
RocketMQ 架构简析


整体架构
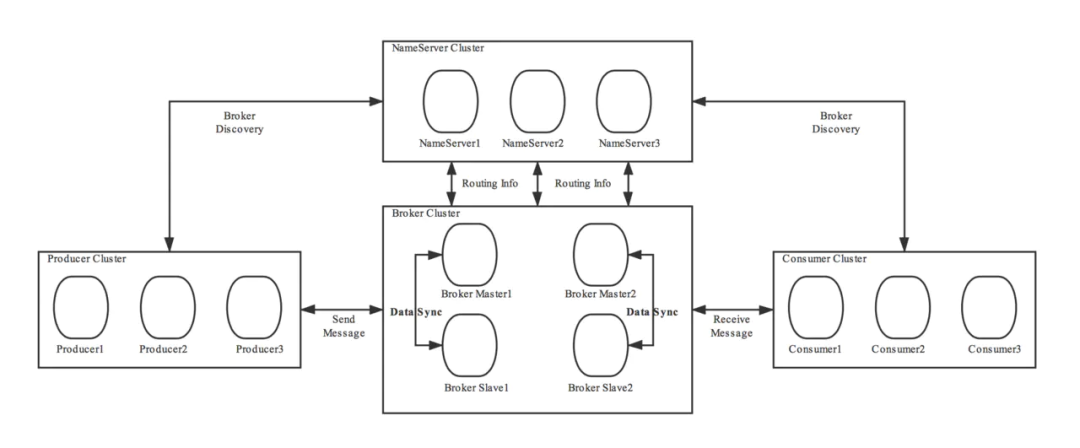
Namesrv
路由元信息
topicQueueTable:topic 消息队列路由信息。 brokerAddrTable:broker基础信息。包含broker name,所属集群名称,主broker地址等。 clusterAddrTable:broker集群信息,存储集群中所有broker的名称。 brokerLiveTable:broker状态信息。 filterServerTable:broker上的filterServer列表。filterServer用于消息过滤。
路由注册 RocketMQ路由注册是通过broker与Namesrv的心跳功能实现的。broker启动时向集群中所有Namesrv发送心跳包,之后每隔30秒向集群中所有Namesrv发送心跳包。心跳包中包含:broker集群信息、broker信息、topic配置信息、broker关联的FilterServer列表等。如果brokerA为Master。并且brokerA上的topic1的配置信息发生变化或初次注册,Namesrv会根据报文创建或更新Topic路由元数据,填充topicQueueTable。 路由删除 Namesrv收到brokerA的心跳包会更新brokerLiveTable中的brokerA对应的BrokerLiveInfo中的lastUpdateTimestamp。Namesrv每隔10秒扫描brokerLiveTable一次。如果brokerA对应的BrokerLiveInfo 中 lastUpdateTimestamp距当前时间超过 120秒,Namesrv认为brokerA失效,会将brokerA的路由信息移除并关闭与broker的socket连接。更新:topicQueueInfo、brokerAddrTable、brokerLiveTable、filterServerTable等。 路由发现 RocketMQ路由发现是非实时的。当Topic路由信息发生变化是,Namesrv不会主动推送给客户端(Producer、Consumer)。而是由客户端定时到Namesrv拉去最新的路由信息并缓存(包含Topic路由信息)。
与kafka对比
kafka 由zookeeper集群提供命名服务(Naming Service)。
Kafka通过 ZooKeeper 管理集群配置、选举 Leader 以及在 consumer g
Broker

与kafka对比:
kafka和RocketMQ的broker都可以容纳多个一个或多个分区数据(kafka分区:partition;RocketMQ分区:queue)。
kafka基于partition(分区) 做备份/高可用(partition follower)。
RocketMQ增加了broker group的概念,基于broker(可能包含多个分区)。
Producer
Consumer
Producer、Consumer都只需要和集群中一个Namesrv建立长连接。Broker需要向集群中所有的Namesrv发送心跳包。
其实很好理解:
Namesrv集群提供高可用的命名服务。
Producer、Consumer只需要从其中一台定期同步路由信息。
如果Broker只随机调一台发送心跳包。那么不同的Namesrv保存的路由信息会出现
消费者类型:
拉取式消费(Pull Consumer) Consumer消费的一种类型,应用通常主动调用Consumer的拉消息方法从Broker服务器拉消息、主动权由应用控制。一旦获取了批量消息,应用就会启动消费过程。Pull方式里,取消息的过程需要用户自己写(包括提交offset等操作)。 推动式消费(Push Consumer) Consumer消费的一种类型,该模式下Broker收到数据后会主动推送给消费端,该消费模式一般实时性较高。Push Consumer原理上也是采取pull模式。实际上就是长轮询的pull模式。
一些概念
主题(Topic) 表示一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题,是RocketMQ进行消息订阅的基本单位。每个topic可分为若干个分区(queue)。 生产者组(Producer Group) 同一类Producer的集合,这类Producer发送同一类消息且发送逻辑一致。如果发送的是事务消息且原始生产者在发送之后崩溃,则Broker服务器会联系同一生产者组的其他生产者实例以提交或回溯消费。 消费者组(Consumer Group) 同一类Consumer的集合,这类Consumer通常消费同一类消息且消费逻辑一致。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。要注意的是,消费者组的消费者实例必须订阅完全相同的Topic。RocketMQ 支持两种消息模式:集群消费(Clustering)和广播消费(Broadcasting)。 普通顺序消息(Normal Ordered Message) 普通顺序消费模式下,消费者通过同一个消费队列收到的消息是有顺序的,不同消息队列收到的消息则可能是无顺序的。 严格顺序消息(Strictly Ordered Message) 严格顺序消息模式下,消费者收到的所有消息均是有顺序的。 消息(Message) 消息系统所传输信息的物理载体,生产和消费数据的最小单位,每条消息必须属于一个主题。RocketMQ中每个消息拥有唯一的Message ID,且可以携带具有业务标识的Key。系统提供了通过Message ID和Key查询消息的功能。 标签(Tag) 为消息设置的标志,用于同一主题下区分不同类型的消息。来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费逻辑,实现更好的扩展性。
关于消息中间件
1. 消息优先级(Message Priority;RocketMQ不支持)
2. 顺序消息(Message Order)
投递消息的顺序性:投递消息的顺序性可通过将一组消息投递到同一分区实现。例如:借助MessageQueueSelector将对相同订单的操作消息投放到同一分区。 消费消息的顺序性:RoctetMQ特性保障:特定分区(queue)中的消息不能同时被同一个消费者组中的多个Consumer消费,以避免重复消费。通过自定义或使用预置的AllocateQueueStrategy可设定分区的分配策略(哪些分区分配给哪个消费者消费)。
3. 高可用、消息可靠性
3.1 消息持久化
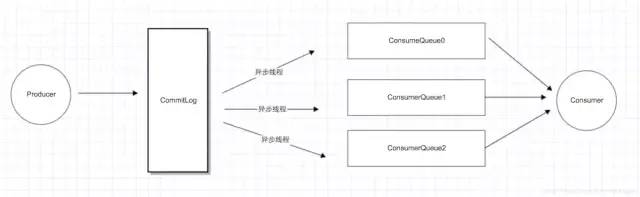
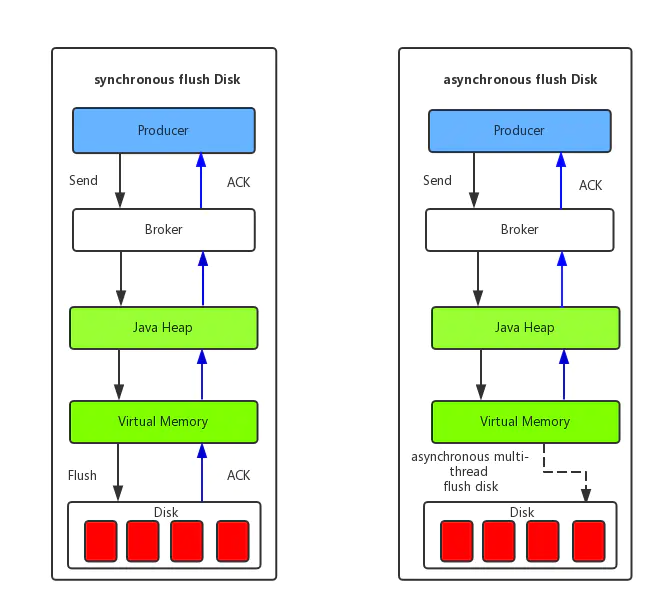
3.2 broker master/salve
4. 高并发、可扩展 ==> 分布式
4.1 生产并行度
4.2 消费并行度
4.3 消息队列分配策略
MessageQueueSelector

AllocateMessageQueueStrategy

AllocateMessageQueueAveragely:平均分配算法 AllocateMessageQueueAveragelyByCircle:基于环形平均分配算法 AllocateMachineRoomNearby:基于机房临近原则算法 AllocateMessageQueueByMachineRoom:基于机房分配算法 AllocateMessageQueueConsistentHash:基于一致性hash算法 AllocateMessageQueueByConfig:基于配置分配算法
参考:
作者:RyanLee86799
来源:https://juejin.im/post/6844904130822029320
文章转载:JAVA高级架构
(版权归原作者所有,侵删)
![]()

点击下方“阅读原文”查看更多
评论