)。
10.2 决策树
10.3 贝叶斯方法
10.4 集成学习方法
10.5 NLP
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 机器学习在线手册 深度学习笔记专辑 《统计学习方法》的代码复现专辑 AI基础下载 本站qq群955171419,加入微信群请扫码: