
PB 级数据即席查询基于 Flink 的实践


第一部分 “Threat Hunting 平台的架构与设计” 将由苏军来为大家分享; 第二部分 “以降低 IO 为目标的优化与探索” 将由刘佳来为大家分享。
一、Threat Hunting 平台的架构与设计
第一部分内容大致分为三个部分,分别是:
平台的演进 架构设计 深入探索索引结构
1. 平台的演进
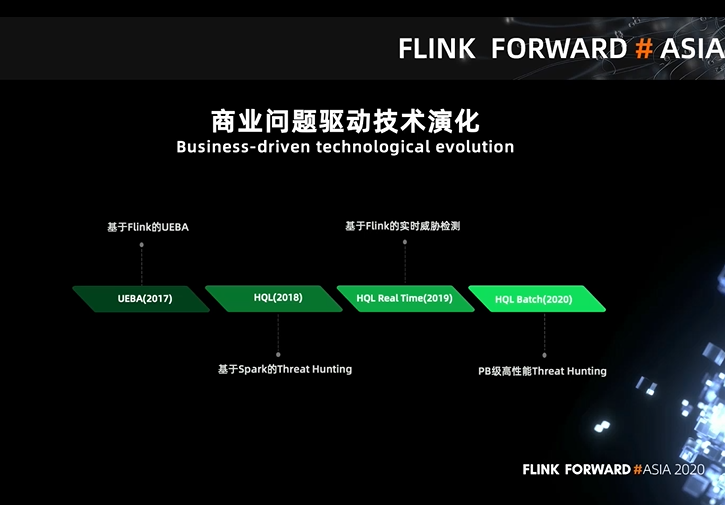
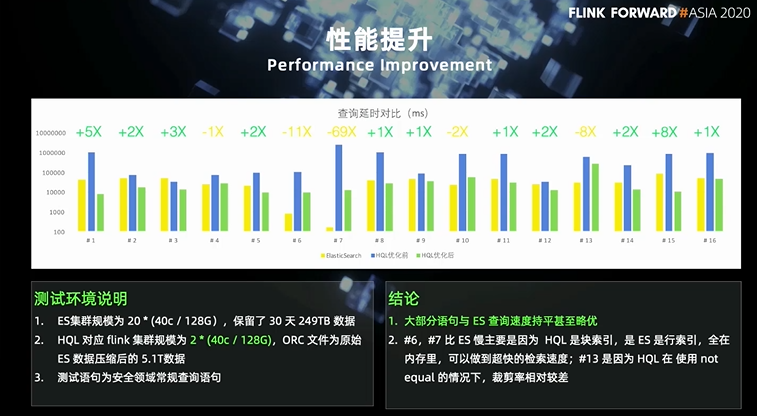
2017 年我们基于 Flink DataStream 开发了用户行为分析系统 UEBA,它是通过接入企业 IT 拓扑的各类行为数据,比如身份认证数据、应用系统访问数据、终端安全数据、网络流量解析数据等等,以用户 / 资产为核心来进行威胁行为的实时检测,最后构建出用户威胁等级和画像的系统; 2018 年基于 UEBA 的实施经验,我们发现安全分析人员往往需要一种手段来获取安全事件对应的原始日志,去进一步确认安全威胁的源头和解决方式。于是我们基于 Spark 开发了 HQL 来解决在离线模式下的数据检索问题,其中 HQL 可以认为是表达能力比 SQL 更加丰富的查询语言,大致可以看作是在 SQL 能力的基础上增加了算法类算; 2019 年随着离线 HQL 在客户那边的使用,我们发现其本身就能够快速定义安全规则,构建威胁模型,如果在离线模式下写完语句后直接发布成在线任务,会大大缩短开发周期,加上 Flink SQL 能力相对完善,于是我们基于 Flink SQL + CEP 来升级了 HQL 的能力,产生了 HQL RealTime 版本; 2020 年随着客户数据量的增大,很多已经达到了 PB 级,过往的解决方案导致离线的数据检索性能远远低于预期,安全分析人员习惯使用 like 和全文检索等模糊匹配操作,造成查询延时非常大。于是从今年开始,我们着重优化 HQL 的离线检索能力,并推出了全新的 Threat Hunting 平台。

第一是低成本的云原生架构。我们知道目前大部分的大数据架构都是基于 hadoop 的,其特点是数据就在计算节点上,能够减少大量网络开销,加速计算性能。但是整个集群为了做到资源均衡,往往需要相同的资源配置,且为了能够存储尽量多的数据,集群规模会很大, 所以这类架构在前期需要投入大量硬件成本。 而存算分离和弹性计算则能够解决这一问题,因为磁盘的价格是远低于内存和 CPU 的,所以用廉价的磁盘存储搭配低配 CPU 和内存来存储数据,用少量高配机器来做计算,可以在很大程度上降低成本。 第二是低延时的查询响应。安全分析人员在做威胁检测时,大部分时间是即席查询,即通过过滤、join 来做数据的检索和关联。为了能够尽快的获取查询结果,对应的技术方案是:列存/索引/缓存。 列存不用多说了,是大数据领域常见的存储方案; 在列存的基础上,高效的索引方案能够大量降低 io,提高查询性能; 而存算分析带来的网络延时可以由分布式缓存来弥补。 第三是需要丰富的查询能力,其中包括单行的 fields/filter/udf 等,多行的聚合 /join,甚至算法类的分析能力,这部分我们主要依赖于自己开发的分析语言 HQL 来提供。
2. 架构设计
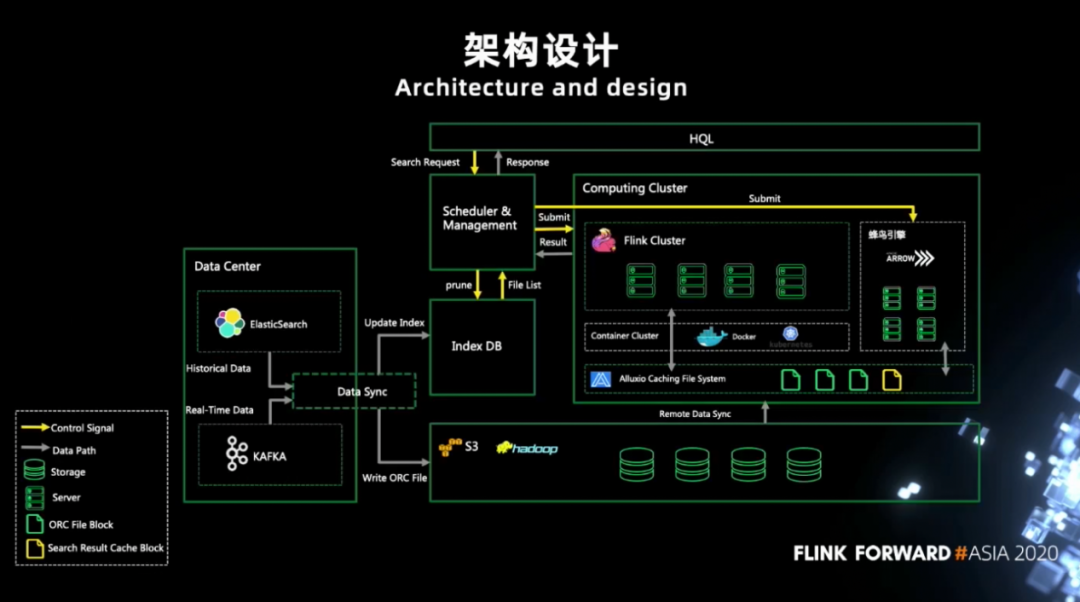
如果分析语句的输入是已经算好并且 cache 好了的中间结果,那么直接读取缓存来继续计算; 如果不能命中,证明我们必须从 orc 文件开始重新计算。
第一点是索引数据库会返回一批符合该条件的文件列表,如果文件列表非常大的话,当前的 Flink 版本在构建 job graph 时,在获取 Filelist Statistics 逻辑这里在遍历大量文件的时候,会造成长时间无法构建出 job graph 的问题。目前我们对其进行了修复,后期会贡献给社区。 第二点是数据缓存那一块,我们的 HQL 之前是通过 Spark 来实现的。用过 Spark 的人可能知道,Spark 会把一个 table 来做 cache 或 persist。我们在迁移到 Flink 的时候,也沿用了这个算子。Flink 这边我们自己实现了一套,就是用户在 cache table 时,我们会把它注册成一个全新的 table source,后面在重新读取的时候只会用这个新的 table source 来打通整个流程。
3. 深入探索索引结构


第一是 transaction。我们知道列存文件往往是无法 update 的,而我们在定期优化文件分布时会做 Merge File 操作,为了保证查询一致性,需要数据库提供 transaction 能力。 第二是性能。数据库拥有较强的读写和检索能力,甚至可以将谓词下推到数据库来完成,数据库的高压缩比也能进一步节省存储。

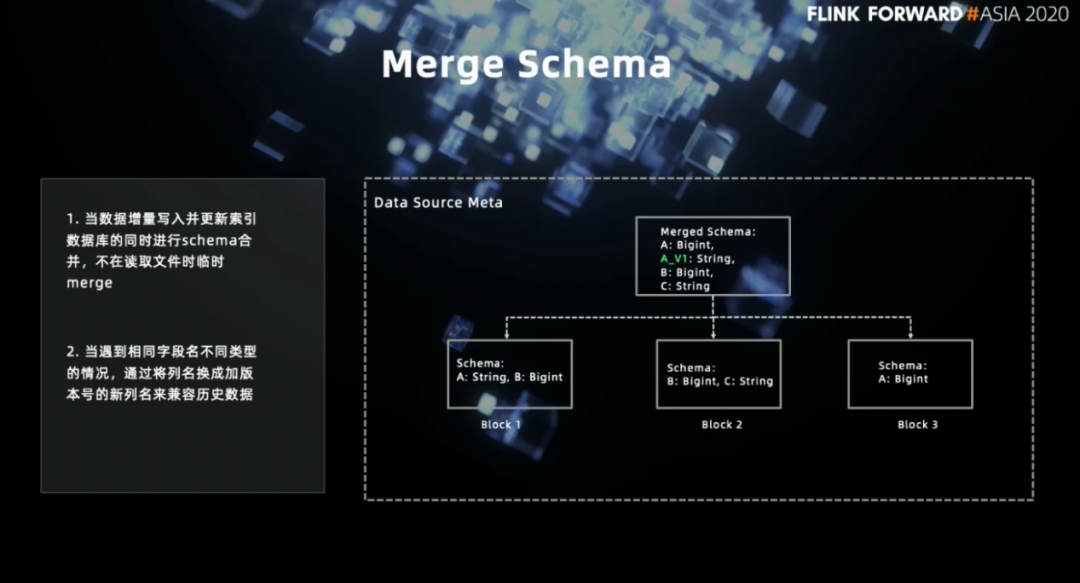
二、以降低 IO 为目标的优化与探索
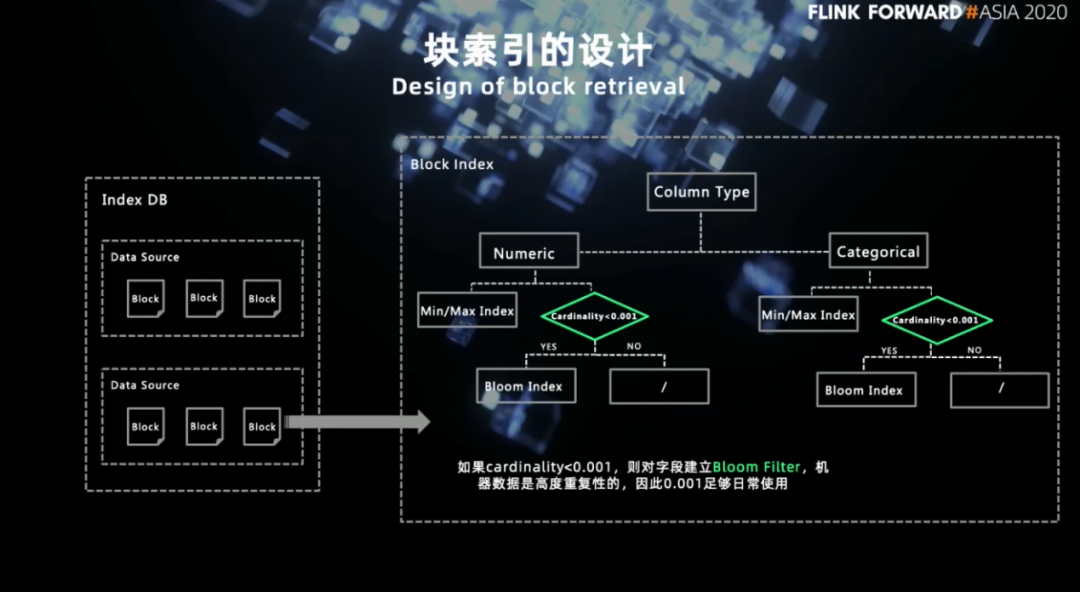
上文介绍了为什么要选择块索引,那么接下来将具体介绍如何使用块索引。块索引的核心可以落在两个字上:“裁剪”。裁剪就是在查询语句被真正执行前就将无关的文件给过滤掉,尽可能减少进入计算引擎的数据量,从数据源端进行节流。
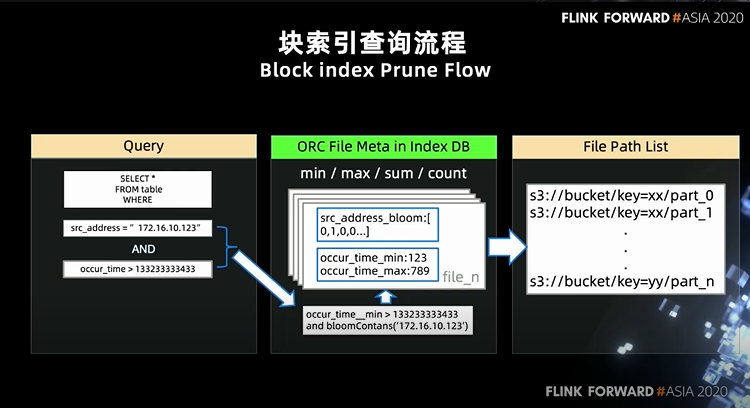
第一步是解析查询语句。获取到相关的 filter,可以看到最左边的 SQL 语句中有两个过滤条件, 分别是 src_address = 某个 ip,occur_time > 某个时间戳。 第二步将查询条件带入 Index DB 对应数据源的 meta 表中去进行文件筛选。src_address 是字符串类型字段,它会联合使用 min/max 和 bloom 索引进行裁剪。occur_time 是数值类型字段并且是时间字段,我们会优先查找 min/max 索引来进行文件裁剪。需要强调的是, 这里我们是将用户写的 filter 封装成了 index db 的查询条件,直接将 filter pushdown 到数据库中完成。 第三步在获取到文件列表后,这些文件加上前面提到的 merged schema 会共同构造成一个 TableSource 来交给 Flink 进行后续计算。

第一点,数据在未排序的情况下,裁剪率是有理论上限的,我们通过在数据写入的时候使用 hilbert 曲线排序原始数据来提升裁剪率; 第二点,因为安全领域的特殊性,做威胁检测严重依赖 like 语法,所以我们对 orc api 进行了增强,使其支持了 like 语法的下推; 第三点,同样是因为使用场景严重依赖 join,所以我们对 join 操作也做了相应的优化; 第四点,我们的系统底层支持多种文件系统,所以我们选取 Alluxio 这一成熟的云原生数据编排系统来做数据缓存,提高数据的访问局部性。
1. 裁剪率的理论上限及 Hilbert 空间填充曲线
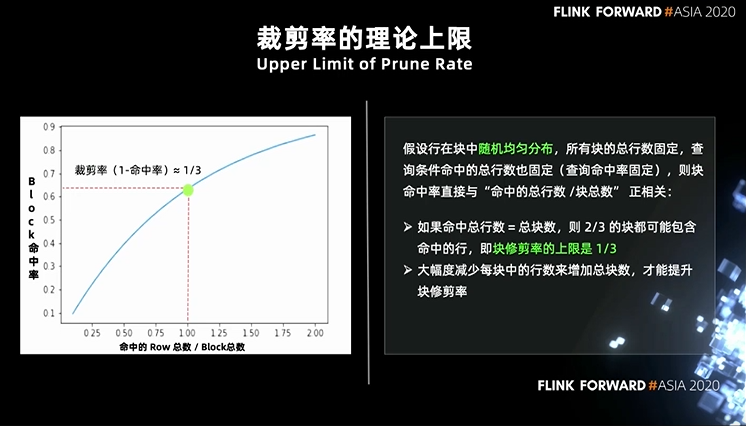
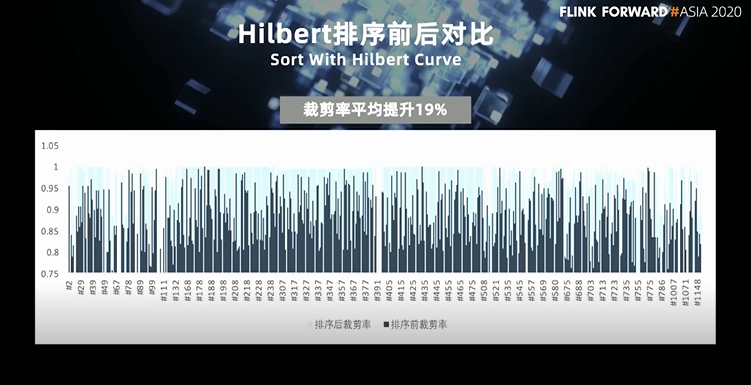
第一点,如果命中总行数 = 总块数,即 X 轴值为 1 的时候,命中率为 2/3, 也就是 2/3 的块,都包含命中的行,对应的块修剪率的上限是 1/ 3。1/3 是一个很低数值,但是由于它的前提是数据随机均匀分布,所以为了让数据分布更好,我们需要在数据写入时对原始数据进行排序。 第二点,假设命中总行数固定,那么大幅度减少每块中的行数来增加总块数,也能提升块修剪率。所以我们缩小了块大小。根据测试结果,我们设定每个文件的大小为:16M。缩小文件大小是很简单的。针对排序,我们引入了 hilbert 空间填充曲线。
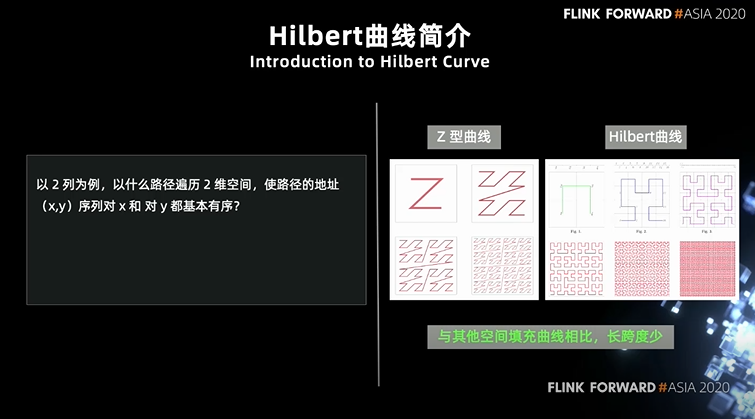
首先是,以什么路径遍历 2 维空间,使路径的地址序列对其中任一维度都基本有序?为什么要对每一列或者说子集都有序?因为系统在使用的过程中,查询条件是不固定的。数据写入时排序用到了 5 个字段,查询的时候可能只用到了其中的一个或两个字段。Hilbert 排序能让多个字段做到既整体有序,又局部有序。 另外,空间填充曲线有很多,还有 Z 形曲线、蛇形曲线等等,大家可以看看右边这两张对比图。直观的看,曲线路径的长跨度跳跃越少越好,点的位置在迭代过程中越稳定越好。而 hilbert 曲线在空间填充曲线里面综合表现最好。
2. 字典索引上 Like 的优化
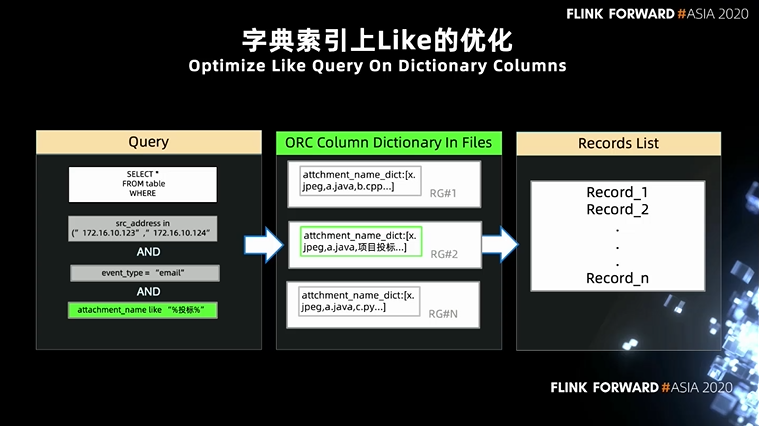
首先我们为 ORC api 添加了 like 条件表达式,保证 SQL 中的 like 能下推到 orc record reader 中。 其次,重构了 orc record reader 的 row group filter 逻辑,如果发现是 like 表达式,首先读取该字段的 dict steam,判断 dict stream 是否包含 like 目标字符串,如果字典中不存在该值,直接跳过该 row group,不用读取 data stream 和 length steam,能大幅提高文件读取速度。后期我们也考虑构建字典索引到索引数据库中,直接将字典过滤 pushdown 到数据库中完成。
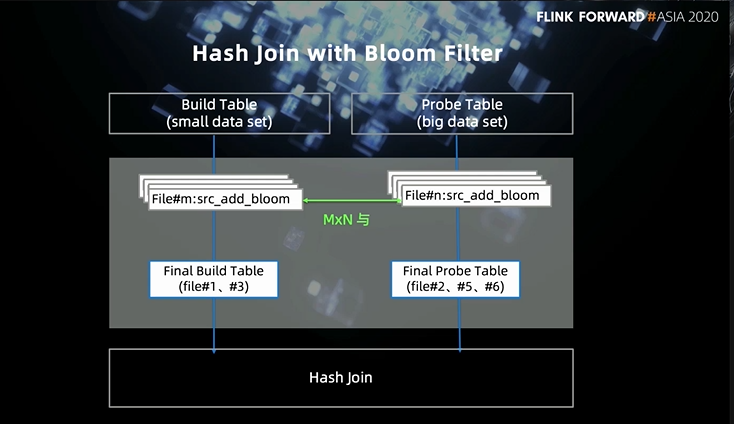
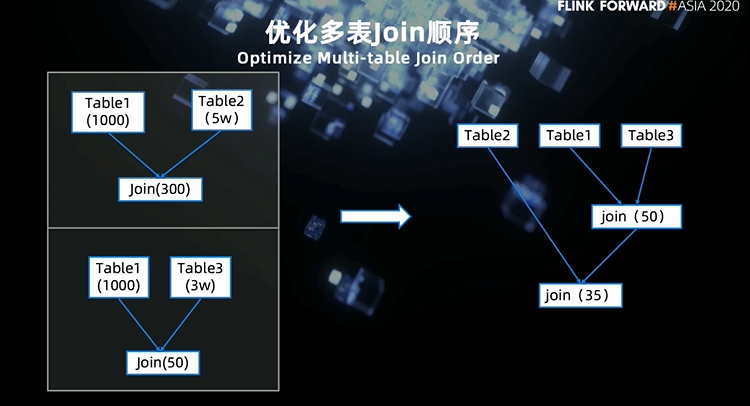
3. 基于索引对 join 的优化
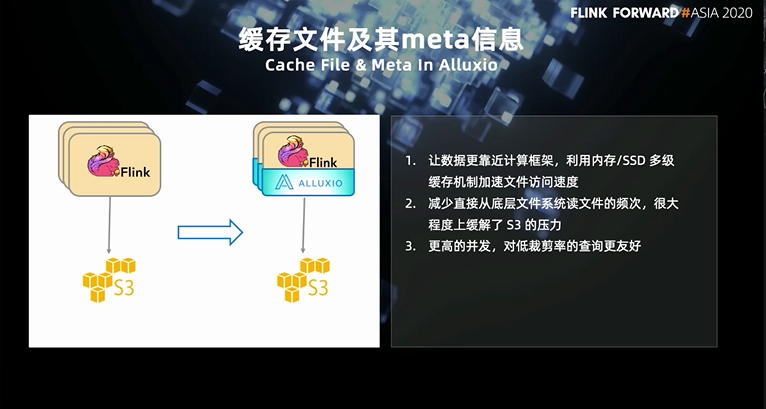
4. Alluxio 作为对象存储的缓存
三、未来规划

评论