
CVPR2021全新Backbone | ReXNet在CV全任务以超低FLOPs达到SOTA水平(文末下载论文和源码)

本文主要是针对Representational Bottleneck问题进行的研究,并提出了一套可以显著改善模型性能的设计原则。仅仅对Baseline网络进行微小的改变,可以在ImageNet分类、COCO检测以及迁移学习上实现显著的性能提升。
1 简介
本文主要是针对Representational Bottleneck问题进行的讨论,并提出了一套可以显著改善模型性能的设计原则。本文中作者认为在传统网络的设计的中可能会存在Representational Bottleneck问题,并且该问题会导致模型性能的降低。
为了研究Representational Bottleneck问题,本文作者研究了由上万个随机网络产生的特征矩阵的秩。为了设计更精确的网络结构,作者进一步研究了整个层的Channel配置。并在此基础上提出了简单而有效的设计原则来缓解Representational Bottleneck问题。
通过遵循这一原则对Baseline网络进行微小的改变,可以在ImageNet分类上实现显著的性能改进。此外,在COCO目标检测结果和迁移学习结果的改善也为该方法用来解决Representational Bottleneck问题和提高性能提供了依据。
本文主要贡献
通过数学和实验研究探讨网络中出现的Representational Bottleneck问题; 提出了用于改进网络架构的新设计原则; 在ImageNet数据集上取得了SOTA结果,在COCO检测和4种不同的细粒度分类上取得了显著的迁移学习结果。
2 表征瓶颈
2.1 特征编码
给定一个深度为L层的网络,通过维的输入可以得到个被编码为的特征,其中为权重。
这里称的层为层,称的层为层。为第个点出的非线性函数,比如带有BN层的ReLU层,每个fi(·)表示第i个点非线性,如带有批归一化(BN)层的ReLU,为Softmax函数。
当训练模型的时候,每一次反向传播都会通过输入得到的输出与Label矩阵()之间的Gap来进行权重更新。
因此,这便意味着Gap的大小可能会直接影响特征的编码效果。这里对CNN的公式做略微的改动为;式中和分别为卷积运算和第个卷积层核的权值。用传统的重新排序来重写每个卷积,其中和重新排序的特征,这里将第个特征写成:
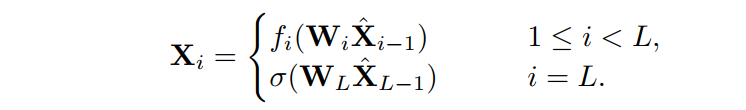
2.2 表征瓶颈与特征矩阵的秩
回顾Softmax bottleneck
这里讨论一下Softmax bottleneck,也是Representational bottleneck的一种,发生在Softmax层,以形式化表征性瓶颈。
由2.1所提的卷积公式可知,交叉熵损失的输出为,其秩以的秩为界,即。由于输入维度小于输出维度,编码后的特征由于秩不足而不能完全表征所有类别。这解释了Softmax层的一个Softmax bottleneck实例。
为了解决这一问题,相关工作表明,通过引入非线性函数来缓解Softmax层的秩不足,性能得到了很大的改善。
此外,如果将增加到更接近,它会成为另一种解决Representational bottleneck的解决方案吗?
通过layer-wise rank expansion来减少Representational bottleneck
这里从为ImageNet分类任务而设计的网络说起。网络被设计成有多个下采样块的模型,同时留下其他层具有相同的输出和输入通道大小。作者推测,扩展channel大小的层(即层),如下采样块,将有秩不足,并可能有Representational bottleneck。
而本文作者的目标是通过扩大权重矩阵的秩来缓解中间层的Representational bottleneck问题。
给定某一层生成的第个特征,的阈值为(这里假设)。这里,其中表示与另一个函数的点乘。在满足不等式的条件下,特征的秩范围为:
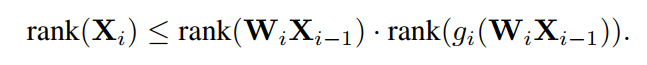
因此,可以得出结论,秩范围可以通过增加的秩和用适当的用具有更大秩的函数来替换展开,如使用swish或ELU激活函数,这与前面提到的非线性的解决方法类似。
当固定时,如果将特征维数调整到接近,则上式可以使得秩可以无限接近到特征维数。对于一个由连续的1×1,3×3,1×1卷积组成的bottleneck块,通过考虑bottleneck块的输入和输出通道大小,用上式同样可以展开秩的范围。
2.3 实证研究
Layer-level秩分析
为了进行Layer-level秩分析,作者生成一组由单一层组成的随机网络:其中,随机采样,则按比例进行调整。
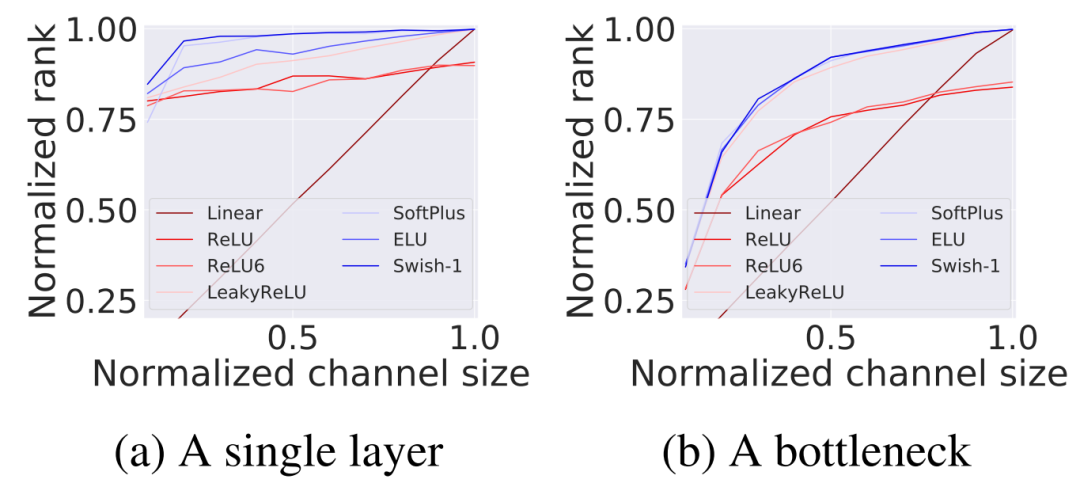
特征归一化后的秩是由每个网络产生。为了研究而广泛使用了非线性函数。对于每种标准化Channel大小,作者以通道比例在之间和每个非线性进行10,000个网络的重复实验。图1a和1b中的标准化秩的展示。
通道配置研究
现在考虑如何设计一个分配整个层的通道大小的网络。随机生成具有expand层(即)的L-depth网络,以及使用少量的condense层的设计原则使得,这里使用少量的condense层是因为condense层直接降低了模型容量。在这里作者将expand层数从0改变为,并随机生成网络。
例如,一个expand层数为0的网络,所有层的通道大小都相同(除了stem层的通道大小)。作者对每个随机生成的10,000个网络重复实验,并对归一化秩求平均值。结果如图1c和1d所示。
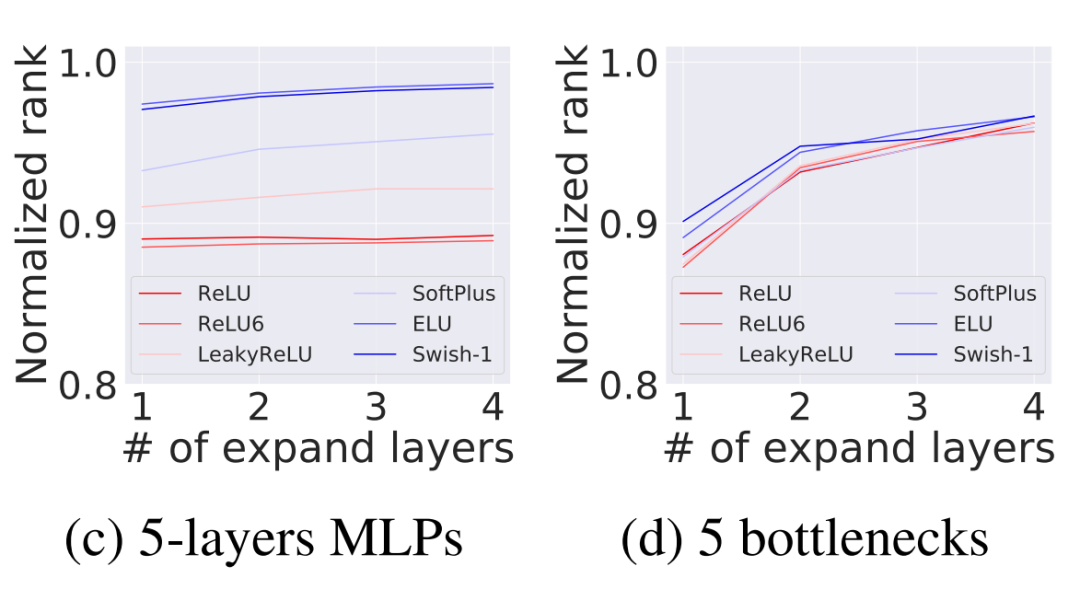
此外,还测试了采样网络的实际性能,每个配置有不同数量的expand层,有5个bottleneck,stem通道大小为32。在CIFAR100数据集上训练网络,并在表1中给出了5个网络的平均准确率。
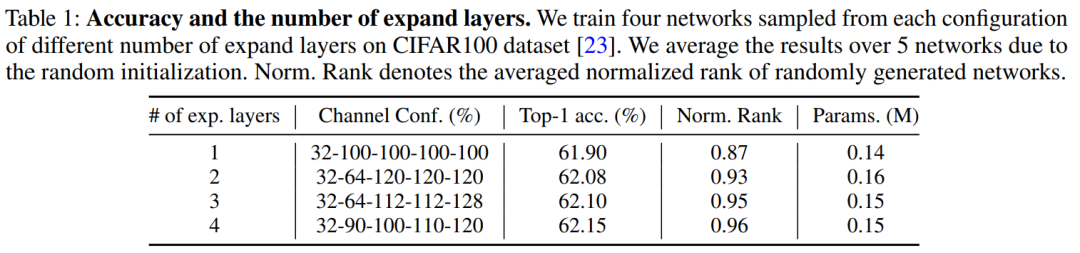
观察结果
从图1a和图1b中可以看到,选择恰当的非线性函数与线性情况相比,可以在很大程度上扩大秩。
其次,无论是单层(图1a)还是bottleneck块(图1b)情况下,归一化的输入通道大小都与特征的秩密切相关。
对于整个层的Channel配置,图1c和1d表明,在网络深度固定的情况下,可以使用更多的expand层来扩展秩。
这里给出了扩展给定网络秩的设计原则:
在一层上扩展输入信道大小; 找到一个合适的非线性映射; 一个网络应该设计多个expand层。
3 改善网络结构
3.1 表征瓶颈发生在哪里?
在网络中哪一层可能出现表征瓶颈呢?所有流行的深度网络都有类似的架构,有许多扩展层将图像输入的通道从3通道输入扩展到c通道然后输出预测。
首先,对块或层进行下采样就像展开层一样。其次,瓶颈模块和反向瓶颈块中的第一层也是一个扩展层。最后,还存在大量扩展输出通道大小的倒数第2层。
本文作者认为:表征瓶颈将发生在这些扩展层和倒数第2层。
3.2 网络设计
中间卷积层
本文作者首先考虑了MobileNetV1。依次对接近倒数第2层的卷积做同样的修改。通过:
扩大卷积层的输入通道大小; 替换ReLU6s来细化每一层。
作者在MobileNetV1中做了类似MobileNetV2地更新。所有从末端到第1个的反向瓶颈都按照相同的原理依次修改。
在ResNet及其变体中,每个瓶颈块在第3个卷积层之后不存在非线性,所以扩展输入通道大小是唯一的补救办法。
倒数第2个层
很多网络架构在倒数第2层有一个输出通道尺寸较大的卷积层。这是为了防止最终分类器的表征瓶颈,但是倒数第2层仍然受到这个问题的困扰。于是作者扩大了倒数第2层的输入通道大小,并替换了ReLU6。
ReXNets
作者在这里根据前面所说的规则设计了自己的模型,称为秩扩展网络(ReXNets)。其中ReXNet-plain和ReXNet分别在MobileNetV1和MobileNetV2上进行了更新。
这里设计模型是一个实例,它显示了代表性瓶颈的减少是如何影响整体性能的,这将在实验部分中显示。为了进行公平的比较,这里的通道配置设计大致能满足Baseline的整体参数和flops,如果通过适当的参数搜索方法,如NAS方法,还可以找到更好的网络结构。
PyTorch实现如下:
import torch
import torch.nn as nn
from math import ceil
# Memory-efficient Siwsh using torch.jit.script borrowed from the code in (https://twitter.com/jeremyphoward/status/1188251041835315200)
# Currently use memory-efficient Swish as default:
USE_MEMORY_EFFICIENT_SWISH = True
if USE_MEMORY_EFFICIENT_SWISH:
@torch.jit.script
def swish_fwd(x):
return x.mul(torch.sigmoid(x))
@torch.jit.script
def swish_bwd(x, grad_output):
x_sigmoid = torch.sigmoid(x)
return grad_output * (x_sigmoid * (1. + x * (1. - x_sigmoid)))
class SwishJitImplementation(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return swish_fwd(x)
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
return swish_bwd(x, grad_output)
def swish(x, inplace=False):
return SwishJitImplementation.apply(x)
else:
def swish(x, inplace=False):
return x.mul_(x.sigmoid()) if inplace else x.mul(x.sigmoid())
class Swish(nn.Module):
def __init__(self, inplace=True):
super(Swish, self).__init__()
self.inplace = inplace
def forward(self, x):
return swish(x, self.inplace)
def ConvBNAct(out, in_channels, channels, kernel=1, stride=1, pad=0,
num_group=1, active=True, relu6=False):
out.append(nn.Conv2d(in_channels, channels, kernel,
stride, pad, groups=num_group, bias=False))
out.append(nn.BatchNorm2d(channels))
if active:
out.append(nn.ReLU6(inplace=True) if relu6 else nn.ReLU(inplace=True))
def ConvBNSwish(out, in_channels, channels, kernel=1, stride=1, pad=0, num_group=1):
out.append(nn.Conv2d(in_channels, channels, kernel,
stride, pad, groups=num_group, bias=False))
out.append(nn.BatchNorm2d(channels))
out.append(Swish())
class SE(nn.Module):
def __init__(self, in_channels, channels, se_ratio=12):
super(SE, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_channels, channels // se_ratio, kernel_size=1, padding=0),
nn.BatchNorm2d(channels // se_ratio),
nn.ReLU(inplace=True),
nn.Conv2d(channels // se_ratio, channels, kernel_size=1, padding=0),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.fc(y)
return x * y
class LinearBottleneck(nn.Module):
def __init__(self, in_channels, channels, t, stride, use_se=True, se_ratio=12,
**kwargs):
super(LinearBottleneck, self).__init__(**kwargs)
self.use_shortcut = stride == 1 and in_channels <= channels
self.in_channels = in_channels
self.out_channels = channels
out = []
if t != 1:
dw_channels = in_channels * t
ConvBNSwish(out, in_channels=in_channels, channels=dw_channels)
else:
dw_channels = in_channels
ConvBNAct(out, in_channels=dw_channels, channels=dw_channels, kernel=3, stride=stride, pad=1,
num_group=dw_channels, active=False)
if use_se:
out.append(SE(dw_channels, dw_channels, se_ratio))
out.append(nn.ReLU6())
ConvBNAct(out, in_channels=dw_channels, channels=channels, active=False, relu6=True)
self.out = nn.Sequential(*out)
def forward(self, x):
out = self.out(x)
if self.use_shortcut:
out[:, 0:self.in_channels] += x
return out
class ReXNetV1(nn.Module):
def __init__(self, input_ch=16, final_ch=180, width_mult=1.0, depth_mult=1.0, classes=1000,
use_se=True,
se_ratio=12,
dropout_ratio=0.2,
bn_momentum=0.9):
super(ReXNetV1, self).__init__()
layers = [1, 2, 2, 3, 3, 5]
strides = [1, 2, 2, 2, 1, 2]
use_ses = [False, False, True, True, True, True]
layers = [ceil(element * depth_mult) for element in layers]
strides = sum([[element] + [1] * (layers[idx] - 1)
for idx, element in enumerate(strides)], [])
if use_se:
use_ses = sum([[element] * layers[idx] for idx, element in enumerate(use_ses)], [])
else:
use_ses = [False] * sum(layers[:])
ts = [1] * layers[0] + [6] * sum(layers[1:])
self.depth = sum(layers[:]) * 3
stem_channel = 32 / width_mult if width_mult < 1.0 else 32
inplanes = input_ch / width_mult if width_mult < 1.0 else input_ch
features = []
in_channels_group = []
channels_group = []
# The following channel configuration is a simple instance to make each layer become an expand layer.
for i in range(self.depth // 3):
if i == 0:
in_channels_group.append(int(round(stem_channel * width_mult)))
channels_group.append(int(round(inplanes * width_mult)))
else:
in_channels_group.append(int(round(inplanes * width_mult)))
inplanes += final_ch / (self.depth // 3 * 1.0)
channels_group.append(int(round(inplanes * width_mult)))
ConvBNSwish(features, 3, int(round(stem_channel * width_mult)), kernel=3, stride=2, pad=1)
for block_idx, (in_c, c, t, s, se) in enumerate(zip(in_channels_group, channels_group, ts, strides, use_ses)):
features.append(LinearBottleneck(in_channels=in_c,
channels=c,
t=t,
stride=s,
use_se=se, se_ratio=se_ratio))
pen_channels = int(1280 * width_mult)
ConvBNSwish(features, c, pen_channels)
features.append(nn.AdaptiveAvgPool2d(1))
self.features = nn.Sequential(*features)
self.output = nn.Sequential(
nn.Dropout(dropout_ratio),
nn.Conv2d(pen_channels, classes, 1, bias=True))
def forward(self, x):
x = self.features(x)
x = self.output(x).squeeze()
return x
4. 实验
4.1 分类实验
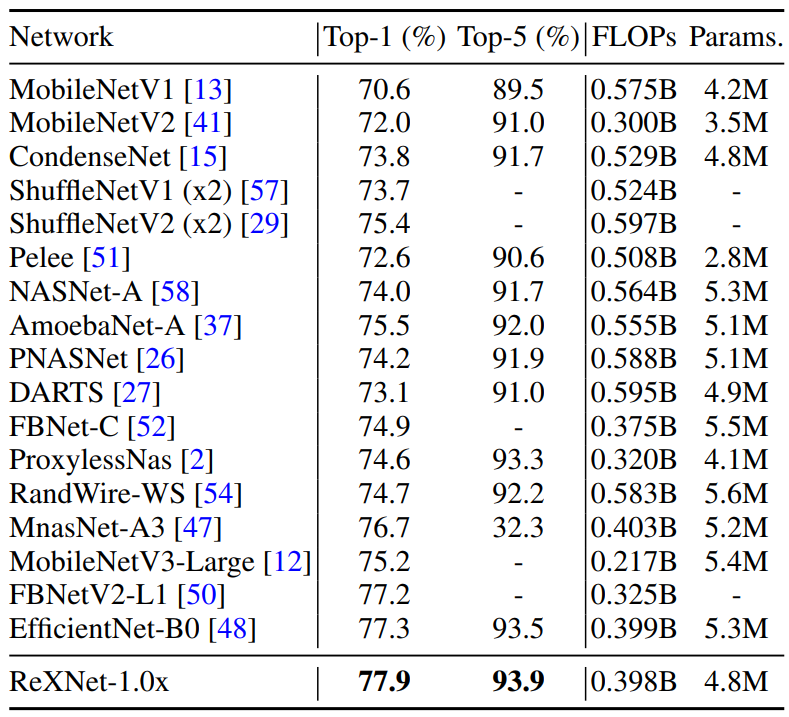
其实透过上表一斤可以看出该方法的优越性了,仅仅是MobileNet的FLOPs和参数两就已经达到甚至超越了ResNet50的水平。
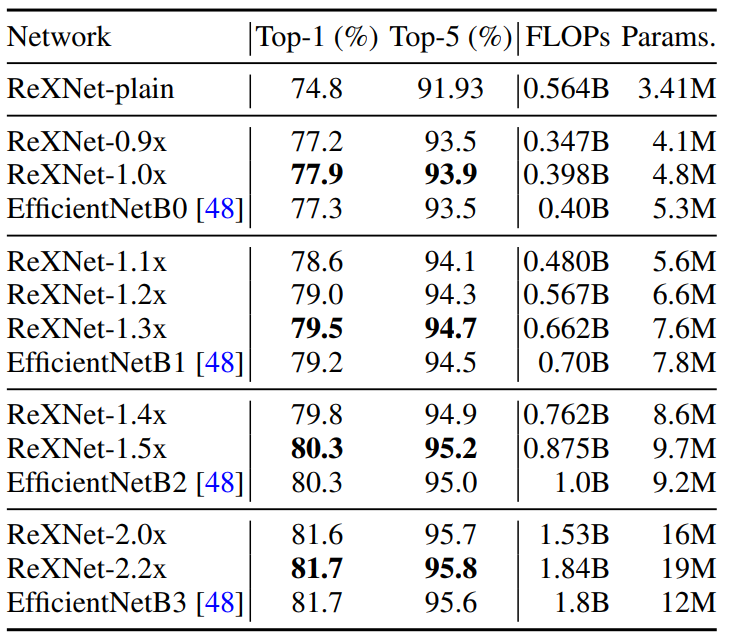
ReXNets的性能更是超越了EfficientNets
4.2 检测实验
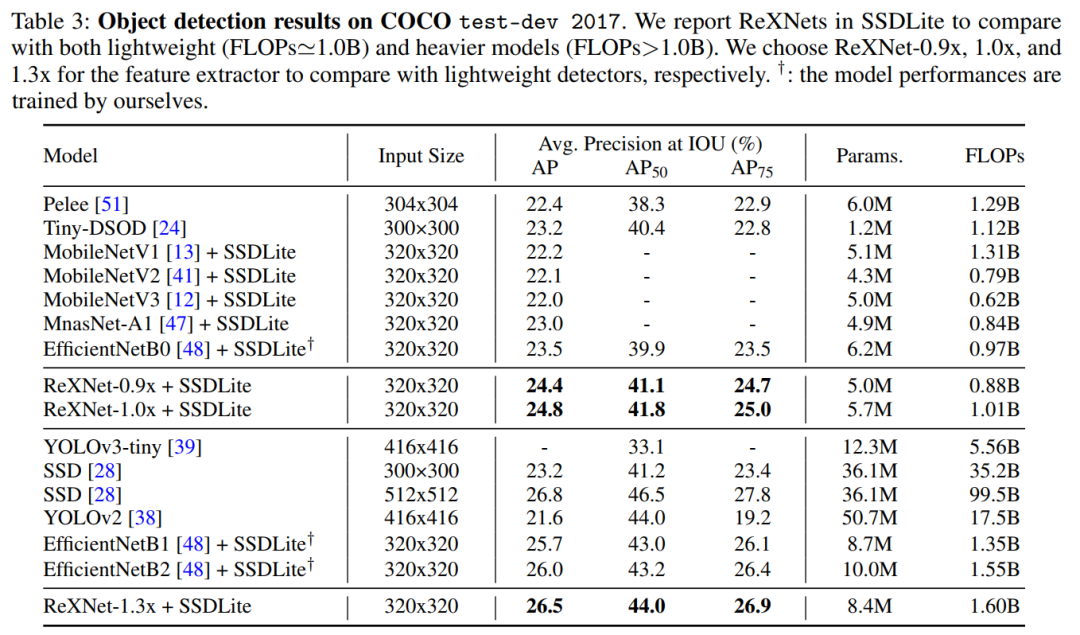
可以看出ReXNet-1.3x+SSDLite仅仅用来十分之一的FLOPs和参数量就可以达到SSD的检测水平。在远低于yolos tiny系列的FLOPs和参数量的情况下更是玩爆yolo-v3-tiny、yolo-v4-tiny直逼yolo-v5s。
4.3 迁移学习
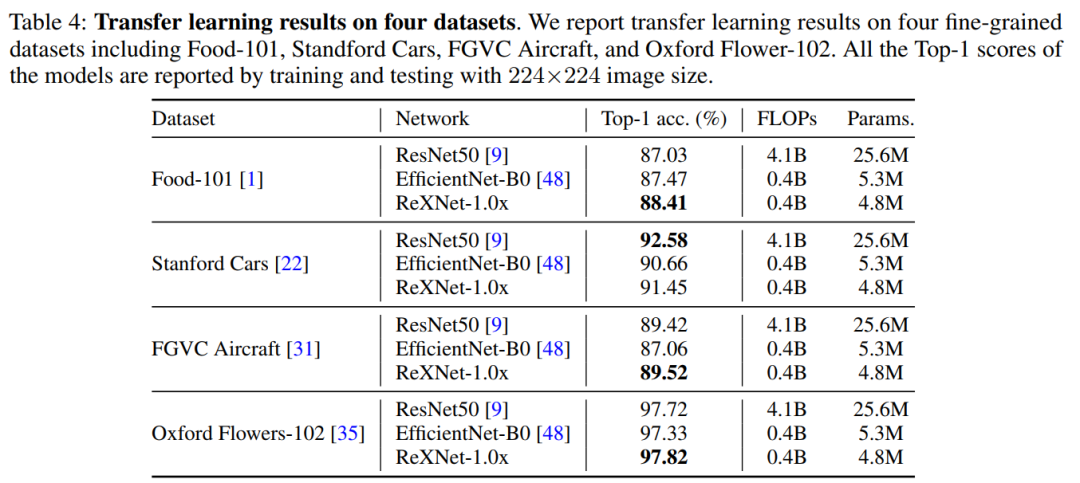
就不比比那么多啦,就是好就对了,很香,很快,很好用!!!
5 参考
[1].ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network
[2].https://github.com/clovaai/rexnet/blob/master/rexnetv1.py
6 推荐阅读
新型卷积 | 涨点神器!利用Involution可构建新一代神经网络!(文末获取论文与源码)
CVPR2021-即插即用 | Coordinate Attention详解与CA Block实现(文末获取论文原文)
全领域涨点 | Transformer携Evolving Attention在CV与NLP领域全面涨点(文末送书)
Backbone | 谷歌提出LambdaNetworks:无需注意力让网络更快更强(文末获取论文源码)
Transformer系列 | 更深、更强、更轻巧的Transformer,DeLighT(文末获取论文与源码)
泛化神器 | 李沐老师新作进一步提升模型在多域多的泛化性,CV和NLP均有大幅度提升(文末获取论文)
本文论文原文获取方式,扫描下方二维码
回复【Involution 】即可获取论文与源码
长按扫描下方二维码加入交流群
声明:转载请说明出处
扫描下方二维码关注【AI人工智能初学者】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!!!
点“在看”给我一朵小黄花呗![]()