如何优雅地实现KNN搜索
我们知道K近邻法(K-Nearest Neighbor, KNN)是一种基本的机器学习算法,早在1968年就被提出。KNN算法简单、直观,是最著名的“惰性学习”算法,不具有显示的学习过程。
正因为其算法的思想简单,我们更加关注KNN算法实现的优化。最简单粗暴的就是线性扫描,但随着样本量的放大,其计算量也会成倍放大,因此本文介绍并实现一种优雅的优化搜索方法——KD树。
K近邻推导与KD树过程
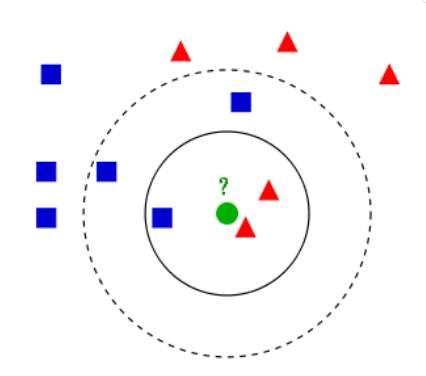
我们可以用文字简单描述下KNN算法:给定一个训练数据集T,对于新的目标实例x,我们在训练集T中找到与实例x最邻近的k个实例,这k个实例大多属于哪一类,目标实例x就被分为这个类。
用数学公式我们表达如下:
给定训练数据集T:
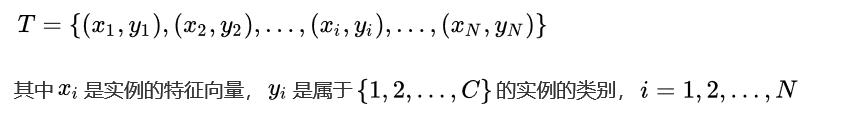
根据给定的新的目标实例Xtarget,和距离度量方法,我们可以在T中找到k个与Xtarget最邻近的实例点,我们将这k个近邻点的集合记作Nk:
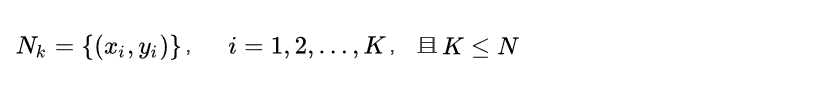
那目标实例的类别Ytarget为:
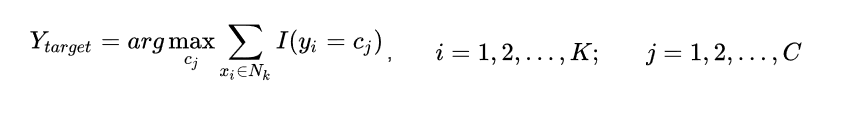
此处的I为指数函数,当yi=cj时为1,否则为0。
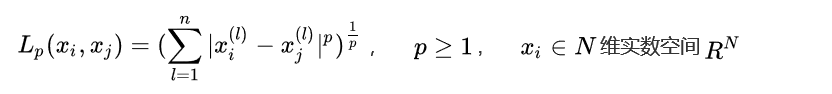

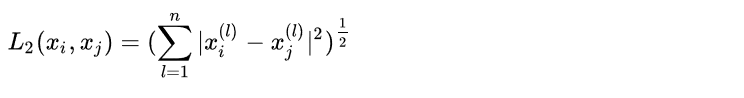
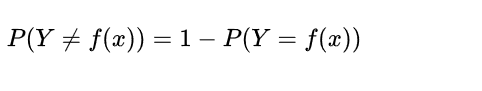
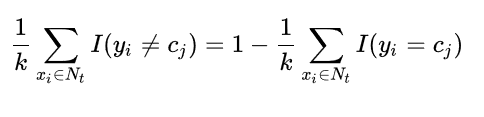
KD树的实现
构造KD树
通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数(median)为切分点,这样得到的KD树是平衡的,但是平衡的KD树搜索时的效率未必是最优的。
切分超平面左侧区域对应的是小于选定坐标轴的实例点,右侧区域对应的是大于选定坐标轴的实例点,将落在切分超平面上的实例点保存在根结点。
当左右两个子区域没有实例存在时停止划分,从而形成KD树的区域划分。
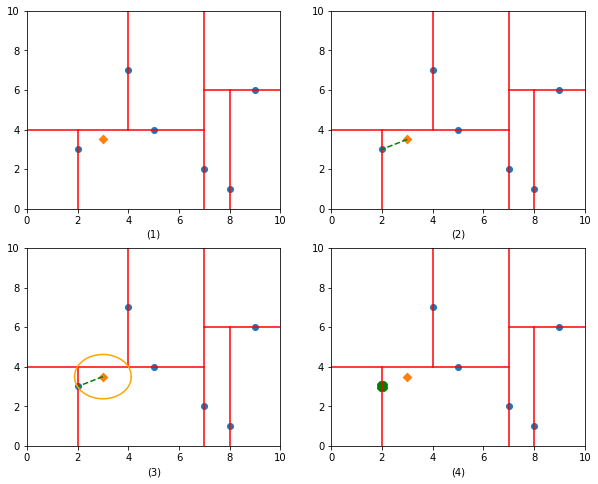
举个例子:给定二维数据集T={(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)},进行区域划分。

搜索KD树
利用KD树可以省去对大部分数据点的搜索,从而减少搜索的计算量,以最近邻为例:给定一个目标点,搜索其最近邻,首先找到包含目标点的叶结点;然后从该叶结点出发,依次回退到父结点;不断查找与目标点最邻近的节点,当确定不可能存在更近的结点时终止。
以目标点(3, 3.5)为例,在上面构造树的基础上进行搜索。
首先,将目标点划分到(2, 3)所在的结点,初步认定(2, 3)就是目标点的最近邻;
其次,计算(2, 3)与(3, 3.5)之间的距离d;
然后,往父结点回溯,以(3, 3.5)为中心,距离d为半径画圆,发现圆圈与其父结点相交;
最后,计算目标点与父结点上的(5, 4)以及另一侧上的(4, 7)距离,发现其最近邻的点还是(2, 3);
再往上一层父结点递归,发现切分超平面并不与圆圈相交,故结束搜索。
以上是K近邻与KD树的推导部分。
Python实现K近邻与KD树
提前说明下,这里写的KD树实现K近邻算法,其最终结果并不是输出Y值,而是输出与目标样例近邻的前K个训练数据中的样例,这样可以清楚地看到KD树的运行轨迹。得到了K近邻,要输出最终的结果也是易如反掌,自己加一段投票策略即可。
首先,先建立了树的类,用来存储一些重要信息。
# KdTree
Python
import numpy as np
import matplotlib.pyplot as plt
#树结构类
class Tree(object):
def __init__(self, cutColumn=None, cutValue=None):
Parameters
----------
cutColumn : Int, optional
切分超平面的特征列. The default is None.
cutValue : float, optional
切分超平面的特征值. The default is None.
self.cutColumn = cutColumn
self.cutValue = cutValue
self.nums = 0 #个数
self.rootNums = 0 #在切分超平面上面的实例个数
self.leftNums = 0 #在切分超平面左侧的实例个数
self.rightNums = 0 #在切分超平面右侧的实例个数
self._tree_left = None #左侧树结构
self._tree_right = None #右侧树结构
self.depth = 0 #树的深度
其次,正式构造一个KNN类,初始化一些属性。
#KD树实现KNN算法
class KNN(object):
def __init__(self, K=1):
self.K_neighbor = K
self.tree_depth = 0
self.n_samples = 0
self.n_features = 0
self.trainSet = 0
self.label = 0
self._tree = 0
然后,写一些用得到的方法。有计算切分的特征列、计算切分的特征值、计算欧式距离、计算数据集中距离目标样本点的前K个近邻。
def cal_cutColumn(self, n_iter):
return np.mod(n_iter, self.n_features)
def cal_cutValue(self, Xarray):
if Xarray.__len__() % 2 == 1:
#单数序列
cutValue = np.median(Xarray)
else:
#双数序列
cutValue = Xarray[np.argsort(Xarray)[int(Xarray.__len__()/2)]]
return cutValue
#计算欧氏距离
def caldist(self, X, xi):
return np.linalg.norm((X-xi), axis=1)
#计算一堆数据集距离目标点的距离,并返回K个最近值
def calKneighbor(self, XIndex, xi):
trainSet = self.trainSet[XIndex,:]
knnDict = {}
distArr = self.caldist(trainSet, xi)
neighborIndex = XIndex[np.argsort(distArr)[:self.K_neighbor]]
neighborDist = distArr[np.argsort(distArr)[:self.K_neighbor]]
for i, j in zip(neighborIndex, neighborDist):
knnDict[i] = j
return knnDict
<<<< 滑动查看完整代码 >>>>接着,是构造KD树的代码部分。主体部分是fit_tree(),其中的build_tree()部分递归生成树的结构。
#造树
def build_tree(self, X, n_iter=0):
nums = X.shape[0]
#不达切分条件,则不生成树,直接返回None
if nums < 2*self.K_neighbor:
return None
#计算切分的列
cutColumn = self.cal_cutColumn(n_iter)
Xarray = X[:,cutColumn]
#计算切分的值
cutValue = self.cal_cutValue(Xarray)
#生成当前的树结构
tree = Tree(cutColumn, cutValue)
rootIndex = np.nonzero(Xarray==cutValue)[0]
leftIndex = np.nonzero(Xarray<cutValue)[0]
rightIndex = np.nonzero(Xarray>cutValue)[0]
#保存树的结点数量
tree.nums = nums
tree.rootNums = len(rootIndex)
tree.leftNums = len(leftIndex)
tree.rightNums = len(rightIndex)
#保存树深,并加1
tree.depth = n_iter
n_iter += 1
#递归添加左侧树枝结构
X_left = X[leftIndex,:]
tree._tree_left = self.build_tree(X_left, n_iter)
#递归添加右侧树枝结构
X_right = X[rightIndex,:]
tree._tree_right = self.build_tree(X_right, n_iter)
return tree
#训练构造KD树
def fit_tree(self, X, y):
self.n_samples, self.n_features = X.shape
self.trainSet = X
self.label = y
self._tree = self.build_tree(X)
return<<<< 滑动查看完整代码 >>>>
最后,是搜索KD树的代码部分。transform_tree()是主体部分,search_tree()对树进行递归搜索以及结点的回退搜索。
#递归搜索树
def search_tree(self, trainSetIndex, tree, xi):
trainSet = self.trainSet[trainSetIndex,:]
#搜索树找到子结点的过程
if not (tree._tree_left or tree._tree_right):
self.neighbor = self.calKneighbor(trainSetIndex, xi)
print("树深度为{},切分平面为第{}列特征,初始化搜索树结束!找到{}个近邻点".format(tree.depth, tree.cutColumn, self.K_neighbor))
return
else:
cutColumn = tree.cutColumn
cutValue = tree.cutValue
#切分平面左边的实例
chidlLeftIndex = trainSetIndex[np.nonzero(trainSet[:,cutColumn]<cutValue)[0]]
#切分平面上的实例
rootIndex = trainSetIndex[np.nonzero(trainSet[:,cutColumn]==cutValue)[0]]
#切分平面右边的实例
chidlRightIndex = trainSetIndex[np.nonzero(trainSet[:,cutColumn]>cutValue)[0]]
if xi[cutColumn] <= cutValue:
self.search_tree(chidlLeftIndex, tree._tree_left, xi)
#回退父结点的过程
#判断目标点到该切分平面的的距离,计算是否相交
length = abs(tree.cutValue - xi[cutColumn])
#不相交的话,则继续回退
if length >= max(self.neighbor.values()):
print("树深度为%d,切分平面为第%d列特征,和父结点的切分平面不相交!"%(tree.depth, tree.cutColumn))
return
#相交的话,先是计算分类平面上实例点的距离,再计算另外半边的实例点的距离
else:
targetIndex = list(rootIndex) + list(chidlRightIndex) + list(self.neighbor.keys())
self.neighbor = self.calKneighbor(np.array(targetIndex), xi)
print("树深度为%d,切分平面为第%d列特征,检测父结点切分平面和另一侧的样本点是否有更小的!"%(tree.depth, tree.cutColumn))
return
else:
self.search_tree(chidlRightIndex, tree._tree_right, xi)
#回退父结点进行判断
length = abs(tree.cutValue - xi[cutColumn])
if length >= max(self.neighbor.values()):
print("树深度为%d,切分平面为第%d列特征,和父结点的切分平面不相交!"%(tree.depth, tree.cutColumn))
return
else:
targetIndex = list(rootIndex) + list(chidlLeftIndex) + list(self.neighbor.keys())
self.neighbor = self.calKneighbor(np.array(targetIndex), xi)
print("树深度为%d,切分平面为第%d列特征,检测父结点切分平面和另一侧的样本点是否有更小的!"%(tree.depth, tree.cutColumn))
return
#搜索KD树
def transform_tree(self, Xi):
self.neighbor = dict()
self.search_tree(np.arange(self.n_samples), self._tree, Xi)
return self.neighbor
<<<< 滑动查看完整代码 >>>>
代码写完,我们用鸢尾花数据集来测试下,KD树找到的k个最近邻的样本是否准确。
首先,我们先导入鸢尾花数据集,随意写一个目标样本点,并线性地算出从小到大距离这个目标样本点的所有样本的顺序。我们print出来可以看到下标为35的鸢尾花原数据集是距离目标样本最近的点,然后依次是1, 45, 34, 12, 49, 2......
#鸢尾花数据集测试
from sklearn.datasets import load_iris
X, y = load_iris(True)
#线性计算目标集的最小距离下标
targetX = np.array([5, 3, 1.2, 0.3])
minDistIndex = np.argsort(np.linalg.norm((X-targetX), axis=1))
<<<< 滑动查看完整代码 >>>>

然后,我们通过自己写的KD树,分别取K=1, 2, 3, 5, 10来验证下是否正确。
#K=1时
knn = KNN(K=1)
knn.fit_tree(X, y)
knn.transform_tree(targetX)
#K=2时
knn = KNN(K=2)
knn.fit_tree(X, y)
knn.transform_tree(targetX)
#K=3时
knn = KNN(K=3)
knn.fit_tree(X, y)
knn.transform_tree(targetX)
#K=5时
knn = KNN(K=5)
knn.fit_tree(X, y)
knn.transform_tree(targetX)
#K=10时
knn = KNN(K=10)
knn.fit_tree(X, y)
knn.transform_tree(targetX)
K=1时,

K=2时,
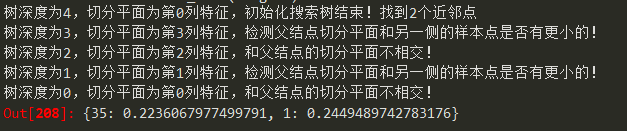
K=3时,

K=5时,

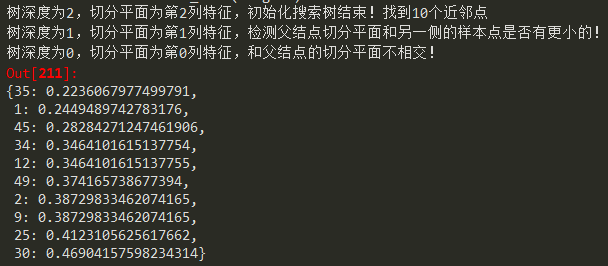
K=10时,
作者:TalkingData金融咨询团队 张伟
转载请联系获取授权
推荐阅读:




TalkingData——用数据说话
每天一篇好文章,欢迎分享关注