利用 SQL 实现 KNN 算法
作为一名数据从业者,大家应该对SQL都不太陌生,对KNN算法也不是很陌生,但是把这两个放在一起很多人估计就没见过了。今天给大家分享如何利用SQL实现KNN算法。
在 2008 年尾的时候,读到一本非常有趣的书,叫做《Data Mining With SQL Server 2008》. 在遇到《Inside Sql Server》系列前夕,此时正值读书的空档期。
为什么会对这本书感兴趣呢,毕竟是作为农学毕业的我,八竿子也打不到 Data Mining 的领域去,主要还是对于前途的担忧。这话题说来,估计长的可以写篇小说了。
咱们不卖焦虑,所以简而言之:做了两年 C/S 的开发之后,深深感到数据才是灵魂,而这灵魂的操盘手,普天之下,Data Mining 稳稳得排在江湖兵器谱第一位!
在坚持了两个月的研究之后,(为什么这么久,只有英语六级水平的人,看纯英文版还是很吃力,当时这本书还没中文本),捣鼓了一点彩票数据进 SQL Server Cube ,以为靠着深奥万能的模型,从此可以财富自由,一时间豪气四射,信心倍增,连蛋饼都加 2 个蛋的,后来才知其实那只是黄粱一梦。
在万恶的资本思想驱使下,一遍遍修炼决策树,聚类,神经网络,贝叶斯模型, 每一遍都用真金白银去豪赌(2 块钱一注,当时月薪 1200 吧,所以真是豪赌),收获的却是一遍遍的失望,那时的心,就像 911 下的五角大楼一样,崩塌在即。直到把聚类的模型统统走完,一次都没中!从此,Data Mining 与我是路人。
十年过来了,如今大火的数据挖掘,又加上了新玩法,美其名曰机器学习,人工智能,深度学习等。再和朋友们谈论的时候,闭口不谈大数据,AI, ML, 大家都会带着异样的眼光看着你,“你丫也是在 IT 圈混的?”... 所以重新拾起来看看,与时俱进。其实内心的回答是,“08 年小哥我开始玩 Weka 的时候,你们连 Oracle 都不会玩吧,还谈大数据,AI”
言归正传,今天的主题是 kNN ( top k nearest ) 最近邻算法。参考的书目是两本《机器学习实战》(Peter 著)与《机器学习》(周志华著).
这两本书各有其优点,《实战》这本书对于 Python 代码实现算法讲的比较多,让你很容易就写出一个模型来完成一次实战,跟玩王者一样的,反馈很及时,而周志华教授的这本《机器学习》则是讲的比较细致了,用的是挑西瓜的例子,很有趣味。
当然 Peter 这本书用的还是 Python 2.0 , 我费了很大的劲儿,才转成 Python 3.0 的语法,以下的例子会有注解, 而周教授的这本书,则是没有数学底子根本看不懂在讲啥,碰到 kNN , 会跟你详细解释权重,概率,线性矩阵,有多少种求解最短距离的算法等,很开眼界,让我瞬间觉得我活着都是在浪费社会资源。
用一幅图来讲解 kNN, 可以让你瞬间秒懂:
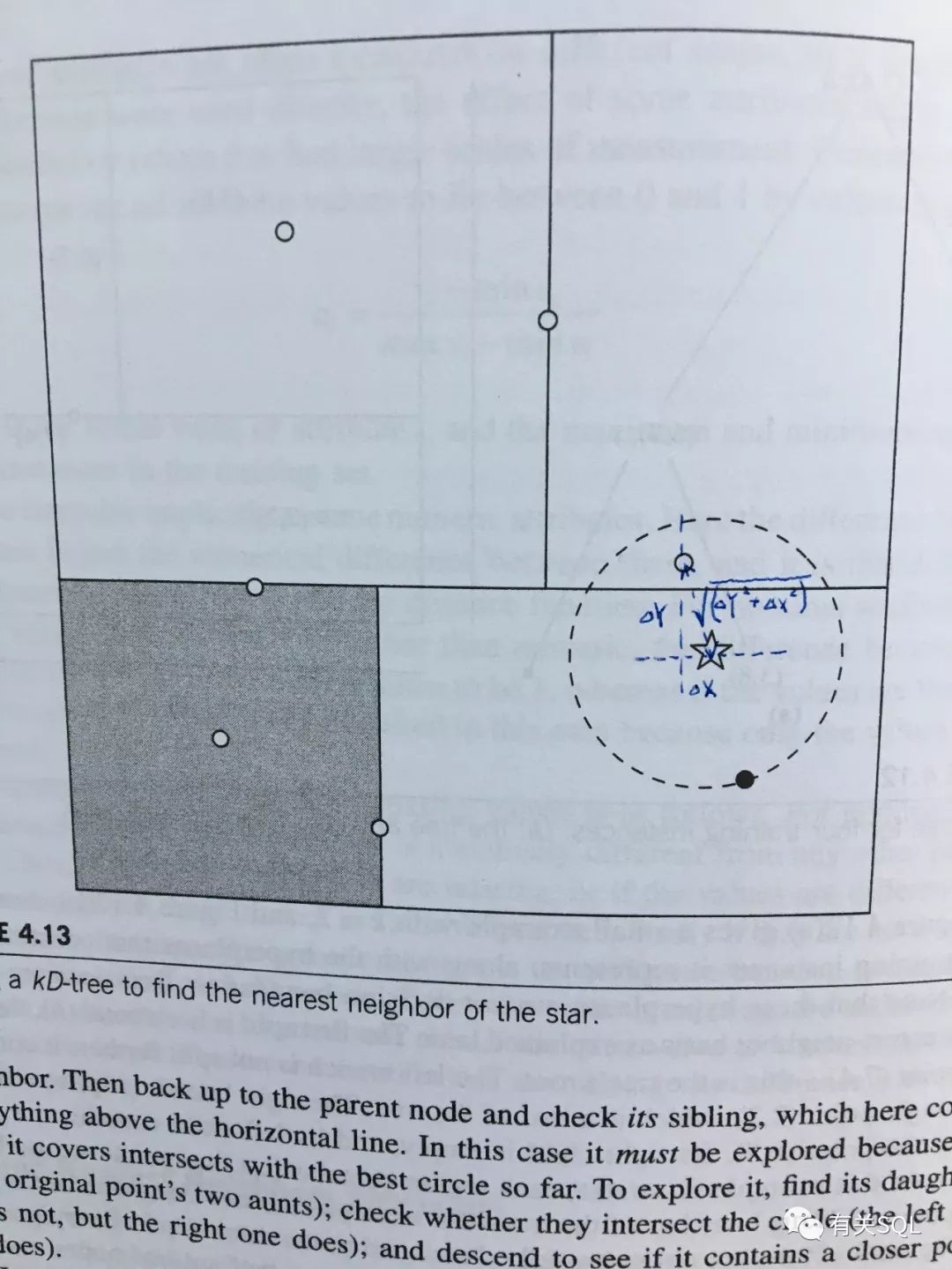
图中的五角星,就是我们待分类的数据。与他最近的 k 个圆点所代表的类别,比重最大的就是预测数据的类别。求解方式很简单,在 2 个属性下,就是求解直三角形斜边的长度,勾股定理一算就出来了。如果在多个属性下,也就是将各自之差的平方相加,再求根,就得到最短距离
Peter 书中采用了婚恋网的匹配推荐项目来演示 kNN。采用的特征分别是:
1 每年的飞行里程
2 每天玩视频游戏所占的时间份额
3 每周吃掉的冰激凌分量
根据这三个特征,收集了近1000个打分结果,来判断约会双方对彼此的影响,是不喜欢,喜欢还是极度渴望约会。
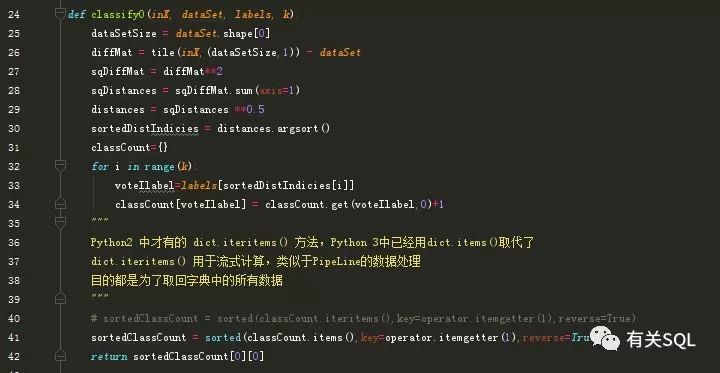
求解 kNN 的核心代码的代码,经过 Python 3.0 修改 之后,如下:
模型做出来了,我们就用划分为测试用例的数据做预测,观察其正确率:
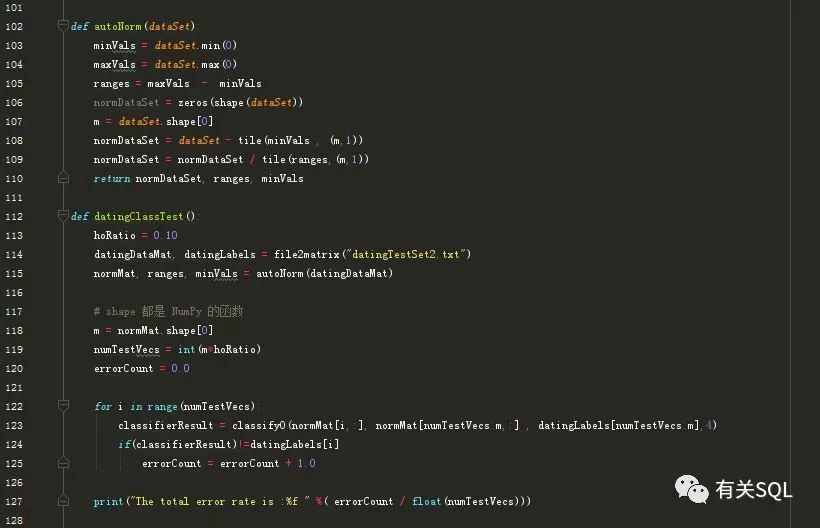
最后得到的误差是4%,模型可以用来预测分类。只要拿到一个对象的这三个特征,就能得到他/她是否能得到大家的喜欢,而这个结果有 96% 的准确性。
为了更好的了解这个功能,用 MatPlotLib 做了一个图,图中面积最大的那些点,就是最受喜欢的那群人,他们的特征在某些方面具有奇高的重叠
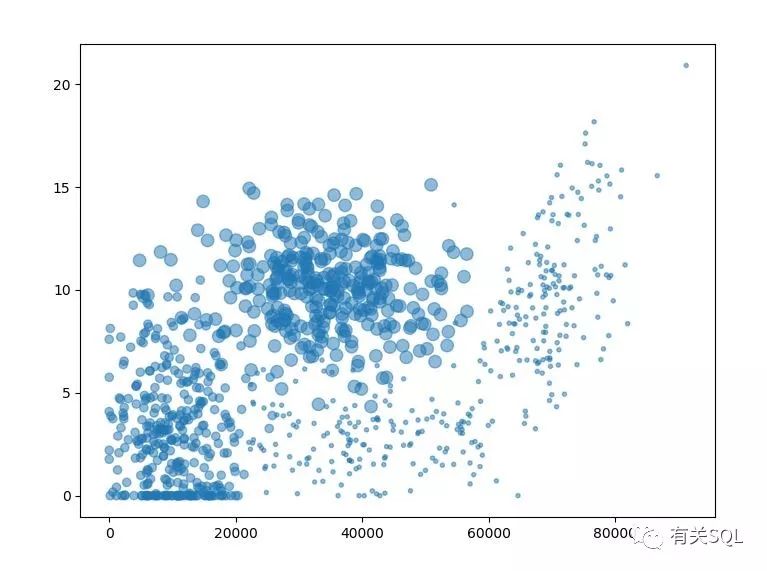
气泡图在 Python 的 MatPlotLib 下实现也非常容易:

那么如何用 SQL 实现呢,kNN 的算法是所有算法中最简单的一个,只要对原理掌握了,不过是把 Python 换成了 SQL。当然这两者在如今的数据量环境下,都不是好的实现语言,必须与 Spark , Hadoop 等分布式存储于计算环境结合起来,方能全量无死角的洞悉信息。
以下是两张数据表,第一张 datingSampleDataSet 就是收集好的数据其中的900条,第二张 datingTestingDataSet 是从收集好的数据中取出来的 100 条,因这份数据已经有喜好的分类了,因此可以作为误差的计算.
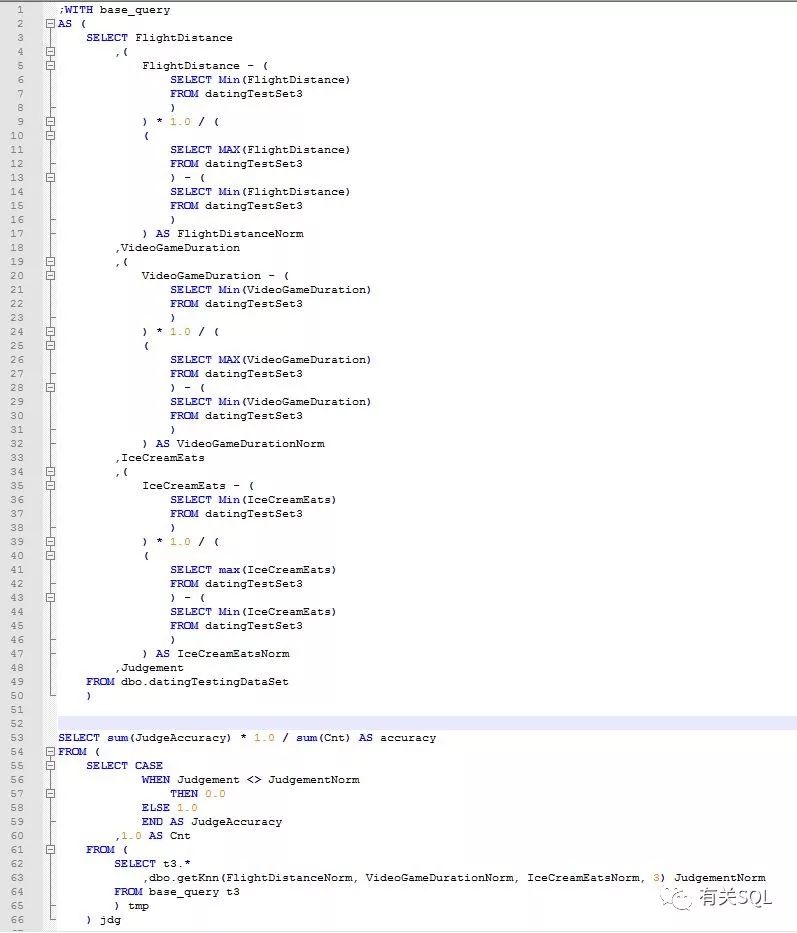
select *
from dbo.datingSampleDataSet
select *
from dbo.datingTestingDataSet
在 SQL 的实现过程中,我们用一个函数来求解预测值的分类,再来判断函数的误差。最后得到的误差和 Python 实现的一样,都是 4%。