
一种基于图像分割实现焊件缺陷检测的方法 | 附源码
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

图像分割是指将图像划分为包含相似属性的不同像素区域。为了对图像分析和解释,划分的区域应与对象特征密切相关。图像分析的成功取决于分割的可靠性,但是图像的正确分割通常是一个非常具有挑战性的问题。
图像中心距是图像像素强度的某个特定加权平均值。图像矩可用于描述分割后的对象。通过图像瞬间发现的图像简单属性包括:
面积(或总强度)
质心
有关其方向的信息
该数据集包含两个目录。原始图像存储在“图像”目录中,分割后的图像存储在“标签”目录中。让我们来看看这些数据:原始图像是RGB图像,用于训练模型和测试模型。这些图片的尺寸各不相同。直观地,较暗的部分是焊接缺陷。模型需要对这些图像执行图像分割。

“标签”目录的图像是二进制图像或地面真相标签。这是我们的模型必须针对给定的原始图像进行预测。在二进制图像中,像素具有“高”值或“低”值。白色区域或“高”值表示缺陷区域,而黑色区域或“低”值表示无缺陷。

我们将使用U-Net来解决这个问题,通过以下三个主要步骤来检测缺陷及其严重性:
图像分割
使用颜色显示严重性
使用图像矩测量严重性
训练模型
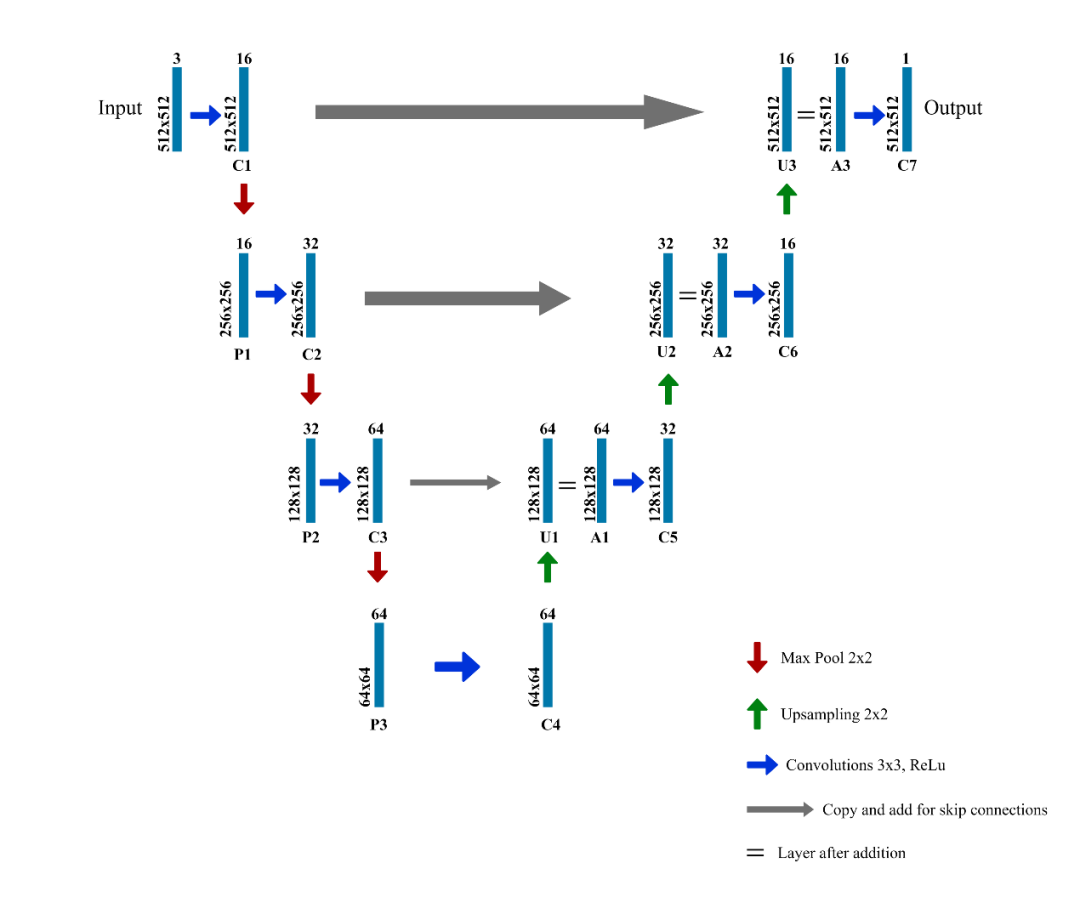
使用的U-Net架构
注意事项:
每个蓝色框对应一个多通道特征图
通道数显示在框的顶部。
(x,y)尺寸位于框的左下边缘。
箭头表示不同的操作。
图层名称位于图层下方。
C1,C2,...。C7是卷积运算后的输出层
P1,P2,P3是最大池化操作的输出层
U1,U2,U3是上采样操作的输出层
A1,A2,A3是跳过连接。
左侧是收缩路径,其中应用了常规卷积和最大池化操作
图像尺寸逐渐减小,而深度逐渐增大。
右侧是扩展路径,在其中应用了(向上采样)转置卷积和常规卷积运算
在扩展路径中,图像尺寸逐渐增大,深度逐渐减小
为了获得更好的精确位置,在扩展的每个步骤中,我们都使用跳过连接,方法是将转置卷积层的输出与来自编码器的特征图在同一级别上连接:
A1 = U1 + C3
A2 = U2 + C2
A3 = U3 + C1
每次串联后,我们再次应用规则卷积,以便模型可以学习组装更精确的输出。
import numpy as npimport cv2import osimport randomimport tensorflow as tfh,w = 512,512def create_model():inputs = tf.keras.layers.Input(shape=(h,w,3))conv1 = tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same')(inputs)pool1 = tf.keras.layers.MaxPool2D()(conv1)conv2 = tf.keras.layers.Conv2D(32,(3,3),activation='relu',padding='same')(pool1)pool2 = tf.keras.layers.MaxPool2D()(conv2)conv3 = tf.keras.layers.Conv2D(64,(3,3),activation='relu',padding='same')(pool2)pool3 = tf.keras.layers.MaxPool2D()(conv3)conv4 = tf.keras.layers.Conv2D(64,(3,3),activation='relu',padding='same')(pool3)upsm5 = tf.keras.layers.UpSampling2D()(conv4)upad5 = tf.keras.layers.Add()([conv3,upsm5])conv5 = tf.keras.layers.Conv2D(32,(3,3),activation='relu',padding='same')(upad5)upsm6 = tf.keras.layers.UpSampling2D()(conv5)upad6 = tf.keras.layers.Add()([conv2,upsm6])conv6 = tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same')(upad6)upsm7 = tf.keras.layers.UpSampling2D()(conv6)upad7 = tf.keras.layers.Add()([conv1,upsm7])conv7 = tf.keras.layers.Conv2D(1,(3,3),activation='relu',padding='same')(upad7)model = tf.keras.models.Model(inputs=inputs, outputs=conv7)return modelimages = []labels = []files = os.listdir('./dataset/images/')random.shuffle(files)for f in files:img = cv2.imread('./dataset/images/' + f)parts = f.split('_')label_name = './dataset/labels/' + 'W0002_' + parts[1]label = cv2.imread(label_name,2)img = cv2.resize(img,(w,h))label = cv2.resize(label,(w,h))images.append(img)labels.append(label)images = np.array(images)labels = np.array(labels)labels = np.reshape(labels,(labels.shape[0],labels.shape[1],labels.shape[2],1))print(images.shape)print(labels.shape)images = images/255labels = labels/255model = tf.keras.models.load_model('my_model')#model = create_model() # uncomment this to create a new modelprint(model.summary())model.compile(optimizer='adam', loss='binary_crossentropy',metrics=['accuracy'])model.fit(images,labels,epochs=100,batch_size=10)model.evaluate(images,labels)model.save('my_model')
测试模型
import numpy as npimport cv2from google.colab.patches import cv2_imshowimport osimport randomimport tensorflow as tfh,w = 512,512num_cases = 10images = []labels = []files = os.listdir('./dataset/images/')random.shuffle(files)model = tf.keras.models.load_model('my_model')lowSevere = 1midSevere = 2highSevere = 4for f in files[0:num_cases]:test_img = cv2.imread('./dataset/images/' + f)resized_img = cv2.resize(test_img,(w,h))resized_img = resized_img/255cropped_img = np.reshape(resized_img,(1,resized_img.shape[0],resized_img.shape[1],resized_img.shape[2]))test_out = model.predict(cropped_img)test_out = test_out[0,:,:,0]*1000test_out = np.clip(test_out,0,255)resized_test_out = cv2.resize(test_out,(test_img.shape[1],test_img.shape[0]))resized_test_out = resized_test_out.astype(np.uint16)test_img = test_img.astype(np.uint16)grey = cv2.cvtColor(test_img, cv2.COLOR_BGR2GRAY)for i in range(test_img.shape[0]):for j in range(test_img.shape[1]):if(grey[i,j]>150 & resized_test_out[i,j]>40):test_img[i,j,1]=test_img[i,j,1] + resized_test_out[i,j]resized_test_out[i,j] = lowSevereelif(grey[i,j]<100 & resized_test_out[i,j]>40):test_img[i,j,2]=test_img[i,j,2] + resized_test_out[i,j]resized_test_out[i,j] = highSevereelif(resized_test_out[i,j]>40):test_img[i,j,0]=test_img[i,j,0] + resized_test_out[i,j]resized_test_out[i,j] = midSevereelse:resized_test_out[i,j] = 0M = cv2.moments(resized_test_out)maxMomentArea = resized_test_out.shape[1]*resized_test_out.shape[0]*highSevereprint("0th Moment = " , (M["m00"]*100/maxMomentArea), "%")test_img = np.clip(test_img,0,255)test_img = test_img.astype(np.uint8)cv2_imshow(test_img)cv2.waitKey(0)
我们使用颜色来表示缺陷的严重程度:
绿色表示存在严重缺陷的区域。
蓝色表示缺陷更严重的区域。
红色区域显示出最严重的缺陷。
以下是三个随机样本,它们显示了原始输入,地面真实情况以及由我们的模型生成的输出。
范例1:

原始图像

二进制图像(地面真相)

范例2:

原始图像

二进制图像(地面真相)

范例3:
原始图像
二进制图像(地面真相)

具有严重性的预测输出
参考文献:
https://www.cs.auckland.ac.nz/courses/compsci773s1c/lectures/ImageProcessing-html/topic3.htm#adaptive
https://medium.com/r/?url=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FImage_moment
https://medium.com/r/?url=https%3A%2F%2Ftowardsdatascience.com%2Funderstanding-semantic-segmentation-with-unet-6be4f42d4b47
https://www.sciencedirect.com/topics/materials-science/welding-defect
代码链接:https://github.com/malakar-soham/cnn-in-welding
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载3 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
