
一个小问题:深度学习模型如何处理大小可变的输入

极市导读
本文对问题:“对于大小可变的输入,深度学习模型如何处理?”进行了一些总结,帮助大家深刻地理解各种模型结构的设计和背后的原理。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
对于大小可变的输入,深度学习模型如何处理?
前几天在学习花书的时候,和小伙伴们讨论了“CNN如何处理可变大小的输入”这个问题。进一步引申到“对于大小可变的输入,深度学习模型如何处理?”这个更大的问题。因为这里面涉及到一些概念,我们经常搞混淆,比如RNN单元明明可以接受不同长度的输入,但我们却在实际训练时习惯于使用padding来补齐;再比如CNN无法直接处理大小不同的输入,但是去掉全连接层之后又可以。因此,这里我想总结一下这个问题:
究竟什么样的模型结构可以处理可变大小的输入? 若模型可处理,那该如何训练/预测? 若模型不可处理,那该如何训练/预测?
一、什么样的网络结构可以处理可变大小的输入?
直接上结论(我个人总结的,不一定对/全面,欢迎指正):
当某个网络(层或者单元)是以下三种情况之一时:
①只处理局部的信息;
②网络是无参数化的;
③参数矩阵跟输入大小无关,
这个网络就可以处理大小可变的输入。
下面我分别从几个经典的网络结构来回应上面的结论:
CNN
首先讲讲CNN。CNN中的卷积层通过若干个kernel来获取输入的特征,每个kernel只通过一个小窗口在整体的输入上滑动,所以不管输入大小怎么变化,对于卷积层来说都是一样的。那为什么CNN不能直接处理大小不同的图片呢?是因为一般的CNN里都会有Dense层,Dense层连接的是全部的输入,一张图片,经过卷积层、池化层的处理后,要把全部的单元都“压扁(flatten)”然后输入给Dense层,所以图片的大小,是影响到输入给Dense层的维数的,因此CNN不能直接处理。但是,有一种网络叫FCNN,即Fully Convolutional Neural Network,是一种没有Dense层的卷积网络,那么它就可以处理大小变化的输入了。
CNN处理大小可变的输入的另一种方案是使用特殊的池化层——SSP(Spatial Pyramid Pooling),即“空间金字塔池化”,最初由何恺明团队提出。这种池化层,不使用固定大小的窗口,而是有固定大小的输出。比方不管你输入的网格是多大,一个固定输出2×2的SSP池化,都将这个输入网络分成2×2的区域,然后执行average或者max的操作,得到2×2的输出。
SSP和FCNN在《花书》中都有展示:
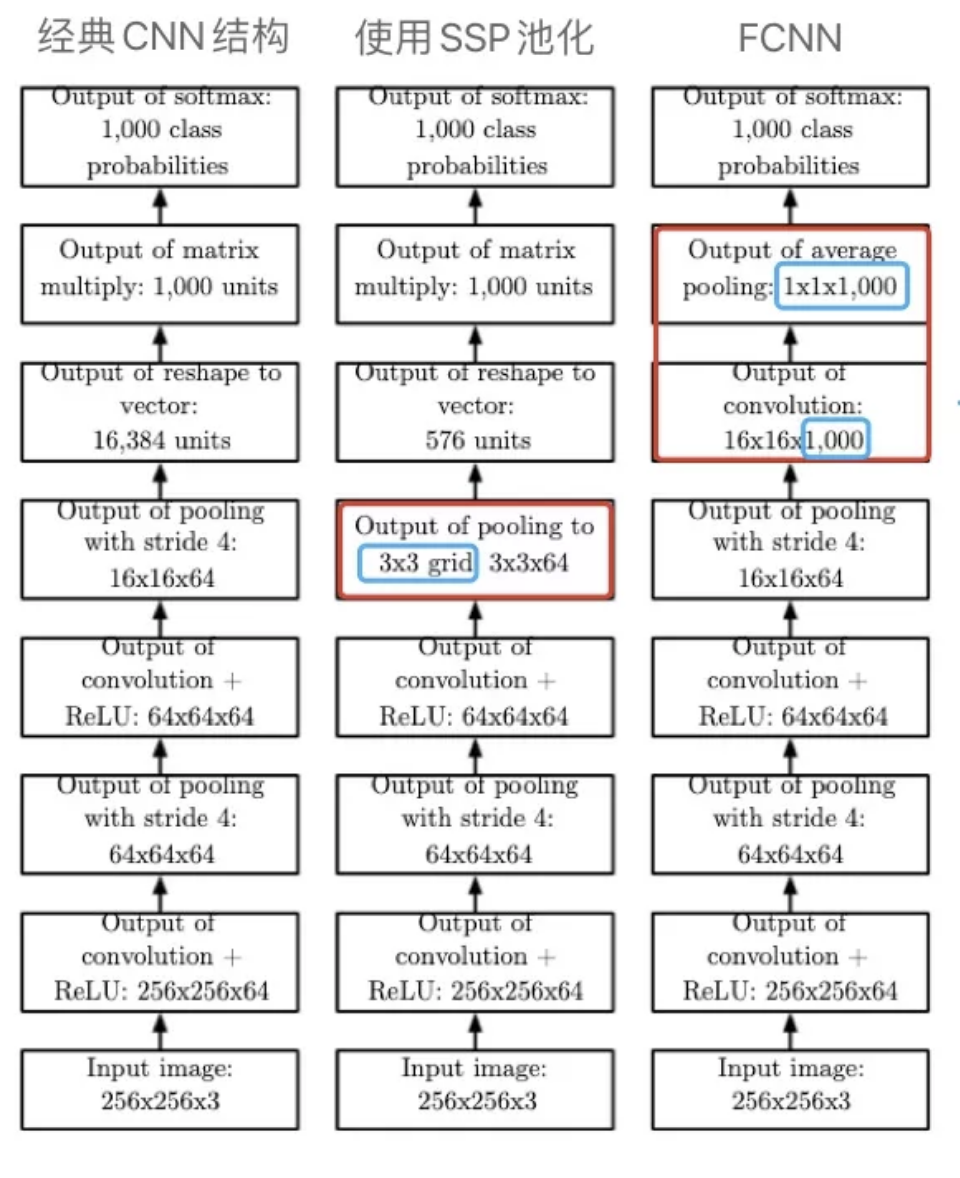
图中,SSP通过一个固定输出大小的pooling,拥有了处理可变大小输入的能力。而FCNN,则是去掉了Dense层,使用kernel的数量来对应类别的数量(如图中例子使用了1000个kernel来对应1000个类),最后使用一个全局池化——GAP(Global Average Pooling),将每个kernel对应的feature map都转化成一个值,就形成了一个1000维的向量,就可以直接使用softmax来分类了,不必使用Dense层了。通过这连个特殊的卷积层和池化层,FCNN也拥有了处理可变大小输入的能力。
RNN
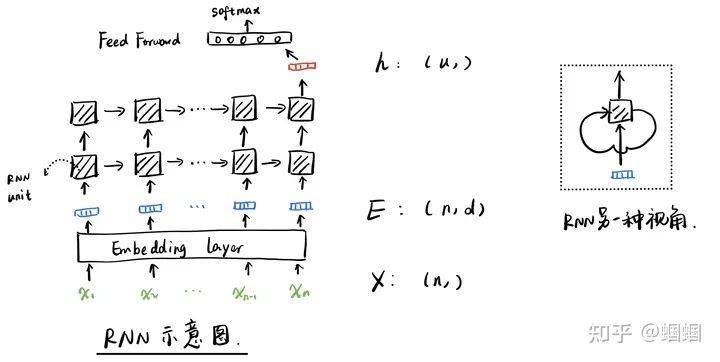
再来讲讲RNN。RNN,是由一个个共享参数的RNN单元组成的,本质上可以看成一层RNN只有一个RNN单元,只不过在不断地循环处理罢了。所以,一个RNN单元,也是处理局部的信息——当前time step的信息。无论输入的长度怎么变,RNN层都是使用同一个RNN单元。往往我们也会在RNN后面接上Dense层,然后再通过softmax输出,这里的Dense会有影响吗?答案是不影响,因为我们使用RNN,往往是只需要用最后一个time step的hidden state,这个hidden state的维度是RNN单元中设置的维度,跟输入的长度无关,因此这个hidden state跟Dense的交互也跟输入的维度无关。比如我们输入的长度是l,RNN单元的输出维度为u,Dense层的单元数为n,那么Dense层中的权重矩阵大小为u×n,跟l是无关的。RNN单元中的权重也跟l无关,只跟每个time step的输入的维度有关,比如词向量的维度d,RNN单元中的权重矩阵大小是d×u。上面过程可以参考下面的示意图:
Transformer
Transformer也可以处理长度可变的输入,这个问题在知乎上有讨论,可惜我都没太看明白。比如邱锡鹏老师讲的,是因为“self-attention的权重是是动态生成的”,我不懂权重怎么个动态法?再例如许同学讲“Transformer是通过计算长度相关的self-attention得分矩阵来处理可变长数据”,这个直接从字面上也不太好理解。
在我看来,这跟self-attention压根没关系。Transformer中的self-attention是无参数化的,从attention层输入,到输出加权后的向量表示,不需要任何的参数/权重,因此self-attention自然可以处理长度变化的输入。Transformer中的参数都来源于Dense层,包括一些纯线性映射层(projection layer)和position-wise FFN(feed-forward layer)。搞清楚这些Dense层的操作,才能理解为何Transformer可以处理变长输入。
我们先看看Transformer的结构:
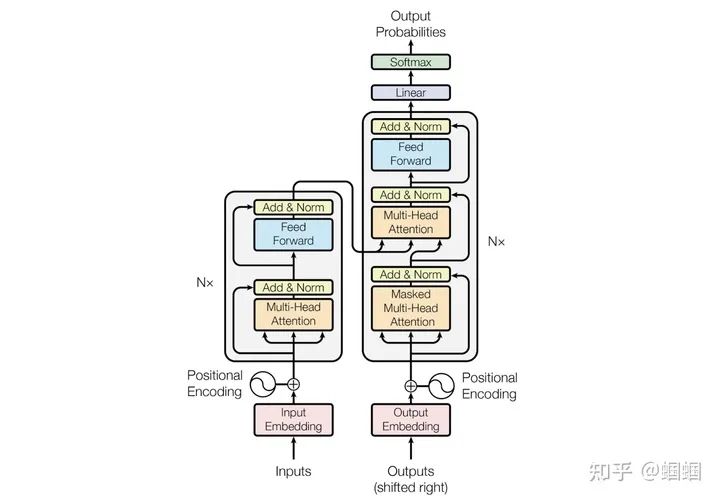
这里我们重点关注encoder部分,即左半部分。但是看这个图,并不能很好的理解为什么可以处理长度变化的输入。为此,我花了一个简陋的草图(省略了多头,省略了Add&Norm,简化了论文中的FFN),来更细致地查看encoder部分:
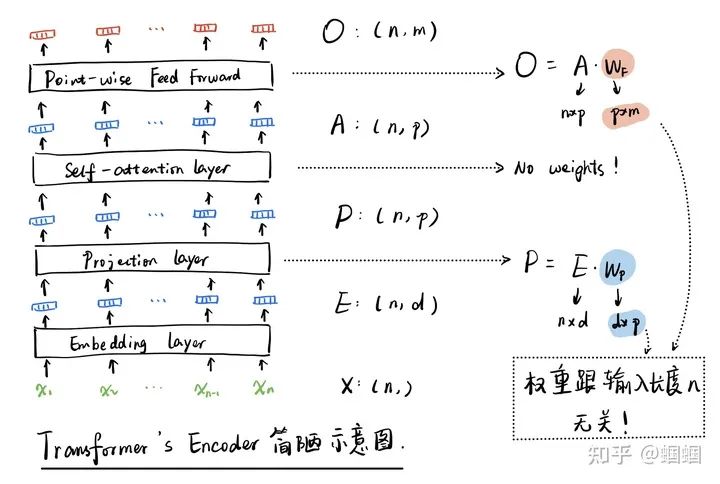
我们不必展开看self-attention的部分,因为它就是让所有的向量,两两之间都计算attention权重然后再分别加权求和得到新的一组向量,中间没有任何的参数,向量的维度、数量都没有任何的变化。
整个encoder,涉及到可学习参数的只有projection layer和point-wise feed-forward layer,其中前者只是为了把每个输入token的向量的维度改变一下(图中,从d变为p),后者则是对每一个token,都使用同一个Dense层进行处理,把每个向量的p维转化为m维。所以,所有的参数,都跟序列的长度n没有任何关系,只要模型参数学好了,我们改变序列长度n也照样可以跑通。
这里唯一值得展开看看的,就是这里的point-wise feed-forward layer,这其实就是普普通通的Dense层,但是处理输入的方式是point-wise的,即对于序列的每个step,都执行相同的操作:
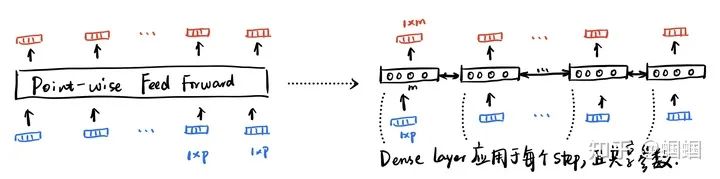
一开始我不理解,为什么明明有一个Dense层接在attention层后面还能处理可变长的输入。后来发现这不是普通的Dense,而是point-wise的,相当于一个recurrent的Dense层,所以自然可以处理变化的长度。
二、若模型可处理大小变化的输入,那如何训练和预测?
通过了第一部分的讨论,我们知道了,什么网络结构可以处理大小变化的输入。
以RNN为例,虽然它可以处理各种长度的序列,但是我们在训练时,为了加速训练,往往会将一批数据同时输入到模型中进行计算、求导。那同一批数据,要喂给网络,我们必须把它组织成矩阵的形式,那矩阵的每一行/列自然维度需要相同。所以我们必须让同一个batch中的各个样本长度/大小一致。
最常用的方法,就是padding,我们通过padding补零,把同一个batch中的所有样本都变成同一个长度,这样就可以方便我们进行批量计算了。对于那些padded values,也就是补的零,我们可以使用masking机制来避免模型对这些值进行训练。
实际上,有研究指出,我们可以对一批样本(以NLP为例),做一个长度的排序,然后分组,每一组使用不同的max length超参数,这样可以节省padding的使用次数,从而提高训练效率(论文我不知道是哪个,听别人说的,知道的同学可以告诉我),文后的连接里,我找到了一个keras的示例代码,可供参考。
当然,如果我们设置batch size=1,那就不需要padding了,就可以开心的把各种不同长度的数据都丢进去训练了。
在预测时,如果我们想进行批量预测,那也是必须通过padding来补齐,而如果是单条的预测,我们则可以使用各种长度。
三、若模型不可处理大小变化的输入,那如何训练与预测?
不可接受,那我们就只能老老实实地把所有输入都规范成同一大小,比如经典的CNN网络,我们会吧所有的图片都进行resize,或者padding。
这里需要提一下transfer learning的场景,我们经常需要直接拿来别人在ImageNet上训练好的牛逼网络来进行finetune,那问题来了,比人训练CNN的时候,肯定有自己固定好的输入大小,跟我们要用的场景往往不一致,那怎么办?只要做过CNN的transfer learning的同学应该都有经验:我们需要把别人的网络的最后面的Dense层都去掉!因为前面分析过了,Dense层才是让CNN无法处理可变大小输入的罪魁祸首,Dense一拿掉,剩下的卷积层啊池化层啊都可以快乐地迁移到各种不同大小的输入上了。
其他的办法,就是改造模型结构了,例如SSP,FCNN都是对经典CNN的改造。
预测时,在这种情况下,我们也只能使用统一的输入大小,不管是单条还是批量预测。
以上总结了这个深度学习中的“小问题”——“对于大小可变的输入,深度学习模型如何处理?” 虽然是个小问题,但仔细探究一下,发现还是挺有意思的,有助于我们更加深刻地理解各种模型结构的设计和背后的原理。
参考链接:
知乎上关于Transformer为何可以处理不同长度数据的讨论:https://www.zhihu.com/question/445895638 keras中如何实现point-wise FFN的一些讨论:
https://ai.stackexchange.com/questions/15524/why-would-you-implement-the-position-wise-feed-forward-network-of-the-transforme https://stackoverflow.com/questions/44611006/timedistributeddense-vs-dense-in-keras-same-number-of-parameters/44616780#44616780
keras中如何使用masking来处理padding后的数据:https://www.tensorflow.org/guide/keras/masking_and_padding 在训练中,给不同的batch设置不同的sequence_length: https://datascience.stackexchange.com/questions/26366/training-an-rnn-with-examples-of-different-lengths-in-keras
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“目标检测竞赛”获取目标检测竞赛经验资源~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
