
springboot第51集:lombok,Swagger,k8s,缓存,sentinel周刊
- @Getter和@Setter :该注解可以使用在类上也可以使用在属性上。生成的getter遵循布尔属性的约定。在使用该注解时,会默认生成一个无参构造。和对应的
getter、setter方法 - @ToString :该注解使用在类上,编译后toString方法返回将会以字段的名称-值的形式输出
- @EqualsAndHashCode :该注解使用在类上,同时生成
equals和hashCode。 - @AllArgsConstructor :该注解使用在类上,提供全参数的构造方法,默认不提供无参构造。
- @NoArgsConstructor :该注解使用在类上,提供无参构造
- @Data :使用
@Data注解就可以有下面几个注解的功能:@ToString、@Getter、@Setter、@EqualsAndHashCode、@NoArgsConstructor。
需要注意的是:同时使用@Data和@AllArgsConstructor后 ,默认的无参构造函数失效,如果需要它,要重新设置@NoArgsConstructor - @Slf4j :在类上注解后,可直接调用log
- @Synchronized :方法中所有的代码都加入到一个代码块中,默认静态方法使用的是全局锁,普通方法使用的是对象锁,当然也可以指定锁的对象。
- @SneakyThrows :当我们需要抛出异常,在当前方法上调用,不用显示的在方法名后面写 throw
- @NonNull :增加不为空判断
- @Builder:bulder 模式构建对象。
- @Cleanup:自动化关闭流,相当于
try with resource
代码示例
-
@Api
@Api(value = "用户博客", tags = "博客接口")
public class NoticeController {
}
-
@ApiOperation
@GetMapping("/detail")
@ApiOperation(value = "获取用户详细信息", notes = "传入notice" , position = 2)
public R<Notice> detail(Integer id) {
Notice detail = noticeService.getOne(id);
return R.data(detail );
}
-
@ApiResponses
@GetMapping("/detail")
@ApiOperation(value = "获取用户详细信息", notes = "传入notice" , position = 2)
@ApiResponses(value = {@ApiResponse(code = 500, msg= "INTERNAL_SERVER_ERROR", response = R.class)})
public R<Notice> detail(Integer id) {
Notice detail = noticeService.getOne(id);
return R.data(detail );
}
-
@ApiImplicitParams
@GetMapping("/list")
@ApiImplicitParams({
@ApiImplicitParam(name = "category", value = "公告类型", paramType = "query", dataType = "integer"),
@ApiImplicitParam(name = "title", value = "公告标题", paramType = "query", dataType = "string")
})
@ApiOperation(value = "分页", notes = "传入notice", position = 3)
public R<IPage<Notice>> list(@ApiIgnore @RequestParam Map<String, Object> notice, Query query) {
IPage<Notice> pages = noticeService.page(Condition.getPage(query), Condition.getQueryWrapper(notice, Notice.class));
return R.data(pages );
}
-
@ApiParam
@PostMapping("/remove")
@ApiOperation(value = "逻辑删除", notes = "传入notice", position = 7)
public R remove(@ApiParam(value = "主键集合") @RequestParam String ids) {
boolean temp = noticeService.deleteLogic(Func.toIntList(ids));
return R.status(temp);
}
-
@ApiModel与@ApiModelProperty
@Data
@ApiModel(value = "BladeUser ", description = "用户对象")
public class BladeUser implements Serializable {
private static final long serialVersionUID = 1L;
@ApiModelProperty(value = "主键", hidden = true)
private Integer userId;
@ApiModelProperty(value = "昵称")
private String userName;
@ApiModelProperty(value = "账号")
private String account;
@ApiModelProperty(value = "角色id")
private String roleId;
@ApiModelProperty(value = "角色名")
private String roleName;
}
-
@ApiIgnore()
@ApiIgnore()
@GetMapping("/detail")
public R<Notice> detail(Integer id) {
Notice detail = noticeService.getOne(id);
return R.data(detail );
}
简介
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
特点
- 解除sql与程序代码的耦合,sql语句与代码分离,存放于xml配置文件中。
- 通过提供DAO层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。
- 将查询的结果集与java对象自动映射。
- 支持编写原生SQL,接近JDBC,比较灵活。
- 可用逻辑标签控制动态SQL的拼接。
简介
MyBatis-Plus(简称 MP)是一个MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
特性
-
无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
-
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
-
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
-
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
-
支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer2005、SQLServer 等多种数据库
-
支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
-
支持 XML 热加载:Mapper 对应的 XML 支持热加载,对于简单的 CRUD 操作,甚至可以无 XML 启动
-
支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
-
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
-
支持关键词自动转义:支持数据库关键词(order、key......)自动转义,还可自定义关键词
-
内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
-
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
-
内置性能分析插件:可输出 Sql 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
-
内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
-
内置 Sql 注入剥离器:支持 Sql 注入剥离,有效预防 Sql 注入攻击
-
统一开发规范不仅有利于代码风格的完整,更有利于系统维护、交接的相关事项
-
现在越来越多的团队开始着重软件开发的规范,希望大家也可以重视起来
-
我们推荐阿里巴巴的开发手册以及开发规约插件辅助代码工作
地址
- github地址:https://github.com/alibaba/p3c
- 手册地址:https://developer.aliyun.com/topic/java20
- idea插件地址:https://github.com/alibaba/p3c/blob/master/idea-plugin/README_cn.md
- eclipse插件地址:https://github.com/alibaba/p3c/blob/master/eclipse-plugin/README_cn.md
 image.png
image.png新建微服务工程
获取认证token
接口地址:/blade-auth/token
请求方式:POST
请求数据类型:application/json
响应数据类型:*/*
接口描述:
传入租户ID:tenantId,账号:account,密码:password
请求参数:
请求参数:
| 参数名称 | 参数说明 | 请求类型 | 是否必须 | 数据类型 | schema |
|---|---|---|---|---|---|
| grantType | 授权类型 | query | true | string | |
| tenantId | 租户ID | query | true | string | |
| account | 账号 | query | false | string | |
| password | 密码 | query | false | string | |
| refreshToken | 刷新令牌 | query | false | string | |
响应状态:
| 状态码 | 说明 | schema |
|---|---|---|
| 200 | OK | R«AuthInfo» |
| 201 | Created | |
| 401 | Unauthorized | |
| 403 | Forbidden | |
| 404 | Not Found | |
响应参数:
| 参数名称 | 参数说明 | 类型 | schema |
|---|---|---|---|
| code | 状态码 | integer(int32) | integer(int32) |
| data | 承载数据 | AuthInfo | AuthInfo |
| accessToken | 令牌 | string | |
| account | 账号名 | string | |
| authority | 角色名 | string | |
| avatar | 头像 | string | |
| expiresIn | 过期时间 | integer(int64) | |
| license | 许可证 | string | |
| oauthId | 第三方系统ID | string | |
| refreshToken | 刷新令牌 | string | |
| tenantId | 租户ID | string | |
| tokenType | 令牌类型 | string | |
| userId | 用户ID | integer(int64) | |
| userName | 用户名 | string | |
| msg | 返回消息 | string | |
| success | 是否成功 | boolean | |
响应示例:
{
"code": 0,
"data": {
"accessToken": "",
"account": "",
"authority": "",
"avatar": "",
"expiresIn": 0,
"license": "",
"oauthId": "",
"refreshToken": "",
"tenantId": "",
"tokenType": "",
"userId": 0,
"userName": ""
},
"msg": "",
"success": true
}
缓存穿透、缓存雪崩对应的解决方案。
缓存穿透
缓存穿透指的是查询一个一定不存在的数据,由于缓存不命中,每次都要去数据库查询,导致数据库压力过大。解决方案如下:
- 布隆过滤器: 使用布隆过滤器判断请求的数据是否存在。如果数据不存在,就不会继续往下查询数据库。
- 空值缓存: 将查询不存在的数据的结果设置为空值,并设置一个较短的过期时间。这样,下次相同的查询就会直接返回空值,而不会继续查询数据库。
缓存雪崩
缓存雪崩指的是缓存中大量的数据同时失效,导致所有的请求都直接访问数据库,造成数据库压力过大。解决方案如下:
- 过期时间分散: 设置缓存的过期时间分散开,而不是集中在同一时刻。这样可以减少大量缓存同时失效的可能性。
- 热点数据永不过期: 对于一些热点数据,可以设置其缓存永不过期,或者采用手动刷新策略,避免大量请求同时刷新。
- 限流降级: 当缓存失效导致大量请求涌入时,可以考虑限制请求的并发数,或者进行降级处理,直接返回默认数据。
- 多级缓存: 使用多级缓存体系,将缓存分为多个层次,从而减轻缓存雪崩的影响。例如,本地缓存、分布式缓存、持久化存储等。
- 异步加载: 对于缓存失效时的数据加载,可以采用异步加载的方式,避免大量请求同时到达数据库。
@TableId 是 MyBatis-Plus 中的注解,用于标识实体类中的主键字段。@TableId 注解有一些属性,其中 value 表示数据库表中的字段名,type 表示主键生成策略。IdType 是 MyBatis-Plus 提供的一个枚举,它定义了一些常见的主键生成策略,如 IdType.AUTO(自动增长)、IdType.ID_WORKER(雪花算法)等。
在你的实体类中,@TableId(value = "id", type = IdType.ID_WORKER) 表示你的数据库表中有一个名为 "id" 的字段,该字段的值由雪花算法生成。
serialVersionUID 是 Java 中的一个序列化版本号。在 Java 中,Serializable 接口用于标识一个类的对象可以被序列化(即转换成字节流)以便在网络上传输或者保存到文件中。serialVersionUID 的作用是为了在反序列化时确保类的版本一致性,避免因为类的变更导致反序列化失败。
在你的实体类中,private static final long serialVersionUID = 1L; 表示你的类有一个版本号为 1L 的序列化标识。通常,如果你的实体类没有特殊的需求,只是简单地用于持久化,你可以简单地使用默认的 serialVersionUID(例如 private static final long serialVersionUID = 1L;),不需要过多关注。
综上所述,你的实体类的主键 "id" 是一个雪花算法生成的自定义主键,用于标识实体对象的唯一性,而 serialVersionUID 是用于序列化版本控制的标识。
@ApiIgnore 是 SpringFox Swagger 中的一个注解,用于标记某个类或方法不被 Swagger 自动生成文档。当你在某个 Controller 类或方法上添加了 @ApiIgnore 注解时,Swagger 将会忽略该类或方法,不在 Swagger 文档中生成相应的接口信息。
这个注解通常用于标记一些内部的、不对外开放的接口或方法,避免将这些接口信息暴露在生成的 API 文档中。使用 @ApiIgnore 注解可以灵活控制哪些接口需要被 Swagger 文档记录,哪些接口不需要。
// Example checking for updates using axios
import axios from 'axios';
const checkForUpdates = async () => {
try {
const response = await axios.get('/api/check-updates');
const latestVersion = response.data.latestVersion;
if (latestVersion > process.env.VERSION) {
// Trigger the update process
// You can use service workers, prompt the user to refresh, etc.
}
} catch (error) {
console.error('Error checking for updates', error);
}
};
setInterval(checkForUpdates, 3600000); // Check for updates every hour
从数量维度上,将单条上报聚合成多条上报,大大减少了数量的请求(比如列表页每条数据的曝光事件)
从时间维度上,先本地化存储数据,将上报请求延后,优先处理业务逻辑请求,在程序空闲时进行上报
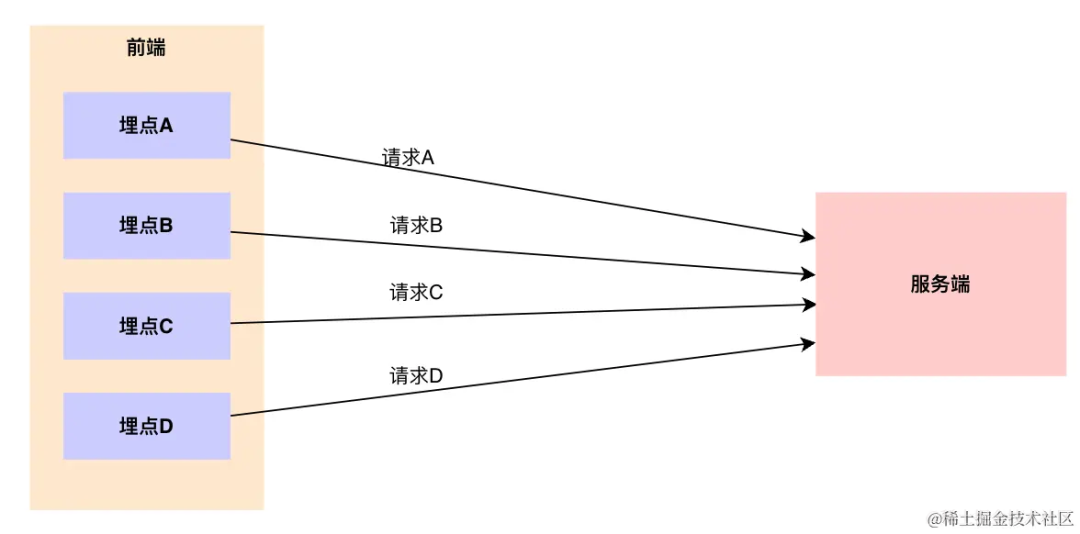 image.png
image.png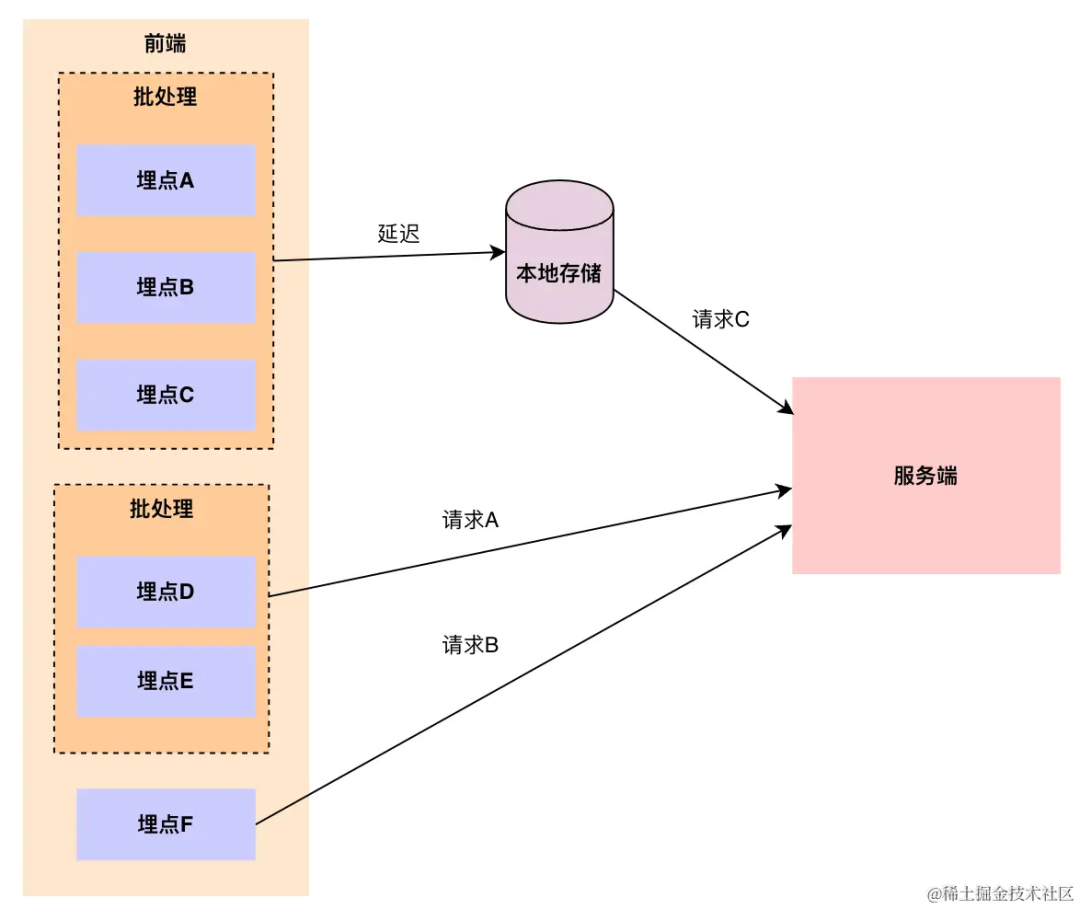 image.png
image.png对于数据请求处理,主要考虑的有三个因素
- 跨域的问题
- 页面销毁时,如何保障还未成功上传的数据完成数据上传请求
- 大数据量的上传
这样看的话数据请求方式上没有银弹,每种方式都有一定的缺陷
所以,一般采用组合方式,根据数据量,选择Image或者Beacon的方式,若检测不支持Beacon, 在大数据量时回退到传统的XHR请求
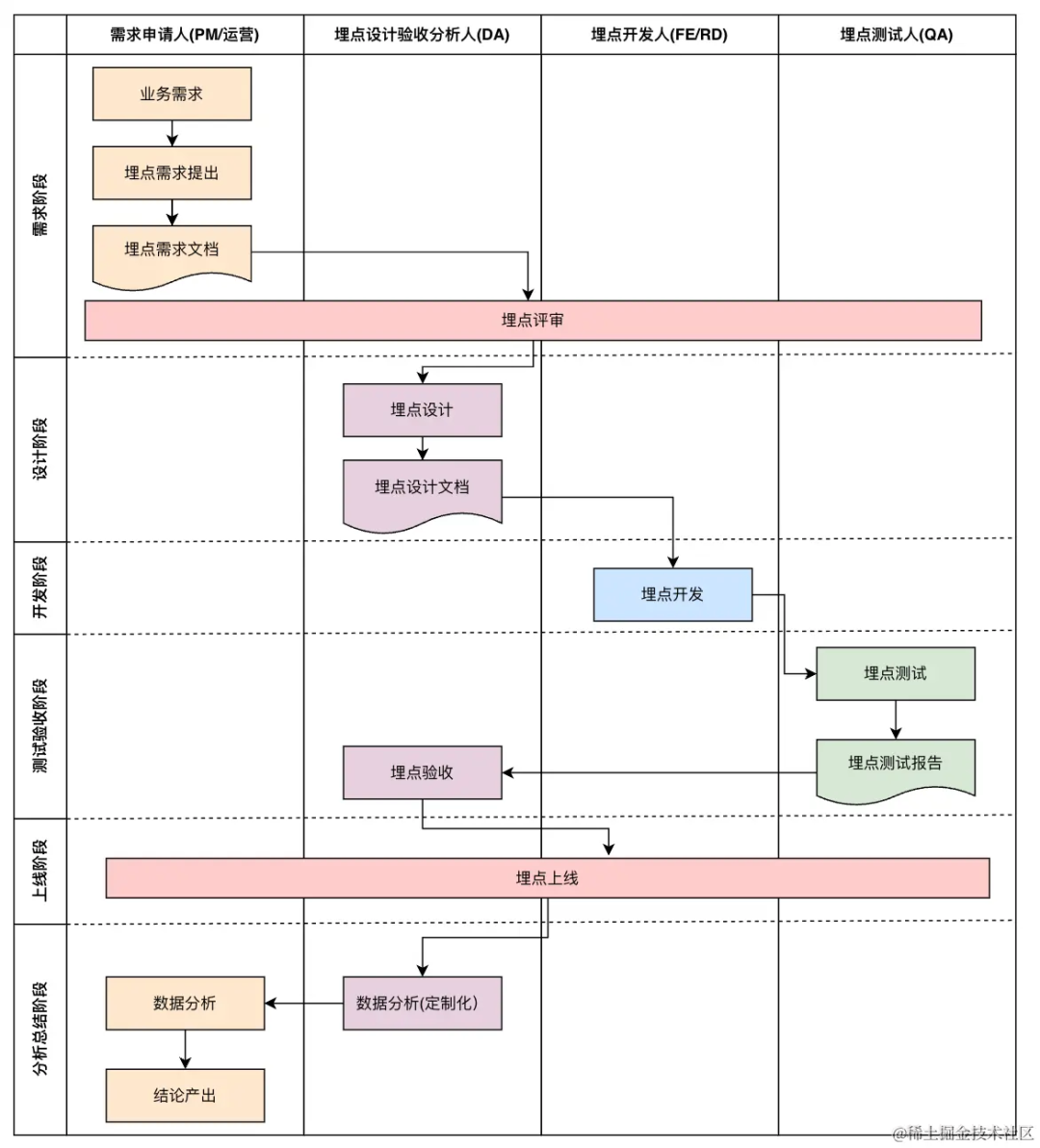 image.png
image.png image.png
image.png image.png
image.png- 基于SpringBoot2、SpringCloud Hoxton、Mybatis构建核心架构
- 采用Oauth2协议进行统一的Token下发与鉴权,保证系统安全性
- 使用Gateway进行网关的统一转发,生产环境采用Traefik代理
- 微服务统一注册至Nacos,Nacos担任注册中心与配置中心的角色
- 采用Feign进行远程调用,Ribbon进行负载,Hystrix进行熔断
- 采用Sentinel进行限流,保障系统整体的性能
- 集成Seata,为分布式事务保驾护航
- 具有日志收集与监控服务为一体的能力
- 支持FatJar、Docker、K8s、阿里云等多种部署方式
- 集成Sentinel从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
- 注册中心、配置中心选型Nacos,为工程瘦身的同时加强了各模块之间的联动。
- 封装集成了基于注解+Web可视化的数据权限,灵活配置,无需重启直接生效。
- 定制了基于Nacos的轻量级、高拓展性的动态网关,完美支持多团队开发。
- 精心设计集成了minio,完美支持多租户模式下的oss对象存储需求。
- 集成Oauth2协议,完美支持多终端的接入与认证授权。
- 项目分包明确,规范微服务的开发模式。
- 一套代码兼容MySql、Oracle、PostgreSQL,适应企业各种不同场景的需求。
- 集成了很多企业急切所需的例如多租户、Oauth2授权认证、工作流、分布式事务等等功能。
- 集成最新版本ELK,界面美观,功能强大。同时深度定制了日志模块,支持分布式日志追踪功能。
- 深度定制了Flowable工作流,完美支持SpringCloud分布式服务的场景,以远程调用的方式进行操作。
- 分布式锁 基于Redisson封装的高性能、简单易用的分布式锁插件
- 消息队列 完美集成Kafka、Rabbit、SpringCloud Stream等消息队列
- 分布式任务调度 极简集成xxl-job,支持分布式任务调度功能
- 钉钉监控告警 增强监控,微服务上下限集成钉钉告警
- 分布式日志模块 集成7.x版本ELK,支持分布式日志追踪功能
- Zipkin链路追踪 集成Zipkin分布式链路追踪,快速查找每个请求的调用链
- Turbine集群监控 集成Turbine集群监控,方便查看hystrix的实时状态
- Seata分布式事务 定制集成Seata,支持分布式事务,无代码侵入,不失灵活与简洁
- 动态网关鉴权 基于Nacos的动态网关鉴权,可在线配置,实时生效
- 多租户对象存储系统 在SaaS系统中,各租户可自行配置文件上传至自己的私有OSS
- 分布式文件服务 集成minio等优秀的第三方,提供便捷的文件上传与管理
- 动态聚合文档 实现基于Nacos的Swagger SpringCloud聚合文档
- 动态网关 集成基于Nacos的轻量级、高拓展性动态网关
- Oauth2 集成Oauth2协议,完美支持多终端的接入与认证授权
- Dubbo 完美集成Dubbo最新版,支持远程RPC调用
- Sentinel 集成Sentinel从流量控制、熔断降级、系统负载等多个维度保护服务的稳定性
- Nacos 集成阿里巴巴的Nacos完成统一的服务注册与配置
- Hoxton SpringCloud整体版本升级至Hoxton
sentinel-dashboard:1.8.0
 image.png
image.png"生产版本镜像备份" 通常指的是在生产环境中的应用程序或系统的镜像文件的备份。在软件开发和部署中,一个镜像通常是一个包含了应用程序、运行时环境和相关配置的可执行文件。
生产版本的镜像备份是为了在生产环境中保留一个可恢复的状态。备份通常包括以下内容:
- 应用程序代码和依赖: 生产版本的镜像包含了应用程序的所有代码以及运行时所需的依赖项。这确保了备份的完整性和可恢复性。
- 运行时环境: 镜像中通常包含了应用程序运行所需的操作系统、库和其他运行时环境。这保证了备份可以在相同的环境中重新部署。
- 配置文件: 镜像备份还包括了应用程序的配置文件,这些文件包含了应用程序的设置和参数,确保备份可以在相同的配置下正常运行。
在生产环境中进行镜像备份的原因包括:
- 灾难恢复: 在发生灾难性事件或数据丢失时,可以使用备份镜像还原系统到之前的状态。
- 版本回滚: 如果升级或部署新版本的应用程序导致问题,可以通过还原到之前的备份版本来回滚。
- 性能测试: 镜像备份也可用于在其他环境中进行性能测试、安全测试等。
- 快速部署: 在新的环境中,使用备份镜像可以快速部署应用程序,而不必从头开始配置。
备份镜像是保障系统可用性和稳定性的关键步骤,确保在各种情况下都能够迅速、可靠地恢复。
生产版本镜像备份的示例文件通常是通过一定的策略和工具生成的,具体放置在哪里取决于组织和部署环境的实际情况。以下是一个简单的示例,说明了可能的备份内容和一种备份策略:
备份内容和策略示例:
-
Docker 镜像文件: Docker 镜像文件是应用程序和其依赖项的打包,可以通过 Docker 命令行或者 Docker Compose 进行备份。备份的频率可以根据需求设定,例如每次部署新版本时备份。
示例路径:
/var/lib/docker/images/ -
应用程序代码: 如果应用程序的代码不包含在 Docker 镜像中,而是通过其他手段部署,那么需要备份应用程序的源代码。备份频率可以根据代码变更的频率而定。
示例路径:
/opt/app/source_code/ -
数据库备份: 如果应用程序使用数据库,那么数据库的备份也是至关重要的。数据库备份可以使用数据库管理工具或者数据库备份工具进行。
示例路径:
/var/backups/database/ -
配置文件: 包含应用程序的配置文件,这些文件包括了应用程序的设置和参数。
示例路径:
/etc/app/config/
备份策略:
- 定期全量备份: 按照一定的时间间隔进行完整的系统备份,包括 Docker 镜像、应用程序代码、数据库和配置文件。可以每日、每周或每月执行一次。
- 增量备份: 在全量备份的基础上,只备份自上一次全量备份以来发生变化的部分。这有助于减少备份所需的时间和存储空间。
- 自动化备份任务: 使用自动化工具或脚本来执行备份任务,确保备份的一致性和及时性。
- 安全存储: 将备份文件存储在安全的地方,可以是远程服务器、云存储等,以防止在本地硬件故障或灾难事件中丢失备份。
"dump 一下堆快照文件" 指的是生成并保存一个 Java 虚拟机堆内存的快照文件。这个快照文件通常包含了 JVM 堆内存的详细信息,包括对象的分布、引用关系等。这对于进行内存分析、发现内存泄漏、定位性能问题等方面非常有用。
在 Java 中,你可以使用一些工具来生成堆快照文件,其中最常见的是 Java VisualVM 和命令行工具 jmap。
使用 Java VisualVM 进行 Heap Dump:
- 打开 Java VisualVM(通常可以在 JDK 的
bin目录下找到jvisualvm.exe或jvisualvm)。 - 在左侧的应用程序列表中选择你要生成堆快照的 Java 进程。
- 在 "监视" 标签页下,选择 "堆转储" 按钮。
- 选择 "Dump Snapshot"。
- 选择保存快照的位置和文件名。
使用 jmap 命令进行 Heap Dump:
在命令行中,你可以使用 jmap 命令来生成堆快照。以下是一个简单的示例:
jmap -dump:file=heapdump.hprof <pid>
其中 <pid> 是你的 Java 进程的进程 ID。这个命令将在当前目录下生成一个名为 heapdump.hprof 的堆快照文件。
操作系统监控是指对计算机系统中的操作系统进行实时、定期或周期性地收集、分析和展示相关性能数据的过程。通过操作系统监控,可以及时了解系统的运行状况,识别潜在的问题,并采取必要的措施来优化性能和提高系统稳定性。以下是一些常见的操作系统监控指标和工具:
常见的操作系统监控指标:
- CPU 使用率: 衡量 CPU 处于繁忙状态的程度,通常以百分比表示。
- 内存使用率: 监测系统内存的占用情况,防止内存不足导致的性能问题。
- 磁盘空间: 跟踪磁盘空间的使用情况,防止磁盘溢出和存储问题。
- 网络流量: 观察网络接口的传输速率,帮助识别网络瓶颈和故障。
- 系统负载: 评估系统的负荷情况,了解系统的繁忙程度。
- 进程和线程: 查看系统中正在运行的进程和线程的数量和状态。
- 文件系统 I/O: 跟踪文件系统的输入和输出操作,检测存储性能问题。
- 系统日志: 分析系统生成的日志文件,识别异常事件和错误。
常见的操作系统监控工具:
- top: 在 Unix 和类 Unix 系统上,
top命令提供了实时的系统性能数据,包括 CPU 使用率、内存占用等。 - htop: 类似于
top,但提供了更友好的用户界面和更多的功能。 - sar: System Activity Reporter,用于收集、报告和保存系统活动数据,可以用于生成性能报告。
- nmon: 在 AIX 和 Linux 等系统上使用的监控工具,提供 CPU、内存、网络等多方面的数据。
- Windows Performance Monitor: Windows 操作系统自带的性能监控工具,可用于监视各种系统性能指标。
- Grafana 和 Prometheus: 开源的监控和度量工具,可用于可视化和报告系统性能。
- Nagios 和 Zabbix: 网络监控工具,可用于远程监控多个服务器的性能。
- Sysdig: 提供实时容器监控和安全审计的工具。
以下是关于提到的一些监控指标的简要介绍:
- Thread(线程数): 衡量系统当前运行的线程数量。线程是操作系统调度的基本单位,线程数的增加可能会导致系统负担加重,过多的线程可能引发性能问题。
- YGC(Young Garbage Collection): 表示 Young 区域的垃圾收集次数。在 Java 虚拟机中,内存分为 Young、Old 和 Perm 区域,YGC 主要回收 Young 区的垃圾。频繁的 YGC 可能表明系统中有大量的短周期对象。
- FGC(Full Garbage Collection): 表示 Full GC(或称为 Major GC)的次数。Full GC 是指对整个堆内存进行垃圾收集,包括 Young 和 Old 区域。频繁的 FGC 可能导致系统停顿,对性能有负面影响。
- Log(日志大小): 表示系统产生的日志文件的大小。日志是记录系统运行状态和事件的重要信息,日志大小的增加可能占据磁盘空间,同时大量的日志也需要更多的系统资源来处理和存储。
这些指标通常用于系统性能监控和故障排除。例如,在 Java 应用程序中,通过监控 YGC 和 FGC 的次数,可以评估垃圾收集的效率和系统内存的使用情况。而线程数和日志大小则反映了系统的并发程度和日志记录的活跃程度。监控这些指标有助于及时发现潜在问题,进行性能优化和故障处理。
加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview