
【论文解读】无需额外数据、Tricks、架构调整,CMU开源首个将ResNet50精度提升至80%+新方法
极市导读
该文是CMU的Zhiqiang Shen提出的一种提升标准ResNet50精度的方法,它应该是首个将ResNet50的Top1精度刷到80%+的(无需额外数据,无需其他tricks,无需网络架构调整)。该文对于研究知识蒸馏的同学应该是有不少可参考的价值,尤其是里面提到的几点讨论与结论,值得深思。

paper: https://arxiv.org/abs/2009.08453
code: https://github.com/szq0214/MEAL-V2
Abstract
该文提出一种简单而有效的方法,无需任何tricks,它可以将标准ResNet50的Top1精度提升到80%+。该方法是基于作者之前MEAL(通过判别方式进行知识蒸馏集成)改进而来,作者对MEAL进行了以下两点改进:
(1) 仅在最后的输出部分使用相似性损失与判别损失;
(2) 采用所有老师模型的平均概率作为更强的监督信息进行蒸馏。
该文提到一个非常重要的发现:在蒸馏阶段不应当使用one-hot方式的标签编码。这样一种简单的方案可以取得SOTA性能,且并未用到以下几种常见涨点tricks:(1)类似ResNet50-D的架构改进;(2)额外训练数据;(3) AutoAug、RandAug等;(4)cosine学习率机制;(5)mixup/cutmix数据增广策略;(6) 标签平滑。
在ImageNet数据集上,本文所提方法取得了80.67%的Top1精度(single crop@224),以极大的优势超越其他同架构方案。该方法可以视作采用知识蒸馏对ResNet50涨点的一个新的基准,该文可谓首个在不改变网路架构、无需额外训练数据的前提下将ResNet提升到超过80%Top1精度的方法。
Method
提升模型精度的trick一般包含这样几点:(1) 更好的数据增广方法,比如Mixup、Cutmix、AutoAug、RandAug、Fix resolution discrepancy等;(2) 网络架构的调整,比如SENet、ResNeSt之于ResNet;(3)更好的学习率调整机制,比如cosine;(4)额外的训练数据;(5) 知识蒸馏。而本文则聚焦于采用知识蒸馏(teacher-student)的方法提升标准ResNet50的精度。该文所用方法具有这样几点优势(与已有方法的对比见下表):
No Architecture Modification; No outsize training data beyond ImageNet; No cosine learning rate No extra data augmentation, like mixup, autoaug; No label Smoothing.
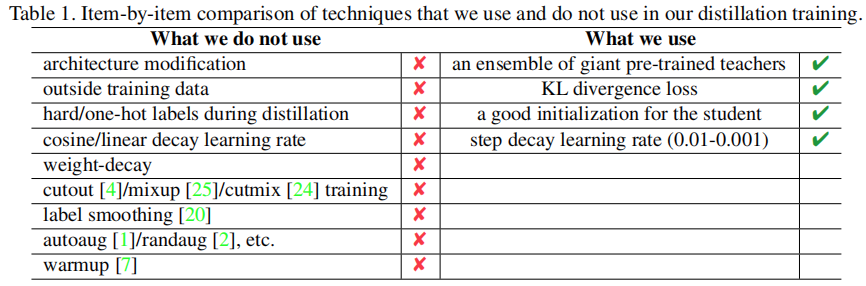
与此同时,该文还得到这样一个发现:The one-hot/hard label is not neccssary and could not be used in the distillation process,该发现对于知识蒸馏尤为重要。
接下来,我们将从Teachers Ensemble, KL-divergence, Discriminator三个方面进行该文方法的介绍。
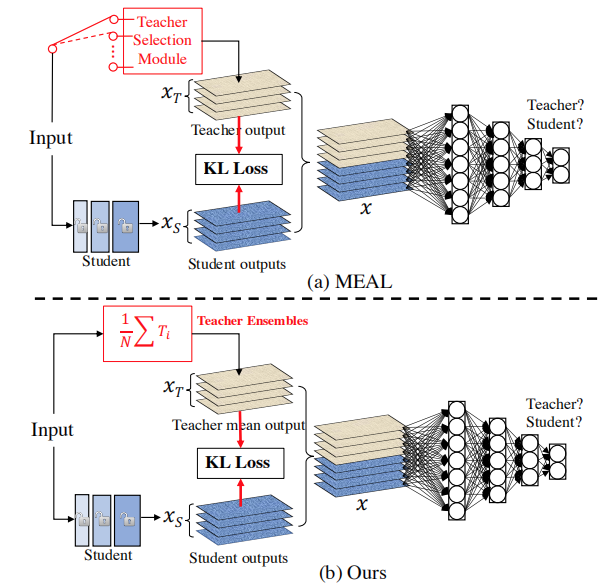
Teachers Ensemble
在该文的知识蒸馏框架中,采用老师模型集成的方式提升更精度的预测并用于指导学生模型训练。上图给出了MEALV1与MEALV2的两者的区别与联系,在训练阶段,在每次迭代开始前MEALV1通过老师选择模块选择用于蒸馏的老师模型;而该文则是采用多个老师模型的平均预测概率作为监督信息。那么,这里所提到的Teachers Ensemble可以描述如下:
其中,分别表示输入、老师模型个数,以及老师模型的预测概率。
KL-divergence
KL散度是知识蒸馏领域最常用的一种损失,它用度量两个概率分布之间的相似性。在该文中,KL散度用于度量学生模型的预测概率与前述老师模型的平均预测概率之间的相似性。KL散度损失函数可以描述如下:
当然,各位同学不用花费精力去研究上述公式,目前各大深度学习框架中均有该损失函数的实现,直接调用就好。除了KL散度损失外,另一个常用的损失函数就是交叉熵损失,定义如下:
各位有没有发现,截止到目前上述所提到的信息基本上就是知识蒸馏最基本的一些信息了。除了Teachers Ensemble外,该文的创新点在哪里呢?
Discriminator
判别器是一个二分类器,它用于判别输入特征来自老师模型还是来自学生模型。它由sigmoid与二值交叉熵损失构成,定义如下:
作者定义了一个sigmoid函数用于模拟老师-学生的概率,定义如下:
其中表示一个三层感知器,即三个全连接, 表示logistic函数。该文采用最后未经softmax处理的输出作为该判别器的输入。
考虑到该文采用的是Teachers Ensemble方式,不方便得到中间特征输出;同时为了使整个框架更简洁,作者仅仅采用了相似损失与判别损失用于蒸馏。作者通过实验表明:老师集成模型的的最后一层输出足以蒸馏一个强学生模型。
Experiments
训练数据:ImageNet,即ILSVRC2012训练集,包含1000个类别,120W数据;测试集:ImageNet,包含5W数据。
在训练过程中,作者采用了最基本的数据增广:RandomResizedCrop、RandomHorizontalFlip,在测试阶段采用了CenterCrop。8GPU用训练,batch=512,优化器为SGD,未采用weight decay,StepLR,初始学习率为0.01,合计训练180epoch,在100epoch时学习率x0.1。
当学生模型的输入为时,老师模型为senet154,resnet152_vl;当学生模型的输入为时,老师模型为efficientnet_b4, efficientnet_b4_ns。注:预训练模型源自rwightman大神(https://github.com/rwightman/pytorch-image-models)。
在实验方面,作者分别以ResNet50、MobileNetV3为基准进行了实验对比,那么接下来就分别进行相关结果的介绍。
ResNet50
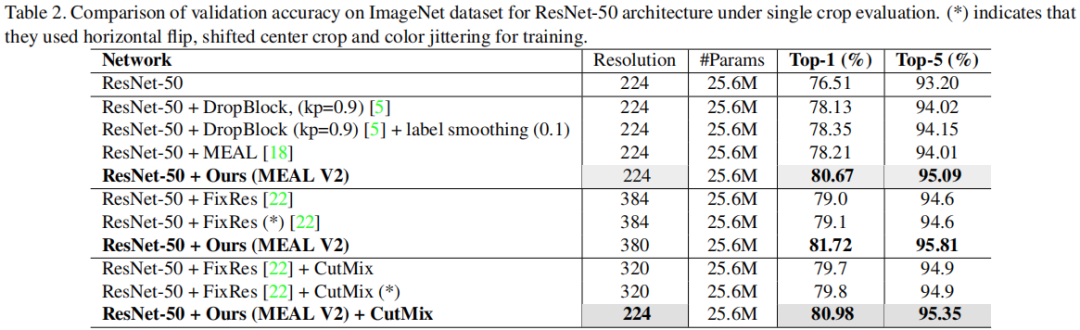
上表给出了所提方法在ResNet50上的性能对比。当输入为时,该方法取得了80.67%的Top1精度,以2.46%的指标优于MEAL;甚至,所提方法还超越了ResNeSt50-fast的80.64%(需要修改网路结构,同时用到了诸多tricks);当输入增大到后,所提方法取得了81.72%的Top1精度,以2.62%优于FixRes的79.1%(训练224,测试384)。
作者同时还探索了所提方法与其他数据增广的互补性,当引入CutMix后,模型的性能还可以进一步提升达到80.98%@224。尽管该提升并不大,但这意味着ResNet50还有继续提升的空间。
更有意思的是,所提学生模型的精度非常接近两个老师模型的精度(81.22%/95.36%, 81.01%/95.42%)了。
MobileNetV3
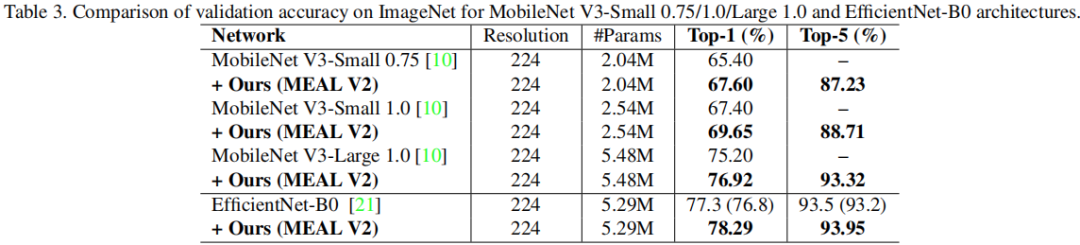
上表给出了所提方法在MobileNetV3与EfficientNetB0上的性能对比。可以看到:MobileNetV3-Samall-0.75的性能提升了2.20%,MobileNetV3-Small-1.0的性能提升了2.25%, MobileNetV3-Large-1.0的性能提升了1.72%, EfficietnNet-B0的性能提升了1.49%(76.8/93.2源自EfficientNet原文,而77.3、93.5源自rwightman大神)。在轻量型模型上取得这样的性能提升着实令人惊讶,要知道,该文方法不会导致推理的任何调整。
Discussion
接下来就是“填坑”时间了,对前文的几个“坑”来进行简单的分析与讨论。
Why is the hard/one-hot label not necessary in knowledge distillation?
One-hot标签是人工标注的,存在不正确或标注信息不全。ImageNet数据中有不少图像包含不止一个目标,但仅赋予了one-hot标签,难以很好的表示图像的内容信息。而更精度的老师模型足以提供高质量的内容信息并更好的引导老师模型的优化方向。
How does the discriminator help the optimization?
判别器用于防止学生模型在训练数据上过拟合,同时可以起到正则作用。
How about the generalization ability of our method on large students?
作者同时还尝试了一些大模型(比如ResNeXt-101 32x8d)同时作为老师和学生模型,这意味着老师模型与学生模型具有相近的容量,正如所期望的,提升不如小模型,但仍可以看到一些提升。一般而言,源自老师模型的软监督信息要比人工标准信息更优化。总而言之一句话:更强的老师模型可以蒸馏出更强的学生模型。
Is there still room to improve the performance of vanilla ResNet50?
答案是肯定的。替换更多、更强的老师模型还可以进一步提升学生模型的精度,同时引入其他tricks可能同样有益(作者没有去尝试哦,资源约束,深表同感,哈哈)。作者提到:当前的老师-学生模型选择是从训练效率、计算资源等方面均衡的选择,该文的目的是验证方法的有效性,而非更高精度(看到这里,无言以对)。
全文到此结束,对该文感兴趣的同学建议去查看一下原文的分析。
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):