
RocketMq架构简析
整体结构
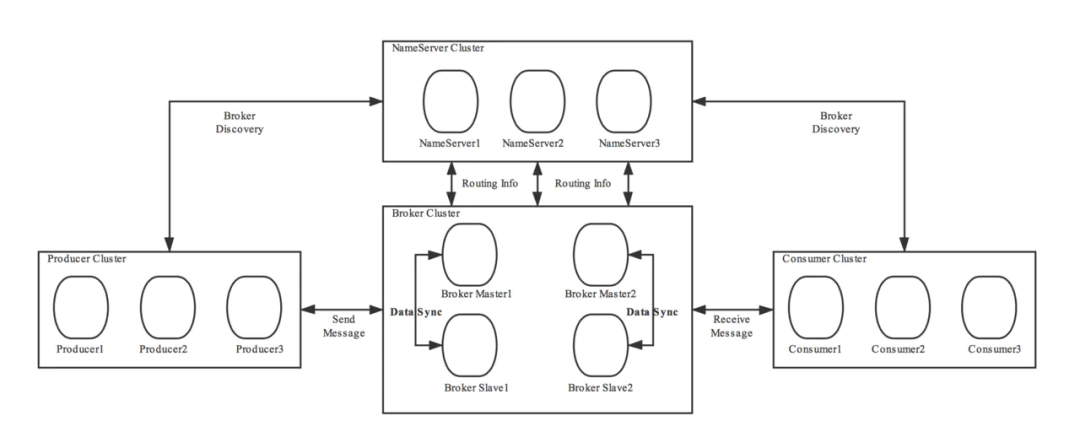
RocketMQ主要由 Producer、Broker、Consumer 三部分组成,其中Producer 负责生产消息,Consumer 负责消费消息,Broker 负责存储消息。每个 Broker 可以存储多个Topic的消息,每个Topic的消息也可以分片存储于集群中的不同的Broker Group。
Namesrv
说道Namesrv首先会想到服务注册与发现。分布式服务SOA架构体系中会有服务注册与发现中心。主要作用是指导服务调用方找到服务提供者提供的服务实例。RocketMQ体系中Namesrv主要作用是:为producer和consumer提供关于topic的路由信息。管理broker节点:监控更新broker的实时状态。路由注册、路由删除(故障剔除)。
Namesrv充当路由消息的提供者。Namesrv是一个几乎无状态节点,多个Namesrv实例组成集群,但相互独立,没有信息交换。
路由元信息
topicQueueTable:topic 消息队列路由信息。 brokerAddrTable:broker基础信息。包含broker name,所属集群名称,主broker地址等。 clusterAddrTable:broker集群信息,存储集群中所有broker的名称。 brokerLiveTable:broker状态信息。 filterServerTable:broker上的filterServer列表。filterServer用于消息过滤。
路由注册 RocketMQ路由注册是通过broker与Namesrv的心跳功能实现的。broker启动时向集群中所有Namesrv发送心跳包,之后每隔30秒向集群中所有Namesrv发送心跳包。心跳包中包含:broker集群信息、broker信息、topic配置信息、broker关联的FilterServer列表等。如果brokerA为Master。并且brokerA上的topic1的配置信息发生变化或初次注册,Namesrv会根据报文创建或更新Topic路由元数据,填充topicQueueTable。 路由删除 Namesrv收到brokerA的心跳包会更新brokerLiveTable中的brokerA对应的BrokerLiveInfo中的lastUpdateTimestamp。Namesrv每隔10秒扫描brokerLiveTable一次。如果brokerA对应的BrokerLiveInfo 中 lastUpdateTimestamp距当前时间超过 120秒,Namesrv认为brokerA失效,会将brokerA的路由信息移除并关闭与broker的socket连接。更新:topicQueueInfo、brokerAddrTable、brokerLiveTable、filterServerTable等。 路由发现 RocketMQ路由发现是非实时的。当Topic路由信息发生变化是,Namesrv不会主动推送给客户端(Producer、Consumer)。而是由客户端定时到Namesrv拉去最新的路由信息并缓存(包含Topic路由信息)。
与kafka对比
kafka 由zookeeper集群提供命名服务(Naming Service)。
Kafka通过 ZooKeeper 管理集群配置、选举 Leader 以及在 consumer g
Broker

每个Broker与Namesrv集群中的所有节点建立长连接,定时发送心跳包到所有Namesrv,更新broker信息、topic路由信息等。一个Topic的不同queue(分区)可分布到集群中不同的broker group上。
与kafka对比:
kafka和RocketMQ的broker都可以容纳多个一个或多个分区数据(kafka分区:partition;RocketMQ分区:queue)
kafka基于partition(分区) 做备份/高可用(partition follower)。
RocketMQ增加了broker group的概念,基于broker(可能包含多个分区)
Producer
Consumer
Producer、Consumer都只需要和集群中一个Namesrv建立长连接。Broker需要向集群中所有的Namesrv发送心跳包。
其实很好理解:
Namesrv集群提供高可用的命名服务。
Producer、Consumer只需要从其中一台定期同步路由信息。
如果Broker只随机调一台发送心跳包。那么不同的Namesrv保存的路由信息会出现
消费者类型:
拉取式消费(Pull Consumer) Consumer消费的一种类型,应用通常主动调用Consumer的拉消息方法从Broker服务器拉消息、主动权由应用控制。一旦获取了批量消息,应用就会启动消费过程。Pull方式里,取消息的过程需要用户自己写(包括提交offset等操作)。
推动式消费(Push Consumer) Consumer消费的一种类型,该模式下Broker收到数据后会主动推送给消费端,该消费模式一般实时性较高。Push Consumer原理上也是采取pull模式。实际上就是长轮询的pull模式。
一些概念
主题(Topic) 表示一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题,是RocketMQ进行消息订阅的基本单位。每个topic可分为若干个分区(queue)
生产者组(Producer Group) 同一类Producer的集合,这类Producer发送同一类消息且发送逻辑一致。如果发送的是事务消息且原始生产者在发送之后崩溃,则Broker服务器会联系同一生产者组的其他生产者实例以提交或回溯消费。
消费者组(Consumer Group) 同一类Consumer的集合,这类Consumer通常消费同一类消息且消费逻辑一致。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。要注意的是,消费者组的消费者实例必须订阅完全相同的Topic。RocketMQ 支持两种消息模式:集群消费(Clustering)和广播消费(Broadcasting)。
普通顺序消息(Normal Ordered Message) 普通顺序消费模式下,消费者通过同一个消费队列收到的消息是有顺序的,不同消息队列收到的消息则可能是无顺序的。
严格顺序消息(Strictly Ordered Message) 严格顺序消息模式下,消费者收到的所有消息均是有顺序的。
消息(Message) 消息系统所传输信息的物理载体,生产和消费数据的最小单位,每条消息必须属于一个主题。RocketMQ中每个消息拥有唯一的Message ID,且可以携带具有业务标识的Key。系统提供了通过Message ID和Key查询消息的功能。
标签(Tag) 为消息设置的标志,用于同一主题下区分不同类型的消息。来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费逻辑,实现更好的扩展性。
关于消息中间件
消息中间件需要解决的问题:异步化、削峰填谷。
消息中间件应具备的基础能力是:消息发布、订阅、消费。概念相对简单这里不过多描述。
消息中间件的一些重要的机制:
1. 消息优先级(Message Priority;RocketMQ不支持)
优先级是指在一个消息队列中,每条消息都有不同的优先级,一般用整数来描述,优先级高的消息先投递,如果消息完全在一个内存队列中,那么在投递前可以按照优先级排序,令优先级高的先投递。由于RocketMQ所有消息都是持久化的,所以如果按照优先级来排序,开销会非常大,因此RocketMQ没有特意支持消息优先级,但是可以通过变通的方式实现类似功能,即单独配置一个优先级高的队列,和一个普通优先级的队列,将不同优先级发送到不同队列即可。
2. 顺序消息(Message Order)
消息有序指的是一类消息消费时,能按照发送的顺序来消费。例如:一个订单产生了3条消息,分别是订单创建,订单付款,订单完成。消费时,要按照这个顺序消费才能有意义。但是同时订单之间是可以并行消费的。RocketMQ可以严格的保证消息有序。
投递消息的顺序性:投递消息的顺序性可通过将一组消息投递到同一分区实现。例如:借助MessageQueueSelector将对相同订单的操作消息投放到同一分区。
消费消息的顺序性:RoctetMQ特性保障:特定分区(queue)中的消息不能同时被同一个消费者组中的多个Consumer消费,以避免重复消费。通过自定义或使用预置的AllocateQueueStrategy可设定分区的分配策略(哪些分区分配给哪个消费者消费)。
3. 高可用、消息可靠性
3.1 消息持久化
RocketMQ、Kafka 以文件记录形式持久化。
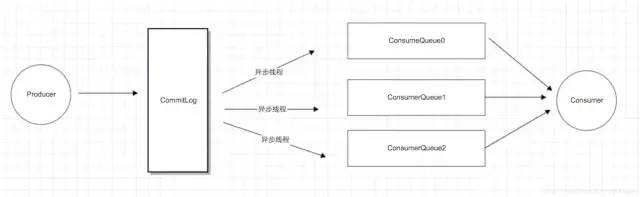
RocketMQ采用了单一的日志文件,即把同1个broker上面所有topic的所有queue的消息,存放在一个文件里面,从而避免了随机的磁盘写入。
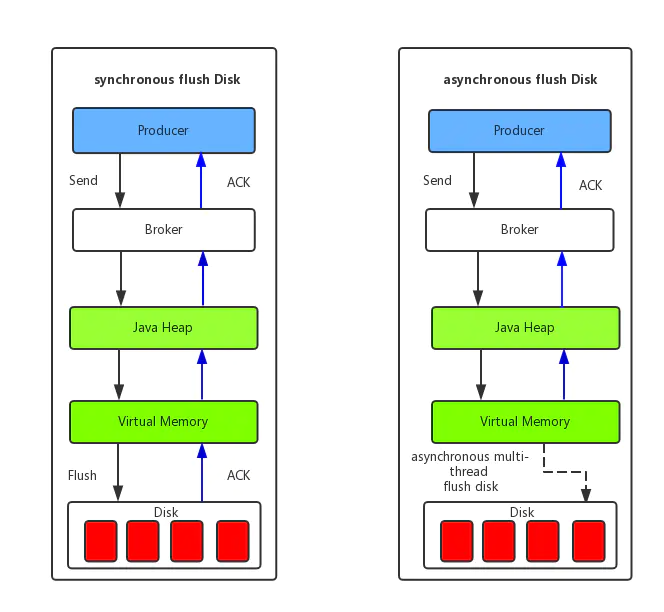
TODO 同步、异步刷盘。
TODO RocketMQ充分利用Linux文件系统内存cache来提高性能。
TODO CommitLog index Commitlog segment的大小与页缓存一致
RocketMQ消息存储机制会在后面的文章详细说明。
3.2 broker master/salve
TODO broker group master/salve
TODO Async/Sync Master;
4. 高并发、可扩展 ==> 分布式
提高并发效率 => 提高生产、消费并行度=>提高分区数量
RocketMQ、kafka都支持topic数据分区存放、动态扩展。
以RocketMQ为例:
topic创建的时候可以用集群模式去创建(这样集群里面每个broker的queue的数量相同),也可以用单个broker模式去创建(这样每个broker的queue数量可以不一致)。
4.1 生产并行度
RocketMQ的生产并行度是由其自身机制及broker的数量决定的。这块后面的文章会详细分析。
4.2 消费并行度
4.3 消息队列分配策略
Producer使用MessageQueueSelector选择将消息投放到哪个分区 使用AllocateMessageQueueStrategy将不同分区分配给Consumer Group中的不同Consumer。一个分区(queue)仅允许分配给同一个Consumer Group下的一个Consumer(防止重复消费)。
MessageQueueSelector

可以通过实现MessageQueueSelector接口,来自定义Producer投递消息时选择分区的算法。
AllocateMessageQueueStrategy

内置实现类:
AllocateMessageQueueAveragely:平均分配算法
AllocateMessageQueueAveragelyByCircle:基于环形平均分配算法
AllocateMachineRoomNearby:基于机房临近原则算法
AllocateMessageQueueByMachineRoom:基于机房分配算法
AllocateMessageQueueConsistentHash:基于一致性hash算法
AllocateMessageQueueByConfig:基于配置分配算法
可以通过实现AllocateMessageQueueStrategy来自定义queue 分配给特定Consumer Group下不同Consumer的策略。
参考(排名不分先后)
https://github.com/apache/rocketmq/blob/master/docs/cn/
https://juejin.im/post/6844903589819875336
https://jaskey.github.io/blog/2016/12/19/rocketmq-rebalance/
http://objcoding.com/2019/09/13/kafka-partition-and-rmq-queue/
http://www.itmuch.com/books/rocketmq
来源:https://juejin.im/post/6844904130822029320
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
