
终于有人把数据分析及其技能树讲清楚了!
本文将以数据分析的兴起与发展为重点,介绍数据时代的发展背最与数据分析的八个流派。本节涉及几个重要的关键名词,如大数据、人工智能、机器学习与深度学习等。文末再对数据分析技能树做个简单讨论。
数据分析概述
什么是数据分析
数据分析(Data Analysis)往往又称数据科学 (Data Science),其目标是在数据中找到有价值的规律或特征,是一门利用数据学习的科学。它结合了各种不同的领域,如数学、统计、机器学习、数据可视化、数据库、云计算等。非专业人士能够利用数据分析来理解问题,通过数据的解读与分析来正确地处理数据。数据分析能够用于不同的领域,如教育、金融或商业。
简单来说,数据分析就是“从数据中找出洞见”的一种技术、一种方法。“数据分析”这个名词兴起于2012-2013年。随着计算机技术的发展,计算机的存储技术与运算效率都有了巨大的提升,进而带出了 “云计算”—>“大数据”—>物联网”—>“机器学习”—>“深度学习”—>“人工智能”这一系列技术新浪潮,而数据分析也是跟着出场的一个新名词。
事实上,数据分析并不是一个新技术,过去传统的科学研究其实都算是广义的数据分析,但是受限于硬件与计算资源的不足,多半只是统计学上的量化研究。现今的数据分析只是一个升级版,是融合了统计、计算机与数据发展的数据分析。
数据分析的发展方向
数据分析的发展方向有如下两个:
由“问题导向”的推论统计和假设检验 (Hypothesis Testing) 由“数据驱动”的数据挖掘(Data Mining)或知识发现(Knowledge Discovery)
推论统计其实就是统计学中的量化研究方法,即人们根据观察或专业知识对一个问题提出虚无假设与对立假设,先证明虚无假设正确,再依照对立假设进行推论。
t-检验、Z-检验、卡方检验都属于假设检验。假设检验是一种由上而下的研究方法,换句话说,必须先有假设,才能有检验。在真实世界中,提出假设本身是一件困难的工作。
另一个困难点在于很多假设是由具有专业知识背最的科学家提出的,难免会掺杂主观的想法,其有一定的不可控性。假设检验是问题导向的,人们可以尝试去证实或举反证来验证预设的想法。
数据挖掘是另一种由下而上(由数据反过来观察结果)的数据驱动方法。在没有任何假设的情況下,人们可以直接通过数据观察归纳出某些重要的特性。不同于必须要先假设的推论统计,数据挖掘仅通过数据由下而上得到结果。数据挖掘不需要过多的事前假设,也不会有主观意念的影响。
不过数据挖掘就像是大海捞针一样,人们需要在茫茫的数据中找寻特性。可想而知,这种方法需要大量的计算与储存资源。这也是数据挖掘过去一直无法成为主流研究方向的主要原因,但随着计算机科学的发展,更快的计算资源与更大的储存空问让数据挖掘逐渐受到重视。数据挖掘是数据驱动的,人们可以从现有的数据中分析出一些未知的事情。机器学习是数据挖掘的一种方法,这两个名词现在经常混用。
统计分析:利用数学模型学习数据,找出一组参数来“描述”数据,目标是找出数据背后的规律,解释数据问的关系 机器学习:通过抽象模型学习拟合数据,着重在学习模型的最佳化过程,目标是达到最好的预测效果。 数据挖掘:强调演算方法或步骤,目标是找出数据背后的价值。人们通常会根据所需要的数据选择适合的方法。
数据挖掘与统计分析这两种方法的目标是相近的,只是使用背景有所不同。数据挖掘是计算机领域发展的议题;统计分析是统计学所探讨的领域。无论是数据挖掘,还是统计分析,它们都有一个共同的目标——从数据中学习。这两种方法的目的都是使人们通过处理数据的过程,对数据有更进一步的了解与认识。数据挖掘、大数据、统计学三者的关系如图所示。
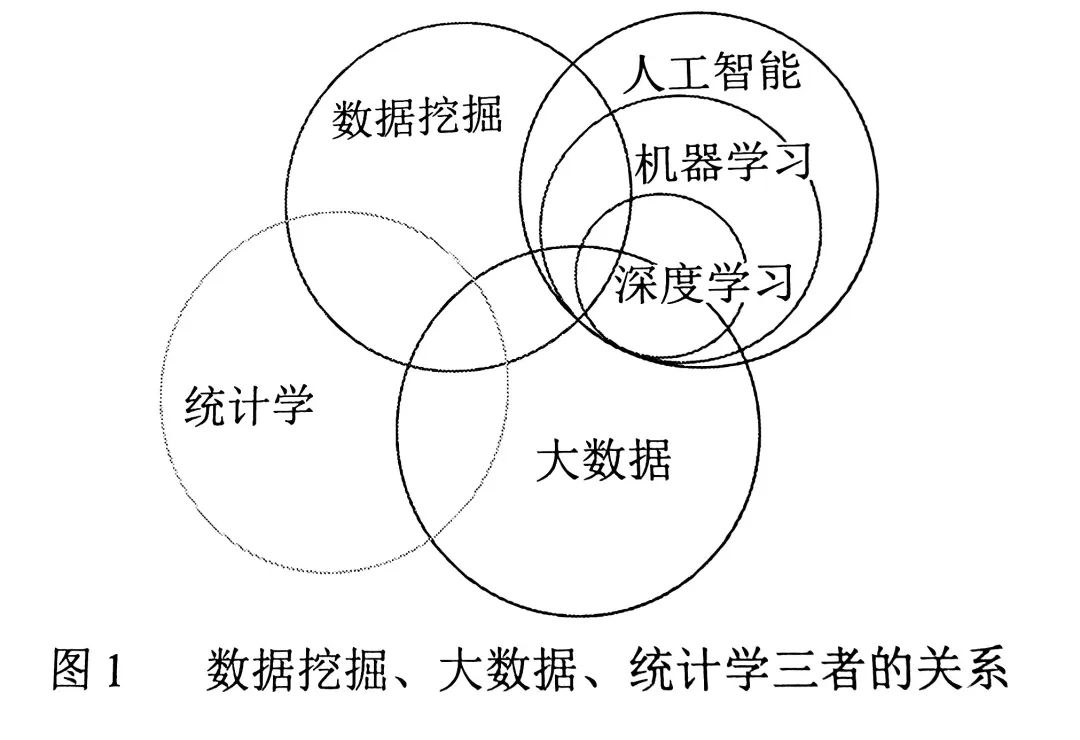
统计方法是人们利用方程描述分类问题,为数据找出一个分割线,将结果分成两类的方法。然而,人们利用机器学习的方法找出来的是一圈一圈的等曲线,看起米似乎可以得到更广泛的结果,而不只是简单的分类问题。机器学习是由人工智慧发展而来的领域,通过非规则的方法学习数据分布的关系。统计模型足统计学中描述自变量(特征栏位)与因变量(目标栏位)的关系的模型。统计模型是基于严格的假说限制进行统计检验的(称为假设检验)。假设检验与机器学习方法的不同之处在于机器学习方法是在无假说的情况下对数据进行计算的算法。
基于假设检验的发展,统计模型能找出更贴近现有数据的趋势。然而,预测的目的是找出“未来数据”或所有数据,但假设会使得数据太贴近现有数据(在机器学习中称为过拟和)。严格的假设是统计学习的一把“双刃剑”,就像数据分析中流传的一句话所说的那样:预测模型中较小的假设,预测能力较强 (The lesser assumptions in a predictive model, higher will be the predictive power)总的来说,数据分析的前身其实就是统计学,随着数据累积才有了大数据,带动了演算法的发展,也就是现在的机器学习与深度学习。现今,数据分析技术正在发展的浪潮上,数据分析的终极目标是利用数据与算法打造一个更智慧的系统,即人工智能。
大数据与厚数据
无论是统计分析还是数据挖掘,数据都扮演着决定性的角色。数据量越大,其所支持的分析模型越完善。如果数据的可用性太低,那么模型再厉害也无法充分发挥作用。所以,数据有两种指标:量与质。
我们把巨量的数据称为大数据,简单的定义如下:当抽样的数量大到接近 “母体” 时,这类数据就可以称为大数据,带来的效益是大幅降低因为抽样产生的误差。大数据具备 Volume (数据量)、Variety (多元性)、 Velocity(即时性)的3V 特性。
为什么巨量数据是一件重要的事情?迈尔•舍恩伯格在《大数据》一书中这样说明:“通过更完整的数据分析,通过接近母体的数据量,可以大幅降低传统抽样所产生的统计误差。”换言之,实现巨量数据需要付出更多、更快的运算机器,所以巨量数据与计算机技术的进步是相辅相成的。不过,数据分析也不尽然要盲目地追求“巨量” 这件事。大企业能享有巨量数据的规模优势,但小团队也有成本及创新上的优势,因为速度够快、灵活度高,就算维持小规模,还是能够蓬勃发展的。重要的是,能否掌握数据时代的思维与创新。
从数据可用性角度来看数据,数据分析领域还有另一个值得关注的名词——厚数据。
厚数据由美国社会学者克利福德•格尔茨提出,是指利用人类学定性研究法来定义的数据。数据隐含大量感性内容。少量数据能够记载更多的意义,也就是说数据本身具有较的信息量。厚数据不同于大数据的量化,更多的是数据的质性。
数据挖掘、机器学习与深度学习
数据挖掘
数据挖掘的英文是 Data Mining,其主要的意思是 Mining From Data, 即从数据中挖掘金矿。另外,KDD CKnowledge Discovery in Databases)是数据挖掘的另一个常见的同义词。Data Mining 是在20 世纪90 年代从数据库领域发展而来的,所以一开始通常用KDD这个名称,在知名的学术论坛也称为 SIGKDD。
第一届 SIGKDD 会议讨论了这个问题,即沿用 KDD还是改名为 Data Mining。会议最终决定这两个名宇都保留,KDD 有其科学研究上的含义,而 Data Mining 也适用于产业界。数据挖掘方法主要分为3种:关联(Association)法、分类(Classification)法和聚类(Clustering)法。
提到数据挖掘,一定会提到“啤酒尿布”这样的案例。该案例涉及一个经典的数据挖掘算法——关联规则 (Association Rule)。因其常用在商品数据上,所以也被称为购物篮数据分析 (Basket Data Analysis)。关联规则通过数据间的关系,找出怎样的组合是比较常出现的。关联规则与传统统计的相关性差异在于关联法则更重视关联性。
分类法是数据挖掘与机器学习中的重要算法。分类法主要用于区分数据,判断数据属于哪一个类别,即从原有的己知类别的数据集进行学习,以判断新进的未知类别的数据。因为是用己知类别的数据集进行学习,所以分类法也被称为监督式学习(Supervised Learning)。
分类法的用法有两种:分析与预测。
分析:解释模型形成的原因,以了解数据本身的特性及应用。 预测:根据数据的特征及模型预测未来新的数据走向。
分类法可应用在多个领域,如银行用来判断是否发放货款,医生用来判断某人是否患病等。
聚类法又称丛集法,是相对于分类法的另一种数据挖掘方法。聚类法也是用来区分数据的,它与分类法的差别在于原本的数据都是未经类别区分的。因为是对末知类别台数据集进行区分,所以聚类法也被称为非监督式学习 (Unsupervised Learning) 。
聚类法通常用于分组。举例来说,一家营销公司想要对不同的用户投放广告,就可以利用聚类法先对其进行初步的分组。聚类法可以用在市场研究、图形识别等领域。因为数据是由不同的属性所组成的向量,会呈现一个多维的对象,所以人们通常利用“距离”的概念表示相似程度。两笔数据会被表示为两个点,两点之间的距离越大,代表两笔数据越相似,反之越不相似。
当然,随着数据样式的变化,许多进阶用法不断出现,如时间序列分析 (Time Series Analysis) 和序列模式分析 (Sequential Pattern Analysis)。
机器学习
机器学习是从人工智能这门学科延伸出来的分支,主要是通过演算法试图从数据中“学习”到数据的规律,从而预测数据的特性。机器学习、数据挖掘与统计分析是用不同的观点看待 “数据” 的技术。随着技术的演进,这些技术所涵盖的方法与技术越来越相近。《大演算》
一书从不同的思维角度将机器学习流派分成 5 种。
符号理论学派:归纳法——从数据反向推导出结论的方法。 演化论学派:遗传算法——通过程序模拟遗传演化产出最后的结果。 类神经网络学派:通过多层的节点模拟脑神经传导的思考。 贝氏定理学派:根据统计学及概率的理论产生模型。 类比推理学派:基于相似度判断进行推论学习。
深度学习
深度学习是机器学习的一个支派,也称为进阶的方法,以前也称为类神经网络。目前业界使用较多的是深度学习这个名称。1980年,多层类神经网络失败,浅层机器学习方法(SVM 等)兴起。直到 2006 年辛顿成功训练出多层神经网络,带动了新一波的深度学习发展。
数据分析技能树
数据分析是一个路领域的学科,而不是单一领域的学科。数据分析人员必须同时掌握不同领域的知识,需要有跨领域合作的思维。
怎样成为数据分析人员
要完成一个好的数据项目,靠的不能只是一个厉害的强者,而是需要一支合作无间的数据团队。换句话说,只要能够找到一个在团队中的位置,人人都有机会参与数据项目。不过,找到这个位置也不是那么容易的,相关人员需要具备跨领域的复合技能与沟通合作的硬实力。
数据分析技能可以分为了种:程序技术、理论分析与专业应用。
程序技术:Python、数据清理、数据工程。 理论分析:统计分析、数据挖掘、机器学习、深度学习。 专业应用:数据分析、数据爬虫、人工智慧。
程序技术员指的是擅长程序开发的人,有比较扎实的工程背景,适合往数据工程方向发展。数理分析能力比较强的人一般具有较好的理论分析能力,其可能具有数学统计或信息背景,可以深入研究数据分析领域或机器学习分析领域。如果一个人写不好程序、也不擅长数学,那么他是不是就难以入门数据分析呢?答案是否定的。拥有某一个领域专业背景的人,也可以往专业应用的方向发展。在擅长 领域中积累知识、找出数据分析可以发挥的空间也是一件很重要的事情。这类人需要的是“相信数据分析的信念”与跨领域沟通的能力。数据分析人员如图所示:

技能树养成之路
数据分析技能那么多,那么技能该怎么学,该从何学起呢?在不同的数据分析教材或课程中,学习地图或课程规划都不太相同,这意味着学习数据分析其实并没有一条绝对的道路。对于新手,建议其首先学好一个程序语言,其次学习相关的系统工具,然后把一个基本的分析过程从头到尾研究透彻,最后就可以摸索自己适合在数据项目因队中的角色了。在学习过程中,数据分析人员应培养与不同角色沟通合作的能力,逐步学习各种数据分析技能,最终成为一个独立的数据分析人员。简单来说,数据分析人员应先学会基本技能,再通过大量的项目掌握完整技能。
那么如何开始数据分析呢?首先挑选一个自己感兴趣的数据集,找出一个可以回答的问题,然后根据这个问题找到一个最基本的原型解 (Prototype Solution)来检验这个问题是否可解,通常就是选用最简单的模型当作基础线(Baseline);接着从基础线开始对解进行优化。一般来说,我们可以从以下两种角度进行优化:更好分的数据和更厉害的模型。
更好分的数据:从数据下手,对数据进行转换与重组,称为“特征工程”。 更厉害的模型:利用复杂的模型,如集成式或深度学习的模型。
除了对模型的准确度进行优化之外,速度与代码质量也是重要的优化指标。
我们可以先利用原型解建立一个基础线的工作流,将预处理与模型比我分为不同的模组,持续从不同的角度进行调整,去观察做哪些动作会造成怎样的优化,最终慢慢提炼出适合数据的手法:建立数据工作沆与优化模组之后,就可以快速地将其迁移到相似的数据与问题上,通过反复练习,从每次的调整中让白己更从容地查看数据。

《深入浅出Python数据分析》
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码: