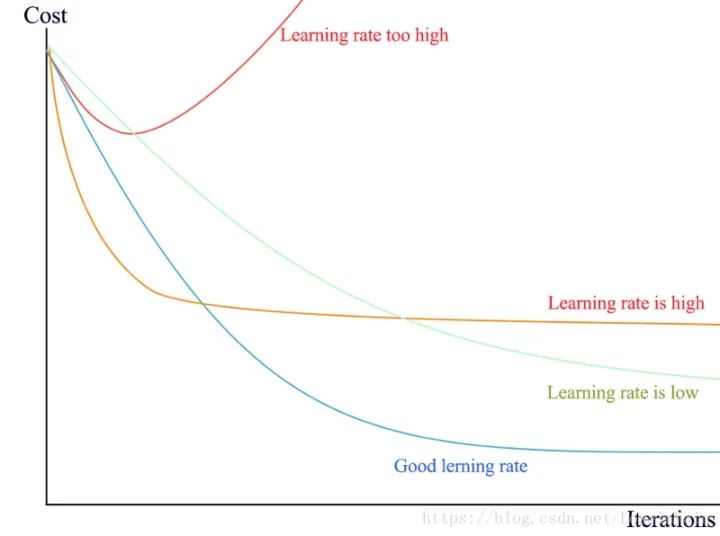
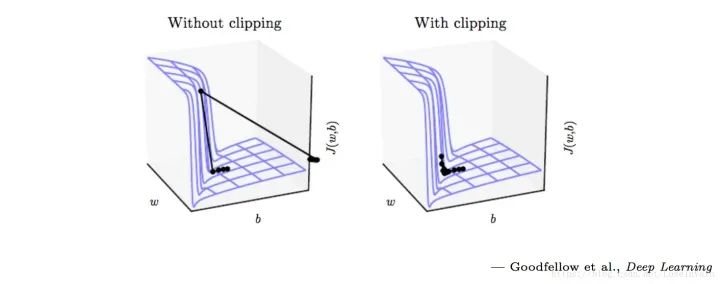
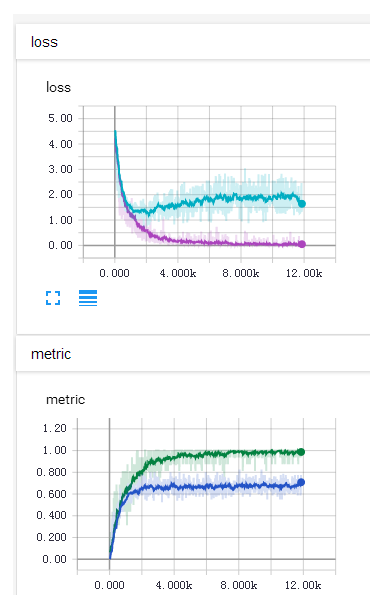
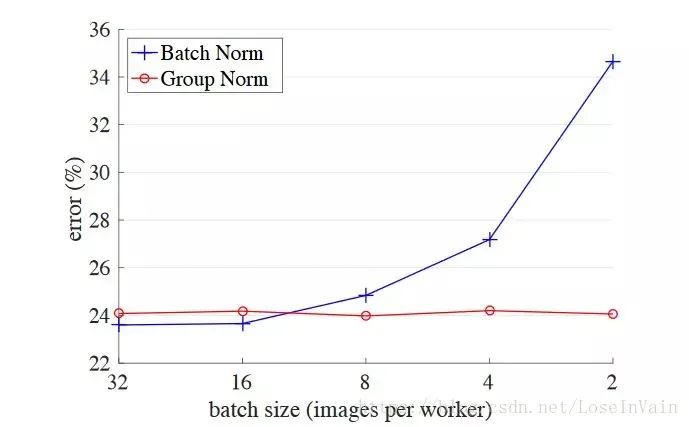
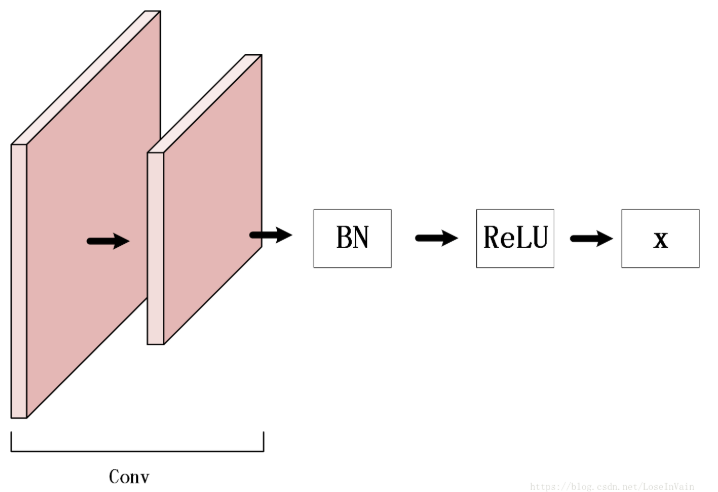
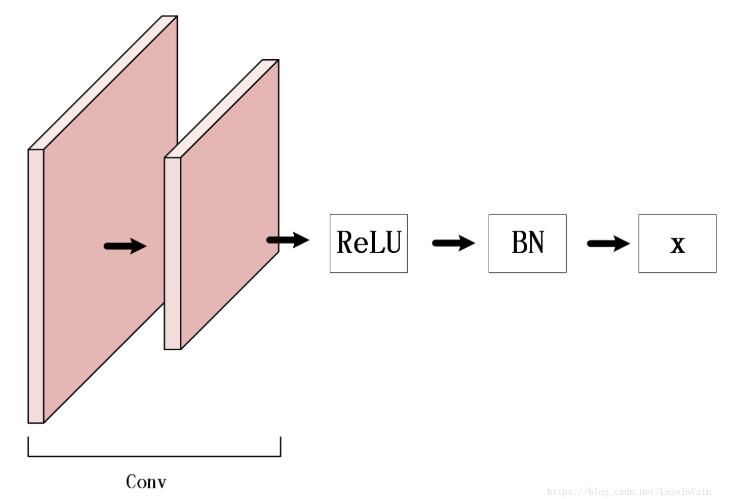
Nan(Not An Number)是一个在数值计算中容易出现的问题,在深度学习中因为涉及到很多损失函数,有些损失函数的定义域并不是整个实数,比如常用的对数,因此一不小心就会出现Nan。在深度学习中,如果某一层出现了Nan,那么是具有传递性的,后面的层也会出现Nan,因此可以通过二分法对此进行排错。一般来说,在深度学习中出现Nan是由于除0异常或者是因为损失函数中的(比如交叉熵,KL散度)对数操作中,输入小于或者等于0了,一般等于0的情况比较多,因此通常会:这里的是个很小的值,一般取即可,可以防止因为对数操作中输入0导致的Nan异常。需要注意的是,有些时候因为参数初始化或者学习率太大也会导致数值计算溢出,这也是会出现Nan的,一般这样会出现在较前面的层里面。
Kullback–Leibler散度,简称KL散度[24],也称为相对熵,是一种用于度量两个分布之间相似性的常用手段,公式如(20.1),其中第二行形式的变形描述了相对熵的特性。我们注意到KL散度是不可能为负数的,其中是定义在同一个概率空间[25]里面的同型的分布,维度相同。从相对熵的定义来看,这个公式描述了用分布去近似所造成的不一致性的程度。在深度学习和机器学习中,一般是用来描述两个维度相同的概率分布之间的相似度。注意到,这里的都是概率分布,因此是需要经过softmax层的,才能保证概率和为1,不然可能会出现KL散度为负数的笑话。而且,在一些框架如Pytorch中,其输入值需要是log_softmax而目标值需要是softmax值,也就说输入值需要进行对数操作后再转变为概率分布[27]。参考资料[1] Janocha K, Czarnecki W M. On loss functions for deep neural networks in classification[J]. arXiv preprint arXiv:1702.05659, 2017.(Overview about loss function used in DNN)[2] tf.one_hot()进行独热编码[3] 曲线拟合问题与L2正则[4] Kinga D, Adam J B. A method for stochastic optimization[C]//International Conference on Learning Representations (ICLR). 2015, 5.[5] 深度学习系列:深度学习中激活函数的选择[6] 机器学习之特征归一化(normalization)[7] 机器学习模型的容量,过拟合与欠拟合[8] 在机器学习中epoch, iteration, batch_size的区别[9] Pytorch Dataloader doc[10] tf.clip_by_value[11] 梯度截断的tensorflow实现[12] 均方误差(MSE)和均方根误差(RMSE)和平均绝对误差(MAE)[13]. Du S S, Zhai X, Poczos B, et al. Gradient Descent Provably Optimizes Over-parameterized Neural Networks[J]. arXiv preprint arXiv:1810.02054, 2018.[14] The inconsistency between the loss curve and metric curve?[15] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]// International Conference on International Conference on Machine Learning. JMLR.org, 2015:448-456.[16] Wu Y, He K. Group normalization[J]. arXiv preprint arXiv:1803.08494, 2018.[17] Park S, Kwak N. Analysis on the dropout effect in convolutional neural networks[C]//Asian Conference on Computer Vision. Springer, Cham, 2016: 189-204.[18] Where should I place dropout layers in a neural network?[19] Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. arXiv preprint arXiv:1207.0580, 2012.[20] Why do I never see dropout applied in convolutional layers?[21] L1正则[22] 深度学习系列:反向传播算法的公式推导[23] 训练集、测试集、检验集的区别与交叉检验[24] Kullback–Leibler divergence[25] Probability space[26] 如何理解K-L散度(相对熵)[27] KL Divergence produces negative values[28] Chen G, Chen P, Shi Y, et al. Rethinking the Usage of Batch Normalization and Dropout in the Training of Deep Neural Networks[J]. arXiv preprint arXiv:1905.05928, 2019.[29] https://forums.fast.ai/t/rethinking-batchnorm-dropout-combine-together-for-independent-component-layer/46232如有问题请指出,联系方式:E-mail: FesianXu@gmail.comQQ: 973926198github: https://github.com/FesianXu