
海量图片去重算法-局部分块Hash算法

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
本文主要调研了一下海量图片(>1000000张)去重的方法,在调研之前,先考虑一下自己能想到的方法的可行性。
文献发表:《基于pHash分块局部探测的海量图像查重算法》https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CJFD&filename=JSJY201909051
能想到的方法
在调研之前,思考一下能想到的比较简单的方法。当然下面的方法都是在拿到图片特征之后做的。
方法1-按照pair计算图片的相似性
这种方法原始,简单,粗暴。基本思想就是挑选一个图片pair,按照某种方法计算相似度(可以是图片特征之间的相似度,可以是由网络计算的相似度),相似度低于某个阈值,则认为它们是重复的,然后从数据库中移除其中一张图片即可。这种方法虽然简单,但实际上并不可行,因为数据量太大,时间复杂度为O(n^2)。
方法2-感知Hash
生成图片的pHash,并计算pair之间pHash的Hamming distance。当然这种方法复杂度也是非常高的O(n^2)。
方法3-聚类
生成图片的特征向量并聚类,簇的数量需要设定的非常多(>10000)。每一个簇内计算图片对的距离,然后移除掉距离足够小的图片之一。但是这种方法复杂度也是挺高的,改进策略是进行多阶段聚类。首先设定第一次聚类的簇数为一个比较小的数(<100),然后聚类。然后对每一个簇再分别聚类,对第i个簇c_i,设定子簇数为|c_i| / b。
网上搜到的方法
方法1-pHash分块局部探测
该算法的主要步骤是这样
生成所有图片的pHash(64bit)指纹特征,也可以是图片的二值化特征向量;
将每个图片的二值化特征等分成n等分,比如对于64bit指纹特征,n取4,那么每个等分的长度为16;
建立n个dict,其中第i个dict的key为第i个等分,值为一个list,用于存储具有相同第i个等分的的所有图片(url);
遍历所有的dict,对每一个值(list)计算两两图片之间的Hamming distance,若有dist小于某个阈值的,则标记两者为相同的。为了测试效果,返回一部分相同的图片并显示。
这种方法需要做一些test查看每个list的规模,如果规模足够小,那么遍历一个pair的图片复杂度也不高,甚至于对于一些没有重复的图片,一个list只有单独的一张图片。不过条件是pHash的效果要比较好才行。即相似的图片pHash之间具有较小的Hamming distance。
目前的代码实现了该算法
参考:https://www.jianshu.com/p/c87f6f69d51f
方法2-若干Bucket存储可能相似的图片
这种方法也是减小可能相似的pair的搜索空间。原始的方法思想:
生成所有图片的特征向量。
选择任意一张图片x,遍历所有图片,如果存在图片a,b,使得d(a, x) =d(b, x),那么图片a, b可能是重复的(这一步可以在O(n)内找出所有距离一样的图片对),并进一步计算a, b之间的距离。
如果a, b的距离为0,那么说明图片a, b是重复的。
原始的方法有些不合理的条件,对距离的要求太过苛刻。一种改进是:
生成所有图片的特征向量
建立相似图片的局部搜索空间:选择一个边界样本x, 计算x到所有图片的距离,按照某种方法生成若干(>1000)的bucket,每一个bucket会存储距离处于一定范围的样本,且任意两个个bucket掌握的范围之间是不相交的。
对每一个bucket,计算图片之间的距离,并移除掉距离足够近的样本对中的一个。
关键问题是:bucket与bucket之间尽管不相交,但bucket掌握的范围边界可能仍然存在相似甚至相同的样本对。这部分样本是无法探测到的。
Bucket如何建立?比较简单的方法是计算x到其他样本的最大距离,按照最大距离将距离区间划分成若干等分。
参考:https://www.xzbu.com/8/view-7438065.htm
方法3-基于minHash的局部敏感Hash
局部敏感Hash算法希望原始特征空间中保持相邻的数据在经过某种Hash方法后依然有较高概率能保持相邻。
这里我们以基于minHash的局部敏感Hash算法为例。
首先讲解一下minHash算法的步骤:
对每个样本生成二值化的特征向量(列形式)。
所有样本的二值化特征向量按列拼成一个矩阵X_d*n,d为特征向量的维度,n为样本个数。
i = 1; 特征矩阵按行进行一个随机排列,记录每一列(每一个样本)第一次出现1的行号h_i(x),h_1(x)可以认为是样本x的特征向量的一个近似。
重复k次步骤3,每次重复i++,并记录每一个样本的minHash向量[h_1(x), ..., h_k(x)]。该向量被称为样本x的minHash signature。
对于signature,我们可以知道有这样一个性质,越是相似的样本,相同的h_i值就越多,因为h_i是整数。
基于minHash的LSH方法步骤:
用pHash或者网络生成图片的2值化特征向量。
生成所有样本的签名(列向量),所有样本的签名按照列拼成签名矩阵X_k*n
将签名矩阵的k行等分成b个band,每一个band有r行,也就是k = r*b。
针对每一个band,分别建立一个Hash表,然后就可以把所有样本在一个band上的minHash子向量进行散列,这样相似的样本在同一个band上就非常有可能被映射到Hash表中同一个位置。
图片去重的过程就是在每一个Hash表中的每一个位置做图片对的相似度计算,然后去除掉相似度较小的图片。
这个方法主要参考了https://blog.csdn.net/yc461515457/article/details/48845775,https://xdrush.github.io/2017/08/09/%E5%B1%80%E9%83%A8%E6%95%8F%E6%84%9F%E5%93%88%E5%B8%8C/
pHash分块局部探测算法用法
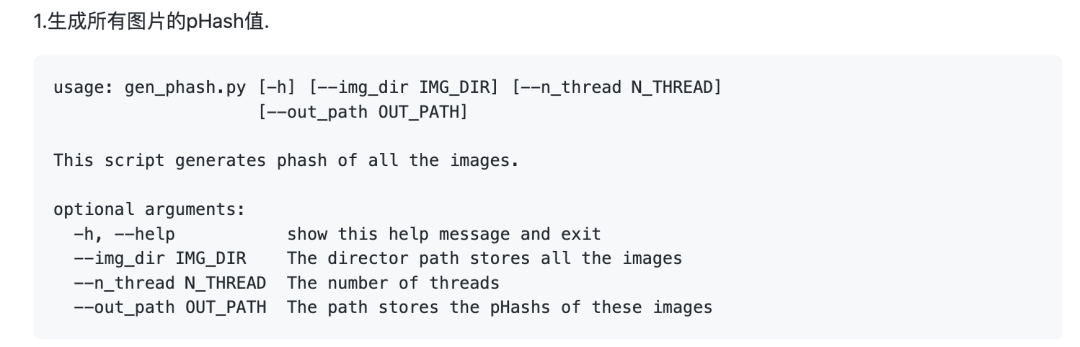
2.根据pHash值探测重复图片
2.1.不具传递性的重复图片探测. 假设sim(a, b) < threshold,sim(b, c) < threshold,那么a和b,b和c都被认为是重复的。如果sim(a, c)>threshold,则a,c被认为是不重复的.
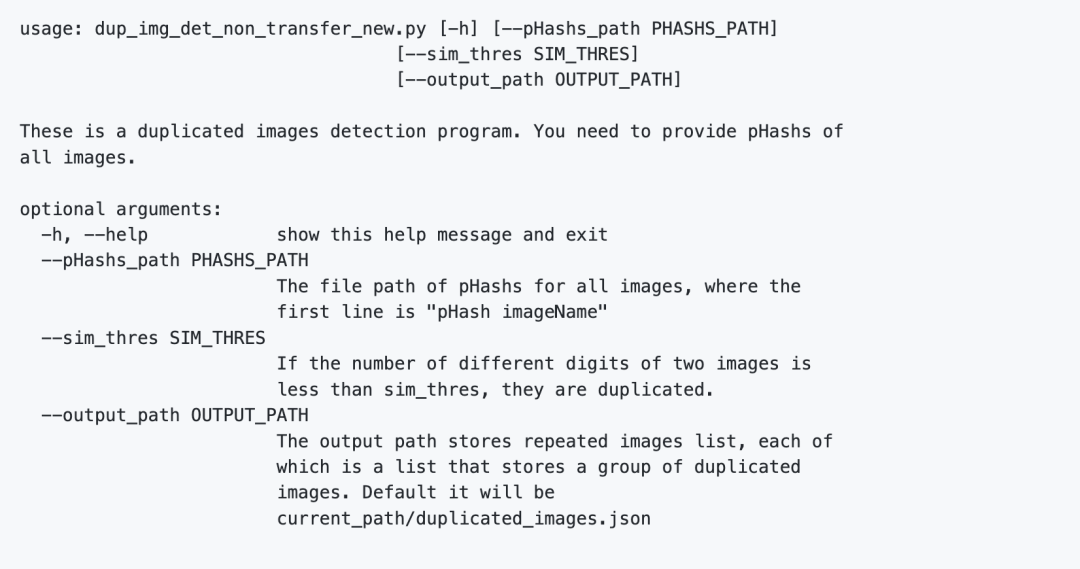
2.2.具有传递性的重复图片探测. 假设sim(a, b) < threshold,sim(b, c) < threshold,那么a和b,b和c都被认为是重复的。且a,c也被认为是重复的.
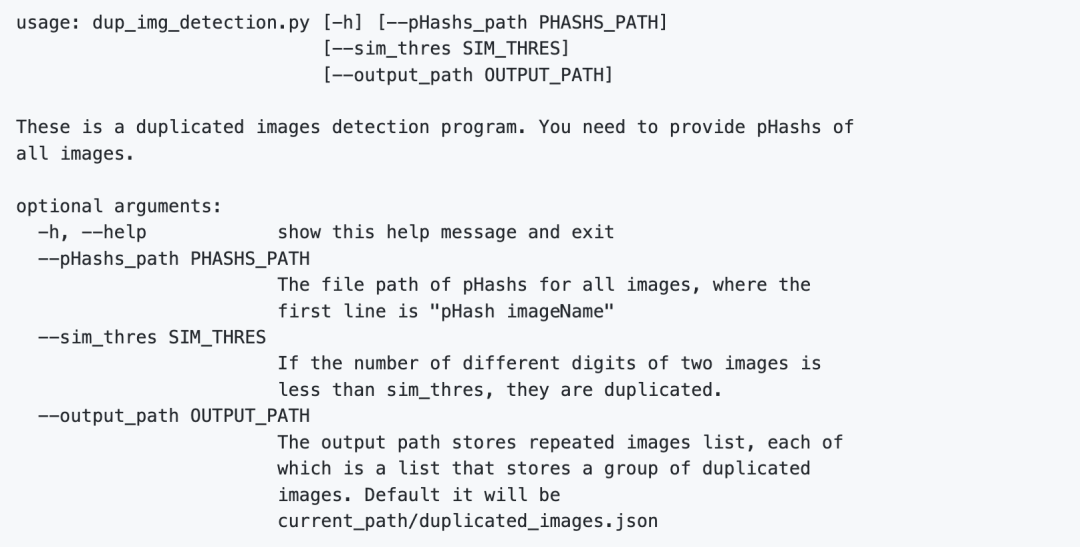
输出格式描述
输出是一个json文件,通过d = json.load(open(output_path))读取。d是一个list,其中每一项也是一个list,存放着相同图片的全路径。
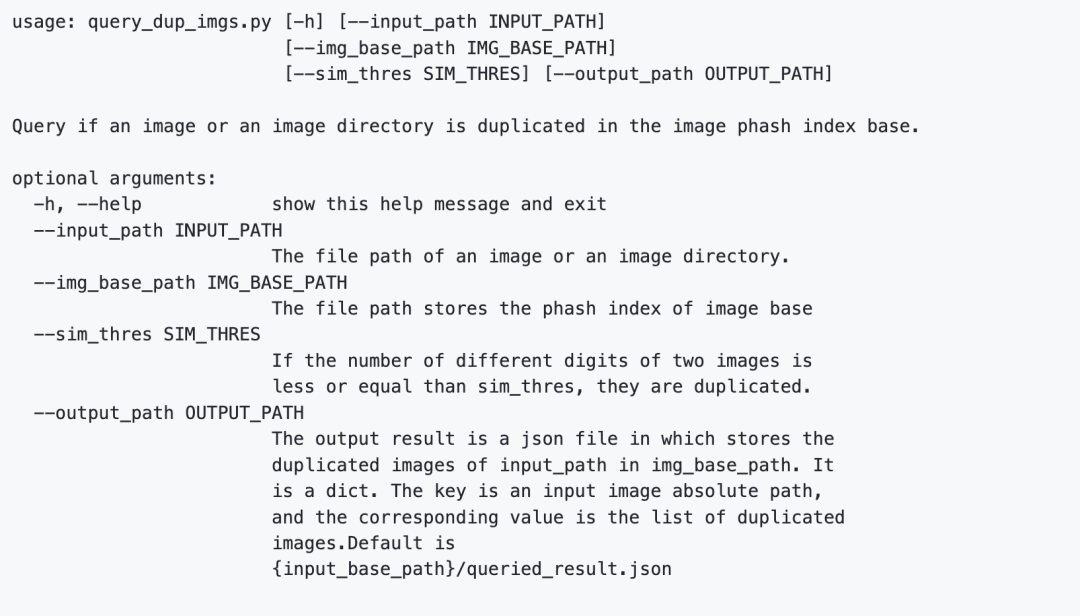
重复图片查询
给定一张图片的路径或者是图片文件夹路径,查询在图片库中是否有与之重复的图片。
1.生成图片的phash分块索引库。

查询指定图片或图片文件夹在图片索引库里是否含有重复的图片
原文地址 https://github.com/xuehuachunsheng/DupImageDetection
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx