
使用 PyTorch 检测眼部疾病
重磅干货,第一时间送达
深度学习是基于人工神经网络(ANN)的机器学习方法大家庭的一部分。深度学习是当今普遍存在的一种学习方式,它被广泛应用于从图像分类到语音识别的各个领域。在这篇文章中,我将向你展示如何构建一个简单的神经网络,用PyTorch从视网膜光学相干断层扫描图像中检测不同的眼部疾病。
数据集
OCT 是一种成像技术,用于捕捉活体患者视网膜的高分辨率横截面。每年大约要进行3000万次 OCT 扫描,这些图像的分析和解释需要大量的时间。
这个数据集来自 kaggle,它被分成3个文件夹(train,test,val) ,每个图像类别包含子文件夹: 脉络膜新血管生成(CNV) ,糖尿病性黄斑水肿(DME) ,早期 AMD (DRUSEN)中出现的多个视网膜,以及保留中心凹轮廓的正常视网膜,没有任何视网膜液体/水肿(NORMAL)。
加载和预处理图像
首先,我们要加载所有的库,并指定函数,我们将用来加载我们的数据和模型在 GPU 上。
import torchimport torch.nn as nnimport torch.optim as optimfrom torch.optim import lr_schedulerfrom torch.utils.data import DataLoaderimport torch.nn.functional as Ffrom PIL import Imageimport torchvisionimport torchvision.models as modelsfrom torchvision import datasets, modelsfrom torchvision.utils import make_gridimport torchvision.transforms as ttimport timeimport osfrom itertools import productfrom tqdm.notebook import tqdmfrom tqdm import trangeimport numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as pltimport matplotlib.image as mpimgimport matplotlib.lines as mlinesfrom matplotlib.ticker import MaxNLocator, FormatStrFormatterplt.style.use(['seaborn-dark'])mpl.rcParams.update({"axes.grid" : True,"grid.color": "grey",'grid.linestyle':":",})from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score, classification_report, ConfusionMatrixDisplay, confusion_matrix
def to_device(data, device):"""Move tensor(s) to chosen device"""if isinstance(data, (list,tuple)):return [to_device(x, device) for x in data]#print(f"Moved to {device}")return data.to(device, non_blocking=True)#Pick GPU if available, else CPUif torch.cuda.is_available():device = torch.device('cuda')else:device = torch.device('cpu')print(device)
cuda
然后我们将解析 train 文件夹中的所有图像,以创建包含训练图像的每个通道的平均值和标准差的两个矢量。我们要利用这些数据对图像进行normalize操作。
def get_stats_channels(path="./", batch_size=50):"""Create two tuples with mean and std for each RGB channel of the dataset"""data = datasets.ImageFolder(path, tt.Compose([tt.CenterCrop(490),tt.ToTensor()]))loader = DataLoader(data, batch_size, num_workers=4, pin_memory=True)nimages = 0mean = 0.std = 0.for batch, _ in tqdm(loader):# Rearrange batch to be the shape of [B, C, W * H]batch = batch.view(batch.size(0), batch.size(1), -1)# Update total number of imagesnimages += batch.size(0)# Compute mean and std heremean += batch.mean(2).sum(0)std += batch.std(2).sum(0)mean /= nimagesstd /= nimagesreturn mean, std#normalization_stats = get_stats_channels(data_dir+"/"+"train")normalization_stats = (0.1899, 0.1899, 0.1899), (0.1912, 0.1912, 0.1912)#normalization_stats = (0.485, 0, 0), (0.229, 1, 1)
现在我们使用 pytorch 加载数据。每幅图像都是中心像素,大小为490x490像素(为了在每幅图像之间保持统一大小) ,然后转换为张量,再进行规范化。
data_transforms = {'Train': tt.Compose([tt.CenterCrop(490),tt.ToTensor(), tt.Normalize(*normalization_stats)]),'Valid': tt.Compose([tt.CenterCrop(490),tt.ToTensor(), tt.Normalize(*normalization_stats)]),'Test': tt.Compose([tt.CenterCrop(490),tt.ToTensor(), tt.Normalize(*normalization_stats)])}train_data = datasets.ImageFolder(data_dir+"/"+"train/",transform=data_transforms["Train"])valid_data = datasets.ImageFolder(data_dir+"/"+"val/",transform=data_transforms["Valid"])test_data = datasets.ImageFolder(data_dir+"/"+"test/",transform=data_transforms["Test"])
可视化数据
现在我们已经加载并预处理了数据,我们可以进行一些数据探索。
CNV = Image.open('../input/kermany2018/OCT2017 /train/CNV/CNV-1016042-1.jpeg')DME = Image.open('../input/kermany2018/OCT2017 /train/DME/DME-1072015-1.jpeg')DRUSEN = Image.open('../input/kermany2018/OCT2017 /train/DRUSEN/DRUSEN-1001666-1.jpeg')NORMAL = Image.open('../input/kermany2018/OCT2017 /train/NORMAL/NORMAL-1001666-1.jpeg')fig, (ax1, ax2) = plt.subplots(nrows=2, ncols=4, figsize=(10,10))ax1[0].imshow(CNV)ax1[0].set(title="CNV")ax1[0].axis('off')ax1[1].imshow(DME)ax1[1].set(title="DME")ax1[1].axis('off')CNVtransform = data_transforms["Train"](CNV.convert('RGB')).permute(1, 2, 0)ax1[2].imshow(CNVtransform)ax1[2].set(title="DME transformed")ax1[2].axis('off')DMEtransform = data_transforms["Train"](DME.convert('RGB')).permute(1, 2, 0)ax1[3].imshow(DMEtransform)ax1[3].set(title="DME transformed")ax1[3].axis('off')ax2[0].imshow(DRUSEN)ax2[0].set(title="DRUSEN")ax2[0].axis('off')ax2[1].imshow(NORMAL)ax2[1].set(title="NORMAL")ax2[1].axis('off')DRUSENtransform = data_transforms["Train"](DRUSEN.convert('RGB')).permute(1, 2, 0)ax2[2].imshow(DRUSENtransform)ax2[2].set(title="DRUSEN transformed")ax2[2].axis('off')NORMALtransform = data_transforms["Train"](NORMAL.convert('RGB')).permute(1, 2, 0)ax2[3].imshow(NORMALtransform)ax2[3].set(title="NORMAL transformed")ax2[3].axis('off')plt.tight_layout()plt.show()
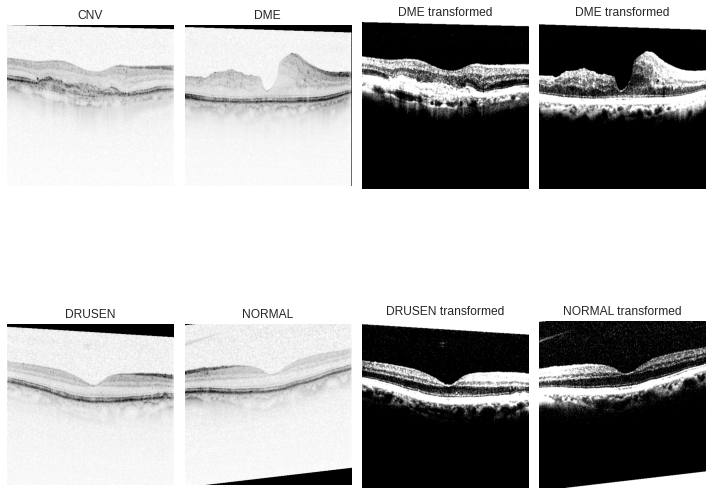
在左边我们可以看到原始图像,在右边我们看到经过预处理的图像。标准化将所有通道的平均值都集中在零点附近,这种操作有助于网络更快地学习,因为梯度对每个通道的作用是一致的,并有助于在图像中产生有意义的特征。
fig, (ax1, ax2, ax3) = plt.subplots(nrows=3, ncols=1,figsize=(5,8), sharex=True)train_labels.plot(ax=ax1, kind="bar")ax1.set(title="Train label")valid_labels.plot(ax=ax2, kind="bar")ax2.set(title="Validation labels")test_labels.plot(ax=ax3, kind="bar")ax3.set(title="Test labels")plt.show()

我们绘制训练集标签、验证集标签以及测试集标签的分布图便于检查标签不平衡。我们可以看到,验证集和测试集中的标签分布是均匀的,而训练集中的标签分布是不平衡的。有不同的方法来处理不平衡的数据集,这里我们尝试了抽样处理。
加载数据
class DeviceDataLoader():"""Wrap a dataloader to move data to a device"""def __init__(self, dl, device):self.dl = dlself.device = devicedef __iter__(self):"""Yield a batch of data after moving it to device"""for b in self.dl:yield to_device(b, self.device)def __len__(self):"""Number of batches"""return len(self.dl)
batch_size = 30train_dl = DataLoader(train_data, batch_size=batch_size,sampler=ImbalancedDatasetSampler(train_data, num_samples=4000),pin_memory=True, num_workers=4)valid_dl =DataLoader(valid_data, batch_size=batch_size,shuffle=True, pin_memory=True, num_workers=4)test_dl = DataLoader(test_data, batch_size=batch_size, pin_memory=True, num_workers=4)
train_dl = DeviceDataLoader(train_dl, device)valid_dl = DeviceDataLoader(valid_dl, device)test_dl = DeviceDataLoader(test_dl, device)
这里我们使用自定义加载器在 GPU 上加载数据。由于 GPU 的内存不足以容纳数以千计的图像,因此需要批量大小将数据以较小的批量输入模型。训练数据集并不是整体加载的,我们使用了一个自定义的采样器来对数据进行子采样(为了使每个标签的分布更加均匀) ,并将训练数据总数减少到4000个图像,以加快计算时间的速度。
模型
#================================================================================class TransferResnet(nn.Module):"""Feedfoward neural network with 1 hidden layer"""def __init__(self, classes=4):super().__init__()# Use a pretrained modelself.network = models.resnet34(pretrained=True)#self.network.avgpool = AdaptiveConcatPool2d()# Replace last layernum_ftrs = self.network.fc.in_featuresself.network.fc = nn.Sequential(nn.Linear(num_ftrs, 128),nn.ReLU(),nn.Dropout(0.50),nn.Linear(128,classes))def forward(self, xb):out = self.network(xb)return outdef feed_to_network(self, batch):images, labels = batchout = self(images)loss = F.cross_entropy(out, labels)#Don't pass the softmax to the cross entropyout = F.softmax(out, dim=1)return loss, out
model = TransferResnet()model = to_device(model, device)model
部分结果
最后我们创建了我们的模型,给出了我们相对较小的样本量(并且为了加快训练时间) ,我们使用了迁移学习和 ResNet 的预训练模型,并删除了最终的全连接层,并添加了两个线性层和一个 ReLu 激活函数。因为我们正在做一个分类任务,我们的损失函数将是交叉熵损失。
训练模型
def get_scores(labels, prediction, loss=None):"Return classification scores"accuracy = accuracy_score(labels, prediction)f1 = f1_score(labels, prediction,average='weighted', zero_division=0)precision = precision_score(labels, prediction,average='weighted', zero_division=0)recall = recall_score(labels, prediction,average='weighted', zero_division=0)if loss:return [accuracy, f1, precision, recall, loss]else:return [accuracy, f1, precision, recall]def get_predictions(model, loader):"""This function takes a model and a data loader,returns the list of losses, the predictions and the labels"""model.eval()with torch.no_grad():losses = []predictions = []labels = []for batch in loader:loss, out = model.feed_to_network(batch)predictions += torch.argmax(out, dim=1).tolist()labels += batch[1].tolist()losses.append(loss.item())return labels, predictions, sum(losses)/len(losses)
def new_fit(model, train_loader, val_loader,optimizer=torch.optim.Adam, lr=1e-2, epochs =10):def get_lr(optimizer):for param_group in optimizer.param_groups:return param_group['lr']train_metrics_df = pd.DataFrame(columns=['accuracy', 'f1', 'precision','recall', 'loss'])valid_metrics_df = pd.DataFrame(columns=['accuracy', 'f1', 'precision','recall', 'loss'])optimizer = optimizer([{"params": model.network.fc.parameters(), "lr": lr},{"params": model.network.layer4.parameters(), "lr": lr/2.5},{"params": model.network.layer3.parameters(), "lr": lr/5},{"params": model.network.layer2.parameters(), "lr": lr/10},{"params": model.network.layer1.parameters(), "lr": lr/100},], lr, weight_decay=1e-5)sched = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=3)lr_list = []for epoch in range(epochs):model.train()lr_list.append(get_lr(optimizer))train_label = []train_prediction = []train_losses = []for batch in tqdm(train_loader):optimizer.zero_grad()loss, out = model.feed_to_network(batch)loss.backward()optimizer.step()#momentum_list.append(get_parameter(optimizer, parameter="momentum"))#lr_list.append(get_parameter(optimizer, parameter="lr"))#Extract labels, predictions and loss of the training settrain_prediction += torch.argmax(out, dim=1).tolist()train_label += batch[1].tolist()train_losses.append(loss.item())#Evaluation phaseval_labels, val_predictions, val_loss = get_predictions(model, val_loader)train_metrics_df.loc[epoch] = get_scores(train_label,train_prediction,loss=sum(train_losses)/len(train_losses))valid_metrics_df.loc[epoch] = get_scores(val_labels, val_predictions,loss=val_loss)print_epoch_trainLoss = train_metrics_df.iloc[epoch]["loss"]print_epoch_validLoss = valid_metrics_df.iloc[epoch]["loss"]print_epoch_validAccu = valid_metrics_df.iloc[epoch]["accuracy"]print_epoch_trainAccu = train_metrics_df.iloc[epoch]["accuracy"]sched.step(print_epoch_trainLoss)print(f"\t\tEpoch {epoch+1}\t\n"f"Train loss:{train_losses[-1]:.4f}\tValid loss:{print_epoch_validLoss:.4f}\n"f"Train acc :{print_epoch_trainAccu*100:.2f}\tValid acc :{print_epoch_validAccu*100:.2f}")return train_metrics_df, valid_metrics_df, lr_list
一个经过训练的模型是有用的,因为它的层已经被训练来提取特征(比如特定的形状或线条,等等)。因此,在训练过程中,网络卷积部分的权重和偏差不会发生很大变化。另一方面,我们创建的全连接层是用随机权重初始化的。解决这个问题的一个方法是冻结网络中所有预先训练的部分,只训练最后的全连接层,然后解冻所有的网络,以较低的学习率训练它。我们采用了另一种技术:我们对网络的每个部分使用不同的学习速度。更深的网络层使用更低的学习率。通过这种方法,我们训练了分类器,并对预训练的网络进行了微调,而无需对其进行两次训练。
作为一个例子,我们使用 Adam 优化器对这个网络进行了15个 epoch 的训练,学习率为0.004,并使用了一个学习率调度器。
计划学习率是非常有用的,因为高学习速率有助于网络学习更快,但他们有可能错过最小的损失函数。另一方面,低学习率可能太慢了。

我们使用了一个调度器,降低了学习率一旦它停止,以减少损失函数。我们绘制每个 epoch 的损失函数、学习速度和不同的分类指标:
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']fig = plt.figure(constrained_layout=True, figsize=(8,5))gs = fig.add_gridspec(nrows=4, ncols=2)fig_ax1 = fig.add_subplot(gs[0, :])fig_ax1.plot(train_metrics_df["loss"], label="train")fig_ax1.plot(valid_metrics_df["loss"])fig_ax1.xaxis.set_major_locator(MaxNLocator(integer=True))fig_ax1.set(title='Loss')fig_ax1.set_ylim(bottom=0)fig_ax2 = fig.add_subplot(gs[1, 0])fig_ax2.plot(train_metrics_df["accuracy"], label="train")fig_ax2.plot(valid_metrics_df["accuracy"], label="validation")fig_ax2.xaxis.set_major_locator(MaxNLocator(integer=True))fig_ax2.set(title="Accuracy", ylim=(0,1))fig_ax3 = fig.add_subplot(gs[1, 1])fig_ax3.plot(train_metrics_df["f1"], label="train")fig_ax3.plot(valid_metrics_df["f1"], label="validation")fig_ax3.xaxis.set_major_locator(MaxNLocator(integer=True))fig_ax3.set(title="F1", ylim=(0,1))fig_ax4 = fig.add_subplot(gs[2, 0])fig_ax4.plot(train_metrics_df["precision"], label="train")fig_ax4.plot(valid_metrics_df["precision"], label="validation")fig_ax4.xaxis.set_major_locator(MaxNLocator(integer=True))fig_ax4.set(title="Rrecision", ylim=(0,1))fig_ax5 = fig.add_subplot(gs[2, 1])fig_ax5.plot(train_metrics_df["recall"], label="train")fig_ax5.plot(valid_metrics_df["recall"], label="validation")fig_ax5.xaxis.set_major_locator(MaxNLocator(integer=True))fig_ax5.set(title="Recall", ylim=(0,1))fig_ax6 = fig.add_subplot(gs[3, :])fig_ax6.plot(lr_list, label="learning rate", color=colors[2])fig_ax6.xaxis.set_major_locator(MaxNLocator(integer=True))fig_ax6.set(title='Learning Rate')fig_ax6.set_ylim(bottom=0)dummytrain = mlines.Line2D([], [], color=colors[0], label='Train set')dummyvalid = mlines.Line2D([], [], color=colors[1], label='Validation set')dummyrate = mlines.Line2D([], [], color=colors[2], label='Learning Rate')fig.legend([dummytrain, dummyvalid,dummyrate],["Training set", "Validation set", "Learning Rate"],bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)plt.show()
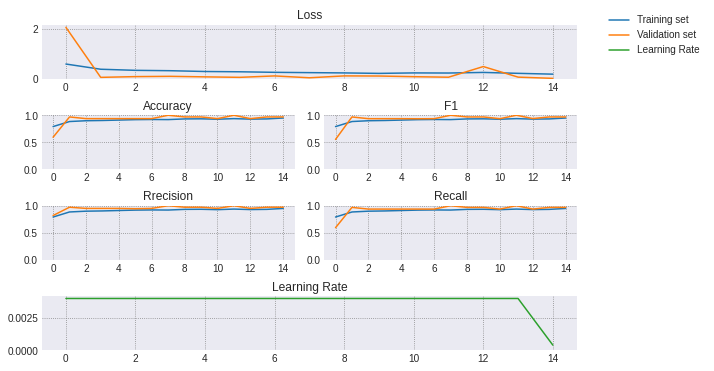
所有的指标在短短几个时期内就达到了0.9,在训练结束时验证的准确率达到了93.75% ,对于一个简单的网络来说,这已经不错了!
测试模型
最后,我们使用测试集来测试模型。首先让我们看看相关矩阵:
cm = confusion_matrix(test_labels, test_predictions, normalize="pred")fig, ax = plt.subplots(figsize=(8,6))im = ax.imshow(cm, cmap="viridis")fig.colorbar(im)ax.set(xticks=np.arange(len(labels)),yticks=np.arange(len(labels)),xticklabels=labels,yticklabels=labels,ylabel="True labels",xlabel="Predicted labels")# Rotate the tick labels and set their alignment.plt.setp(ax.get_xticklabels(), rotation=45, ha="right",rotation_mode="anchor")# Loop over data dimensions and create text annotations.cmap_min, cmap_max = im.cmap(0), im.cmap(256)for i,j in product(range(len(labels)),range(len(labels))):color = cmap_max if cm[i,j] < cm.max()/4 else cmap_mintext = ax.text(j, i, round(cm[i, j],2),ha="center", va="center", color=color)ax.set_title("Confusion matrix of the test set")fig.tight_layout()plt.show()
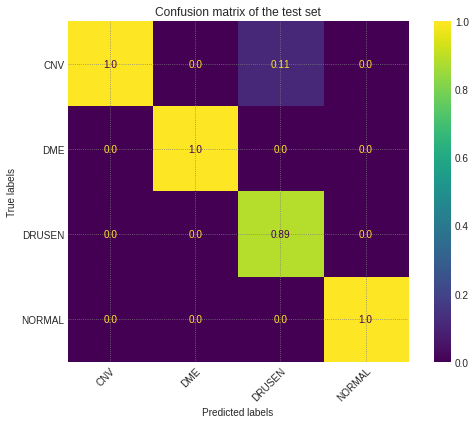
这几乎是完美的!该模型能够正确地对几乎所有的标签进行分类,其中11% 的 DRUSEN 图像混淆为 CNV。现在让我们来看看测试集的度量:
labels = ['CNV', 'DME', 'DRUSEN', 'NORMAL']test_labels, test_predictions, _ = get_predictions(model, valid_dl)print(classification_report(test_labels, test_predictions,zero_division = 0, target_names=labels))

最后,测试集上的所有度量值都是0.97,甚至高于验证集!
这个网络表现很好,但是它还可以改进:
更多的 epoch :由于时间限制,我们只训练了15个 epoch,使用更多的 epoch 可以极大地提高准确性;
早期停止:使用更多的时期,我们可以避免数据过拟合的风险和增加泛化误差,早期停止训练,避免为了过度拟合测试集引起的验证集的loss爆炸;
改变参数:学习速度,权重衰减等。所有的参数均可以调整,以提高准确性;
使用数据增强:增加随机旋转、裁剪等等可以帮助模型更好地泛化。