
详解:深度学习框架数据Pipeline设计

极市导读
随着GPU算力越来越强,对于数据处理Pipeline的效率也提出了越来越高的要求。本文整理分析了Pytorch的数据Pipeline、MindSpore && Tensorflow的local数据处理pipeline、Tensorflow中的分布式数据处理Pipeline >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
过去的双月我一直在做训练框架中数据模块的工作。核心目的在于优化IO的效率和预处理的加速,致力于支持更多更丰富的数据处理方式,以及提升整个数据处理的pipeline的效率。随着日后GPU算力越来越强,对于数据处理Pipeline的效率也提出了越来越高的要求。于是在双月的结束整理分析各个框架数据处理pipeline的设计。
以下文章第一节,第二节主要参考MindSpore架构师金雪峰的文章,这部分内容文章里面写得很全了,基本把我所想表达整理的内容全部写了。
金雪锋:AI框架中数据处理的挑战与解决思路
https://zhuanlan.zhihu.com/p/352487023
一、AI框架中的数据处理
深度学习框架核心三大件事:数据,计算和通信。数据模块主要包括数据读取(IO密集型)和数据变换(CPU密集型)。典型的训练数据处理流程如下图所示:

图片来自于 https://zhuanlan.zhihu.com/p/352487023
加载:指从各种异构存储中将训练数据加载到内存中,加载时涉及数据的IO、解码等处理;目前一般都会从HDFS中或者OBS中读取序列化存储的数据,并在内存中进行解析校验。
Shuffle:训练一般是多个epoch,通过shuffle打乱数据集不同epoch的数据排序,防止训练过拟合。如果数据集支持随机访问,则只需按不同顺序随机选择数据就可以非常有效地进行混洗shuffle。如果数据集不支持随机访问(或仅部分随机访问像多个文件对象),那么一个子集的数据可以加载到一个特殊的混洗缓冲区shuffle buffer中。
map:完成训练数据的预处理工作。map为数据集算子,表示对整个数据集的变换操作。这是tensorflow和mindspore这类框架的算子抽象模式。在pytorch中,更多是以单个数据为粒度的处理算子。
batch:数据的batch逻辑处理。
repeat:可以通过repeat的方式增加训练的总数据量;一次repeat就是加载一遍整个训练集。
模型在进行推理时,同样会涉及到数据处理,不同的是推理时一般加载单样本进行处理,而非数据集。典型的过程如下图所示:

图片来自于https://zhuanlan.zhihu.com/p/352487023
二、难点与挑战
2.1 数据处理的高效性
当前各AI框架的数据处理主要利用CPU运算,训练则利用GPU/AI芯片,两者是并行的。理想情况下,应该在每轮迭代开始前,就准备好完成增强之后的数据,保持训练过程持续地进行。然而在实际的训练中,很多时候数据处理成为了阻碍性能提升的瓶颈:或是因为从存储中读取数据的速度不足(I/O bound),或是因为数据增强操作效率过低(CPU bound)。
根据黄氏定律,GPU/AI芯片的算力每一年会提升一倍,相比于即将失效的摩尔定律,AI芯片的算力提升速度会远大于CPU。模型迭代计算效率的不断提升,对数据处理也提出了更高的要求:数据处理过程必须足够高效,才能够避免GPU/AI芯片因为等待训练数据而空闲。
2.2 数据处理的灵活性
数据处理的灵活性挑战主要体现在以下两个方面:
多源数据集读取
多源数据集读取主要有两种情况
不同数据源有着不同的格式。 在一个训练数据处理pipeline中涉及到不同数据源数据读取处理如下图所示
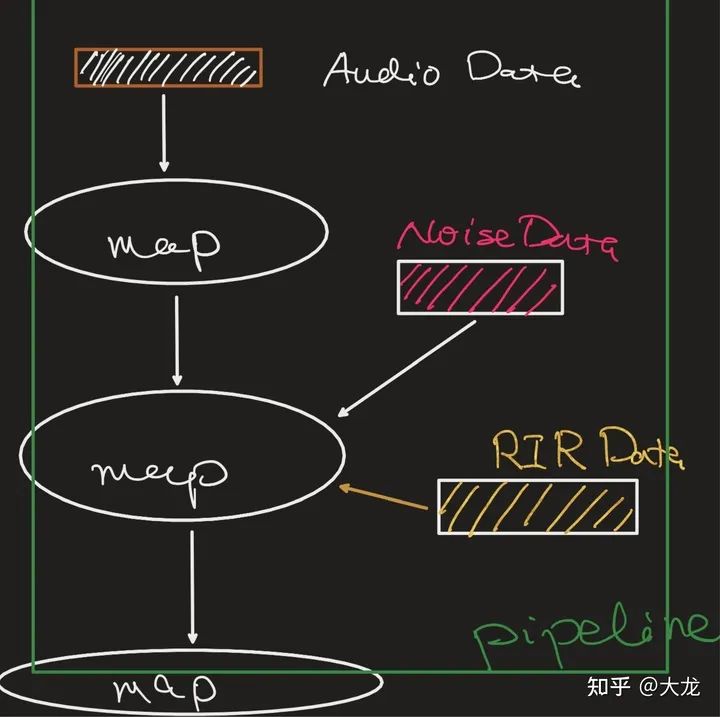
针对问题1目前常规的解决方案主要有针对不同的数据源定制相应的Reader和数据打包成统一格式,两种解决方案。问题2在tensorflow这种场景下不会成为大的问题,但是在pytorch中遇到这样的问题就需要特殊的处理,避免不同数据源的数据读取变成串行读取。
数据增强算法非常灵活,需要框架提供足够易用的接口来支持用户定制数据处理过程
为了方便算法工程师快速的实验各种预处理方法,算法框架要允许算法工程师轻易的增加新的预处理算子。但是数据pipeline的灵活性常常和效率是一对矛盾的点,很难兼顾二者。想要高效基本都需要底层C++实现算子,但是这对灵活性带来了麻烦。pytorch很灵活,但是做到高效需要做很多二次开发。
三、现有的框架中的数据pipeline流程
接下来我们介绍一下现存框架的数据pipeline,我们核心关心的是pipeline的灵活性和高效性设计。灵活性体现在要允许算法工程师灵活的自定义算子,降低开发的成本,高效性体现在要能够可拓展,能够高性能。没错,这是一个既要,又要,还要的问题。
Pytorch的数据Pipeline设计与实现
Pytorch的pipeline设计整体比较清晰明了,所以我们首先拿他开刀。接下来的内容中我主要依据我的这篇博客为主进行介绍,限于篇幅,这篇文章中主要以图片为主。
大龙:Pytorch数据Pipeline设计总结
https://zhuanlan.zhihu.com/p/351666693
关于Pytorch,我们首先介绍其数据Pipeline的抽象: Sampler, Dataset, Dataloader, DataloaderItor四个层次,其关系如下图所示。Sampler负责生成读取处理的数据Index序列,Dataset模块负责定义是数据的加载和预处理,DataloaderItor负责进行单进程/多进程数据处理的管理,Dataloader则负责最高层的用户交互。
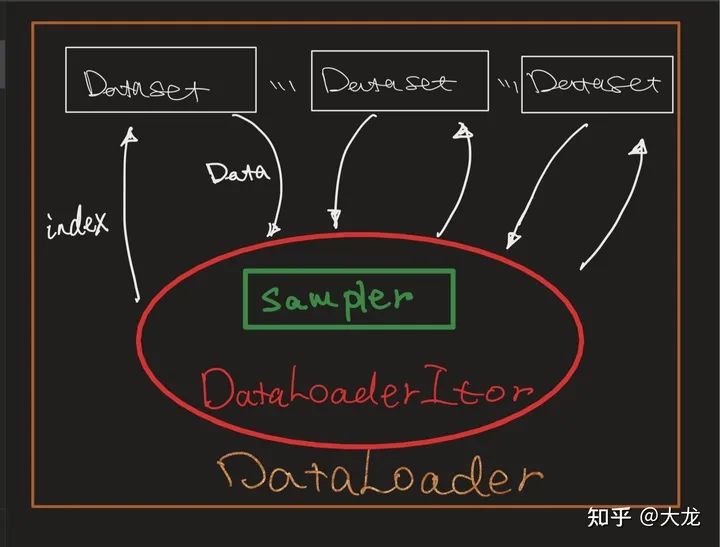
从pipeline的灵活性上讲,pytorch无疑是最灵活的,因为本身就是纯python的实现,自然对算法工程师来讲灵活定制成本最低,我们接下来介绍pipeline的高效性设计。pytorch中支持多进程数据加载,其核心流程图如下所示。
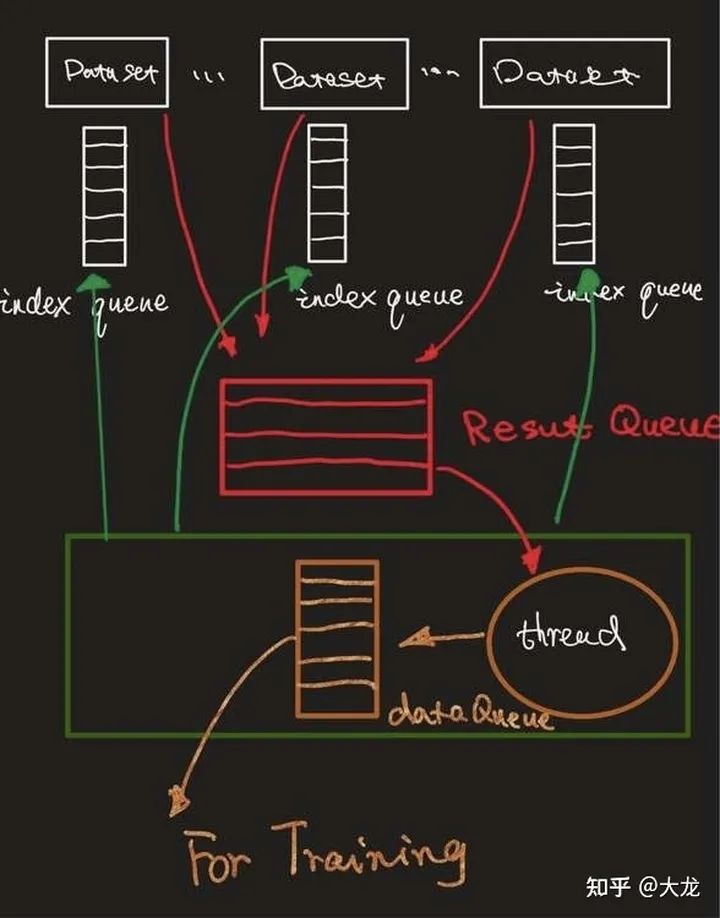
由主进程生成采样序列,放到各个读取进程的index队列中,每个进程读取处理完数据之后,把数据通过进程间队列result_queue来传给主进程,主进程中的子线程对数据做简单的处理(在pytorch中主要是pin memory的操作,加快CPU到GPU的数据拷贝)。主线程从数据队列中读取数据返回给模型进行。
MindSpore && Tensorflow的local数据处理pipeline
MindSpore和TF中的pipeline设计比较像,故在此一并介绍。这两个框架中的pipeline的设计思想我是非常喜欢的。其核心是把数据处理算子处理抽象为了两类:数据集算子和Tensor算子。数据集算子主要负责计算资源的调度和输入输出的控制,Tensor算子负责具体的数据增强的计算。一段典型的数据tensorflow预处理代码如下所示:
import tensorflow as tfimport tensorflow_addons as tfafrom tensorflow.keras.applications.resnet50 import ResNet50from tensorflow.keras.layers.experimental import preprocessingdef get_dataset(batch_size):# parse TFRecorddef parse_image_function(example_proto):image_feature_description =: tf.io.FixedLenFeature([], tf.string),: tf.io.FixedLenFeature([], tf.int64)}features = tf.io.parse_single_example(image_feature_description)image = tf.io.decode_raw(features['image'], tf.uint8)* 32 * 32])image = tf.reshape(image, [32, 32, 3])label = tf.cast(features['label'], tf.int32)return image, label# dilation filterdef dilate(image, label):dilateFilter = tf.zeros([3, 3, 3], tf.uint8)image = tf.expand_dims(image, 0)image = tf.nn.dilation2d(dilateFilter, strides=[1, 1, 1, 1],dilations=[1, 1, 1, 1],padding='SAME',data_format='NHWC')image = tf.squeeze(image)return image, label# blur filterdef blur(image, label):image = tfa.image.gaussian_filter2d(image=image,filter_shape=(11, 11), sigma=0.8)return image, label# rescale filterdef rescale(image, label):image = preprocessing.Rescaling(1.0 / 255)(image)return image, label# augmentation filtersdef augment(image, label):data_augmentation = tf.keras.Sequential(image = data_augmentation(image)return image, labelautotune = tf.data.experimental.AUTOTUNEoptions = tf.data.Options()= Falserecords = tf.data.Dataset.list_files('data/*',shuffle=True).with_options(options)# load from TFRecord filesds = tf.data.TFRecordDataset(records,num_parallel_reads=autotune).repeat()ds = ds.map(parse_image_function, num_parallel_calls=autotune)ds = ds.map(dilate, num_parallel_calls=autotune)ds = ds.map(blur, num_parallel_calls=autotune)ds = ds.batch(batch_size)ds = ds.map(rescale,num_parallel_calls=autotune)ds = ds.map(augment, num_parallel_calls=autotune)ds = ds.prefetch(autotune)return dsif __name__ == "__main__":model = ResNet50(weights=None,input_shape=(32, 32, 3),classes=10)=tf.losses.SparseCategoricalCrossentropy(),optimizer=tf.optimizers.Adam())dataset = get_dataset(batch_size = 1024)steps_per_epoch=100, epochs=10))
整体实际上是采用了类似于Spark中RDD这样的处理思想:对数据集进行变换。
通过map函数中传入各种处理算子(实际上对于Tensorflow底层的节点来说,就是一个C++函数调用链),我们构建了一个计算图。计算图上的每个节点定义了对数据集的处理操作,每个节点输入是一个Dataset,变换后输出仍然是一个Dataset。所以Dataset是tensorflow中处理的基础核心概念。我们查看MapDatasetOp的源码会发现,Map的核心输入是一个Dataset,输出是一个Dataset,操作是一个Opcontext。
class MapDatasetOp : public UnaryDatasetOpKernel {public:static constexpr const char* const kDatasetType = "Map";static constexpr const char* const kInputDataset = "input_dataset";static constexpr const char* const kOtherArguments = "other_arguments";static constexpr const char* const kFunc = "f";static constexpr const char* const kTarguments = "Targuments";static constexpr const char* const kOutputTypes = "output_types";static constexpr const char* const kOutputShapes = "output_shapes";static constexpr const char* const kUseInterOpParallelism ="use_inter_op_parallelism";static constexpr const char* const kPreserveCardinality ="preserve_cardinality";explicit MapDatasetOp(OpKernelConstruction* ctx);protected:void MakeDataset(OpKernelContext* ctx, DatasetBase* input,DatasetBase** output) override;private:class Dataset;std::shared_ptr<FunctionMetadata> func_metadata_ = nullptr;DataTypeVector output_types_;std::vector<PartialTensorShape> output_shapes_;bool preserve_cardinality_;};
以MindSpore为例子,其数据处理pipeline如下图所示(图片来源于此:https://zhuanlan.zhihu.com/p/352487023)。这样抽象的好处在于各个Map算子处理的计算资源解耦。对于处理速度慢的算子我们可以分配更多的计算资源,对于处理速度快的算子我们可以分配更少的计算资源。因为在我们的Dolphin中很明显的发现,不同的算子耗时差异非常大。更合理的讲我们就需要对不同的算子给不同的计算资源,来加速整个预处理。
从训练的可复现性上讲,Tensorflow和MindSpore采用了各自的保序处理。整个数据训练的数据保序是通过递归算子保序来保证的,即对于一个Map算子来说,保序性意味着输出的数据和输入的数据的顺序要一致,如果所有的Map算子都能保证这一点,那么整体来讲模型获得的数据顺序就是保序的。
MindSpore中使用统一抽象的Connector来处理,Tensorflow中则在各个Map算子中用锁和异步等待来完成保序处理。
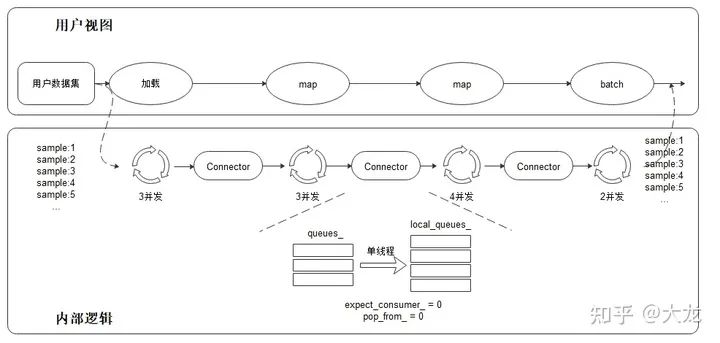
MindSpore中Connector的核心目的就是保证输出的顺序和输入的顺序保持一致。其源码中的Push和Pop的实现代码如下所示:
virtual Status Pop(int32_t worker_id, // The worker-id of the caller. See the requirement at the top of this file.T *result) noexcept {{MS_ASSERT(worker_id < num_consumers_);std::unique_lock<std::mutex> lk(m_);RETURN_IF_NOT_OK(cv_.Wait(&lk, [this, worker_id]() { return expect_consumer_ == worker_id; }));RETURN_IF_NOT_OK(queues_[pop_from_]->PopFront(result));pop_from_ = (pop_from_ + 1) % num_producers_;out_buffers_count_++;expect_consumer_ = (expect_consumer_ + 1) % num_consumers_;}cv_.NotifyAll();return Status::OK();}// Add an element into the DbConnector without the overhead of synchronization.// It may block when the internal queue is full.// The element passed to this function will be copied into the internal queue.// @param worker_id The id of a worker thread calling this method.// @param el A const lvalue element to be passed/added/pushed.Status Push(int32_t worker_id, const T &el) noexcept {MS_ASSERT(worker_id < static_cast<int32_t>(queues_.size()));MS_ASSERT(queues_[worker_id] != nullptr);return (queues_[worker_id]->Add(el));}
天下没有免费的午餐,上述的pipeline我认为基本上从效率上来讲,是local能够实现的最优pipeline,但是缺点在于不易做灵活的定制。这点MindSpore做的更好一些,Tensorflow底层pipeline实现由C++函数调用链完成,那么就意味着对于自定义的Python处理不能很好的兼容,上层的Python算子为了能够被底层C++调用,需要满足相应的限制才可以。
Tensorflow中的分布式数据处理Pipeline
Tensorflow好不好用单说,从工程的角度而言,Tensorflow的每个单独功能的设计还是做得相当不错。这篇文章重点介绍其中一个就是Tensorflow在2.3版本中推出的分布式数据加载Dataservice的功能, 这个功能牛就牛在对用户来说可以完全无感的切换处理。这个功能的具体内容可在我的这篇文章中进行查看。限于篇幅,本文主要直接对图进行说明。
大龙:分布式数据预处理——TensorFlow DataService架构设计总结
https://zhuanlan.zhihu.com/p/351810621
如下是一段使用Dataservice的简短示例代码:
dispatcher = tf.data.experimental.service.DispatchServer()dispatcher_address = dispatcher.target.split("://")[1]worker = tf.data.experimental.service.WorkerServer(tf.data.experimental.service.WorkerConfig(dispatcher_address=dispatcher_address))dataset = tf.data.Dataset.range(10)dataset = dataset.apply(tf.data.experimental.service.distribute(processing_mode="parallel_epochs", service=dispatcher.target))print(list(dataset.as_numpy_iterator()))
TFDataservice的设计实际上是一个简易版的MapReduce。但其任务分配、执行机制和与客户端的交互逻辑上则简单了很多。
我们用几张图介绍TFDataservice中的机制和概念。首先是任务的概念。
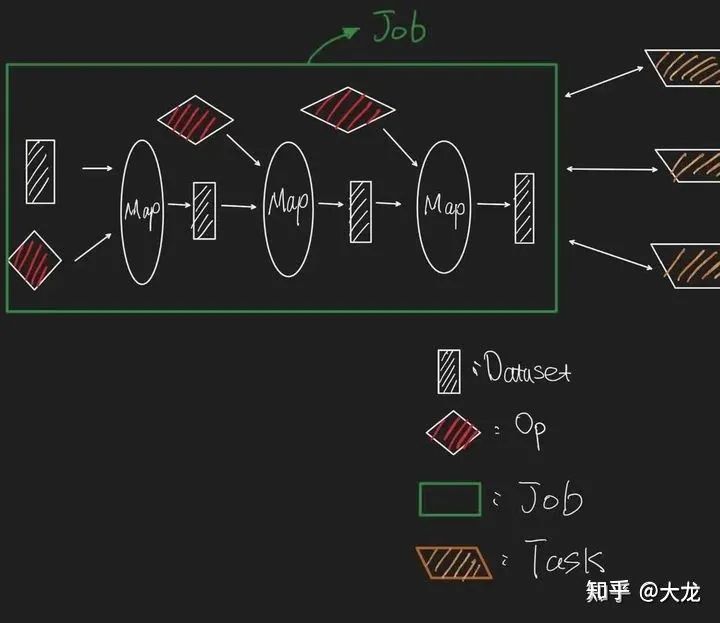
TFDataservice中有Dataset, Task, Job三层核心概念。对于数据集处理算子来说,Dataset是数据处理的基本单位,所以数据集的概念是最好理解的,就是多个Tensor的集合。针对该数据集的一个处理变换pipeline的定义我们称之为一个Job。对于Job的每一个执行实体我们称之为一个Task。
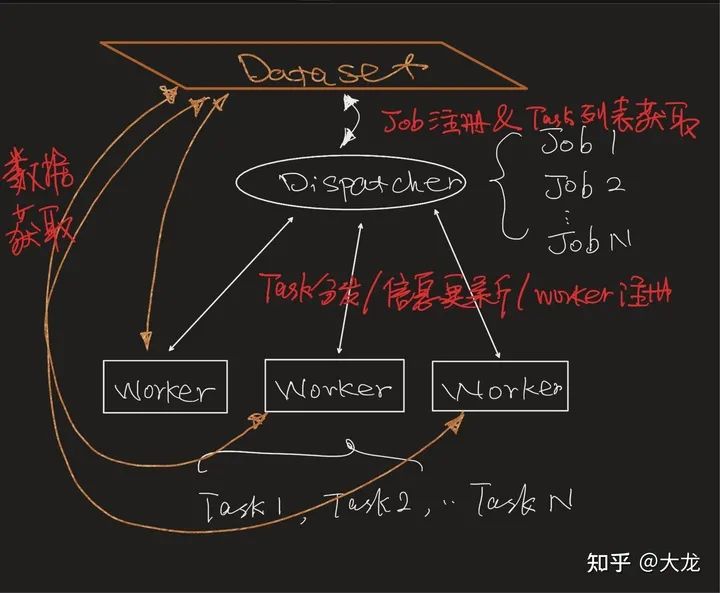
而在任务分配与执行中,TFDataservice也有三层概念Dispatcher,Worker, TaskRunner,其与上述的任务概念的交互关系如下图所示。具体我们接下来一一解释。
任务执行这部分和MapReduce的执行很像,所以我们回顾一下MR中的任务执行。
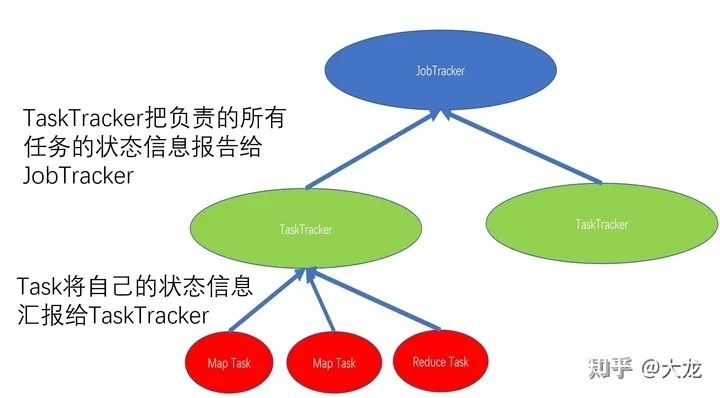
在MR中有JobTracker负责Job和Task的新建、执行以及状态维护。客户端同过JobTracker新建一个Job,新建Job的同时JobTracker会根据用户的定义进行Task的拆分以及新建,在MR中其实就是MapTask以及ReduceTask的新建。每个TaskTracker会通过Heartbeat和JobTracker进行任务的领取以及当前正在执行的Task的状态的更新。TaskTracker领取到一个任务之后,会启用或者复用一个JVM来执行,每个Task的执行最终由TaskRunner来完成。
Dataservice中采用几乎一一对应的概念,其中Dispatcher对应JobTracker,Worker对应TaskTracker,TaskRunner对应TaskRunner。只不过在TF中,worker接收到一个Task之后不需要重新起一个JVM来执行代码,而是直接进行函数调用即可。整体而言TFDataservice中的分布式数据处理的架构如下图所示。这个图看起来有点乱,但是基本上就描述清了TFDataservice中的设计。Dispatcher和Worker都是两个RPC Server。Dataset和Dispatcher,Dispatcher和Worker以及Dataset和Worker之间都是采用RPC调用进行通信。
四、一些未来需要解决的数据pipleline的问题:
1. 资源的自适应分配
预处理pipeline执行的进程数和当前各数据增强算子使用的处理线程数目由用户手工配置,对用户的调优经验要求极高。通过自适应判断Pipeline瓶颈,由框架给各个数据增强算子合理分配CPU资源,可以在训练过程中动态优化数据处理性能,免去用户繁琐的调优过程。
2. 异构硬件加速
当前的数据处理Pipeline操作在CPU执行,一旦出现瓶颈,带来AI芯片/GPU等待空闲,用户无法充分利用所有硬件的计算能力。期望构建用户无感知的异构硬件资源调度能力:通过监测硬件资源使用,完善TPU/GPU上的数据处理算子,采用代价模型自适应地将数据处理任务调度至合适的资源,实现异构硬件的充分利用。我们在音频混响操作(核心为FFT和IFFT操作)中发现GPU的使用能极大的加速数据预处理,然而过多的进程申请GPU缓存池对训练本身会造成一定的影响,这个问题我们下个双月会着重研究GPU显存的精细化管理。
3. 用户无感知的分布式数据加载
当前大部分框架使用本地多进程、多线程进行数据预处理。但是随着GPU的性能的逐年提升、AIOT端测模型的进一步减小,CPU Bound和IO Bound会越发的明显,本地的数据处理已经难以满足模型的需求。使用分布式的预处理是解决数据处理和读取瓶颈的出路。如何做到本地、分布式预处理用户无感知切换是未来非常有前景的方向。Tensorflow中的TFDataservice给众多框架开了一个头,估计后续MindSpore等框架会持续跟上。
推荐阅读
2020-10-17
2020-02-13
2020-11-14

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
