
计算机视觉中的corner-case及其优化策略
问题定义
Corner cases(CC)是指不经常出现或一些极端的场景数据,也是一种长尾问题的表现形式。然而,对于感知模型来说,CC非常重要,因为在自动驾驶系统的推理过程中,它需要训练、验证和提高感知模型的泛化性能。例如,一辆配备了最先进的目标检测器的车辆在高速公路上疾驰,可能无法及时发现失控的轮胎或翻倒的卡车(如下图)。这些自动驾驶目标检测失败的案例可能会导致严重的后果,危及生命。

认定是否为corner-case,也可以使用下面的约束:
危险性:当目标挡住或即将挡住自动驾驶汽车的潜在行进路径,这些目标非常容易被车撞到。不在道路上的静态物体,例如树木和建筑物,不被认为会阻挡车辆。
新奇性:该目标不属于任何自动驾驶基准数据集的类别,或者它是其中类别的新的实例。这样的目标很容易漏检。
当同时满足这两个条件,可以认为是一个corner-case。
corner case(CC)也可以分为不同级别,见下图。
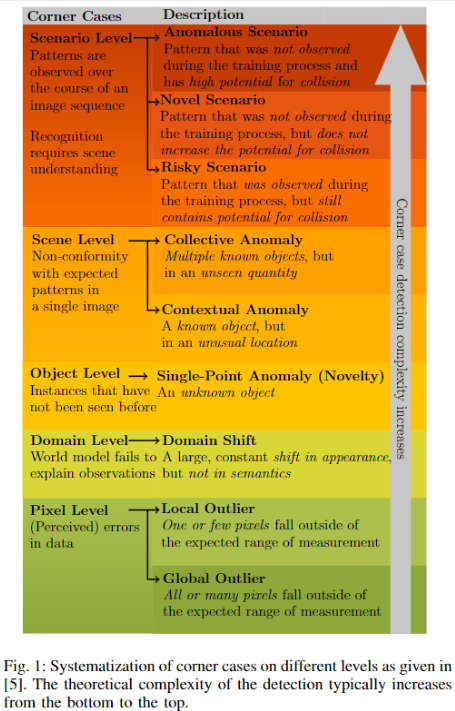
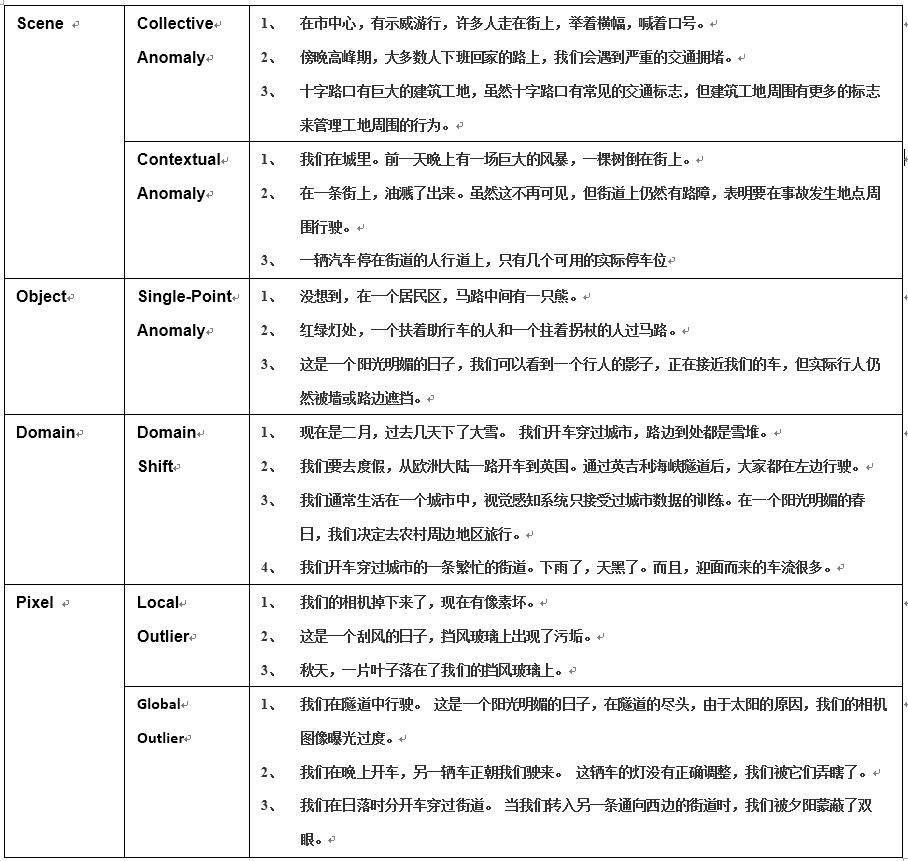
每个级别的形象的例子见下表。

优化方法
corner-case分级及优化对策
自动驾驶中的corner-case根据检测复杂度做了分级,然后针对每个级别去寻找解决方案。主要分为5级:像素级(Pixel)、域级(Domain)、目标级(Object)、场景级(Scene)、时序场景级(Scenario)。
针对每个级别,应用不同的检测方法来进行检测,具体方法如下:
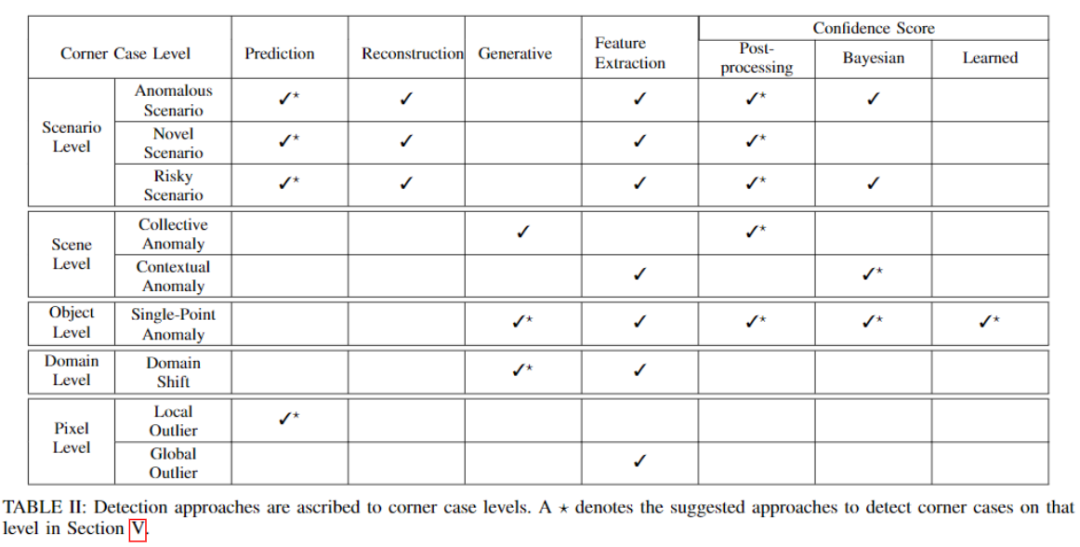
Pixel级别
在像素级别,只有很少的深度学习方法存在。但是为了检测这种corner-case,对于全局异常值,特征提取方法提供了较好结果[41],因为我们的目标是检测影响大部分甚至整个图像的corner-case。在这种情况下,检测可以被认为是一个二元分类问题,并且网络能够为该任务提取足够的特征。可以使用监督训练方法,因为像素级别的corner-case没有意外的多样性。然而,由于缺乏带有标签的全局异常值(例如过度曝光)的自动驾驶数据集,研究利用少样本学习或类似技术方法是有益的。此外,我们对检测多个全局异常值感兴趣,例如同时检测图像中的过度曝光和曝光不足。在进出隧道时,过度和不足的曝光情况甚至可以出现在同一图像中。这可以通过考虑联合或多任务学习来进行研究。
局部异常值仅影响图像的一小部分,例如坏点。这些corner-case的检测可以进行监督学习,因为可以在训练数据中模拟这些坏点。由于可以模拟,检测可以当成包含一个其它类的语义分割方法来处理。也就是会有像素级标签,它将告知坏点像素的位置。我们相信局部异常值的检测将受益于预测(未来帧)方法,因此包括时间跨度。例如,坏点的预测位置可以与实际位置进行比较。理想情况下,实际位置与基于学习光流的预测位置相反。
Domain级别
为了检测域级别的corner-case,我们不需要使用域适应方法,而是找到合适的域不匹配度量。然而,这些措施通常源于域适应方法,它们被用作损失函数。通常,这些措施被认为是特征提取方法。训练可能需要来自源域的正常样本的监督,但应明确排除来自另一个域的训练数据。在训练中使用第二个域的特定样本的方法有可能无法在第三个域中达到相同的性能。这些方法通常通过将一个数据集视为同分布而将另一个数据集视为分布外(out of distribution)来进行评估。分布外检测器通常通过区分它们训练过的数据集和另一个数据集来评估。这些方法可以从分类设置扩展到自动驾驶视觉感知设置,因为它们只需要通过正常样本监督的训练。为了可靠地检测域级别的corner-case,我们需要对域不匹配进行可靠的测量。为此,我们依赖于使用不止一个目标域进行评估。
Object级别
在目标级别,主要目标是检测未知目标。这些是属于以前在训练中未见过的新类的实例。在训练期间提供此类corner-case的样本将导致网络推理仅检测与这些样本相似的corner-case,这对我们的目标来说是缺少泛化的。目标级corner-case的检测属于开放集识别的广泛领域,相关方法通常提供某种类型的置信度分数。理想情况下,对于检测和定位,我们要求每个像素的得分。也有符合这一思想的重建和生成方法。然而,基于重建的方法结果不太有意义[18]。我们希望为输入图像获得语义分割掩码,其中未知目标的像素与未知类标签或大量不确定性预测相关联。考虑到这一目标,追求置信度得分和生成检测方法似乎是最有效果的,并且最近的许多方法都符合这一目标[24]、[18]、[28]。使用贝叶斯置信度分数,求解一个与那些未知目标相关的具有高不确定性的模型。在这里,应用 Monte-Carlo dropout[32]或deepsembles[33]的贝叶斯深度学习的可扩展方法为检测提供了第一步。就训练期间未见实例的那些单点异常的定义而言,我们推测有效和可靠的检测方法不能依赖于包括corner-case在内的训练样本。人们不得不求助于只能使用正态样本进行训练的无监督方法。
Scene级别
我们的目标是检测未知数量或位置的已知类别。Chalapathy 等人[19]采用生成方法来检测集体异常,取得了较好结果。此外,我们认为未来的工作应该利用实例分割来计算每个类的实例数获得组大小。在这种情况下,需要一个阈值来将集合定义为异常。可以通过使用特征提取方法来检测上下文异常[38]。然而,在自动驾驶视觉感知情况下,特征提取可能无法捕捉到整个场景的复杂性。因此,许多现有方法给出置信度分数[35]、[33]或重建错误[13] 并区分正常和异常样本。我们建议调查加入类别先验如何影响该过程,因为这些先验可能有助于检测错位的类别。同样,贝叶斯深度学习产生的置信度分数表明模型在哪里不确定,因此它们对于定位出现在不寻常上下文中的目标很有用。场景级别的两种corner-case类型都可以使用正常数据进行监督训练,因为它们都检测已知类的实例,只是在不寻常的位置或数量上。然而,与目标级别的corner-case相比,除了我们可能需要像素级语义分割标签,我们还要求提供实例标签,告诉我们一个目标出现在一个不寻常的位置,或者如果看不到目标,就提供图像标签。
Scenario级别
Scenario级别的corner-case由在特定时间跨度内出现的模式组成,并且在单个帧中可能看起来并不异常。基于预测的方法,其决策取决于预测帧与实际帧之间的比较,得到了较好结果[9]。纯粹的重建方法再次获得不可靠的corner-case检测分数。预测方法可以在有监督下训练,因为它们只需要正常的训练样本即可在推理过程中检测corner-case。这对于新奇Scenario和异常Scenario尤其重要,因为在这些场景中,由于情况的数量大和危险性高,我们无法捕捉每一种可能。此外,包含这些样本实际上可能会妨碍网络。
未来,我们需要定义足够的度量来检测这种类型的corner-case。虽然我们可能仍然想知道corner-case在图像中的位置,但我们还需要这种corner-case发生的时间点。为了实现这一点,我们可以考虑在一定的时间跨度上的图像标签。除了对指标的调查,我们建议使用代价函数来优先检测出现在视野边缘的易受伤害的路人。例如,这可以改进对从遮挡后面跑到街道上的人的检测,因为当帧中出现几个人体像素时,该人已经可以检测到。这种方法还需要逐帧掩码来识别由于被遮挡或超出视野而未包含在前一个掩码中的像素。
CODA数据集
CODA数据集是华为提出的一个数据集,主要是从3个目标检测基准数据集(包括KITTI、nuScenes、ONCE)中提取建立。从这些数据集中选取了约1500个场景图片,包含大约6000个目标级别的corner case。下图示例了部分样本。

数据集链接:https://coda-dataset.github.io/
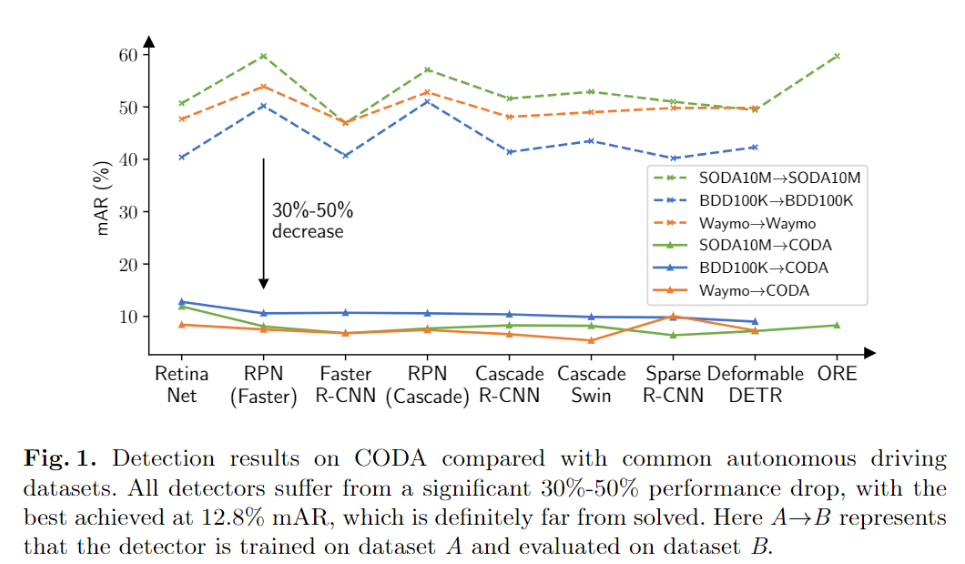
建立这个数据集的目的是测试现有自动驾驶目标检测模型在极端场景下的效果,为优化提供参考。经过实验,现有常用的一些检测模型在CODA上效果较差(见下图)。
CODA作者的主要贡献:
建立了面向自动驾驶的corner-case数据集CODA;
评测了常用的检测模型,并发现其问题;
提出了一种corner-case样本挖掘方法COPG,可以减少90%的人工标注。
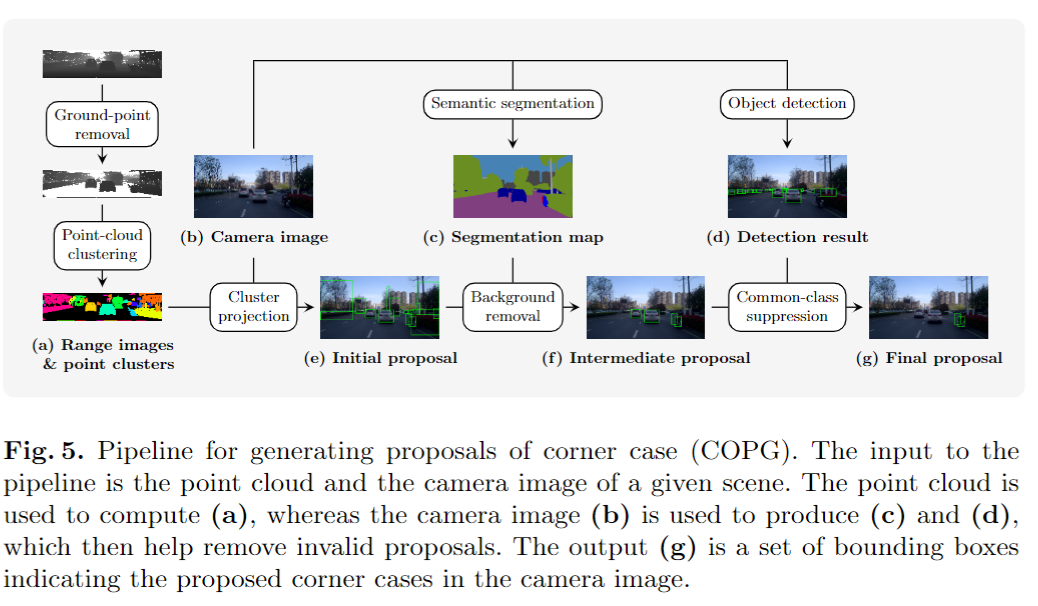
只需要相机和LiDAR的原始数据,即2D图像和3D点云,就可以识别任何给定数据集中的潜在corner-case。
COPG的流程如下图:
COPG方法的有效性验证,证明COPG方法是可以有效解决部分corner-case问题的。如下:

讨论
通过对自动驾驶领域的corner-case进行分级,可以通过不同办法来优化它们。在解决的过程中对corner-case数据集的需求非常紧迫,CODA的出现非常及时。corner-case问题纯靠感知是无法完成解决的,需要结合车联网、车路协同技术,同步对一些没有见过的,少见的问题通过多方面协同进行优化。
参考文献
[1]Breitenstein J, Termöhlen J A, Lipinski D, et al. Corner cases for visual perception in automated driving: Some guidance on detection approaches[J]. arXiv preprint arXiv:2102.05897, 2021.
[2]Li K, Chen K, Wang H, et al. CODA: A Real-World Road Corner Case Dataset for Object Detection in Autonomous Driving[J]. arXiv preprint arXiv:2203.07724, 2022.
[3]Bogdoll D, Breitenstein J, Heidecker F, et al. Description of corner cases in automated driving: Goals and challenges[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 1023-1028.