
Flink 实践 | 基于 Flink Kylin Hudi 湖仓一体的大数据生态体系
湖仓一体的架构
Flink/Hudi/Kylin 介绍与融合
T3 出行结合湖仓一体的实践

首先第一点,是没有走现在传统数仓所广泛应用的 Shared-Nothing 这个架构,而是转向 Shared-Data 这个架构。
其次,论文中重点提及的存储和计算分离,是文中我觉得最有价值的一个观点。他提出了统一存储然后弹性计算的这样一个观念。
第三,数仓及服务是我认为他们商业化最成功的点。它将数仓提供了一个 SaaS 化的体验,并且摒弃传统上大家认为的数仓是大而重的偏见。
第四,高可用这一块是提高用户体验和容错的很关键的一个点。
最后,结构化延伸到半结构化这一块已经体现当时他们能够探索湖上通用数据的能力。

第一点,Table 上的数据可以进行跨节点的水平分区,并且每个节点有自己的本地存储。每个节点的计算资源,只关注处理每个节点自己存储的数据。
所以它的另一个优点就是它的处理机制相对简单,是数仓领域很典型的一个架构。
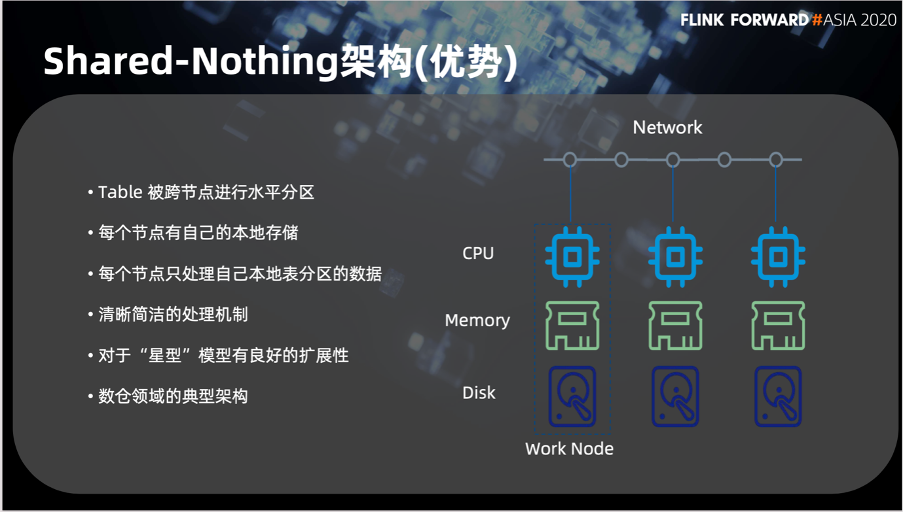
最大的一点就是他耦合了计算与存储资源,
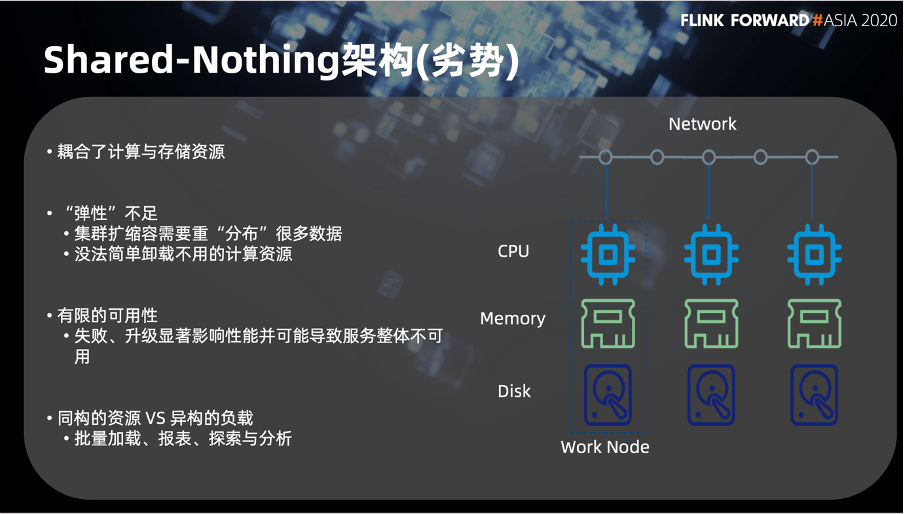
同时也带来第二个问题,就是弹性不足。具体可以体现在 2 个方面。
集群在扩缩容的时候,数据需要被大量重分布
没有办法简单地卸载不用的计算资源。
第三个问题是,耦合计算和存储资源同时也就造成了它的可用性是相当有限的。由于这些称之为有状态的计算,所以在失败或者是升级的时候会显著影响性能,并会导致服务整体不可用的状态。
最后是同构的资源与异构的负载的问题。因为在数仓的场景中,我们有很多异构的负载,比如说批量的加载,查询,报表的大规模计算分析等等。但 Shared-Nothing 架构的资源是同构的,所以这带来两者之间的碰撞。
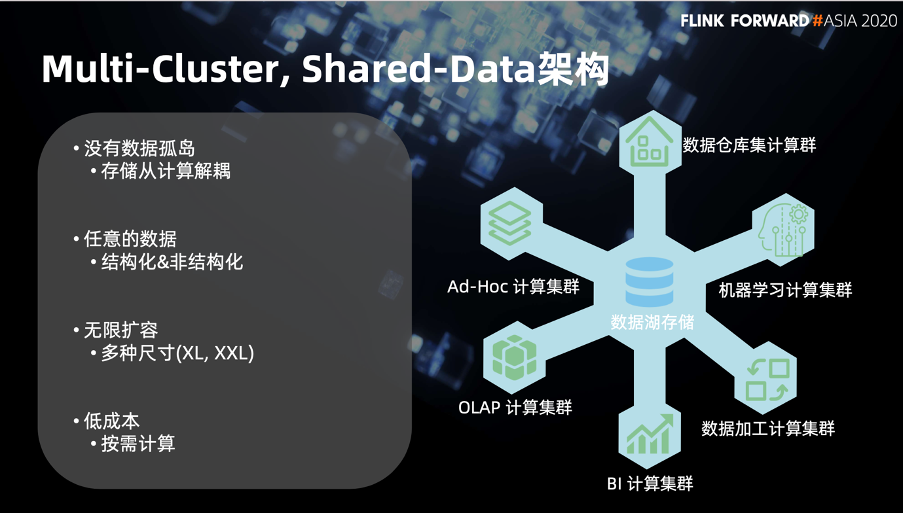
这个架构的第一个优势是它没有数据孤岛,是一个统一的存储。这也就能够将存储从计算中进行解耦。
第二个优势是基于现在的对象存储去容纳结构化和非结构化数据。
第三,它的集群规模是可以弹性作用的。
第四,上述特征同时也带来了按需计算这个低成本优点。
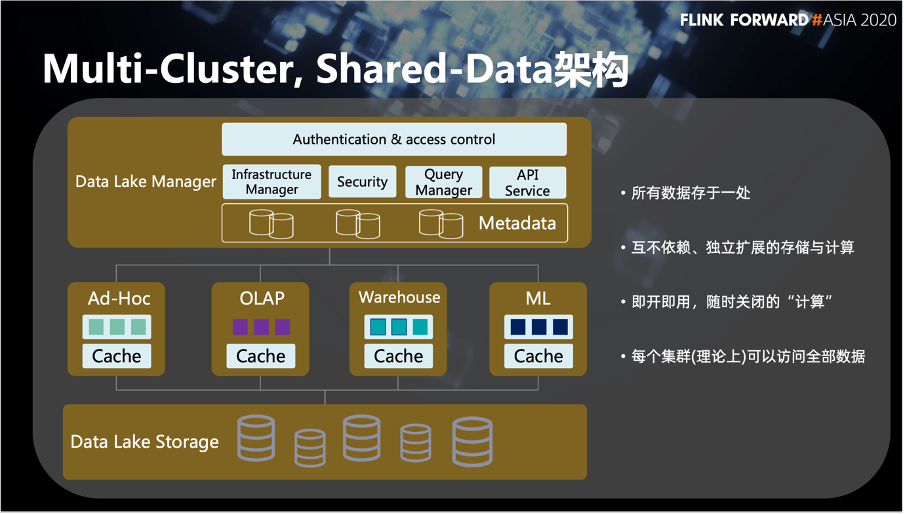
最底层是云厂商提供的对象存储,也就是用户的存储。
中间层是多用途多份的计算集群。
再往上是数据湖的管理服务,它存载的是一个大的 SaaS 化的平台,是对整个底层存储以及计算集群的管理的角色。
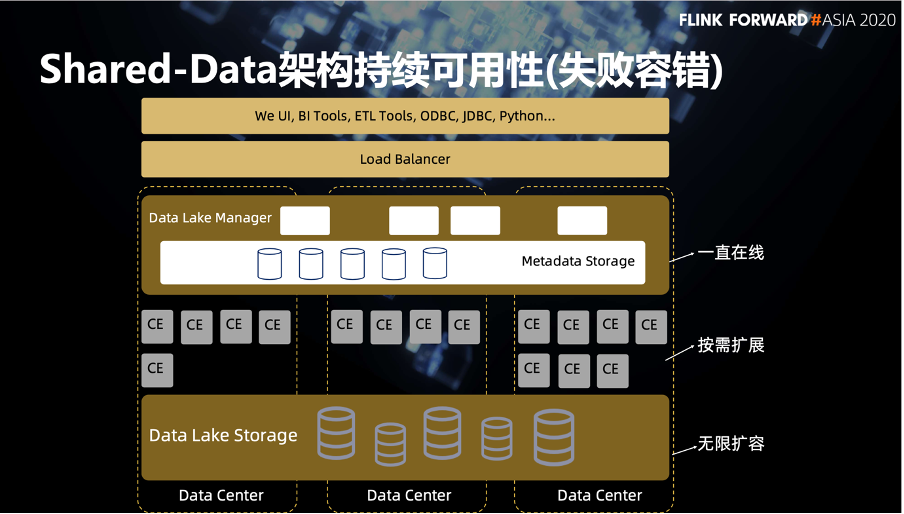
首先,作为一个 SaaS 化的应用,它的容错性是需要体现在整体架构上。这里我们同样分层来回顾一下。
最底层的存储层利用了云厂商的对象存储能力,他本身是一个跨中心复制以及接近无限扩容的一个机制,所以用户基本无需关心。
再往上是多元的计算集群。每个计算集群是在同一个数据中心内,来保证它网络传输的性能。这里就提到一个问题,有可能某一个计算集群会有节点失败的问题。假如在一次查询中有一个节点失败,这些计算节点会将这个状态返回上面的服务层。服务层在接受这个失败后,会将这个计算再次传递到可用的节点中进行二次查询。所以 Shared-Data 存储和计算分离的这种架构上节点近乎是无状态的计算。这种架构的一个节点失败就不是一个非常大的问题。
再往上服务层对于元数据的存储也是利用了对象存储的这个能力。所以这个服务层基本上可以看做是无状态的服务。
最上层是一个负载均衡器,可以进行服务的冗余和负载的均摊。
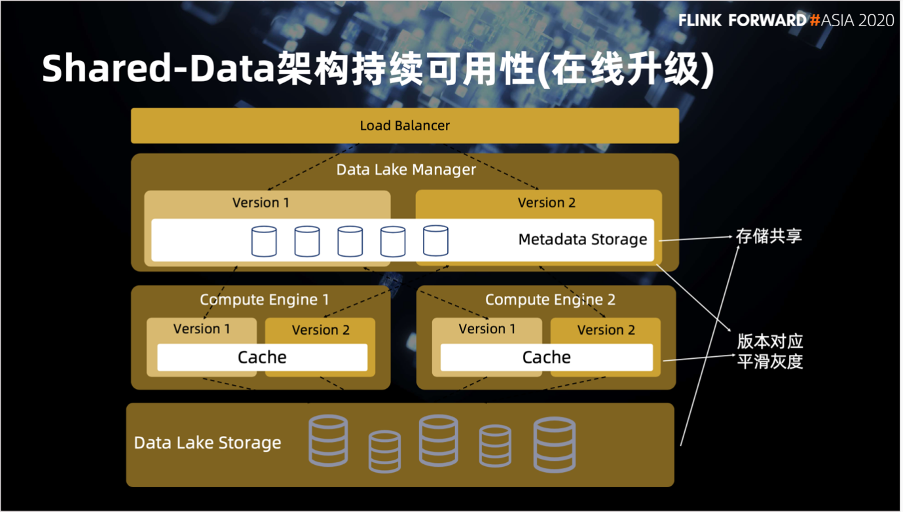
第二点在线升级这一块主要利用两个设计,其实这也并不是很新颖的做法。一个是在计算层和服务层的多方面的映射,然后灰度的切换。这里可以看到在计算层是分多版本的,并且这些版本之间会共享本地的 Cache。服务层的元数据管理也是在多方面共享。这其实也是架构内的子 Shared-Data,对于多版本之间的数据共享能做到再升级和平滑灰度的能力。

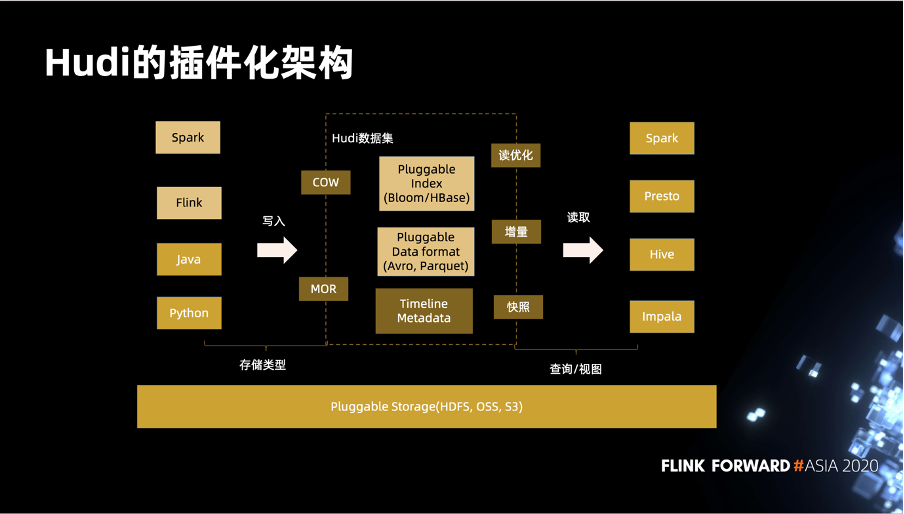
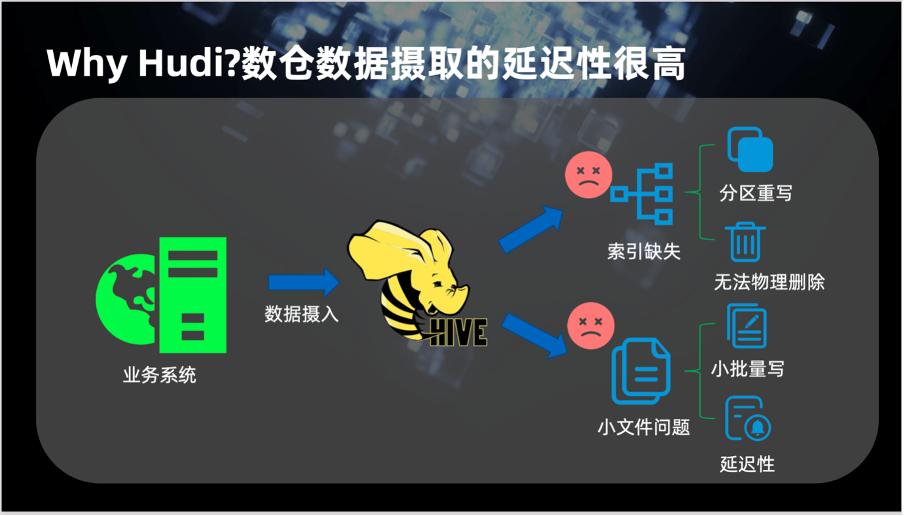
在存储方面,Hudi 可以支持 HDFS,OSS 和 S3。
在数据处理引擎方面,Hudi 支持 Flink 和 Spark。Java 和 Python 客户端已经在社区支持中。Hudi 支持两种表,COW 和 MOR,这两种表分别对应低延迟的查询和快速摄入两种场景。
在索引方面,Hudi 支持 Bloom 和 HBase 等 4 种索引类型。底层用了 Parquet 和 Avro 存储数据,社区还正在做 ORC 格式的支持以及 SQL支持,相信不久的将来会跟大家见面。
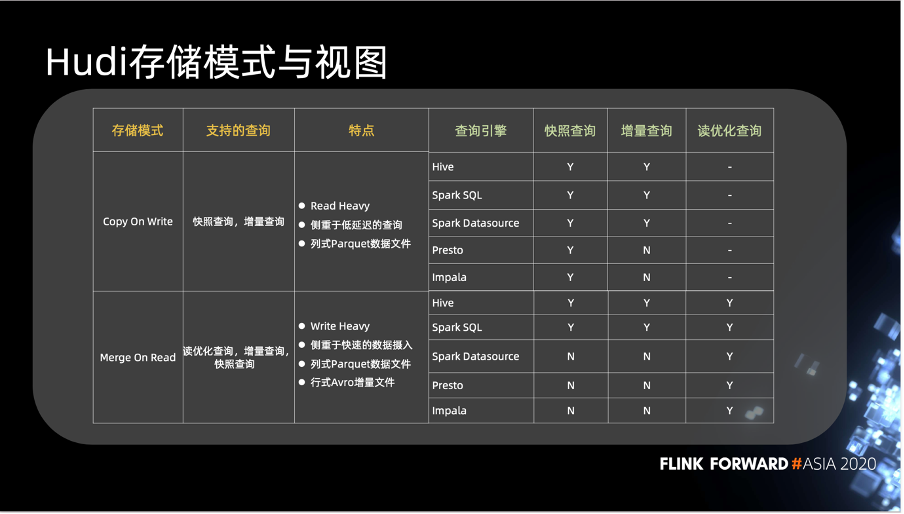
第一个是 Copy On Write 模式,对应到 Hudi 的 COW 表。它是一种侧重低延时的数据查询场景的表,底层使用 Parquet 数据文件存储数据,能够支持快照查询和增量查询两种查询方式。在查询引擎方面,大家可以看到上面有 5 个引擎,他们对快照查询、增量查询和读优化 3 种视图都有不同程度的支持。
Merge On Read 表对 Copy On Write 有不同层面的互补,可以看到它侧重于快速的数据摄入场景。使用 Parquet 文件来存储具体的数据,使用行式 Avro 增量文件来存储操作日志,类似于 HBase WAL。它支持 Hudi 所有 3 种视图,可以看到 Hive,Spark SQL,Spark Datasource, Presto 和 Impala 对于读优化查询都是支持的。而 Hive, Spark SQL 只支持到了快照查询。这种组件支持的信息大家以后可以到官网上查询。
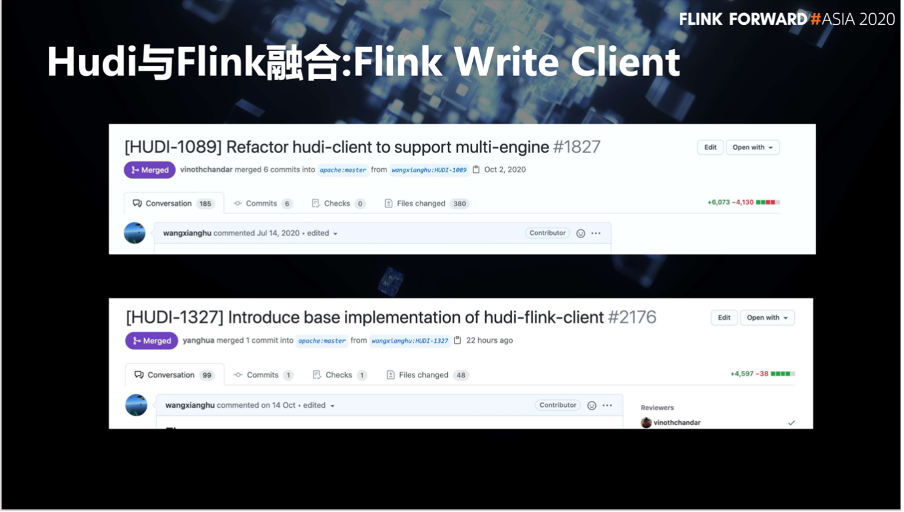
第一个 Hudi client 支持多引擎,将 Hudi 与 Spark 解耦,让 Hudi 支持多引擎成为可能。
第二个是 Flink 客户端基本实现贡献到社区,让 Hudi 可以真正意义上写入 Flink 数据表。这 2 个改动非常大,加在一起已经超过了 1 万行的代码,也可以说是今年 Hudi 社区比较亮眼的一个特性。


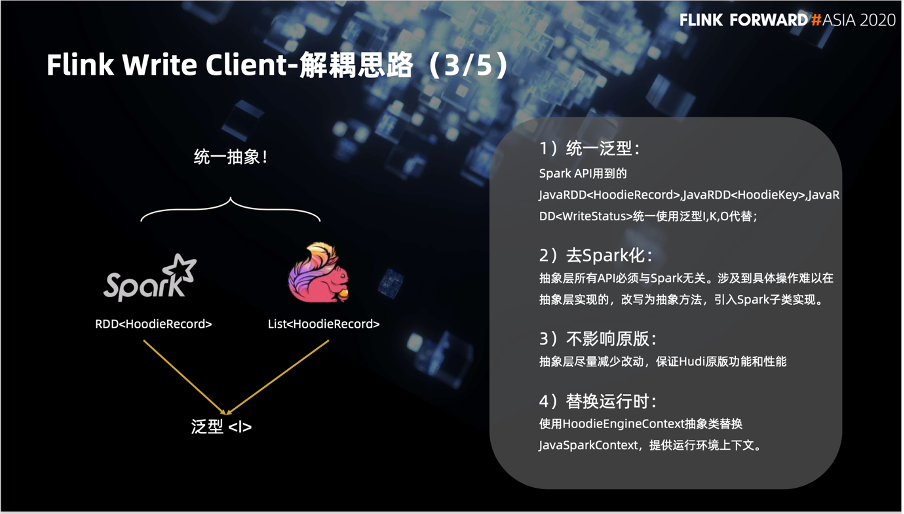
统一使用泛型 I、K、O 代替。
去 Spark 化,抽象层 API 都是引擎无关的,难以在抽象层实现的,我们会把它改为抽象方法下推到 Spark 子类实现。
不影响原版,抽象层尽量的减少改动,以保证固定的功能性。
引入 HoodieEngineContext 代替 JavaSparkContext, 提供运行时的上下文。
下面说 Flink Client DAG,这里主要分了 5 部分,
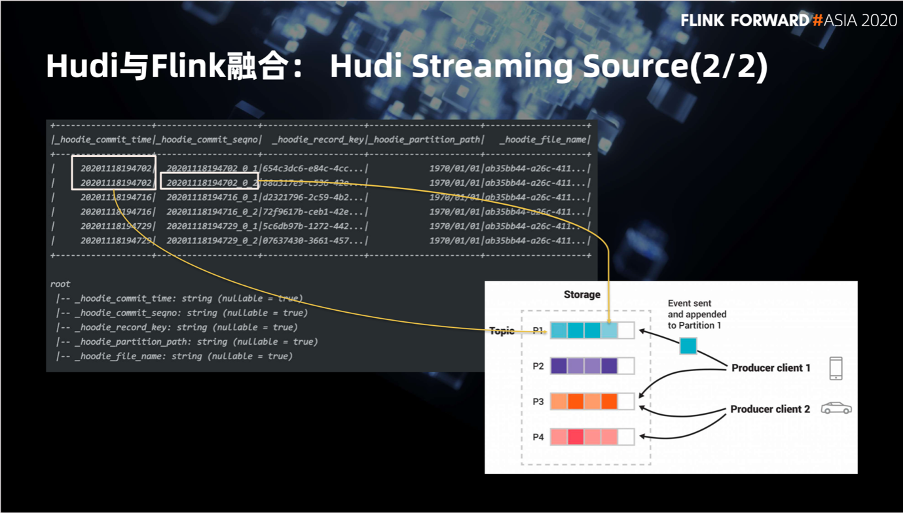
第一部分是 Kafka Streaming Source,主要用来接收Kafka数据并转换成 List<HoodieRecord>。
第二个是 InstantGeneratorOperator,一个 Flink 算子, 用来生成全局唯一的 instant。
第三是 KeyBy 分区操作,根据 partitionPath 分区避免多个子任务将数据写入同一个分区造成冲突。
第四个是 WriteProcessOperator,这也是我们自定义的一个算子。这个算子是写操作实际发生的地方。
第五个是 CommitSink,他会接受上游 WriteProcessOperator 发来的数据,根据上游数据判断是否提交事务。

可以看到 insert 函数的入参是 RDD,返回值也是 RDD。右侧抽象之后的 abstract 可以看到它的入参变成了泛型I,返回值变成了 O,有兴趣的话大家可以去了解一下。


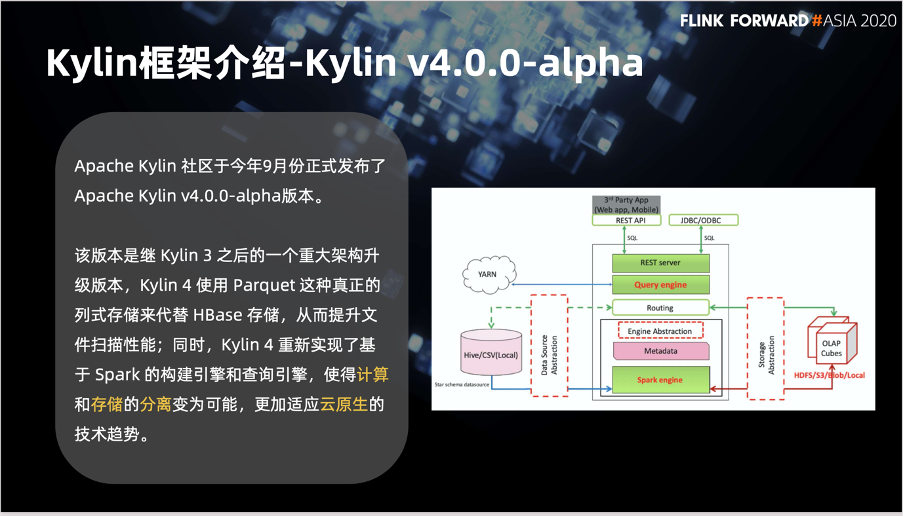
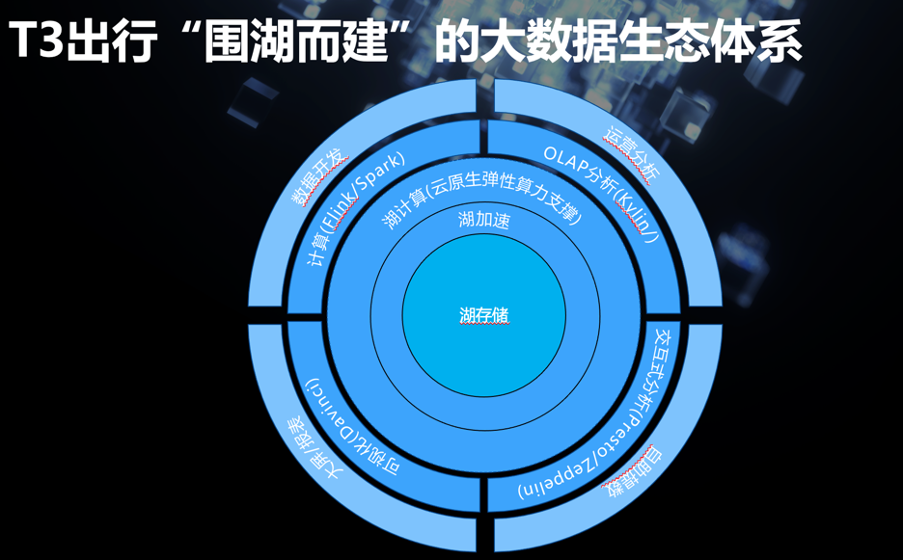
计算层我们用到了 Flink、Spark、Kylin 和 Presto 并且搭配 ES 做任务调度。数据分析和展示方面用到了达芬奇和 Zeppelin。
在存储层,我们使用了阿里云 OSS 并搭配 HDFS 做数据存储。数据格式方面使用 Hudi 作为主要的存储格式,并配合 Parquet、ORC 和 Json 文件。在计算和存储之前,我们加了一个 Alluxio 来加速提升数据处理性能。资源管理方面我用到了 Yarn,在后期时机成熟的时候也会转向 K8s。

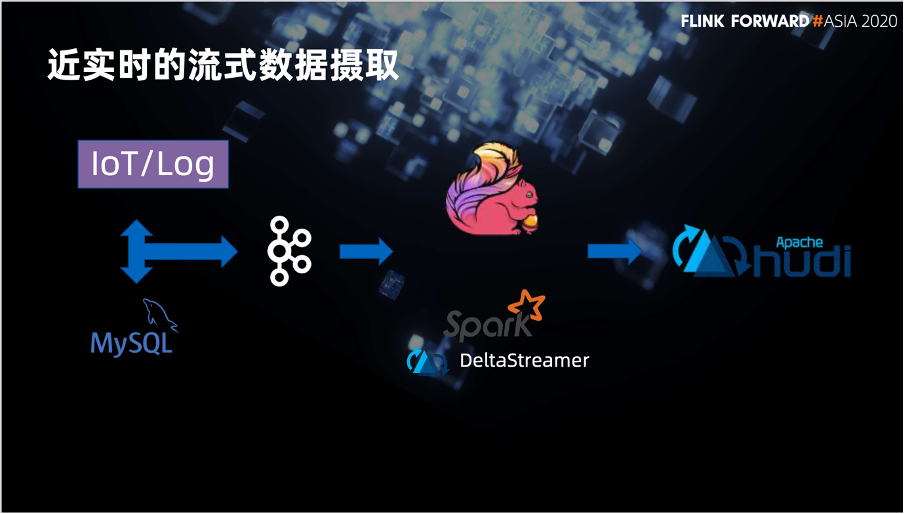
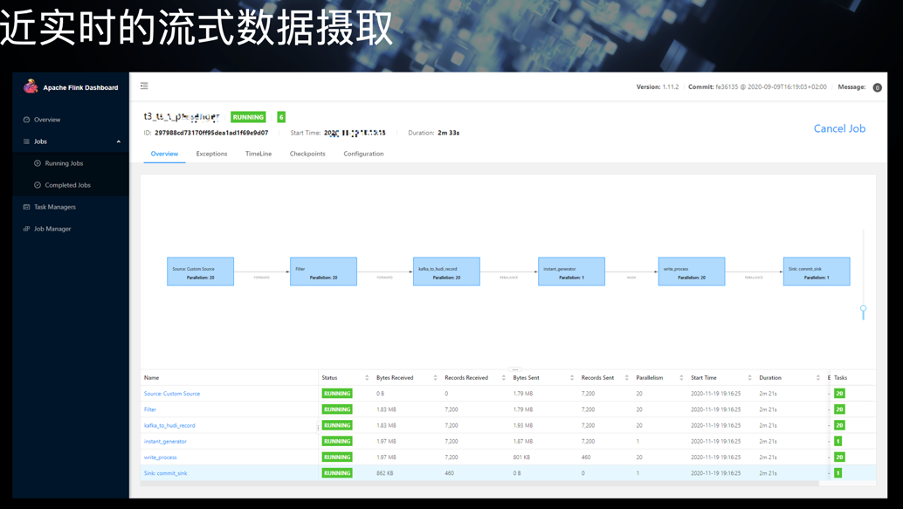
一个是近实时的流数据管道。我们可以从左侧通过 Log、MySQL 或者直接读取业务数据的 Kafka,把数据导入到数据管道中,再使用 Flink 或者原版的 DeltaStreamer 将流式数据输入到列表中。
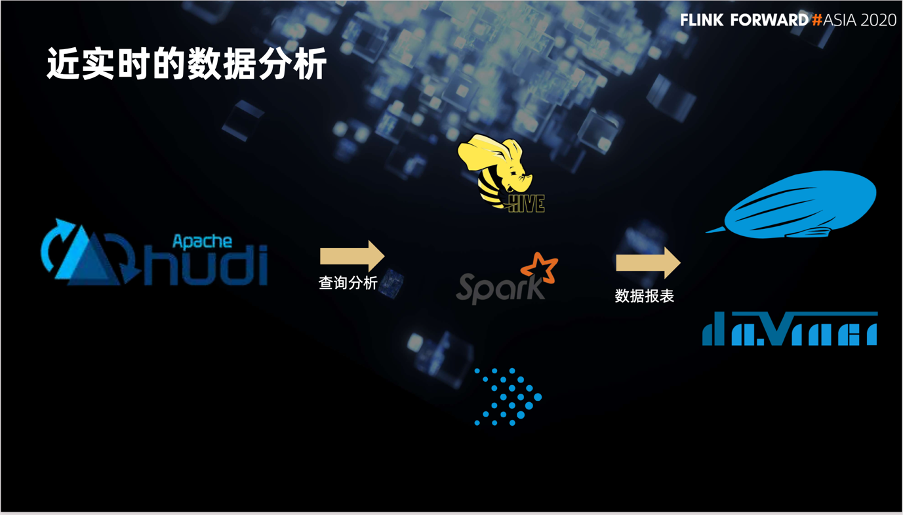
另一个是近实时的数据分析场景。我们使用 Hive、Spark 或 Presto 查询数据,并最终用达芬奇或者 Zeppelin 做最终的数据报表。
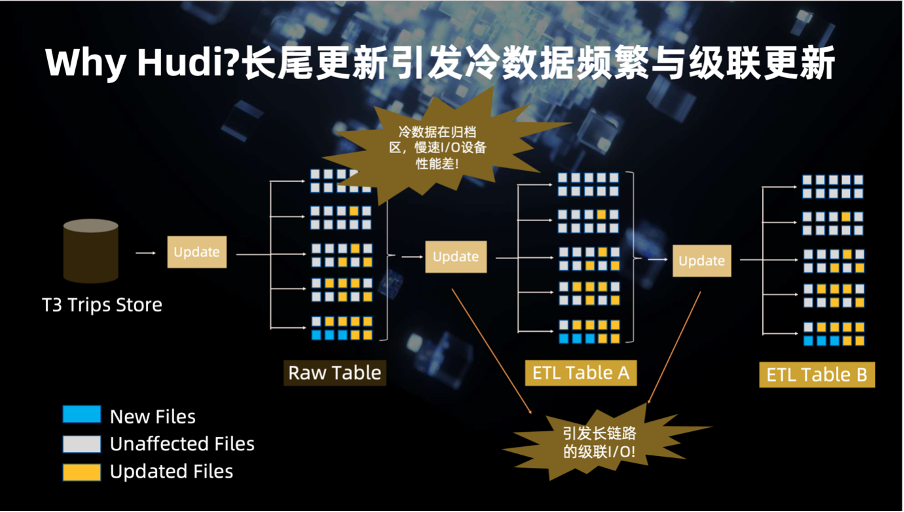
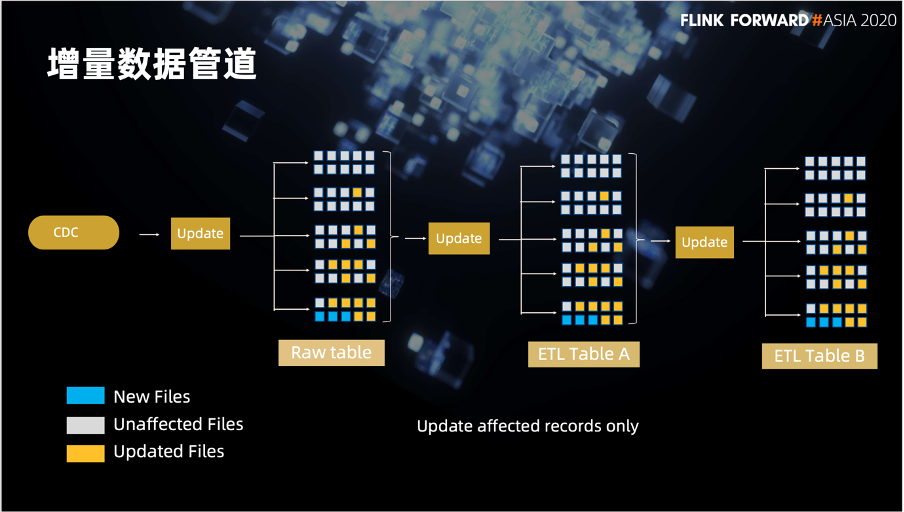
这是我们用 Hudi 构建的增量数据管道。最左侧 CDC 数据捕获之后要更新到后面的一系列的表。有了 Hudi 之后,因为 Hudi 支持索引和增量数据处理,我们只需要去更新需要更新的数据就可以了,不需要再像以前那样去更新整个分区或者更新整个表。
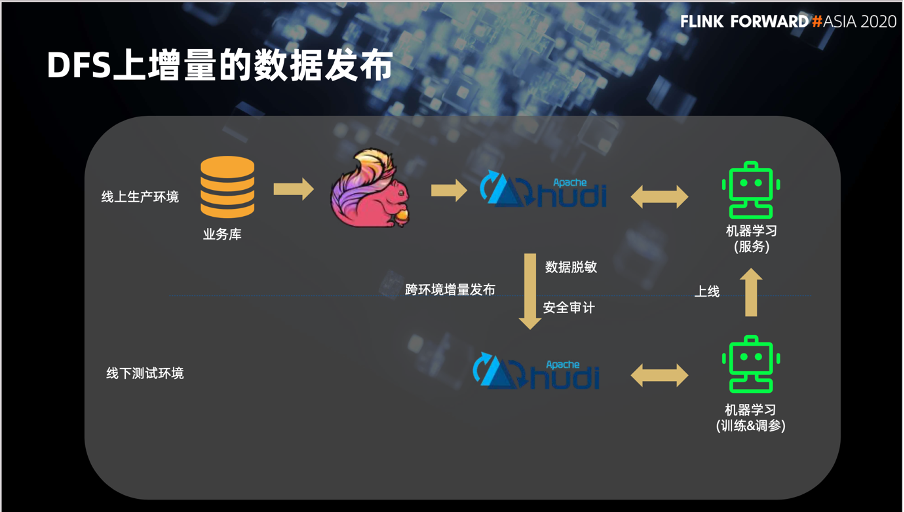
最后的一个场景是将前面介绍的用 Flink 将线上或者业务数据订阅 ETL 到 Hudi 表中供机器学习使用。但是机器学习是需要有数据基础的,所以我们利用 Hudi 将线上的数据增量发布到线下环境,进行模型训练或者调参。之后再将模型发布到线上为我们的业务提供服务。
▼ 关注「Flink 中文社区」,获取更多技术干货 ▼
 戳我,回顾作者分享视频!
戳我,回顾作者分享视频!