
入门 | 云计算、大数据和人工智能

一个专注于计算机视觉与机器学习知识分享的公众号
转载自 | 数据派THU
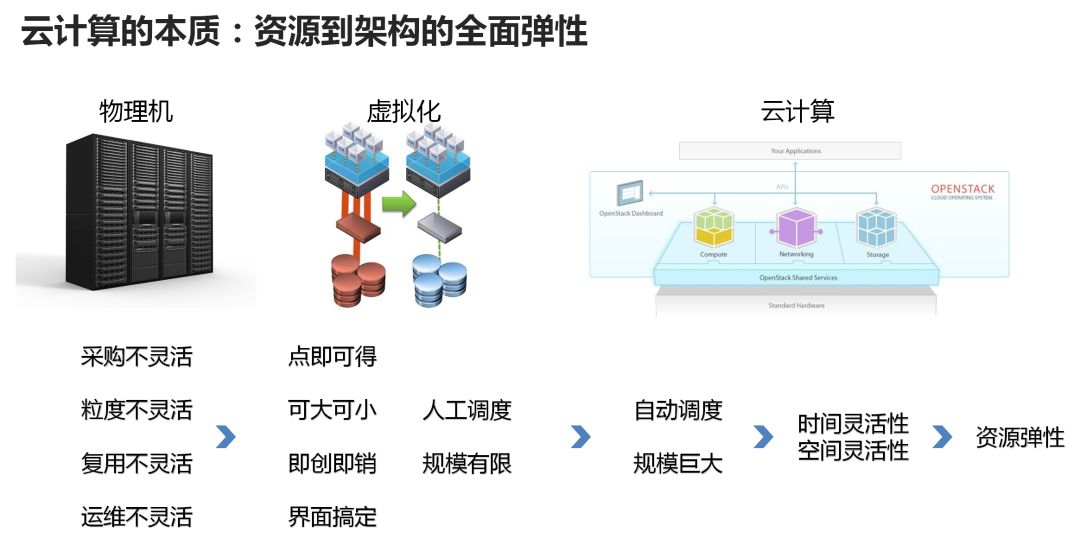
时间灵活性:想什么时候要就什么时候要,需要的时候一点就出来了; 空间灵活性:想要多少就有多少。需要一个很小的电脑,可以满足;需要一个特别大的空间例如云盘,云盘给每个人分配的空间动不动就很大很大,随时上传随时有空间,永远用不完,也是可以满足的。
首先是它缺乏时间灵活性。不能够达到想什么时候要就什么时候要。比如买台服务器、买个电脑,都要有采购的时间。如果突然用户告诉某个云厂商,说想要开台电脑,使用物理服务器,当时去采购就很难。与供应商关系好的可能需要一个星期,与供应商关系一般的就可能需要采购一个月。用户等了很久电脑才到位,这时用户还要登录上去慢慢开始部署自己的应用。时间灵活性非常差。 其次是它的空间灵活性也不行。例如上述的用户需要一个很小很小的电脑,但现在哪还有这么小型号的电脑?不能为了满足用户只要一个G的内存、80G硬盘的需求,就去买一个这么小的机器。但是如果买一个大的,又会因为电脑大,需要向用户多收钱,可用户需要用的只有那么小一点,所以多付钱就很冤。
例如在闭源的世界里有Windows,大家用Windows都得给微软付钱;开源的世界里面就出现了Linux。比尔盖茨靠Windows、Office这些闭源的软件赚了很多钱,称为世界首富,就有大牛开发了另外一种操作系统Linux。很多人可能没有听说过Linux,很多后台的服务器上跑的程序都是Linux上的,比如大家享受双十一,无论是淘宝、京东、考拉……支撑双十一抢购的系统都是跑在Linux上的。
再如有Apple就有安卓。Apple市值很高,但是苹果系统的代码我们是看不到的。于是就有大牛写了安卓手机操作系统。所以大家可以看到几乎所有的其他手机厂商,里面都装安卓系统。原因就是苹果系统不开源,而安卓系统大家都可以用。
私有云:把虚拟化和云化的这套软件部署在别人的数据中心里面。使用私有云的用户往往很有钱,自己买地建机房、自己买服务器,然后让云厂商部署在自己这里。VMware后来除了虚拟化,也推出了云计算的产品,并且在私有云市场赚的盆满钵满。 公有云:把虚拟化和云化软件部署在云厂商自己数据中心里面的,用户不需要很大的投入,只要注册一个账号,就能在一个网页上点一下创建一台虚拟电脑。例如AWS即亚马逊的公有云;例如国内的阿里云、腾讯云、网易云等。
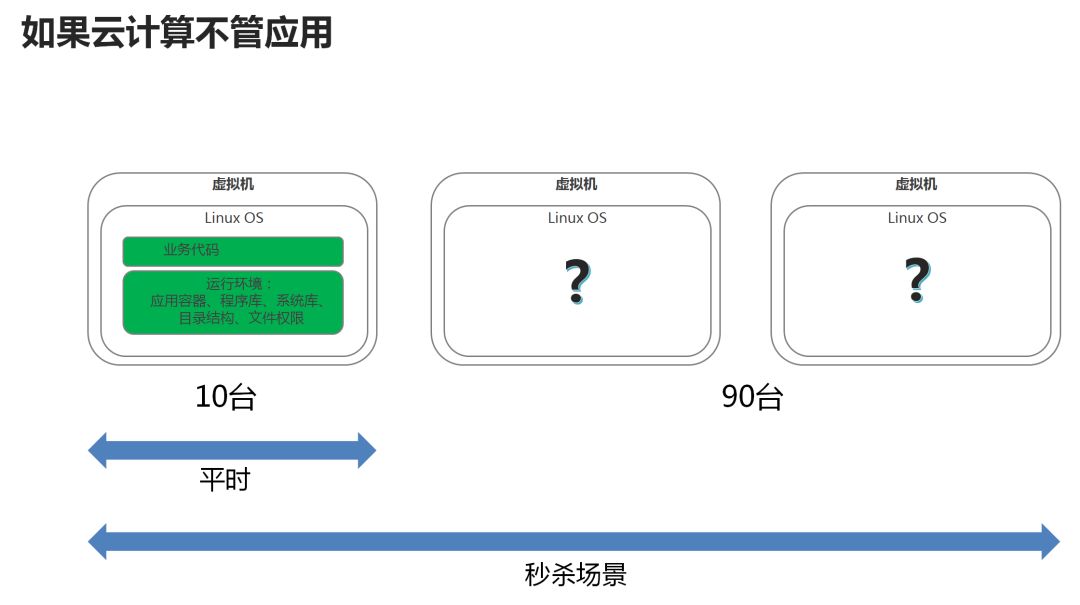
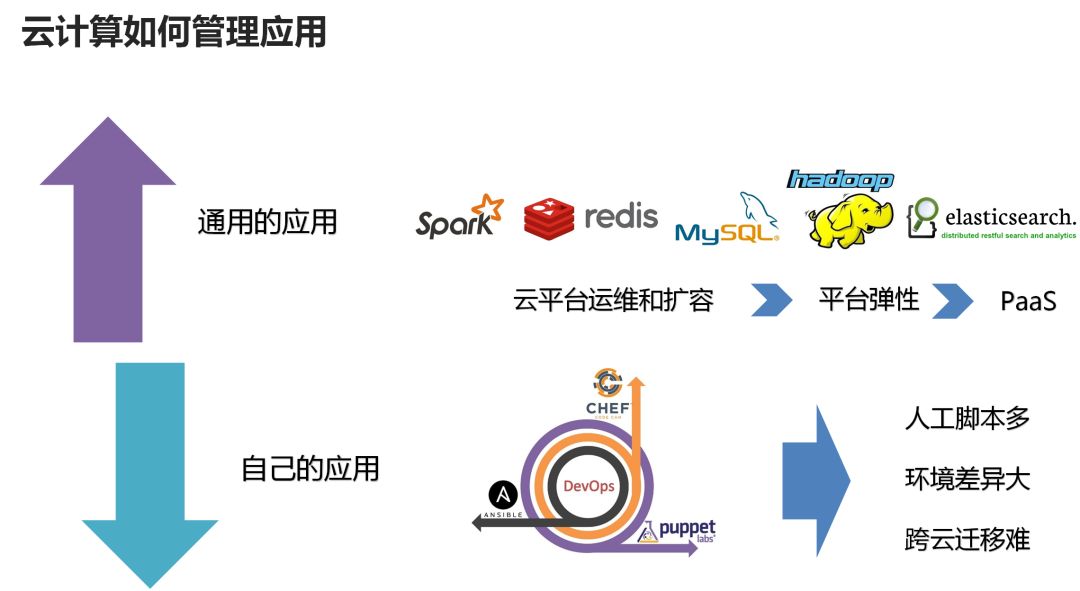
自己的应用自动安装:比如电商应用是你自己开发的,除了你自己,其他人是不知道怎么安装的。像电商应用,安装时需要配置支付宝或者微信的账号,才能使别人在你的电商上买东西时,付的钱是打到你的账户里面的,除了你,谁也不知道。所以安装的过程平台帮不了忙,但能够帮你做得自动化,你需要做一些工作,将自己的配置信息融入到自动化的安装过程中方可。比如上面的例子,双十一新创建出来的90台机器是空的,如果能够提供一个工具,能够自动在这新的90台机器上将电商应用安装好,就能够实现应用层面的真正弹性。例如Puppet、Chef、Ansible、Cloud Foundary都可以干这件事情,最新的容器技术Docker能更好的干这件事情。 通用的应用不用安装:所谓通用的应用,一般指一些复杂性比较高,但大家都在用的,例如数据库。几乎所有的应用都会用数据库,但数据库软件是标准的,虽然安装和维护比较复杂,但无论谁安装都是一样。这样的应用可以变成标准的PaaS层的应用放在云平台的界面上。当用户需要一个数据库时,一点就出来了,用户就可以直接用了。有人问,既然谁安装都一个样,那我自己来好了,不需要花钱在云平台上买。当然不是,数据库是一个非常难的东西,光Oracle这家公司,靠数据库就能赚这么多钱。买Oracle也是要花很多钱的。
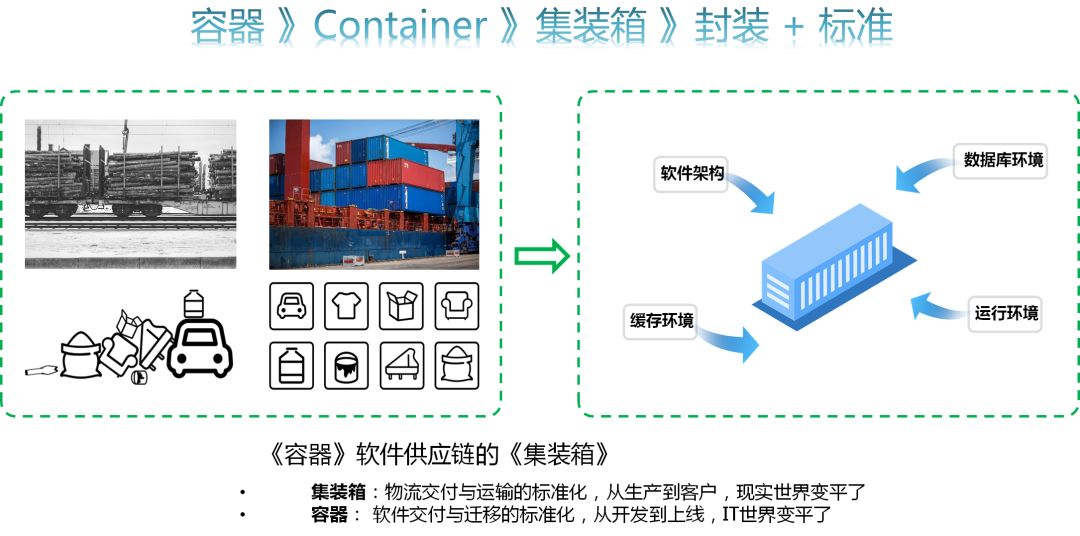


结构化的数据:即有固定格式和有限长度的数据。例如填的表格就是结构化的数据,国籍:中华人民共和国,民族:汉,性别:男,这都叫结构化数据。 非结构化的数据:现在非结构化的数据越来越多,就是不定长、无固定格式的数据,例如网页,有时候非常长,有时候几句话就没了;例如语音,视频都是非结构化的数据。 半结构化数据:是一些XML或者HTML的格式的,不从事技术的可能不了解,但也没有关系。
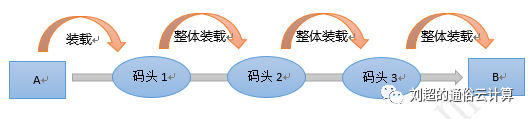
第一个方式是拿,专业点的说法叫抓取或者爬取。例如搜索引擎就是这么做的:它把网上的所有的信息都下载到它的数据中心,然后你一搜才能搜出来。比如你去搜索的时候,结果会是一个列表,这个列表为什么会在搜索引擎的公司里面?就是因为他把数据都拿下来了,但是你一点链接,点出来这个网站就不在搜索引擎它们公司了。比如说新浪有个新闻,你拿百度搜出来,你不点的时候,那一页在百度数据中心,一点出来的网页就是在新浪的数据中心了。 第二个方式是推送,有很多终端可以帮我收集数据。比如说小米手环,可以将你每天跑步的数据,心跳的数据,睡眠的数据都上传到数据中心里面。
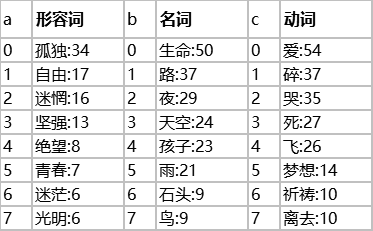
有一位网友统计了知名歌手在大陆发行的 9 张专辑中 117 首歌曲的歌词,同一词语在一首歌出现只算一次,形容词、名词和动词的前十名如下表所示(词语后面的数字是出现的次数):
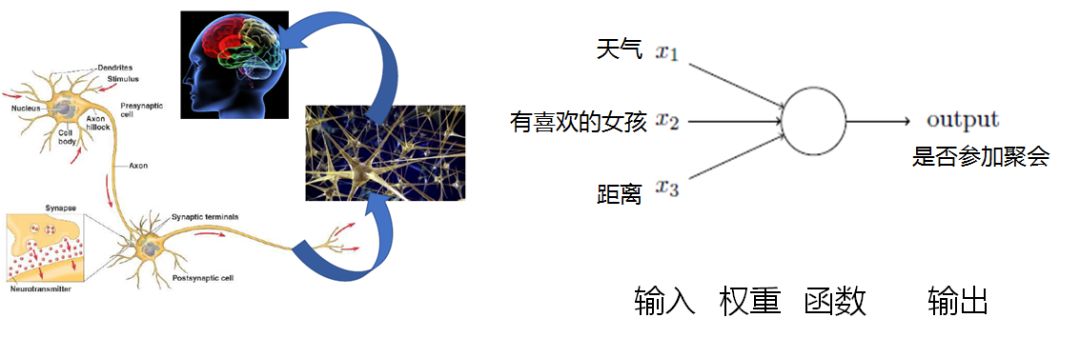

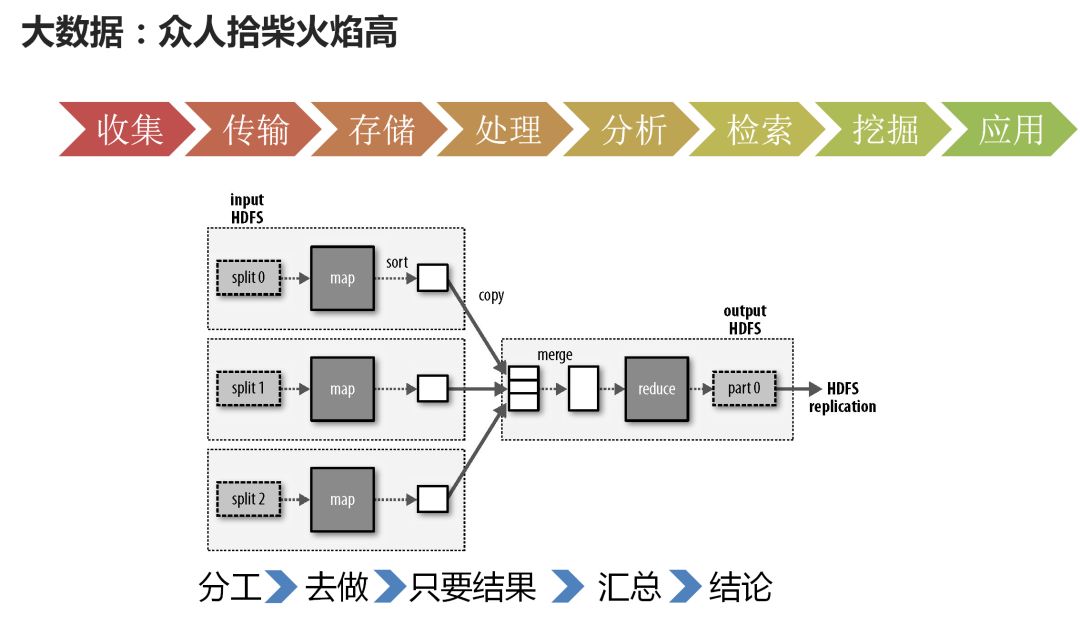
第一个阶段依赖于关键词黑白名单和过滤技术,包含哪些词就是黄色或者暴力的文字。随着这个网络语言越来越多,词也不断地变化,不断地更新这个词库就有点顾不过来。 第二个阶段时,基于一些新的算法,比如说贝叶斯过滤等,你不用管贝叶斯算法是什么,但是这个名字你应该听过,这个一个基于概率的算法。 第三个阶段就是基于大数据和人工智能,进行更加精准的用户画像和文本理解和图像理解。
END
评论