
YOLOv5永不缺席 | YOLO-Pose带来实时性高且易部署的姿态估计模型!!!


本文介绍了
YOLO-Pose,一种新的无Heatmap联合检测方法,是基于YOLOv5目标检测框架的姿态估计。现有的基于
Heatmap的两阶段方法并不是最优的,因为它们不是端到端训练的,且训练依赖于替代L1损失,不等价于最大化评估度量,即目标关键点相似度(OKS)。
YOLO-Pose可以进行端到端训练模型,并优化OKS度量本身。该模型学习了在一次前向传递中联合检测多个人的边界框及其相应的二维姿态,从而超越了自上而下和自下而上两种方法的最佳效果。
YOLO-Pose不需要对自底向上的方法进行后处理,以将检测到的关键点分组到一个骨架中,因为每个边界框都有一个相关的姿态,从而导致关键点的固有分组。与自上而下的方法不同,多个前向传播被取消,因为所有人的姿势都是局部化的。YOLO-pose在COCO验证(90.2%AP50)和测试开发集(90.3%AP50)上获得了新的最先进的结果,在没有翻转测试、多尺度测试或任何其他测试时间增加等Trick的情况超过了所有现有的自底向上的方法。本文中报告的所有实验和结果都没有任何测试时间的增加,而不像传统的方法使用翻转测试和多尺度测试来提高性能。
1YOLO-Pose方法
YOLO-Pose与其他Bottom-up的方法一样,也是一种Single Shot的方法。然而,它并不使用 Heatmaps。相反,YOLO-Pose将一个人的所有关键点与Anchor联系起来。
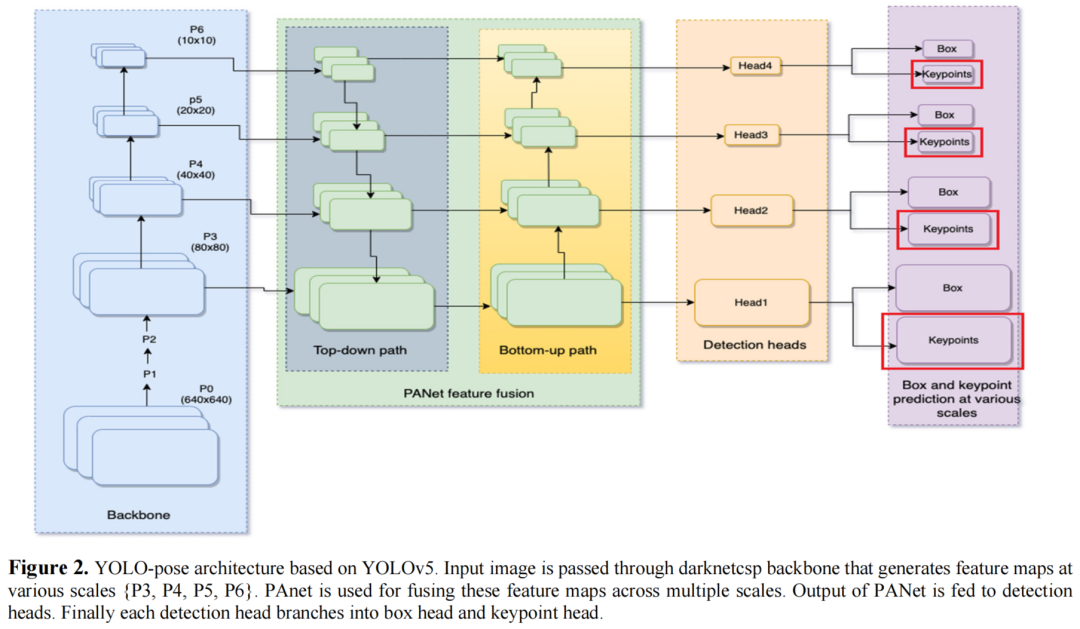
YOLO-Pose基于YOLOv5目标检测框架,也可以扩展到其他框架。YOLO-Pose也在YOLOX上在有限程度上进行了验证。图2说明了具有用于姿态估计的总体架构。
2.1 总览
YOLOv5在精度和复杂性方面都是一个非常不错的检测器。因此,选择它作为搭建的基础,并在其之上构建。YOLOv5主要关注于80个类COCO目标检测,Box head预测每个Anchor的85个元素,分别对应于80个类的边界框、目标分数和置信度得分。而对应于每个网格位置都有3个不同形状的Anchor。
对于Human Pose Estimation可以看作为一个单类的Person detection问题,每个人有17个相关的关键点,每个关键点有再次识别的位置和可信度:。所以,与一个Anchor关联的17个关键点总共有51个元素。
因此,对于每个Anchor,Keypoint Head预测51个元素,Box head预测6个元素。对于具有n个关键点的Anchor,总体预测向量定义为:

关键点置信度是基于关键点的可见性标志进行训练的。如果一个关键点是可见的或被遮挡的,那么Ground Truth置信度设置为1,否则,如果关键点在视场之外,置信度设置为0。
在推理过程中要保持关键点的置信度大于0.5。所有其他预测的关键点都被屏蔽的。预测的关键点置信度不用于评估。然而,由于网络预测了每个检测的所有17个关键点,需要过滤掉视场之外的关键点。否则,就会有置信度第的关键点导致变形的骨架。现有的基于Heatmap的Bottom-up方法不需要这样做,因为视野外的关键点一开始就不会被检测到。
YOLO-Pose使用CSP-darknet53作为Backbone,用PANet来融合来自Backbone的不同尺度的特征。接下来是4个不同尺度的Head。最后,有2个Decoupled Heads用于预测box和keypoints。
在这项工作中将YOLO-Pose的复杂性限制在150个GMACS之内,在这个范围内,YOLO-Pose能够实现具有竞争力的结果。随着复杂性的进一步增加,可以进一步弥补与Top-down方法的差距。然而,YOLO-Pose并不追求这条道路,因为YOLO-Pose的重点是实时模型。
2.2 Anchor based multi-person pose formulation
对于给定的图像,与一个人匹配的Anchor将存储其整个2D pose和bounding box。bounding box的坐标被转换为Anchor中心,而bounding box的尺寸则根据Anchor的高度和宽度进行规范化。同样,关键点位置将w.r.t转换为Anchor中心。然而,关键点并没有与Anchor的高度和宽度进行标准化。Key point和box都被预测在Anchor的中心。
由于YOLO-Pose的改进与Anchor的宽度和高度无关,所以YOLO-Pose可以很容易地扩展到Anchor Free的目标检测方法,如YOLOX, FCOS。
2.3 IoU Based Bounding-box Loss Function
大多数目标检测器优化了IoU Loss的变体,如GIoU、DIoU或CIoU Loss,而不是Distance-based Loss,因为这些损失是尺度不变的,并直接优化了评估度量本身。而YOLO-Pose使用CIoU Loss来进行bounding box监督。对于在位置和scale s上的第k个Anchor所匹配的Ground Truth bounding box,损失定义为:
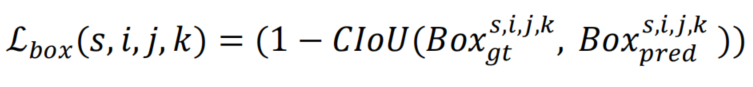
为第k个Anchor在位置(i,j)和scale s的预测框。在YOLO-Pose中,每个位置有3个Anchor,并且预测发生在4个cale上。
2.4 Human Pose Loss Function Formulation
OKS是评估关键点的比较常用的指标。传统上,Heat-map based Bottom-up方法使用L1损失来检测关键点。然而,L1损失并不一定适合获得最佳的OKS。同样,L1损失并没有考虑目标的尺度或关键点的类型。由于Heat-map是概率图,因此在基于纯Heat-map的方法中不可能使用OKS作为损失。只有当回归到关键点位置时,OKS才能被用作损失函数。耿等人使用尺度归一化L1损失进行关键点回归,这是迈向OKS损失的一步。
因此,作者直接将回归的关键点直接定义为Anchor中心,于是便可以优化评估度量本身,而不是一个surrogate loss。这里将IoU损失的概念从box扩展到关键点。
在出现关键点的情况下,目标关键点相似度(OKS)被视为IOU。OKS损失本质上是尺度不变的,比某些关键点更重要。例如,一个人头部上的关键点(眼睛、鼻子、耳朵)比他身体上的关键点(肩膀、膝盖、臀部等)受到的惩罚更多。
基于YOLOv5的Yolo姿态架构。输入图像通过CSP-darknet53主干,生成不同尺度的特征图{P3、P4、P5、P6}。PANet用于跨多个尺度融合这些特征图。PANet的输出被输入到检测头。最后,每个检测头分支到Box Head和关键点Head。
与标准的IoU损失不同,IoU损失在不重叠的情况下,其梯度会消失,而OKS损失永远不会。因此,OKS损失更类似于DIoU损失。
对应于每个边界框,存储整个姿态信息。因此,如果一个GT边界框在位置和scale s上与Anchor相匹配,将预测相对于Anchor中心的关键点。对每个关键点分别计算OKS,然后求和,给出最终的OKS损失或关键点IOU损失。

对应于每个关键点,学习一个置信参数,显示那个人是否存在一个关键点。在这里,关键点的可见性标志被用作GT。
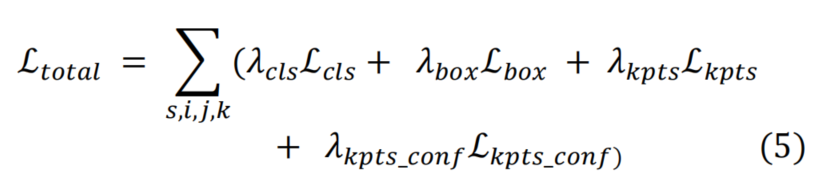
其中超参数:,,,。主要是用来平衡损失。
2.5 Test Time Augmentations
所有用于姿态估计的SOTA方法都依赖于测试时间增强(TTA)来提高性能。翻转测试和多尺度测试是两种常用的测试技术。翻转测试增加了2X的复杂度,而多尺度测试在三个尺度{0.5X, 1X, 2X}上运行推理,增加复杂度(0.25X+1X+4X)=5.25X。随着翻转测试和多尺度测试的进行,复杂性将增加5.25*2x=10.5X。
除了增加计算复杂度外,准备扩充数据本身也很昂贵。例如,在翻转测试中,需要翻转图像,这会增加系统的延迟。类似地,多尺度测试需要对每个尺度进行调整大小操作。这些操作可能非常昂贵,因为它们可能不会加速,不像CNN的操作。融合各种前向传播的输出需要额外的成本。对于嵌入式系统来说,在没有任何TTA的情况下,能够获得具有竞争力的结果才是最重要的。
因此,YOLO-Pose的所有结果都没有任何TTA。
2.6 Keypoint Outside Bounding Box
top-down的方法在遮挡下表现很差。与top-down的方法相比,YOLO-Pose的优势之一是:关键点没有限制在预测的边界框内。因此,如果关键点由于遮挡而位于边界框之外,它们仍然可以被正确地识别出来。然而,在top-down的方法中,如果人的检测不正确,姿态估计也会失败。在YOLO-Pose方法中,遮挡和不正确的框检测在一定程度上减轻了这些挑战,如图3所示。

2.7 ONNX Export for Easy Deployability
YOLO-Pose中使用的所有ops都是标准深度学习库的一部分,并且与ONNX兼容。因此,整个模型可以导出到ONNX中,这使得它很容易跨平台部署。这个独立的ONNX模型可以使用ONNXRUNTIME执行,以图像为输入,并推断图像中每个人的边界框和姿势。没有其他top-down的方法可以端到端地导出到中间的ONNX表示。
2实验结果
3.1 消融实验
1、OKS Loss vs L1 Loss
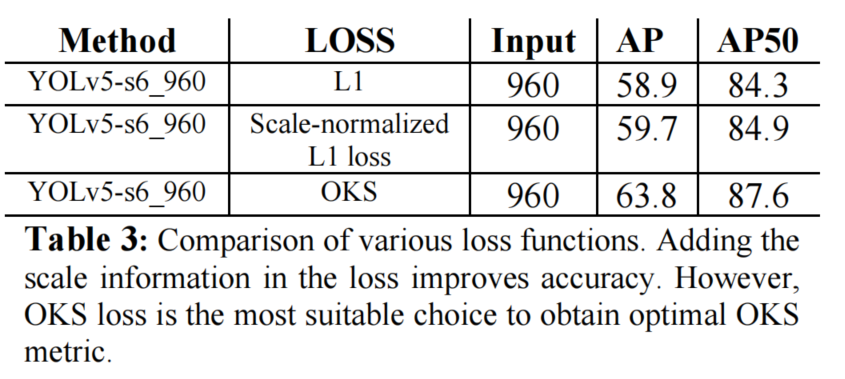
2、Across Resolution
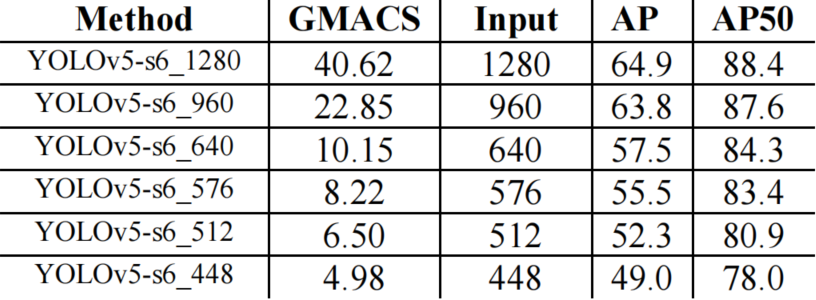
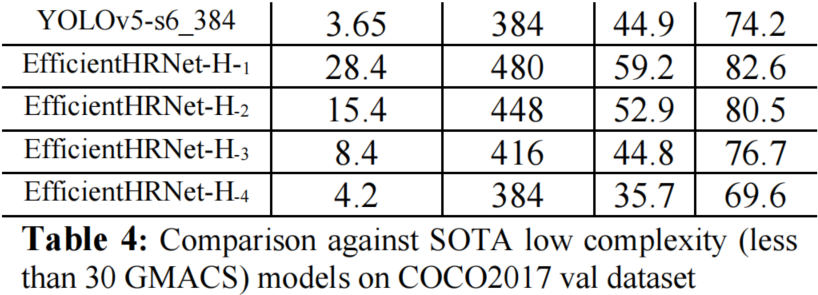
3、量化操作
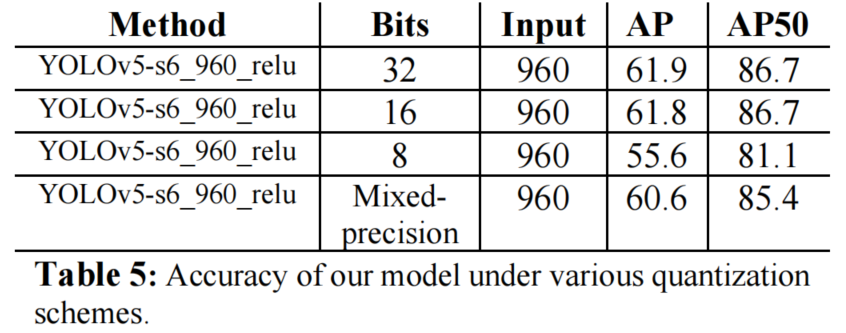
YOLOv5模型是sigmoid-weighted linear unit (SiLU)。Liu等观察到,像SiLU或HardSwish这样的无界激活函数对量化不友好,而具有ReLUX激活的模型由于其具有有限性,对量化具有鲁棒性。
因此,用ReLU激活对模型进行了重新训练。我们观察到从SiLU到ReLU的活化降低了1-2%。我们称这些模型为YOLOv5_relu。
3.2 COCO结果
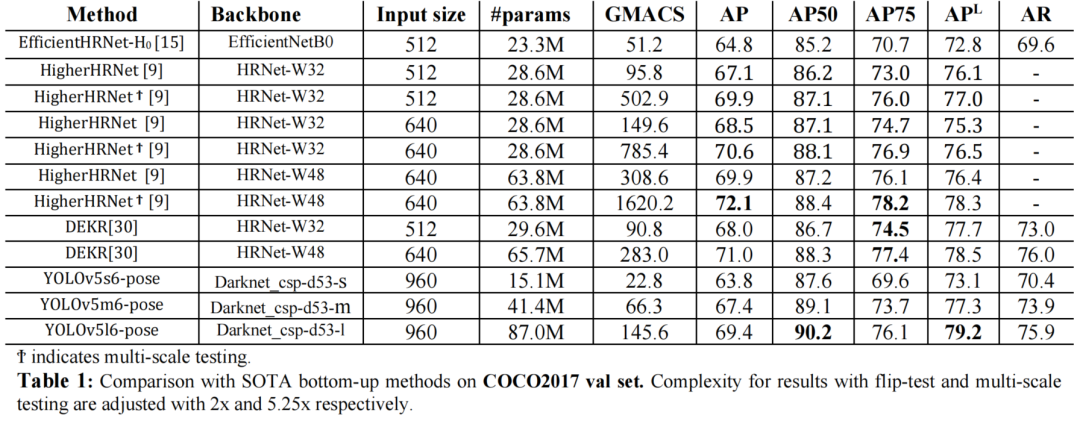
3参考
[1].YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object
Keypoint Similarity Loss
4推荐阅读
Transformer崛起| TopFormer打造Arm端实时分割与检测模型,完美超越MobileNet!
阿里巴巴提出USI 让AI炼丹自动化了,训练任何Backbone无需超参配置,实现大一统!
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
