
深度学习的多个 loss 是如何平衡的?
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

来自 | 知乎
地址 | https://www.zhihu.com/question/375794498
编辑 | AI有道
在一个端到端训练的网络中,如果最终的loss = a*loss1+b*loss2+c*loss3...,对于a,b,c这些超参的选择,有没有什么方法?
作者:Evan
https://www.zhihu.com/question/375794498/answer/1052779937
其实这是目前深度学习领域被某种程度上忽视了的一个重要问题,在近几年大火的multi-task learning,generative adversarial networks, 等等很多机器学习任务和方法里面都会遇到,很多paper的做法都是暴力调参结果玄学……这里偷偷跟大家分享两个很有趣的研究视角
1. 从预测不确定性的角度引入Bayesian框架,根据各个loss分量当前的大小自动设定其权重。有代表性的工作参见Alex Kendall等人的CVPR2018文章:
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
https://arxiv.org/abs/1705.07115
文章的二作Yarin Gal是Zoubin Ghahramani的高徒,近几年结合Bayesian思想和深度学习做了很多solid的工作。
2. 构建所有loss的Pareto,以一次训练的超低代价得到多种超参组合对应的结果。有代表性的工作参见Intel在2018年NeurIPS(对,就是那个刚改了名字的机器学习顶会)发表的:
Multi-Task Learning as Multi-Objective Optimization
http://papers.nips.cc/paper/7334-multi-task-learning-as-multi-objective-optimization
因为跟文章的作者都是老熟人,这里就不尬吹了,大家有兴趣的可以仔细读一读,干货满满。

作者:杨奎元-深动
链接:https://www.zhihu.com/question/375794498/answer/1050963528
1. 一般都是多个loss之间平衡,即使是单任务,也会有weight decay项。比较简单的组合一般通过调超参就可以。
2. 对于比较复杂的多任务loss之间平衡,这里推荐一篇通过网络直接预测loss权重的方法[1]。以两个loss为例,  和
和  由网络输出,由于整体loss要求最小,所以前两项希望
由网络输出,由于整体loss要求最小,所以前两项希望  越大越好,为防止退化,最后第三项则希望越小越好。当两个loss中某个比较大时,其对应的也会取较大值,使得整体loss最小化,也就自然处理量纲不一致或某个loss方差较大问题。
越大越好,为防止退化,最后第三项则希望越小越好。当两个loss中某个比较大时,其对应的也会取较大值,使得整体loss最小化,也就自然处理量纲不一致或某个loss方差较大问题。

该方法后来被拓展到了物体检测领域[2],用于考虑每个2D框标注可能存在的不确定性问题。
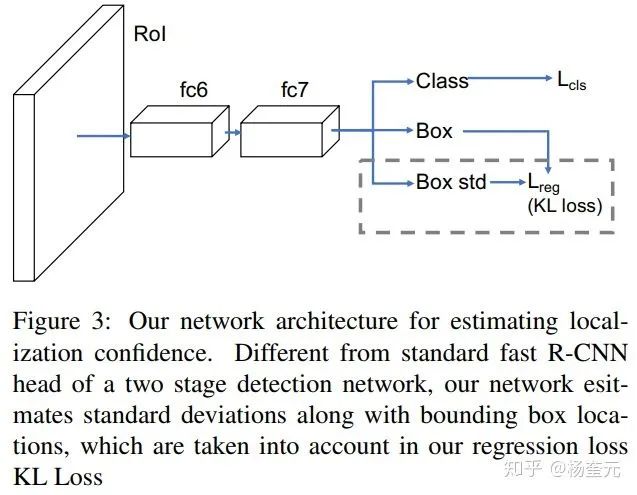
[1] Alex Kendall, Yarin Gal, Roberto Cipolla. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. CVPR, 2018.
[2] Yihui He, Chenchen Zhu, Jianren Wang, Marios Savvides, Xiangyu Zhang. Bounding Box Regression with Uncertainty for Accurate Object Detection. CVPR, 2019.
作者:郑泽嘉
链接:https://www.zhihu.com/question/375794498/answer/1056695768
Focal loss 会根据每个task的表现帮你自动调整这些参数的。
我们的做法一般是先分几个stage 训练。stage 0 : task 0, stage 1: task 0 and 1. 以此类推。在stage 1以后都用的是focal loss。
========== 没想到我也可以二更 ===============
是这样的。
首先对于每个 Task,你有个 Loss Function,以及一个映射到 [0, 1] 的 KPI (key performance indicator) 。比如对于分类任务, Loss function 可以是 cross entropy loss,KPI 可以是 Accuracy 或者 Average Precision。对于 regression 来说需要将 IOU 之类的归一化到 [0, 1] 之间。KPI 越高表示这个任务表现越好。
对于每个进来的 batch,每个Task_i 有个 loss_i。每个Task i 还有个不同的 KPI: k_i。那根据 Focal loss 的定义,FL(k_i, gamma_i) = -((1 - k_i)^gamma_i) * log(k_i)。一般来说我们gamma 取 2。
于是对于这个 batch 来说,整个 loss = sum(FL(k_i, gamma_i) * loss_i)
在直观上说,这个 FL,当一个任务的 KPI 接近 0 的时候会趋于无限大,使得你的 loss 完全被那个表现不好的 task 给 dominate。这样你的back prop 就会让所有的权重根据那个kpi 不好的任务调整。当一个任务表现特别好 KPI 接近 1 的时候,FL 就会是0,在整个 loss 里的比重也会变得很小。
当然根据学习的速率不同有可能一开始学的不好的task后面反超其他task。http://svl.stanford.edu/assets/papers/guo2018focus.pdf 这篇文章里讲了如何像momentum 一样的逐渐更新 KPI。
由于整个 loss 里现在也要对 KPI 求导,所以文章里还有一些对于 KPI 求导的推导。
当然我们也说了,KPI 接近 0 时,Loss 会变得很大,所以一开始训练的时候不要用focal loss,要确保网络的权重更新到一定时候再加入 focal loss。
希望大家训练愉快。
作者:Hanson
链接:https://www.zhihu.com/question/375794498/answer/1077922077
对于多任务学习而言,它每一组loss之间的数量级和学习难度并不一样,寻找平衡点是个很难的事情。我举两个我在实际应用中碰到的问题。
第一个是多任务学习算法MTCNN,这算是人脸检测领域最经典的算法之一,被各家厂商魔改,其性能也是很不错的,也有很多版本的开源实现(如果不了解的话,传送门)。但是我在测试各种实现的过程中,发现竟然没有一套实现是超越了原版的。下图中是不同版本的实现,打了码的是我复现的结果。

这是一件很困扰的事情,参数、网络结构大家设置都大差不差。但效果确实是迥异。

clsloss表示置信度score的loss,boxloss表示预测框位置box的loss,landmarksloss表示关键点位置landmarks的loss。
那么  这几个权值,究竟应该设置为什么样的才能得到一个不错的结果呢?
这几个权值,究竟应该设置为什么样的才能得到一个不错的结果呢?
其实有个比较不错的注意,就是只保留必要的那两组权值,把另外一组设置为0,比如  。为什么这么做?第一是因为关键点的回归在人脸检测过程中不是必要的,去了这部分依旧没什么大问题,也只有在这个假设的前提下才能进行接下来的实验。
。为什么这么做?第一是因为关键点的回归在人脸检测过程中不是必要的,去了这部分依旧没什么大问题,也只有在这个假设的前提下才能进行接下来的实验。
就比如这个MTCNN中的ONet,它回归了包括score、bbox、landmarks,我在用pytorch复现的时候,出现一些有意思的情况,就是将landmarks这条任务冻结后(即 ),发现ONet的性能得到了巨大的提升。能超越原始版本的性能。
但是加上landmarks任务后(  )就会对cls_loss造成影响,这就是一个矛盾的现象。而且和a、b、c对应的大小有很大关系。当设置成(
)就会对cls_loss造成影响,这就是一个矛盾的现象。而且和a、b、c对应的大小有很大关系。当设置成(  )的时候关键点的精度真的是惨不忍睹,几乎没法用。当设置成(
)的时候关键点的精度真的是惨不忍睹,几乎没法用。当设置成(  )的时候,loss到了同样一个数量级,landmarks的精度确实是上去了,但是score却不怎么让人满意。如果产生了这种现象,就证明了这个网络结构在设计的时候出现了一些缺陷,需要去修改backbone之后的multi-task分支,让两者的相关性尽量减小。或者是ONet就不去做关键点,而是选择单独的一个网络去做关键点的预测(比如追加一个LNet)。box的回归并不是特别受关键点影响,大部分情况box和landmarks是正向促进的,影响程度可以看做和score是一致的,box的精度即便下降了5%,它还是能框得住目标,因此不用太在意。
)的时候,loss到了同样一个数量级,landmarks的精度确实是上去了,但是score却不怎么让人满意。如果产生了这种现象,就证明了这个网络结构在设计的时候出现了一些缺陷,需要去修改backbone之后的multi-task分支,让两者的相关性尽量减小。或者是ONet就不去做关键点,而是选择单独的一个网络去做关键点的预测(比如追加一个LNet)。box的回归并不是特别受关键点影响,大部分情况box和landmarks是正向促进的,影响程度可以看做和score是一致的,box的精度即便下降了5%,它还是能框得住目标,因此不用太在意。
上面这个实验意在说明,要存在就好的loss权重组合,那么你的网络结构就必须设计的足够好。不然你可能还需要通过上述的实验就验证你的网络结构。从多种策略的设计上去解决这中loss不均衡造成的困扰。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!