
想要一个适配GPU端的轻量级网络?安排!华为诺亚带着 G-GhostNet 走来

极市导读
本文介绍的工作 G-GhostNet 是适配 GPU 端的轻量级 GhostNet,作者在本文中研究跨 Block 特征的冗余性和相似性。借助 G-GhostNet 技术,GhostNet 可以在准确性和 GPU 延迟之间获得更好的权衡。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
NeurIPS'22 Spotlight|华为诺亚GhostNetV2出炉:长距离注意力机制增强廉价操作
本文目录
1 G-GhostNet:打造适配 GPU 端的轻量级 GhostNet
(来自北京华为诺亚方舟实验室)
1.1 G-GhostNet 论文解读
1.1.1 CPU 高效的 GhostNet 回顾和本文动机
1.1.2 G-GhostNet:研究跨 Block 的冗余
1.1.3 中间特征的聚合
1.1.4 G-Ghost Stage 复杂度分析
1.1.5 G-GhostNet 架构
1.1.6 实验结果
1 G-GhostNet:打造适配 GPU 端的轻量级 GhostNet
论文名称:
GhostNets on Heterogeneous Devices via Cheap Operations (IJCV 2022)
论文地址 G-GhostNet:
https://arxiv.org/pdf/2201.03297.pdf
1.1.1 CPU 高效的 GhostNet 回顾和本文动机
GhostNet 是一种轻量级卷积神经网络,是专门为移动设备上的应用而设计的。其主要构件是 Ghost 模块,一种新颖的即插即用模块。Ghost 模块设计的初衷是使用更少的参数来生成更多特征图 (generate more features by using fewer parameters)。 我们知道,深度神经网络的每个卷积层都有一定数量的输出特征图。给定输入特征 分别是特征图的高度, 宽度和通道数), 常规的卷积过程是:

式中, 代表卷积操作。 是卷积, 是输出特征。这个过程的理论计算量 FLOPs 是: , 这个值通常是比较大的, 因为卷积核的数量 和输入通道数 通常是比较大的。
GhostNet 方法认为:如下图1所示是由 ResNet50 生成的输入图像的一些特征映射图,其中存在许多相似的特征图对,它们就像彼此的幻影 (Ghost),同一个特征里面很多通道的特征图是相似且冗余的,彼此相似的特征图使用扳手表示。特征映射的冗余可能是一个性能优异的深度神经网络的重要特征。

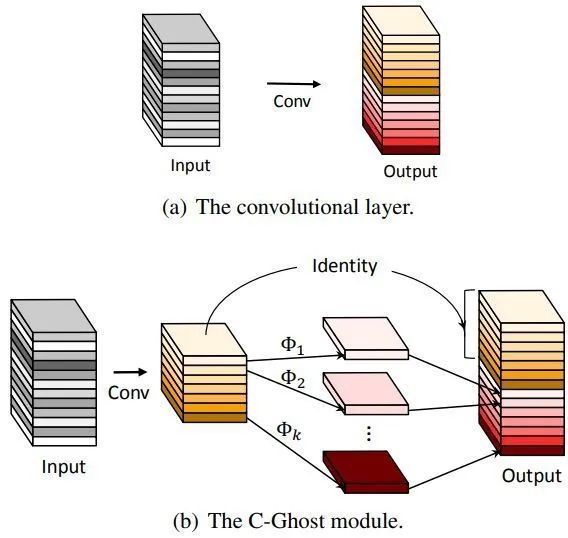
如下图2所示,Ghost 模块将输出通道分成了两个部分 (一般是对半分):
第一部分是常规的卷积,这部分就是正常的实现,没有任何区别。唯一不同的是输出特征图的数量将会严格控制,因为不能让计算量太大:

式中, 代表卷积操作。 是 point-wise 卷积, 是部分输出特征。
这一步卷积的 Kernel size,Stride,Padding 等超参数与普通卷积中的超参数相同,以保持输出特征映射的空间大小一致。
第二部分是廉价操作 (cheap operation),目的是得到另外一些 Ghost 特征图,只是不再采用常规的卷积进行实现,而是通过简单的线性变换 (Linear Transformation) 来生成:
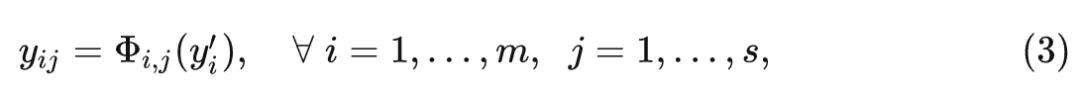
式中, 是第 个中间特征, 是得到第 个 Ghost 特征的廉价操作, 廉价操作 可以进 行局部特征聚合和调整, 生成一些新的特征图。然后把廉价操作得到的所有特征 Concat 在一起: , 得到 个新特征。
最后把2式和3式的结果 Concat 在一起得到最终的输出:
按照这样的两个步骤实现的卷积模块,就称之为 C-Ghost 模块 (C-Ghost module)。与普通卷积模块相比,在同样的输入和输出特征图数量的情况下,Ghost 模块所需要的参数量 (Param) 和计算量 (MACs) 都得到了降低。C-Ghost 模块的理论加速比是:
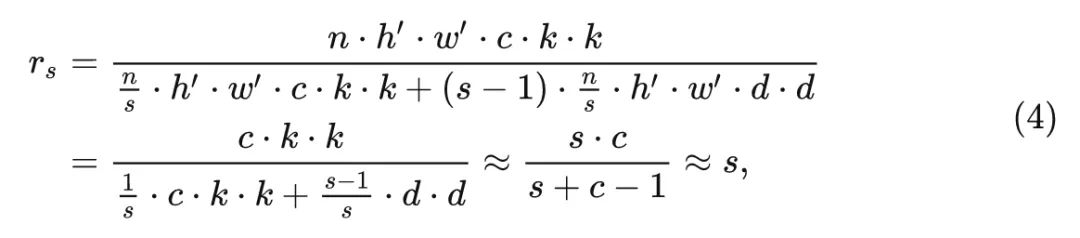
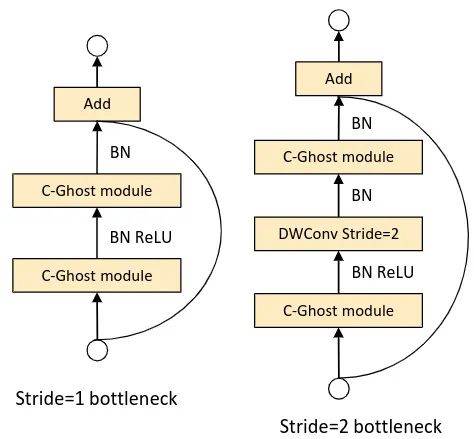
如下图3所示,一个 C-GhostNet Block 通常会堆叠两个 C-Ghost 模块,类似于 MobileNetV2 的[1]Inverted bottleneck 的设计思路,第一个 C-Ghost 模块用来增加输出 channel 数,第一个 C-Ghost 模块再把输出 channel 数减小回原来的值,使之匹配 shortcut path。每个 C-Ghost 模块或者下采样操作之后都有 BN 层。
C-Ghost 模块的局限性
尽管 C-Ghost 模块可以大幅度地减少计算代价,但是 C-GhostNet 使用的 Depthwise 等廉价操作对于流水线型 CPU、ARM 等移动设备更友好,对于并行计算能力强的 GPU 就显得不那么 "廉价" 了。因为 Depthwise 操作的计算密度比较低,不足以充分利用好 GPU 设备的并行计算能力。如何在准确性和 GPU 延迟之间更好地权衡,仍然是一个被忽视的问题。
本文介绍的工作 G-GhostNet 是适配 GPU 端的轻量级 GhostNet,借助 G-GhostNet 技术,GhostNet 就成为了全系列硬件上的极简 AI 网络。本文被 IJCV 2022 接收。
1.1.2 G-GhostNet:研究跨 Block 的冗余
除了 FLOPs 和参数量,激活 (activations) 也可以被用来度量网络的复杂性,即所有卷积层的输出张量的大小 (the size of the output tensors of all conv layers)。与 FLOPs 相比,GPU 上的延迟与激活的关系更大。也就是说,删除部分特征图,减少 activations 可以减少 GPU 上的延迟。
从这个角度来讲,作者开始研究跨 Block 特征的冗余性和相似性。那么首先一个问题是:不同 Block 之间的特征是相似的吗?
下图给出了答案,如下图4所示是 ResNet34 的 Stage2 的第一个和最后一个 Block 的特征,我们可以看到,在同一个 Stage 里面,即使是特征来自于不同的 Block,也是具有很高的相似性。因此,作者希望合理地利用这些相似性,这样就可以大大减少中间特征,从而减少相关的计算成本和内存使用。
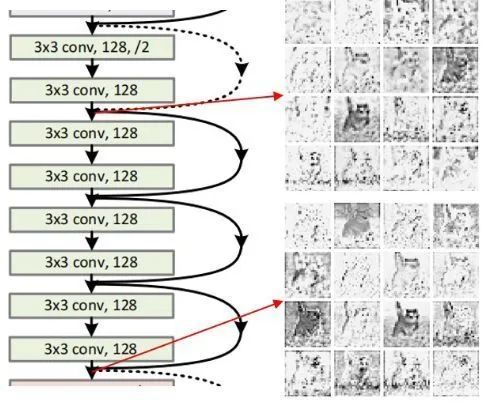
一般而言, 常用的骨干模型一般是由几个 Stage 顺序连接, 这些 处理Stage 的特征的分辨率逐渐 降低。对于 NN中的每个 Stage, 里面有 个 Block, 表示为 。给定输入特征 映射 , 第一个 Block 和最后一个 Block 的输出分别为:
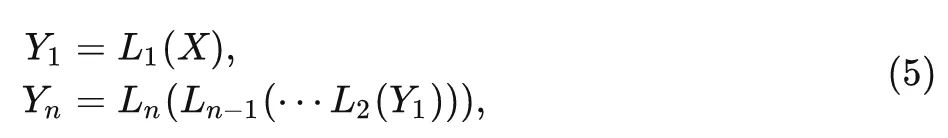
为了充分利用好 Block 之间特征的冗余, 作者认为:要得到最后一个 Block 的输出特征 , 并不 一定需要5式这样的计算方式。如上图4所示, ResNet34 的 Stage2 的第一个和最后一个 Block 的 特征相似。虽然最后1个 Block 的特征要经过另外5个 Block 的处理, 但其中一些特征与第1个 Block 的特征非常相似, 这意味着这些特征可以通过简单的底层特征转换就可以得到。
这里作者将最后一个 Block 的输出特征 分为复杂特征 和廉价特征 。其中, 是廉价特征的比例。复杂特征仍然需要一系列顺序的 Block 来生成:
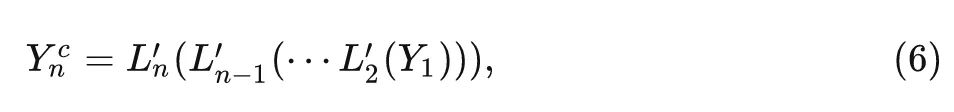
其中, 是5式中的对应层, 只是通道数更少, 只有原来宽度的 倍。
而廉价特征更容易从浅层特征中获得:

廉价操作可以是 卷积, 卷积等等。最后把复杂特征 和廉价特征 Concat 在一起得到最终的这个 Stage 的输出特征::

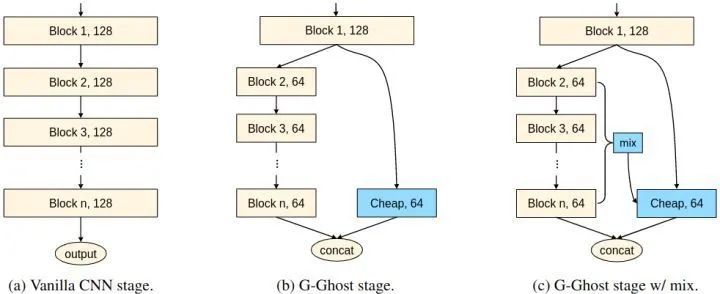
以上这个 Stage 就称为 G-Ghost Stage。
1.1.3 中间特征的聚合
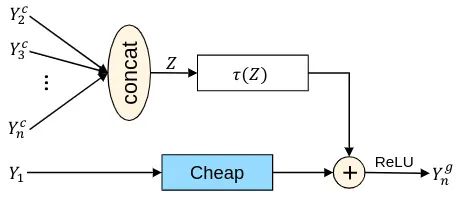
如下图6所示为 G-Ghost Stage 和原来的 CNN Stage 的架构对比。在一个 Stage 里面, 虽然深层的特征可以通过廉价操作近似生成, 但 可能缺乏需要多层提取的深层信息。为了弥补信息的不足, 作者提出利用复杂路径中的中间特征来增强廉价操作的表示能力, 把中间层的特征收集起来得到 , 式中, 是 channel 的总数。这些从多层提取的中间特征的操作, 可以为廉价操作提供丰富的信息补充。作者再把 转化到 相同的域中, 再混合:

式中, 是变换函数, 为了不带来太多额外的计算, 应该尽量使变换 保持简单, 所以这里作者首先应用全局平均 Pooling 来得到聚合特征 , 再通过 FC 层把 转化到 相同的域中, 如下图5所示:
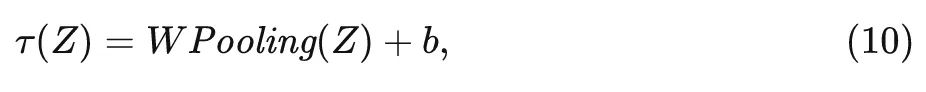
式中, 分别是 weight 和 bias。
1.1.4 G-Ghost Stage 复杂度分析
通过本文提出的 G-Ghost Stage 对原有的 CNN 结构进行升级, 可以大大降低计算和存储成本。具 体而言, 给定一个有 个 Block 的 Stage, 第 个块的 FLOPs 为 , 参数量为 。G-Ghost阶 段将原始 块的 FLOPs 分别减小为 。参数量分别简化为 。因此, 理论计算复杂度的优化率分别是:
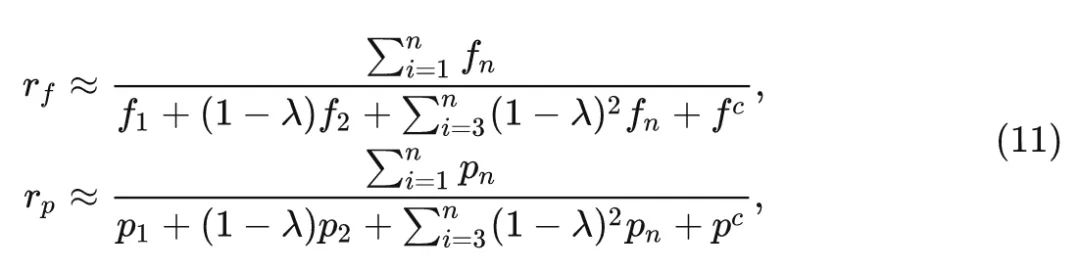
当 时 FLOPs 或参数量的降低比较明显。
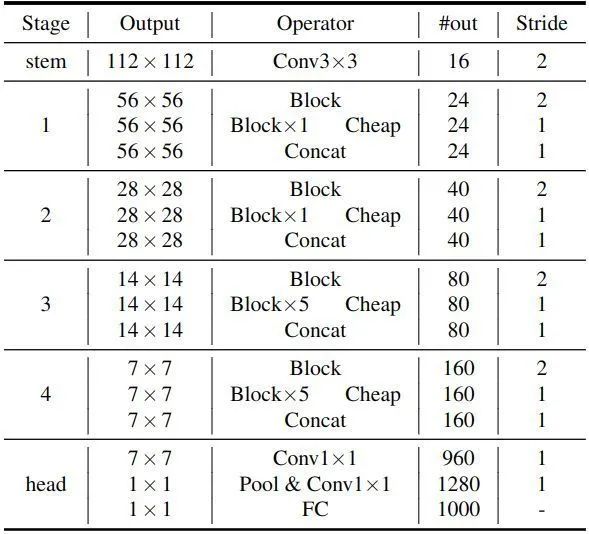
1.1.5 G-GhostNet 架构
利用 G-Ghost Stage 来改造现有的 CNN 架构,得到了 G-GhostNet 架构。\lambda\lambda 设置为0.4,Expansion ratio 设为3。
1.1.6 实验结果
ResNet + G-Ghost Stage 图像分类结果
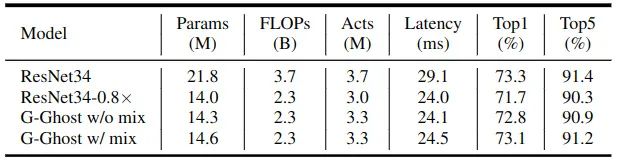
G-Ghost Stage 可以迁移到不同的 CNN 模型中,可以用来加速现有的网络。在 ResNet 上面的应用结果如下图8所示。G-GhostResNet34 在没有混合操作的情况下,在 FLOPs 和 GPU Latency 相似的情况下,性能明显优于ResNet34-0.8×。混合运算 Mix 进一步提高了性能,而额外的计算成本可以忽略不计。最后,带有混合操作的 G-Ghost-ResNet34,通过减少约 16% 的 GPU 延迟,达到了与原始 ResNet34 相当的精度。
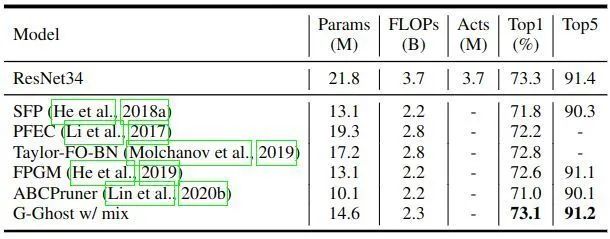
与剪枝方法对比
模型剪枝是一种广泛应用的简化神经网络的方法,它将不重要的通道剪掉。作者将 GGhost-ResNet34 与最先进的剪枝方法进行了比较,包括 SFP,PFEC,Taylor-FO-BN 和 FPGM。如下图9所示,G-Ghost-ResNet34 优于其他方法。
可视化结果
作者分别在图10和图11中展示了原始 ResNet 和 G-Ghost-ResNet 的特征图。G-Ghost-ResNet34 的特征图与原始特征相似,说明廉价操作达到了生成信息量较大的特征的目的,复杂性的降低不影响网络的容量。


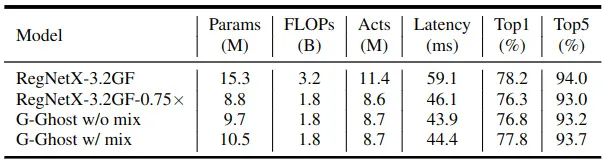
RegNet + G-Ghost Stage 图像分类结果
在 ResNet 上面的应用结果如下图12和13所示。在相似的推理延迟下,G-Ghost Stage 加持下的 RegNet 的 top-1 精度比 RegNetX-3.2GF0.75× 高 1.1%。
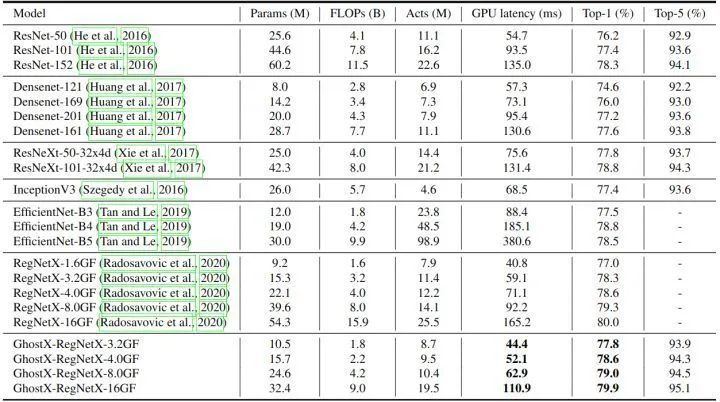
COCO minival 目标检测实验结果
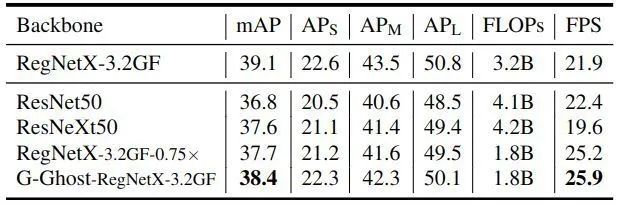
作者选择典型的单级检测器 RetinaNet 作为基本框架,并使用 G-Ghost 作为骨干模型。所有模型均采用 1× learning rate schedule (12 epochs) 进行训练。如下图14所示为 COCO minival 的结果。G-Ghost 只需要降低很小的 mAP,就可以将 GPU 速度从 21.9帧/秒提高到 25.9帧/秒。
总结
本文介绍的工作 G-GhostNet 是适配 GPU 端的轻量级 GhostNet,作者在本文中研究跨 Block 特征的冗余性和相似性。借助 G-GhostNet 技术,GhostNet 可以在准确性和 GPU 延迟之间获得更好的权衡。
参考
^Mobilenetv2: Inverted residuals and linear bottlenecks

公众号后台回复“速查表”获取
21张速查表(神经网络、线性代数、可视化等)打包下载~
算法竞赛:算法offer直通车、50万总奖池!高通人工智能创新应用大赛等你来战!
技术干货:超简单正则表达式入门教程|22 款神经网络设计和可视化的工具大汇总
极视角动态:芜湖市湾沚区联手极视角打造核酸检测便民服务系统上线!|青岛市委常委、组织部部长于玉一行莅临极视角调研

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选
