一番实验后,有关Batch Size的玄学被打破了
视学算法编译
编辑:泽南
有关 batch size 的设置范围,其实不必那么拘谨。

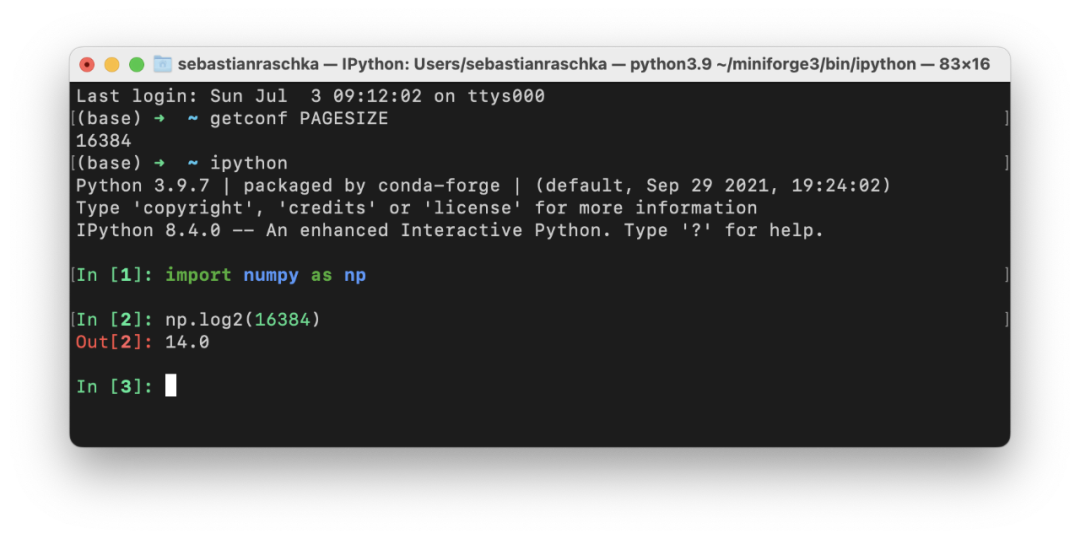

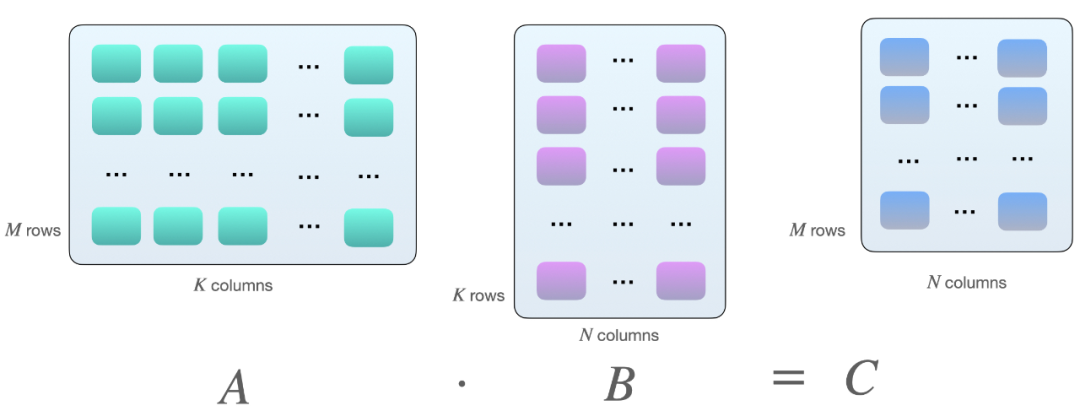
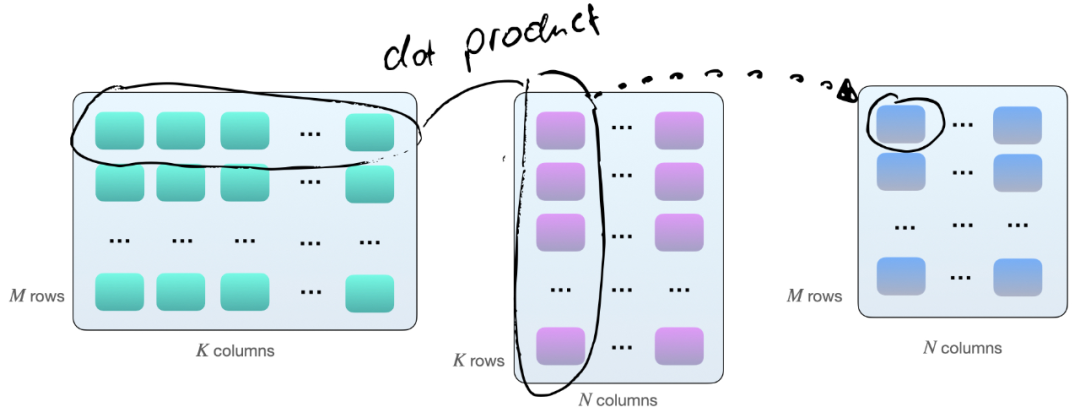
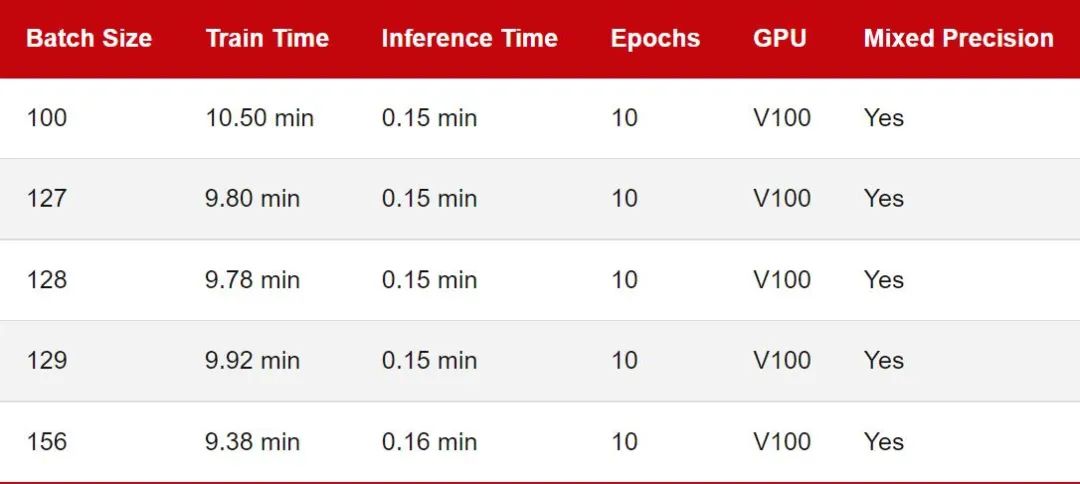
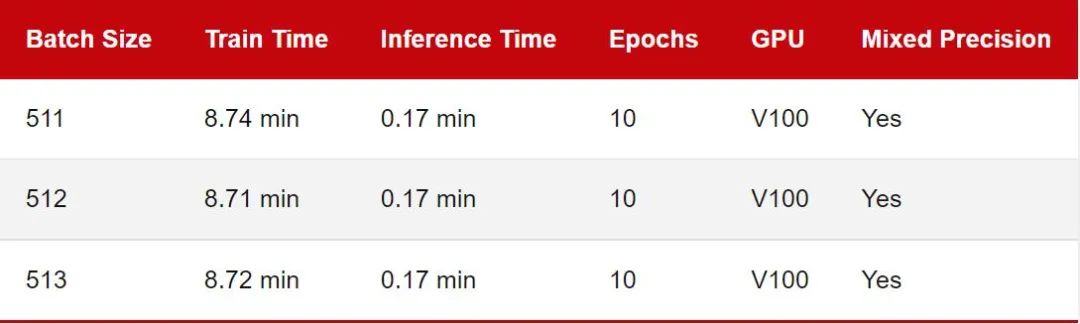
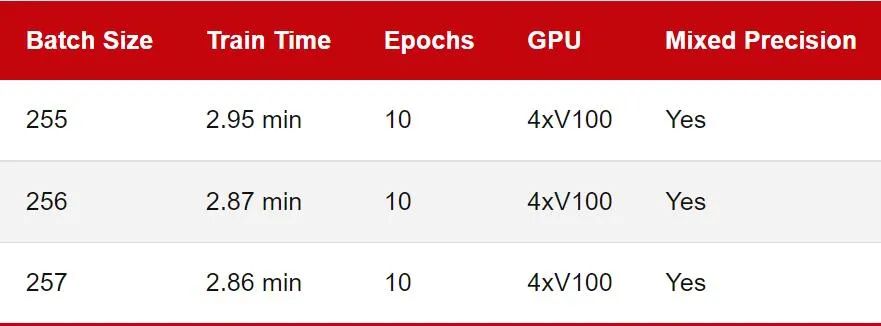
显卡是否有 Tensor Core; 显卡是否支持混合精度训练; 在像 DeiT 这样的无卷积视觉转换器。
© THE END
转载请联系原公众号获得授权

点个在看 paper不断!
评论
 下载APP
下载APP视学算法编译
编辑:泽南
有关 batch size 的设置范围,其实不必那么拘谨。
© THE END
转载请联系原公众号获得授权
点个在看 paper不断!