1967年,斯坦福大学的两位研究员Cover和Hart, 以 《战国策》中 “物以类聚,人以群分 ”的思想, 提出了一种实用的机器学习算法。它的基本思想是这样的:某家餐厅新出了一款汉堡D,不知道如何定价。参考店里已有的商品发现:汉堡A-18元,汉堡B-22元,汉堡C-38元,可乐A-8元,可乐B-9元,薯条A-12元...
相比可乐、薯条,汉堡D与同类汉堡A/B/C的特征更接近 )。于是,他们决定暂时把新汉堡的价格定为汉堡A/B/C的平均价,26元。这就是被称为数据挖掘10大算法之一的K近邻算法 (KNN),利用数据集对特征 向量空间进行划分,并作为其分类的模型。 简单的说,假设现在有100种食品(训练集),多数属于某个类,就把该实例分为这个类 (汉堡)。 下面我们简单介绍KNN的三要素,重点关注它的实现方法 。 01 距离度量 当我们通过特征工程或神经网络获得了数据集和新样本的特征后,首先需要确定一种距离度量策略,来衡量距离的远近。 机器学习领域常用的距离度量方法有欧式距离、余弦距离、曼哈顿距离、dot内积等等。 其中,n维特征的a、b向量的欧式距离体现数值上的绝对差异,余弦距离体现方向上的相对差异 。对向量经过归一化 处理后,两者的效果基本是等价的。 更多距离度量方法,可以参考:https://zhuanlan.zhihu.com/p/336946131 02 K值和决策规则 有了距离度量方法后,我们需要确定参数k和最终的决策规则。 如果选择较小的k值,相当于只取少量的样本进行预测,预测结果会对近邻的样本点非常敏感。换句话说,k值减小意味着整体模型变得复杂,容易发生过拟合。 如果选择较大的k值,预测的样本会更多,与实例不太相似的样本也会参与预测,意味着整体的模型变得简单。 极端情况下,交叉验证 选取最优的k。 至于决策规则,对于分类 而言,一般采用多数表决规则,少数服从多数 。对于回归 任务,可以采用平均法则 。 如果不打算将该算法实际应用的读者,读到这儿就可以啦。相信今后看到KNN这个词,一定不会陌生。想将该算法予以实践的读者,请浏览到最后哦! 03 KNN实现 KNN的原理非常简单,难点在于如何实现KNN算法 。受并发、时延等条件限制,高效性 往往是我们实际项目中「算法落地」要考虑的重要因素。 实际上,K近邻的实现方法多达数十种,下面将抛砖引玉,介绍几种常用的方法。 线性扫描 即暴力法。将新样本和训练样本逐一比对,最终挑选距离最接近的k个样本,时间复杂度O(n)。 对于样本数量比较少的情况,这种方法简单稳定,已经能有不错的效果。但是数据规模较大时,时间开销线性上升,无法接受。 KD树 KD树是二叉树,核心思想是对 k 维特征空间不断切分(假设特征维度是100,对于0-99中的每一个维度,以中值递归切分 )构造的树,每一个节点是一个超矩形,小于结点的样本划分到左子树,大于结点的样本划分到右子树。 构造完毕后,检索时(1)从根结点出发,递归向下访问KD树。若目标点 x 当前维的坐标小于切分点的坐标,移动到左子树,否则移动到右子树,直到叶结点;(2)以此叶结点为“最近点”,递归地向上回退,查找该结点的兄弟结点中是否存在更近的点,若存在,则更新“最近点”,否则回退;(3)未到达根结点时继续执行(2);(4)回退到根结点时,搜索结束。 KD树在特征维度小于20时效率最高 ,一般适用于训练样本数远大于空间维数时的k近邻搜索。当空间维数接近训练实例数时,效率会迅速下降,几乎接近线形扫描。 Annoy Annoy,全称“A pproximate N earest N eighbors O h Y eah”,是一种适合实际应用的快速相似查找算法。 Annoy 同样通过建立一个二叉树,使得每个点查找时间复杂度是O(log n)。和KD树不同的是,Annoy没有对k维特征进行切分。 Annoy的每一次空间划分,可以看作聚类数为2的KMeans过程 。收敛后在产生的两个聚类中心连线之间建立一条垂线(图中的黑线),把数据空间划分为两部分。 在划分的子空间内不停的迭代划分,直到每个子空间最多只剩下k个数据节点,划分结束。 最终生成的二叉树具有类似如下结构,二叉树底层是叶子节点,记录原始数据;中间节点记录的是分割超平面的信息。查询过程和KD树类似,先从根向叶子结点递归查找,再向上回溯即可。 HNSW 和前几种算法不同,HNSW(H ierarchcal N avigable S mall W orld graphs)是基于图存储 的数据结构。
假设我们现在有13个2维数据向量,我们把这些向量放在了一个平面直角坐标系内,隐去坐标系刻度,它们的位置关系如上图所示。
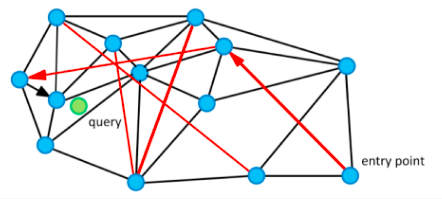
朴素查找法:把某些点和点之间连上线,构成一个查找图,存储备用;当我想查找与粉色点最近的一点时,我从任意一个黑色点出发,计算它和粉色点的距离,与这个任意黑色点有连接关系的点我们称之为“友点”(直译),然后我要计算这个黑色点的所有“友点”与粉色点的距离,从所有“友点”中选出与粉色点最近的一个点,把这个点作为下一个进入点,继续按照上面的步骤查找下去。
如果当前黑色点对粉色点的距离比所有“友点”都近,终止查找,这个黑色点就是我们要找的离粉色点最近的点。
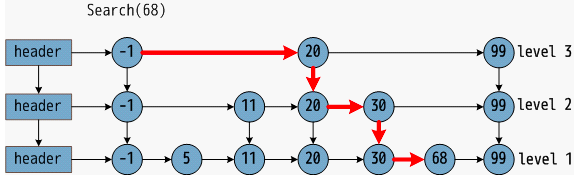
https://blog.csdn.net/u011233351/article/details/85116719 为了达到快速搜索的目标,HNSW在构建图时还至少要满足如下要求:1)图中每个点都有“友点”;2)相近的点都互为“友点”;3)图中所有连线的数量最少;4)配有高速公路机制的构图法 。 HNSW低配版——NSW论文中配了这样一张图,黑线是近邻点连线,红线是“高速公路” ,如此可以大幅减少平均搜索的路径长度。 在NSW基础之上,HNSW加入跳表结构 做了进一步优化。最底层是所有数据点,每一个点都有50%概率进入上一层的有序链表。这样可以保证表层是“高速通道”,底层是精细查找 。 通过层状结构,将边按特征半径进行分层,使每个顶点在所有层中平均度数变为常数,从而将NSW的计算复杂度由多重对数复杂度降到了对数复杂度 。 关于HNSW的详细介绍可以参考原论文[2]和博客HNSW算法理论的来龙去脉[3]。 04 实验 实验在CLUE发布的今日头条短文本分类数据集 上进行,训练集规模:53,360条短文本。 实验环境 :Ubuntu 16.04.6,CPU:126G/20核,python 3.6requirement :scikit-learn、annoy、hnswlib、bert-as-service实验中使用了肖涵博士开源的bert-as-service服务预先将文本编码为768维度的特征向量,作为输入特征。距离度量统一采用欧式距离 。 为了方便测试,我从验证集中随机抽取了200条 样本,使用不同的KNN实现方法统计top1-top3的查找准确率和时间开销。具体如下:
我们发现,Annoy算法的Top准确率相差不大,200条样本的批量查找速度却从之前的15秒(75ms /条)降到了0.08秒(0.4ms/条),提升了100倍以上 。 HNSW算法预测200条样本耗时0.05秒(0.25ms/条) ,略优于Annoy。此外,同样的53,360条特征向量(768维度),保存为静态索引文件 后,ann索引的大小是227MB,hnsw索引是171MB,从这一点看hnsw也略胜一筹,可以节约部分内存。 实验部分代码可以参考:https://zhuanlan.zhihu.com/p/152522906/ 05 总结 本文介绍了K近邻算法,重点关注其实现方式。通过理论介绍和实验证明,Annoy和HNSW 是可以在实际业务中落地的算法。 其中Bert/Sentence-Bert+HNSW 的组合会有不错的(粗排)召回效果。 K近邻算法的实现方法其实还有很多,感兴趣的同学可以阅读相关论文进一步研究。 在NLP情报局公众号后台回复“ 三件套 ”, 即可 获取深度学习 三件套: 《PyTorch深度学习》,《Hands-on Machine Learning》,《Python深度学习》 欢 迎 关 注 👇 由于微信平台算法改版,订阅号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标 我们帮我们点【在看 】。星标具体步骤: (2)点击 右上角的小点点 ,在弹出页面点击“ 设为星标 ”,就可以啦 参 考 文 献 [1] K近邻算法哪家强?KDTree、Annoy、HNSW原理和使用方法介绍: https://zhuanlan.zhihu.com/p/152522906/edit [2] Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs [3] 一文看懂HNSW算法理论的来龙去脉:
https://blog.csdn.net/u011233351/article/details/85116719
[4] 快速计算距离Annoy算法原理及Python使用:
https://blog.csdn.net/m0_37850187/article/details/92712490
原创不易,有收获的话请帮忙点击分享、 点赞 、 在看 吧🙏