
G-GhostNet | 适配GPU,华为诺亚提出G-Ghost方案升级GhostNet
CV干货,第一时间送达
GhostNet是华为诺亚在轻量化网络架构设计方面的力作,首次见刊于CVPR2020,也是CVPR2020最具影响力论文之一。GhostNet无论在工业界还是在学术界影响力均不小,最近两年也有不少基于GhostNet思想而进行的“魔改”,比如前段时间火热的PP-PicoDet的骨干架构就有GhostNet的身影。
近期该团队对其进行了扩展,提出了适用于服务器的G版GhostNet,即G-GhostNet。作者将早期GhostNet称之为C-GhostNet,即适用于CPU/移动端的GhostNet。关于C-GhostNet可以参考如下两个链接:
知乎@王云鹤:CVPR2020|华为GhostNet,超越谷歌MobileNet 极市平台@余霆嵩:轻量网络GhostNet:不用训练、即插即用的CNN升级组件究竟如何实现?
本文仅针对G版GhostNet进行介绍,感兴趣的同学建议查看原文以全面理解作者关于GhostNet设计的背后思想。

CVPR2020: https://arxiv.org/abs/1911.11907
1背景&出发点
尽管C-GhostNet能大幅减少FLOPs同时保持高性能,但它所用到的cheap操作对于GPU既不cheap也不够高效。具体来说,depthwise卷积具有低计算密度(ratio of computation to memory operations),无法充分利用GPU的并行计算能力。如何在精度和GPU延迟之间获得更好的平衡,仍然是一个被忽视的问题。
除了FLOPs与参数量外,《Designing Networks Desing Space》一文引入"Activations"衡量网络复杂度,相比FLOPs,它与GPU延迟具有更高的相关性。也就是说,如果我们可以移除部分特征减少"Activations",我们就能够很大概率降低GPU延迟。
另一方面,CNN的主体部分通常包含多个分辨率渐进式缩小的阶段,每个阶段由多个Blocks堆叠而成。本文旨在降低"stage-wise"冗余而非C版的"block-wise",极大的减少中间特征进而降低计算量与内存占用。
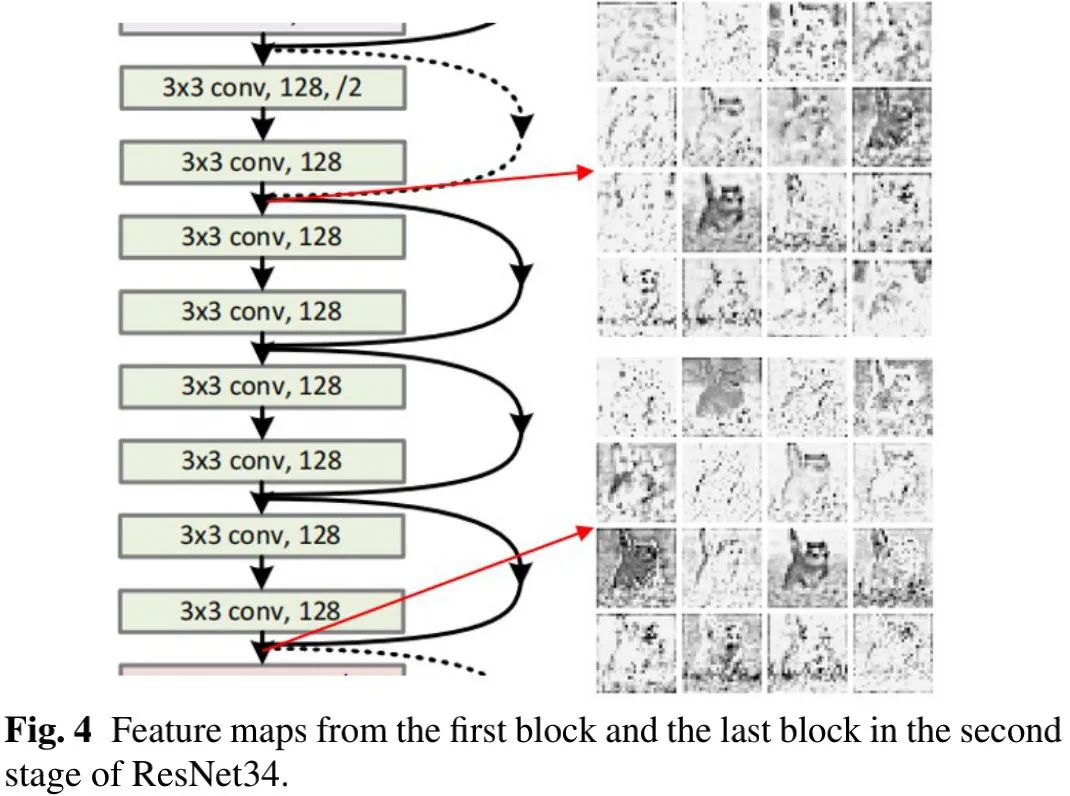
上图给出了ResNet34第二阶段不同block的特征可视化对比,可以看到:尽管最后一个模块的特征采用了更多操作,但部分特征与第一模块处理的特征非常相似,这意味着:这些特征可以通过对底层特征进行简单线性变换得到。此即为G-GhostNet的出发点。
我们可以将特征分为"complicated"与"ghost"两种,前者需要采用大量block处理得到,而后者仅需对浅层特征执行线性变换得到。我们首先定义一个包含n个block的阶段,其输出表示,我们将其中的"complicated"特征表示为,"ghost"特征表示为(),分别通过如下方式生成:
注:这里的C表示Cheap操作,它可以是或者卷积。通过对上述两种特征进行组合即可得到当前阶段输出特征:
2Intrinsic Feature Aggregation
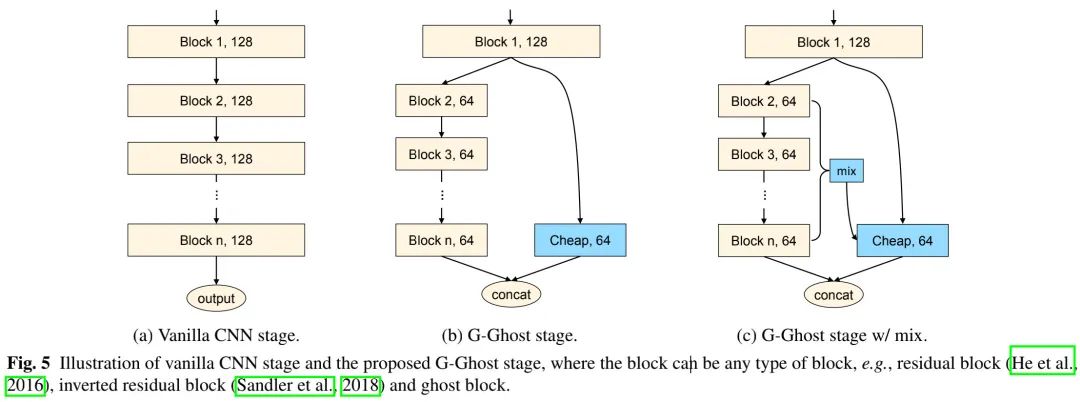
上述给出了G-Ghost阶段的构建方式,它通过cheap操作生成特征以探索第一个模块与最后一个模块之间的冗余。通过这种方式,G-Ghost阶段可以大幅降低计算复杂度(见上图a与b)。尽管简单特征可以通过cheap操作生成,然而可能缺乏需要多层才能提取的深度信息。
为补偿信息缺失,我们提出采用"complicated"分支的中间特征增强cheap操作的表达能力。从"complicated"分支,我们将可收集到的特征表示为,这些中间特征可以为cheap操作提供丰富的信息补充。
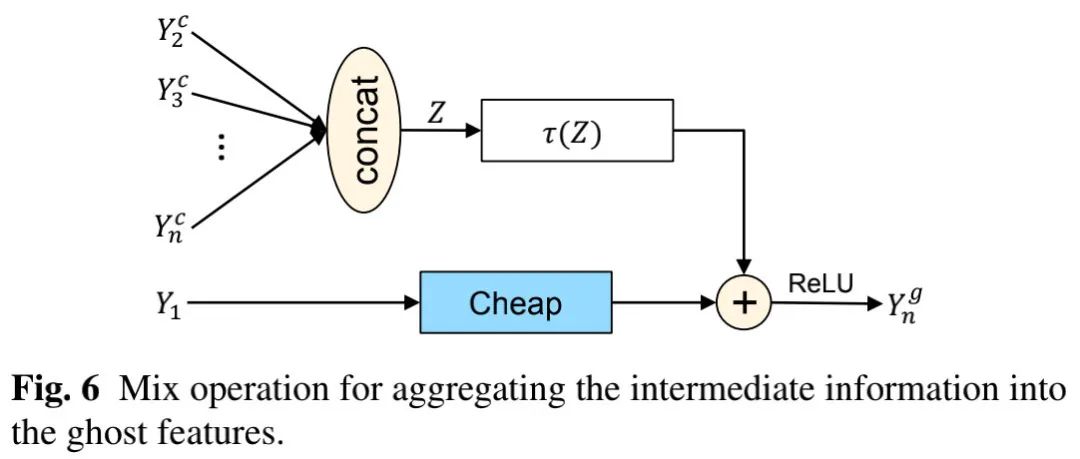
上图给出了G-Ghost中用到的信息聚合示意图,我们首先将Z变换到同域,然后进行信息混合:
注:表示变换函数。为避免引入过度计算,我们尽可能让简单。文中采用的方案:先对Z进行全局均值池化以得到聚合特征,然后采用全连接层将其变换到同域:
3G-GhostNet
我们可以采用上述所提G-Ghost对现有CNN架构进行重构,即将常规的阶段构建替换为G-Ghost阶段构建。通过探索"stage-wise"冗余,G-Ghost阶段取得了更佳的精度-GPU延迟均衡。
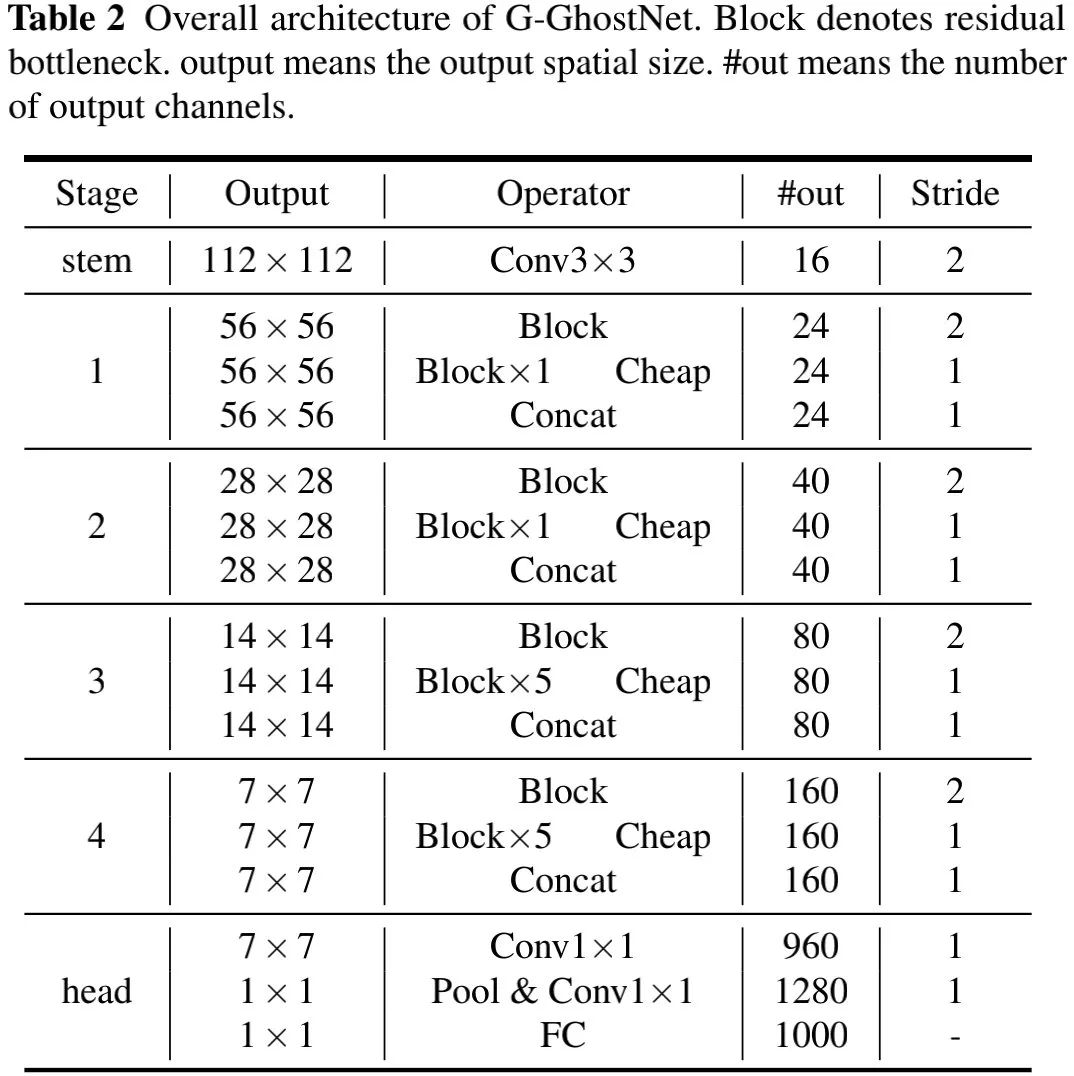
上表给出了本文所构建的G-GhostNet架构配置,它采用卷积作为cheap操作,G-Ghost的超参,bottleneck的扩展比例设为3,同时每个模块中均使用了SE模块,激活函数采用了最简单的ReLU。注:G-GhostNet-表示宽度因子为。
4Experiments
在实验部分,作者进行了非常详尽的分析,为简单起见,这里仅提供了G-GhostNet相关的实验。对其他部分实验感兴趣的同学建议查看原文。
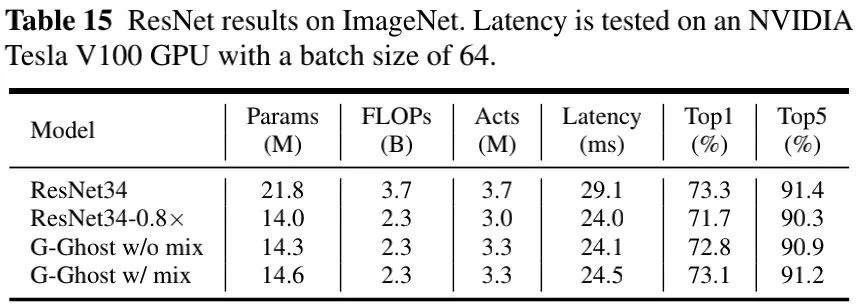
上表给出了以ResNet为蓝本的对比,它采用G-Ghost对ResNet34的阶段架构进行替换,可以看到:
G-Ghost-ResNet34 w/o mix取得了比ResNet34-0.8x更高的性能,同时参数量与GPU延迟相当; 引入mix操作后可以进一步提升模型性能且额外计算量可忽略,G-Ghost w/ mix取得了与ResNet34相当的性能,同时GPU推理延迟降低16%。
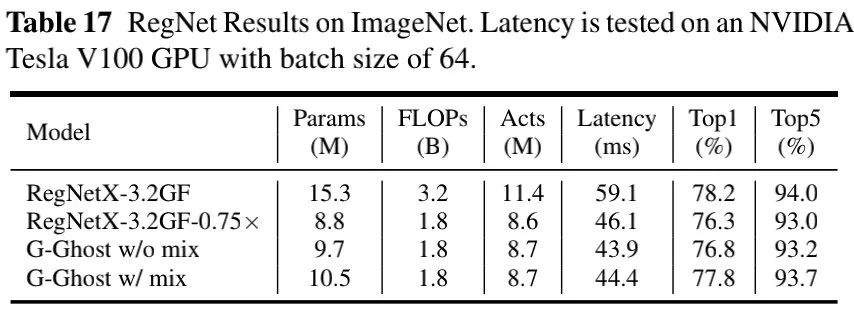
上表给出了RegNet为蓝本的对比,从中可以看到:相比RegNetX-3.2GF-0.75x, G-Ghost-RegNet取得了1.1%的性能提升,同时具有稍快推理速度。
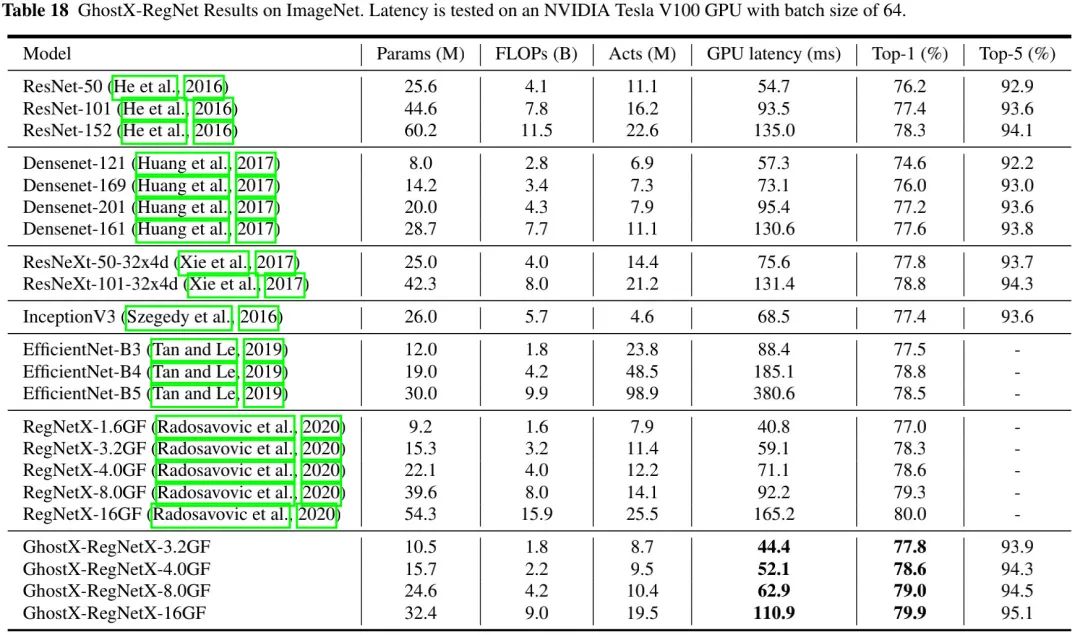
上表对比了G-Ghost-RegNet与其他CNN架构的性能对比,可以看到:所提G-Ghost-RegNet取得了最佳的精度-FLOPs均衡。
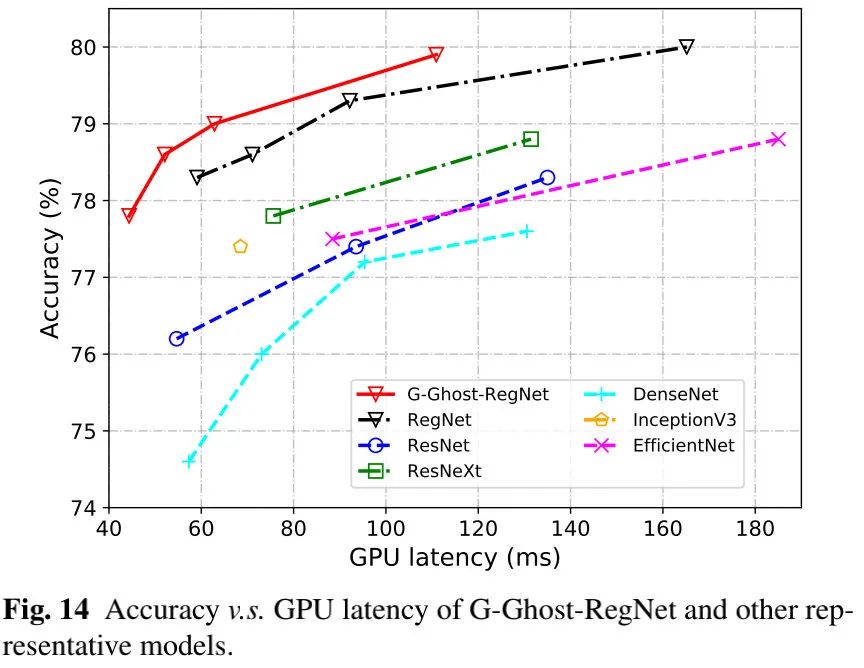
上图给出了不同网络的精度与GPU延迟的对比,可以看到:所提G-Ghost-RegNet取得了最佳的精度-GPU延迟均衡。
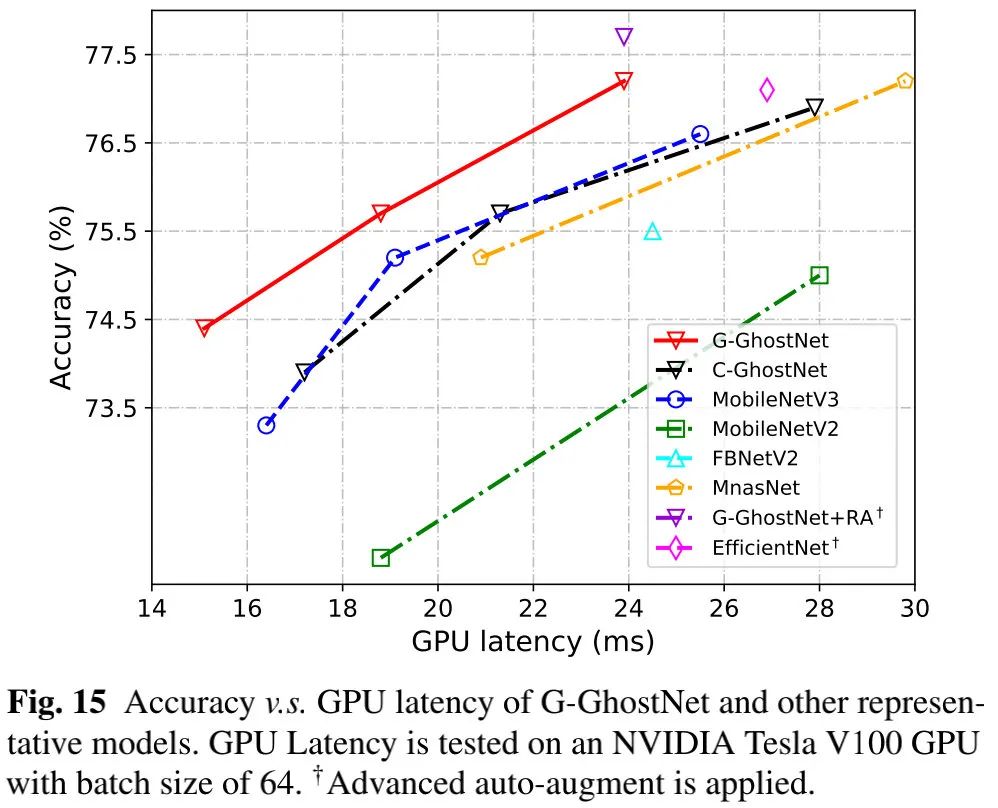
上图给出了本文所设计G-GhostNet与其他轻量型网络的精度-GPU延迟性能对比,可以看到:尽管G-GhostNet具有更高的FLOPs、更高CPU延迟,但****它具有更低的GPU延迟、更高精度。
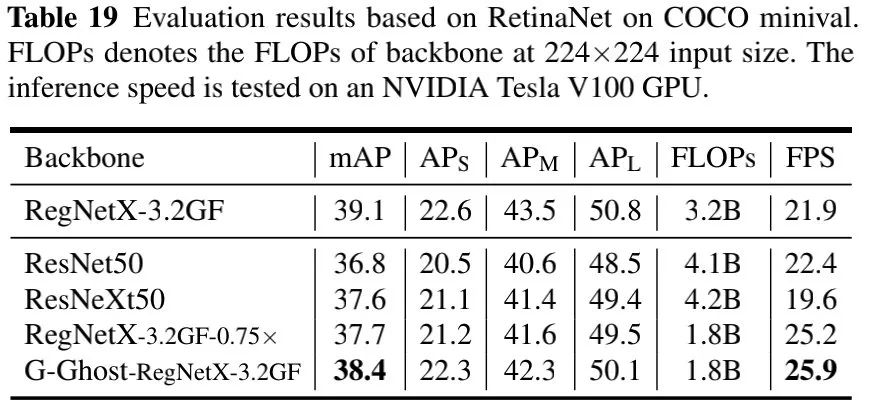
最后,我们再补充一个下游任务上的性能对比,见上表,可以看到:
G-Ghost可以将GPU推理速度从21.9提升到25.9FPS,降低0.7mAP指标; G-Ghost-RegNetX-3.2GF取得了超越ResNet50与RegNetX-3.2GF-0.75x的性能,同时具有更快推理速度,验证了G-Ghost骨干的有效性与泛化性。
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!