撰稿 | 黄威、张佳琦(鹏城实验室访问学生)
人工智能的蓬勃发展推动了其在各个领域的广泛应用,在机器视觉、自动驾驶、棋盘游戏和临床诊断等各个领域取得了巨大的成功,但数据量的飞速增长使智能实现面临速度慢、能耗高的问题。冯·诺依曼架构的摩尔定律逐渐不再有效,集成电子电路算力也慢慢无法应对未来数据量爆炸性的增长,海量数据洪流的时代渐渐淘汰旧的芯片规则约束,正催生芯片架构进行一次巨大的革新。光学计算利用光场仿真人工智能的实现过程,相较于电子计算,具有高速、高宽带、低功耗的优点,为解决这一瓶颈问题提供了一种独特的方式。比如通过光频梳对不同波长的数据或权重进行编码,单个时间步长的操作可以自然而然地同时应用于数千甚至数百万个不同信道。得益于现代图形处理器(GPU)强大的运算和并行计算能力以及广泛开源的数据集,模拟人工智能的光学计算成为可能。在即将到来的第五代移动通信技术(5G)时代,大量的传感器和互联网连接设备每秒都会产生大量的数据,这些数据需要由人工智能以尽可能快的速度处理。神经网络是由成千上万个甚至数百万个相互连接的多层神经元组成的典型的人工智能模型,可以学习具有多层次抽象特征的数据,结构也在变得越来越复杂。为了解决这一公认的困难,近年来研究者在电子架构创新方面进行了各种努力,以加速低功耗下的人工智能推理和训练。近期,来自清华大学、香港科技大学和鹏城实验室的科研工作者回顾并总结了实现人工智能模拟的光学计算在不同人工智能模型中的最新突破,主要涵盖了模拟前馈神经网络、蓄水池神经网络和脉冲神经网络相关的光计算,讨论了当前技术的可行性,并指出了不同领域的各种挑战。其综述以 “Analog optical computing for artificial intelligence”为题发表于中国工程院的院刊 Engineering,该论文的共同第一作者是清华大学的吴嘉敏博士,林星博士和郭雨晨博士,共同通讯作者是清华大学戴琼海院士和方璐教授以及鹏城实验室焦述铭博士,此外香港科技大学的刘军伟老师也参与了论文的撰写。1. 前馈光神经网络(ONN)
前馈神经网络采用一种单向多层结构,其中每一层包含若干个神经元,在这种人工神经网络中,相邻层的所有神经元都通过不同的突触权值相互连接,各神经元可以接收前一层神经元的信号,并传送到下一层。其特点在于整个网络中没有反馈,信号从输入层向输出层单向传播,可以用一个有向无环图表示。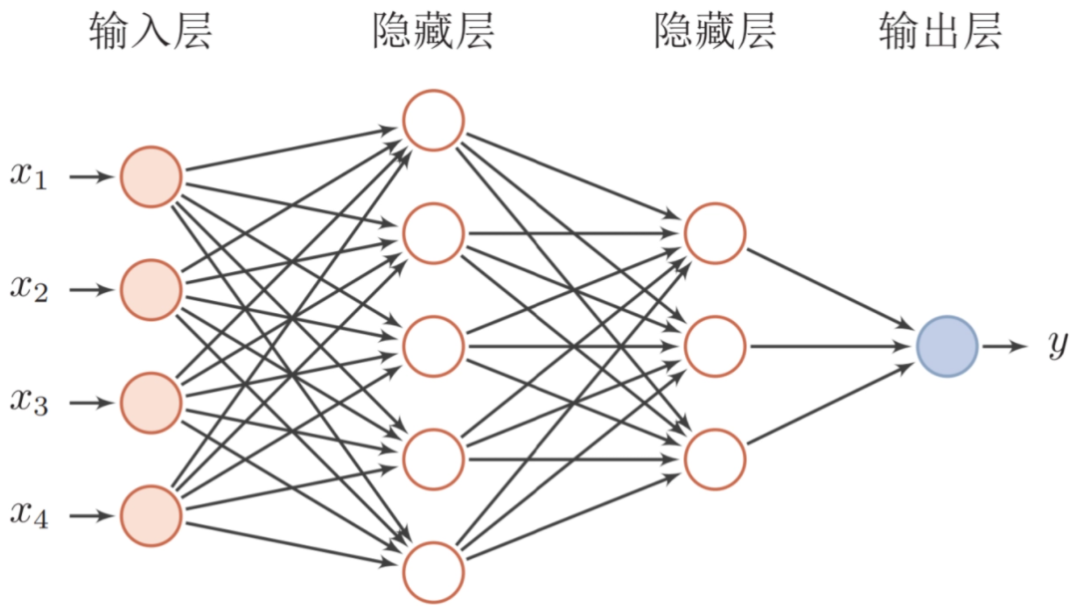
目前,基于前馈神经网络进行的光计算研究主要集中在以下四个方面进行的:光学线性加权总和、光学线性卷积、光学非线性激活函数和光学系统上的在线网络训练。对于全连接神经网络的光学实现,需要在光学上执行加权求和运算或向量矩阵乘法运算。到目前为止,已经有几种不同的光学加权求和的实现方式,具体来说有以下几种。第一种,级联马赫·曾德尔干涉仪类光网络。网络中多个马赫·曾德尔干涉仪相互级联,构成一个矢量矩阵乘法的光学计算装置。马赫·曾德尔干涉仪的基本概念可以追溯到1994年的早期工作,最初主要被用来作为光纤中的波分复用器。在最近的研究中,研究人员提出了一个包含56个硅光子集成电路的可编程纳米光子处理器,每个子处理器相当于一个马赫·曾德尔干涉仪,每个干涉仪又包含两个分束器和两个可调的移相器,这样的光学网络可以等效数学中的奇异值分解的矩阵运算。需要注意的是,一个马赫·曾德尔干涉仪并不等同于人工神经网络中的一个神经元,但一个级联马赫·曾德尔干涉仪网络可以在同一网络中的两层神经元之间执行等效的线性向量-矩阵乘法运算,如下图所示。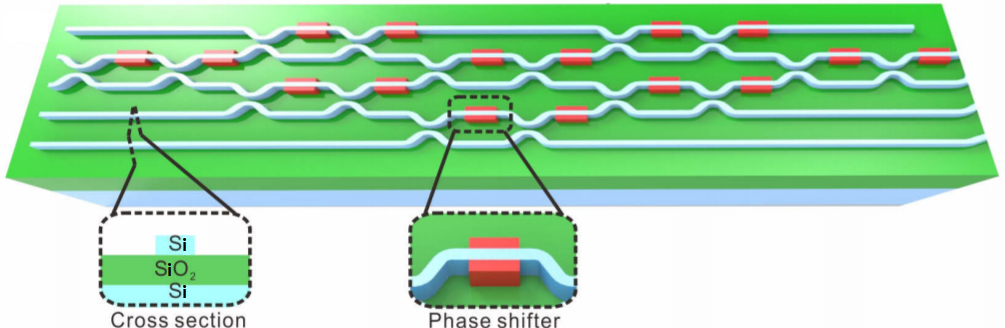
计算某一组向量矩阵相乘时,所构造的级联马赫·曾德尔干涉仪网格架构并不是唯一的,这样就允许我们为相同的向量矩阵计算设计两个不同的级联马赫·曾德尔干涉仪网格,各自分别的特征可以是可调性更强或容错性更强。通过3D打印加工光波导,级联马赫·曾德尔干涉仪系统可以从二维扩展到三维,以实现更高的计算能力。除此之外,复数计算操作也可以通过级联马赫·曾德尔干涉仪有效地实现。级联马赫·曾德尔已被尝试用于多种人工智能任务,如语音识别、花卉数据分类和葡萄酒数据分类等。第二种,深度光衍射神经网络(D2NN)。在D2NN网络结构中,多层级联光衍射调制板垂直于光的传播方向并以一定的空间间隔平行放置,输入平面和输出平面上的空间光强分布分别对应于输入向量和输出向量,如下图所示。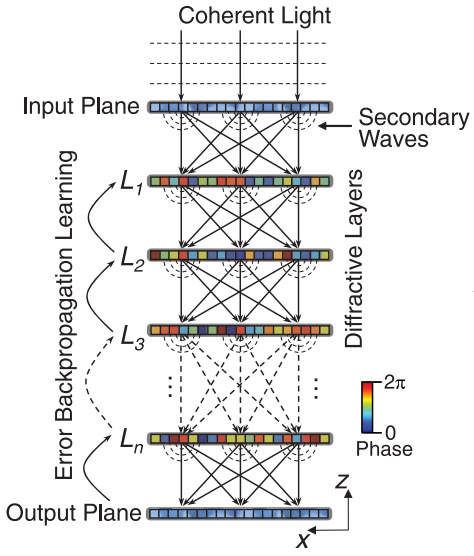
入射光场在自由空间中向前传播,并由每个调制板依次调制。所有衍射光学元件的像素值(相位、振幅或复振幅)通过类似于深度学习中对应的误差反向传播算法进行优化。优化后的整个系统从输入光场到输出光场进行线性变换,实现向量矩阵乘法。通常,一个多层级联衍射调制板系统的信息处理能力与总的层数正向关联。该系统可以作为光学线性分类器,并已被证明能够对MNIST数据集中的数字图像进行光学分类,并在Fashion- MNIST数据集中对服装图像具有中等较高的分类精度。在后续的工作中,D2NN神经网络系统从不同的方面得到了改进和提升。最初D2NN由太赫兹光源驱动,后来尺寸更小的红外和可见光光源系统也被使用。D2NN的实现也不局限于单色相干光照明,宽带D2NN还可以实现用于光谱滤波和波长解复用应用。有的研究人员将D2NN与数字处理器或数字神经网络相结合以提高预测性能。仿照残差深度学习网络的残差D2NN也被提出来,并用多个反射镜简单地实现了输入和输出之间的直接快捷连接。有研究人员针对训练集图片进行几何变换后训练D2NN系统,结果表明D2NN可对于图像的平移、旋转和缩放有一定鲁棒性。大量的研究结果表明,一个D2NN系统可以处理多样化的计算机视觉任务,除目标分类之外,还有图像分割、图像显著性检测以及图像超分辨。除了传统的机器学习任务外,还有研究人员将D2NN应用于其他光计算和光信号处理任务,比如激光雷达的智能光束转向、图像加密、光逻辑门、脉冲整形和模分复用光纤通信中的模式识别/复用/解复用等等。第三种,基于空间光调制器和透镜的光学计算。与之前两种基于相干光设计的架构不同,这种基于空间光调制器和透镜的架构可以使用相干或非相干光照明。入射光在空间光调制器平面的强度分布相当于输入向量值,根据加权系数对空间光调制器的不同像素进行编码,光束依次通过空间光调制器和透镜聚焦到焦点。将探测器放置于透镜焦点上,然后收集空间光调制器平面上的总光强,其结果相当于输入向量和加权系数向量之间的内积。该架构如下图4(a)所示,类似于光学成像中的单像素成像的概念。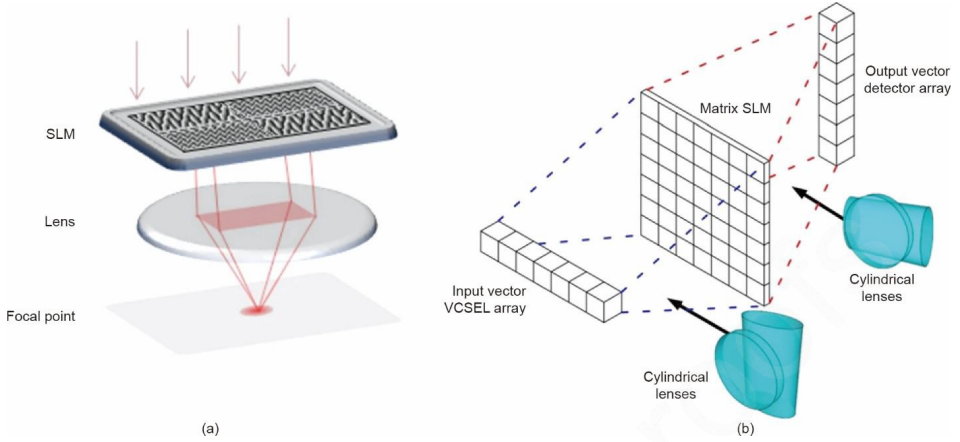
通过使用不同类型的透镜,可以有多种方法来实现复数矩阵乘法,如使用一个傅立叶透镜得到输出光的总和,或使用柱面透镜。柱面透镜只在水平方向或垂直方向上对平行光和会聚光之间进行转换。输入向量由沿水平方向像素化阵列的光强分布表示。两个柱面透镜在空间光调制器平面上执行一维输入阵列的复制和一维加权求和,如图4 (b)所示,输出结果最后通过焦平面上沿垂直阵列的光强分布来表示,这实现了多个线性加权求和操作的并行处理。此外,向量矩阵乘法可以通过简单地用单个傅里叶透镜多次重复加权求和运算来实现。基于空间光调制器和透镜的架构,可以很容易与冷原子系统相结合以实现一个同时具有线性和非线性变换的全光学深度神经网络。基于该架构,有研究人员构建出一个具有174个光学神经元的大规模可编程全光深度神经网络。与其他体系结构相比,这种实现方式对于不同的任务完全可重复编程,而无需改动物理器件。第四种,波分多路复用(WDM)实现线性加权总和。输入向量中的每个元素都由一个具有特定频率(或波长)的光波强度表示,然后通过通常由微环谐振器(MRRs)构造的光子权重阵列对其进行不同的光谱滤波,从而对输入信号进行加权。最终如下图所示,平衡光电二极管(BPD)通过采集不同波段中所有信号的总光功率实现加权线性求和。这种体系结构被认为可能与主流的硅光子器件平台兼容。在最近的工作中,WDM架构与基于光子芯片的微频梳相结合,可以显著提高数据处理速度和容量。非易失性相变材料也被集成到波导上以实现在芯片上局部存储加权值。最近发表在Nature上论文展示基于这一框架的光向量卷积加速器每秒可以执行超过10万亿次的操作。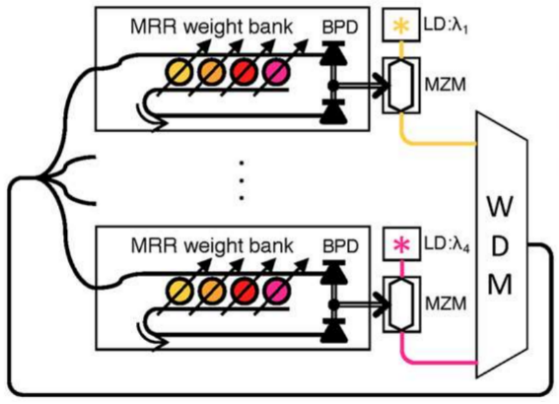
另外,光的向量矩阵乘法运算,也可以通过光在纳米光子介质的传播实现,进入介质的输入光强空间分布表示输入图像模式。光场通过介质后的输出强度空间分布表示计算结果(如图像分类结果)。介质由主体材料和不同折射系数的掺杂物组成,掺杂物对光的散射更强。通过适当优化掺杂物的位置和形状,可以将介质内的光场散射,实现矢量与权重矩阵的乘法。与全连接的神经网络相比,卷积神经网络(CNN)中的神经元的连接更稀疏。此外,多个连接可以共享相同的权重值。CNN中相邻两层神经元之间的向量矩阵乘法运算本质上是一种卷积运算。在数学上,输入图像和核之间的卷积等价于输入图像的傅里叶滤波。在光学中,包含图像信息的输入光场的傅里叶变换和傅里叶反变换可以很容易地通过4f双透镜系统来实现。根据卷积核而设计的滤波掩膜可以放置在4f设置的傅里叶平面上。一些研究中也中进一步实现了在傅里叶域内进行卷积的广义光子张量操作处理器。卷积操作也可以通过其它方式实现,如级联声光调制器阵列、波分复用加光延迟线或色散诱导延迟等。如果一个神经网络是完全线性的,没有任何非线性激活函数,那么即使物理上存在多层线性变换,其有效的计算也只等价于单层,因为多个矩阵的乘法结果仍然是一个单一的矩阵。为了实现全光深度神经网络,实现非线性激活函数是必不可少的。但光学中的非线性过程不容易通过实验实现,这使得以可行方式实现非线性激活功能成为光学神经网络研究中最具挑战性的问题之一。在许多光学神经网络研究中,只有线性操作是光学实现,非线性操作通常是模拟实现的。一般来说,非线性激活函数可以由电子元件和光学元件组成的混合系统实现,但由于光学信号和电子信号之间的相互转换,这种方法不可避免地降低光学计算的性能。理想的方案是使用纯光学元件实现非线性激活函数,最近研究中,电磁诱导透明(EIT)的使用证明了光学实现非线性层的实际可行性。如下图所示,EIT是指一束光在介质中的穿透能力由另一束光所控制的非线性光学现象。理论上,EIT可以发生在任何具有三重态的真实材料系统中,其中不同状态之间的跃迁概率振幅取决于它们的粒子分布。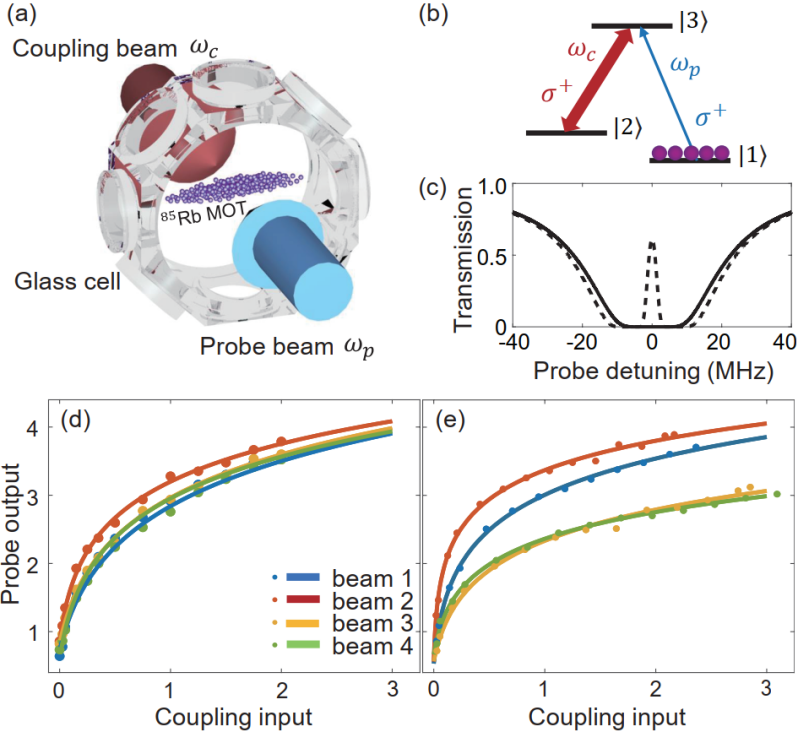
一个深度学习网络通常首先需要大量的样本进行训练,以优化所有的权重系数。经过训练后,网络可以对样本有效地执行一定的预测任务。在许多光学神经网络的相关研究中,训练在计算机上完全数字化离线进行,只有光学神经网络的预测操作是通过光学实验进行的。事实上,对光学神经网络在线训练在一定程度上也可以实现。目前很多关于级联马赫·曾德尔干涉仪网格的在线训练研究已经在进行之中。误差反向传播是数字深度神经网络中应用最广泛的训练算法,在设计算法时,伴随变量法经常用于推导级联马赫·曾德尔干涉仪网格的反向传播算法。在训练中,梯度可以通过级联马赫·曾德尔干涉仪网格不同节点上的光强度来测量。另外,可以使用前向传播和没有反向传播的有限差分法对级联马赫·曾德尔干涉仪系统进行片上在线训练。很多研究者使用遗传算法和粒子群优化两种进化算法,对在线训练的级联马赫·曾德尔干涉仪网格参数进行优化。这些全局优化算法是无梯度的,可以避免陷入局部最优解的问题。而对于D2NN结构,在线训练方法目前也被广泛研究。深度神经网络的标准训练算法是基于误差反向传播,而通过光路可逆和相位共轭原理,通过测量前向和后向传播的光场强度,也可以在线获得梯度值。每一层静态光衍射器件可以被替换为一个空间光调制器,用于动态训练和参数更新。实际输出光场与目标光场之间的残差可以由一个复振幅光场生成器产生,用于光场反向传播。仿真结果表明,与离线计算机训练相比,在线训练方案可以明显降低计算成本。对于其他的光学神经网络架构,如果有适当的优化算法、准确的实验测量和动态编码的光学元件,也可以实现光学系统上的在线训练。2. 光蓄水池计算(RC)
与前馈神经网络相比,递归神经网络因为内部反馈回路的存在,具有记忆和联想的能力,可用于时序信息处理。蓄水池神经网络就是递归神经网络的一种,它由回声状态网络和液体状态机发展而来。由于其在处理时间序列数据方面的特殊优势,该架构在执行时序信号预测和语音识别等任务时显示出了较好适应性。蓄水池神经网络结构通常由一个固定的非线性系统组成,如蓄水池节点,它允许输入信号在高维空间中转换为时空状态。通过训练一个储存态的读取器来确定蓄水池动态,从而获得蓄水池的时间输出数据。蓄水池神经网络的内部结构如下图所示。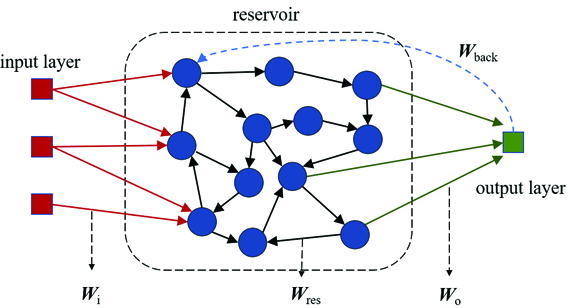
蓄水池神经网络由三层神经元构成,分别为输入层、中间层和输出层,中间层也被称为蓄水池。蓄水池层是整个神经网络中最复杂也是最重要的部分,其内部神经元的互连有着“稀疏、随机且固定”的特点:稀疏是指蓄水池层内的一个神经元不需要与其他神经元一一完全连接;随机是指不需要特意为蓄水池内部神经元设计互连架构,实际上,蓄水池内部的连接状态可以是未知的;固定是指在蓄水池训练过程中,不需要改变其内部神经元的互连权值。蓄水池的这些特点充分模拟了人类大脑中生物神经元的互连方式和动态特性。目前,关于蓄水池神经网络的光计算的研究主要集中在两个方向,一种是全光学类的蓄水池计算,另一种是光电类蓄水池的计算。所谓全光类蓄水池,就是在蓄水池神经网络中的蓄水池的实现是完全模拟光的传播过程,光电类蓄水池的计算即表示结合光电的方法实现蓄水池模型。RC的全光和光电实现之间的差异取决于不同类型的蓄水池和输入层。超高速计算和低功耗是全光RC系统的主要优点。常见的基于全光结构RC可以分为两种:空间分布的RC和基于延迟线的RC。利用衍射光学元件是实现空间分布的光子RC的一种方法。2015年,Bruner和Fischer提出的垂直腔表面发射激光器(VCSELs)网络就是典型的空间分布的RC,如下图所示。该RC结构中,VCSEL阵列晶格间距与成像透镜焦距的组合可以在相邻激光器的主射线之间形成一个角度,通过透镜的焦距来调节,从而调节衍射光学元件实现激光的耦合和衍射复用。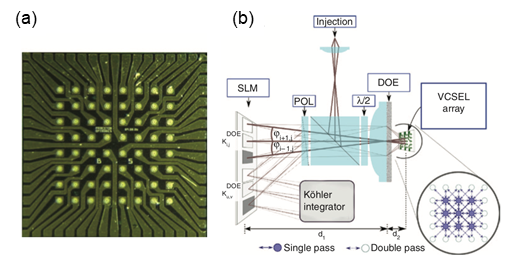
为了简化光子系统的复杂硬件,科研工作者们引入了一种新型的基于延迟线RC的光学系统,这种全光学神经网络通常需要结合半导体激光器、半导体光学放大器或者无源光腔来实现。他们将一个反馈结构分成一系列虚拟节点和一个非线性节点形成一个循环。与具有高网络自由度的空间分布式RC相比,这类蓄水池是固定的,因此一般在更传统的光通信硬件中运用较多。半导体光放大器具有丰富的内部动态,且其增益容易饱和的特点可以为神经网络提供非线性层。在研究全光类蓄水池神经网络的同时,科研工作者也在关注将光和电相结合,以设计可应用于不同场合的光电蓄水池神经网络,综述中将光电类蓄水池神经网络分为两类:片上蓄水池神经网络和自由空间蓄水池空间网络。目前,基于光电系统的蓄水池模型在语音识别、混沌时间预测和雷达信号预测等领域得到了广泛的应用。目前的光电蓄水池神经网络处理速度已经实现了兆赫兹的速度,并在可预见的未来,具有达到千兆赫兹速度的潜力。片上蓄水池,顾名思义,就是结合硬件芯片模拟蓄水池神经网络。基于硅基底的片上蓄水池神经网络在2008年就被比利时根特大学的Vandoorne等人提出,整个网络模型由波导、光学组合器和光分波器三部分组成。研究人员发现,通过标准的快速光电二极管可以在片上蓄水池神经网络中可以进行检测,并解决非线性问题。然而,由于这类系统依赖于探测器中的光电转换,因此它不能进行全光学操作。在设计片上蓄水池神网络时,经常会考虑使用无源组件,其优点在于带宽较宽,甚至可以同步地将多个波长发送到系统中,从而实现频率复用。但其缺点是随着芯片扩展到更多的节点,光损耗可能相当大,很难实现所有节点的并行测量。在无源组件网络中,输入信号时钟的频率和内存时间尺度依赖于分离节点之间的传播延迟,这将要求高达数百个Gbit/s的高注入频率。基于硬件的蓄水池神经网络的输入和输出层通常是通过计算机离线仿真的,为了在未来可以开发更为复杂的蓄水池计算机,目前科研人员已经开始尝试通过硬件模拟实现三层蓄水池神经网络包括蓄水池部分。如下图就是一个使用硬件模拟蓄水池计算机的案例,其输入层可以通过具有两种不同正弦频率的掩模来实现。输出层分别通过马赫-泽德调制器(MZM)获得光蓄水池中的信号和 RLC滤波器对平衡光电二极管的输出信号进行滤波,整个模拟系统的输出通过蓄水池计算机的终端输出。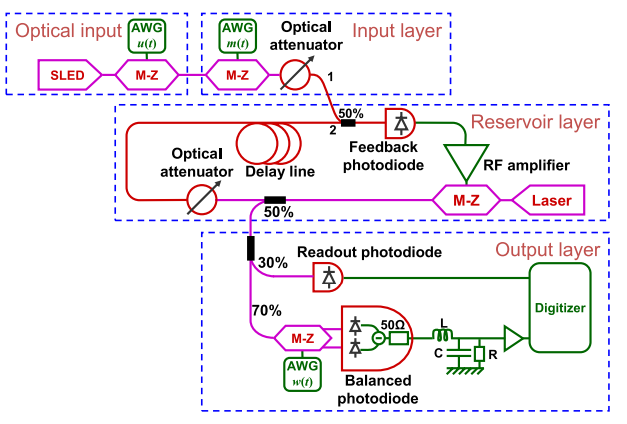
实现光电类蓄水池神经网络也可以通过光的自由空间传播实现,比如通过空间可扩展的数字微镜器件和空间光调制器实现蓄水池神经网络。2018年,Bueno等人证明了包含空间光调制器、衍射光学元件和相机的光学系统可以存储多达2500个衍射耦合光子节点的网络。Dong等人通过数字微镜器二元编码输入光强信息并调控蓄水池。后来,他们应用相同的方法,使用纯相位空间光调制器获得了一个大规模的光蓄水池网络。利用空间相位分布,蓄水池网络可以引入输入和蓄水池信息。2020年,Rafayelyan等人的科研成果表明,强散射介质在光网络中起着关键作用,以保证众多光子节点之间的随机耦合权重以及网络中的并行处理。多维大型混沌系统的预测任务已经在其大型系统中得到了验证,其具有较高的预测精度和相对较高的速度以及较低的功耗。该网络已经证明了处理更大数据集的潜在可扩展性能力。随着纳米光子学和蓄水池神经网络的复合结构的出现,一种新的光学信息处理框架正在引领这一领域,其相对于传统方法具有低功耗和超快计算速度的优点。超高速光学非线性和超低功耗光学器件也可能为光子蓄水池带来光明的未来,提升蓄水池在速度和功率效率方面的性能。此外,具有多节点蓄水池的光子芯片的可扩展性还需要在未来进一步研究。3. 脉冲神经网络
脉冲神经网络(SNNs)被认为是生物学和神经科学的交叉学科,其结构包括前馈神经网络结构和递归神经网络结构。与前馈神经网络和递归神经网络相比,SNNs在神经形态计算中得到了更广泛的应用。除了meta模型外,SNNs中的神经元只有在其膜电位达到阈值时才会被激活。当一个神经元被激活时,一个信号被产生并传递来改变级联神经元的膜电位。在SNNs中,神经元当前的激活水平通常被建模为一个微分方程。激活水平在刺激峰值到达后上升,并持续一段时间,然后逐渐下降。SNNs增强了处理时空数据的能力。一方面,SNNs中的神经元只与附近的神经元连接,并进行单独处理,以增强处理空间信息的能力。另一方面,由于训练依赖于脉冲间隔,因此可以从脉冲的时间信息中检索到二进制代码中丢失的信息,从而提高了处理时间信息的能力。事实表明,脉冲神经元是传统人工神经元更好的计算单元。然而,由于SNNs的训练和物理实施方面的困难,它们尚未得到广泛应用。大多数关于SNNs的研究工作仍然集中在理论分析和简单结构的验证上,包括SNNs的训练算法和光学硬件实现。2016年,普林斯顿大学的Prucnal研究小组提出了一种基于可激活的石墨烯光纤激光器的脉冲处理系统。该系统包含一个掺铒光纤(增益部分),一个石墨烯饱和吸收器(损耗部分),一个980nm吸收器作为泵浦源,以及一个1480nm激光器,携带脉冲激励信号来刺激系统产生触发脉冲神经元反应。2018年,该研究团队提出了一种基于分布式反馈(DFB)激光结构的神经形态光子集成电路。此外,研究小组还讨论了构建可编程和可级联光子神经网络的可行方案,包括传播-加权(B&W)网络原型和相干光学架构。其中,B&W网络原型是一种能够支持大规模光子脉冲神经元并行互连的网络架构。SNNs的训练方法主要遵循监督学习算法,包括:①SpikeProp算法,它利用梯度下降,通常用于多层前馈人工神经网络;②Tempotron 算法,利用脉冲序列输出与预期序列之间的差值来改变网络的权重;③基于突触等质体的算法,如赫边学习算法;④远程监督学习算法,如Resume算法;和⑤基于脉冲序列卷积的监督学习算法,如SPAN算法和PSD算法。2019年,Feldmann等人提出了另一种基于相变材料的脉冲神经网络方案,并采用该方案对光子神经元进行非线性变换。光控相变是一种工作状态,晶体和非晶材料之间的工作状态由输入光功率控制。当输入的光功率低于阈值时,相变材料处于晶体状态,并吸收大量的光强。当输入光功率高于阈值时,相变材料处于非晶态,大部分光功强可以通过阈值。因此,将材料集成到光传输介质中可以根据输入的光强来改变材料的光透导率。这样,它就能够作为光学神经元的激活函数。与TrueNorth、神经网格和SpiNNaker等电子实现的SNN相比,光子实现的SNN利用光处理信息,有更高的带宽和数据吞吐量以及更低的延迟。很多研究成果表明,使用硅/III-V混合平台的光电SNN可达到20GHz的处理速率,比纯电子SNN高出6个数量级以上。由于能量主要由激光源消耗,无源滤波器损耗的电流很低,硅/III-V混合平台的能量效率为0.26pJ,大约比电子神经网络高3个数量级,比SpiNNaker高6个数量级以上。通过使用优化的亚波长结构(如光子晶体)和波长多路复用,可以进一步提高神经形态光子平台的计算性能。展望
虽然光计算在不同的AI模型中得到了广泛的应用,但也面临着各种挑战,实际应用中尚未获得明显优于传统电子处理器的性能证明。例如:如何在响应时间短、对探测光功耗要求低、数据并行的情况下获得比较强的光学非线性特性?如何在不同架构中优化非线性表征?如何在低功耗的芯片上实现高速大规模可重构计算?如何将不同的光学器件集成到单个芯片上,特别是与外部器件连接?如何为不同的任务设计具有自动化设计软件的光学神经网络?尽管未来仍有许多问题有待解决,但目前的光学模拟计算技术在速度、数据并行和功耗方面已经表现出了光技术的独特潜力。下一步,作者认为需要进一步努力克服光计算的关键缺陷,并在不同的实际应用中展示光学计算相对于电子学计算的优越性。如上所述,不同的架构可能适合于专门的特定任务。光学计算中对自由空间中部分相干光场的传播和调制模型的建立有助于计算机视觉中对数据的高速处理。由于自动驾驶等自然场景中的大部分光线是非相干的,目前相干的衍射神经网络模型难以发挥作用。由于非线性特性在深度神经网络中起着至关重要的作用,因此,采用低功耗、低延迟的光学方式实现非线性激活函数可以显著提升当前神经网络的精度。存储和访问是扩展神经形态处理器所需的基础技术,构建具有极快读写速度的光学随机存储器一直是一个挑战,这为光计算和存储的特殊材料的发展提供了巨大机遇。尽管使用了庞大的系统,但自由空间的光学计算可能会加速不需要便携式系统的各种数据中心的云计算。我们期待更先进的具有更高的迭代速度(高达MHz和千兆像素数)的空间光调制器出现。高速和低功耗光电转换在目前的过渡阶段变得越来越重要,其在实际应用中需要光子学和电子学的发展。现状表明,在不久的将来,光学计算会有越来越多的突破。此综述回顾了近些年光学计算在用于实现人工智能专用硬件方面的发展。主要介绍了几个在不同架构下具有代表性和独特优势的光学模拟人工智能模型。尽管大多数模型仍处于概念验证的初级阶段,但我们预期这些架构在未来实际应用中将在计算速度或功耗方面取得数量级的改进。我们相信,随着光子学、电子学、材料学、制造学、计算机科学和生物学等不同领域研究者的不断努力,作为通向全光计算机的过渡阶段,使用光电混合计算机来加速人工智能训练和推理将很快成为现实。论文信息:
Please cite this article as: J. Wu, X. Lin, Y. Guo, J. Liu, L. Fang, S. Jiao, Q. Dai, Analog Optical Computing forArtificial Intelligence, Engineering (2021)
https://doi.org/10.1016/j.eng.2021.06.021
