
这4款数据自动化探索 Python 神器,解决99%的数据分析问题!
探索性数据分析是一种非常重要的数据探索技术,用于了解数据的各个方面,这是执行任何机器学习或深度学习任务之前最重要的步骤之一。
探索性数据分析可以帮助识别明显的错误,区分数据集中的异常,发现重要元素,发现内部信息的设计并提供新的知识。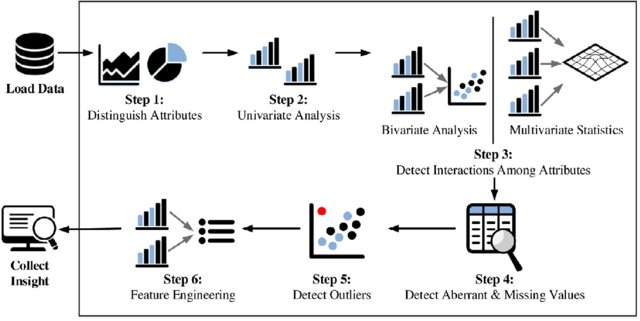
背景
在任何机器学习项目的生命周期中,我们在数据分析、特征选择、特征工程等环节耗费时间占整个项目的 60% 的以上,一方面它是数据科学项目中最重要的部分,另一方面它是必须要进行的,比如清理数据、处理缺失值、处理异常值、处理不平衡的数据集、等等,高效完成数据探索任务势在必行。
自动化探索性数据分析
今天我给大家分享4款自动化探索数据分析的顶级 Python 库,列表如下:
dtale pandas profiling sweetviz autoviz
1、D-tale
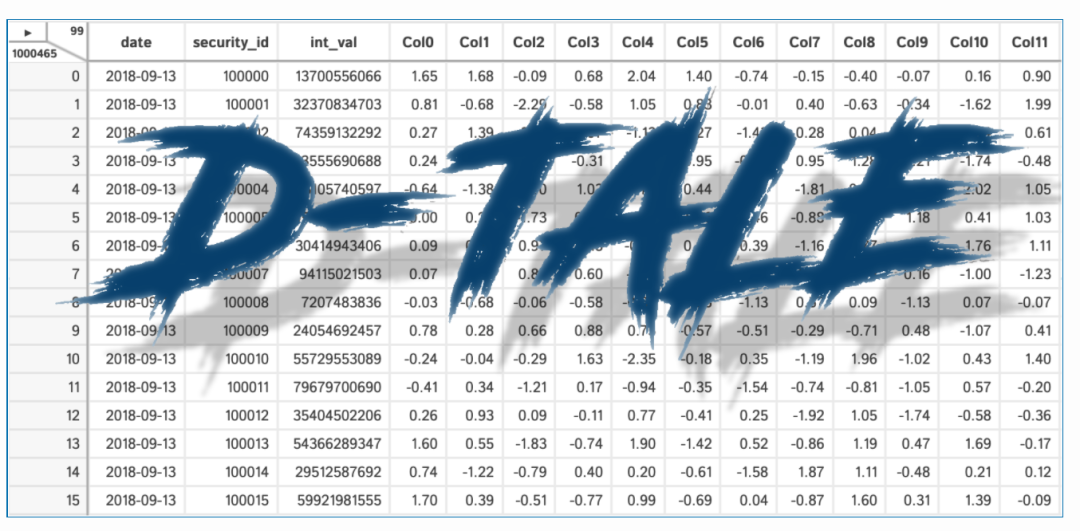 D-tale 是一个在 2020 年 2 月推出的库,可让我们轻松可视化 pandas 数据框。它具有许多功能,对于探索性数据分析非常方便、支持交互式绘图、3d 绘图、热图、特征之间的相关性、构建自定义列等等。
D-tale 是一个在 2020 年 2 月推出的库,可让我们轻松可视化 pandas 数据框。它具有许多功能,对于探索性数据分析非常方便、支持交互式绘图、3d 绘图、热图、特征之间的相关性、构建自定义列等等。
安装
pip install dtale
首先,我们分享一个 d-tale 的案例
import dtale
import pandas as pd
df = pd.read_csv("data.csv")
d = dtale.show(df)
d.open_browser()
上述代码的输出如下所示: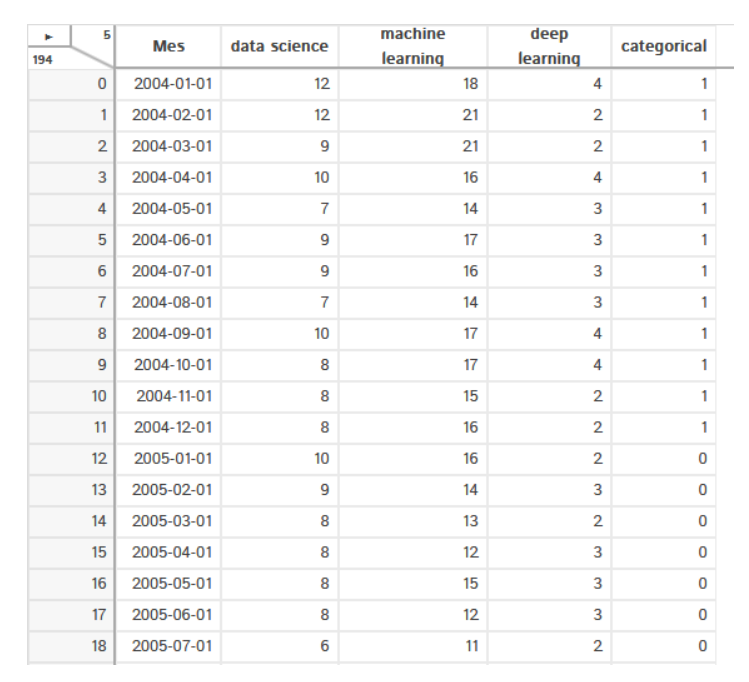 它提供许多选项,例如对数据进行排序、描述数据集、列分析等等,也可以自行查看此功能。
它提供许多选项,例如对数据进行排序、描述数据集、列分析等等,也可以自行查看此功能。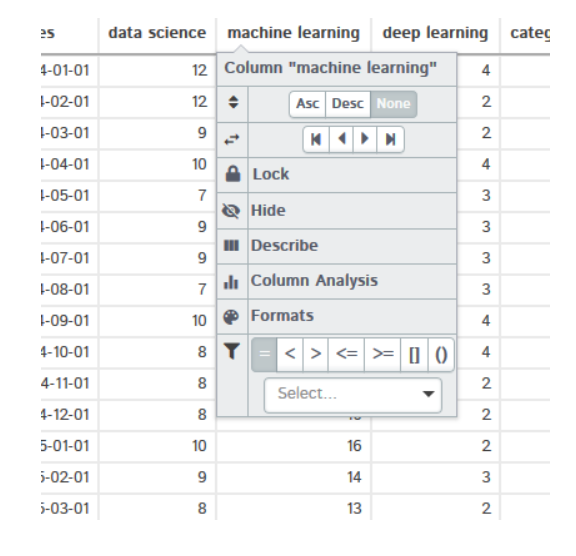 如果单击"Describe",则会显示所选列的统计分析,例如平均值、中位数、最大值、最小值方差、标准差、四分位数等等。
如果单击"Describe",则会显示所选列的统计分析,例如平均值、中位数、最大值、最小值方差、标准差、四分位数等等。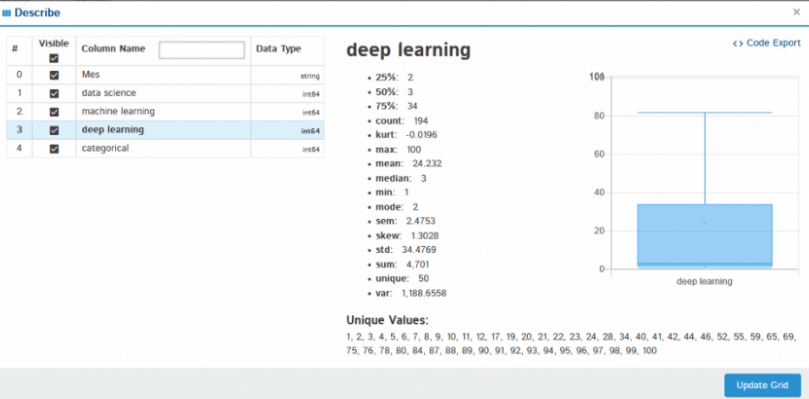 也可以自行尝试其他功能,例如列分析、格式、过滤器。
也可以自行尝试其他功能,例如列分析、格式、过滤器。 如何相互关联呢?
如何相互关联呢?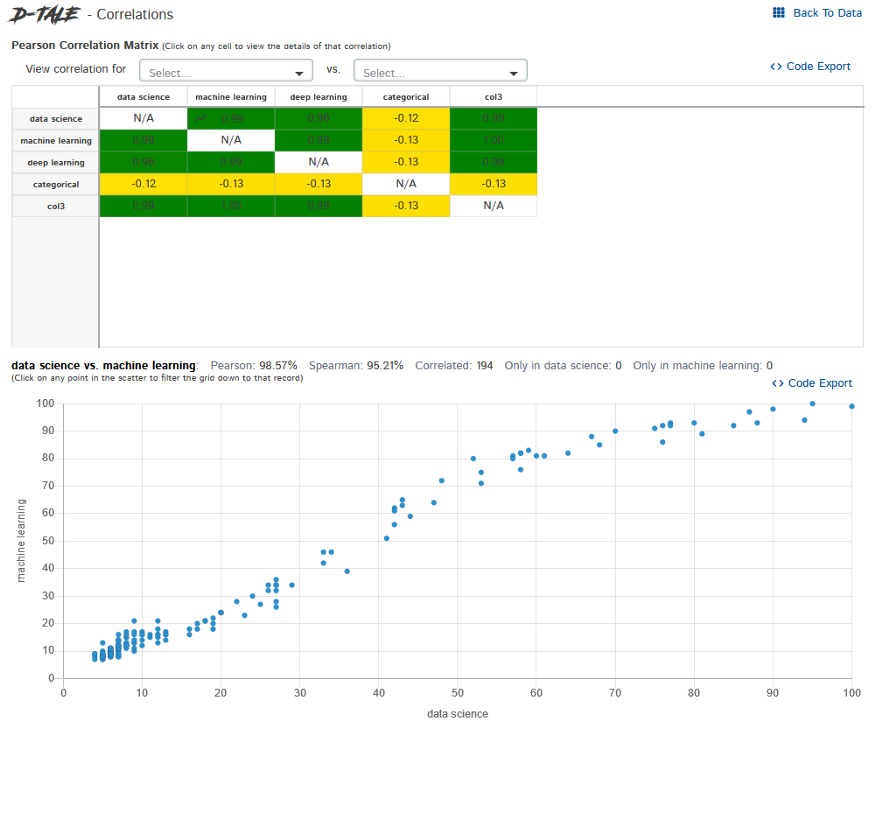 图表 - 建立自定义图表,如折线图、条形图、饼图、堆叠图、散点图、地质图等。
图表 - 建立自定义图表,如折线图、条形图、饼图、堆叠图、散点图、地质图等。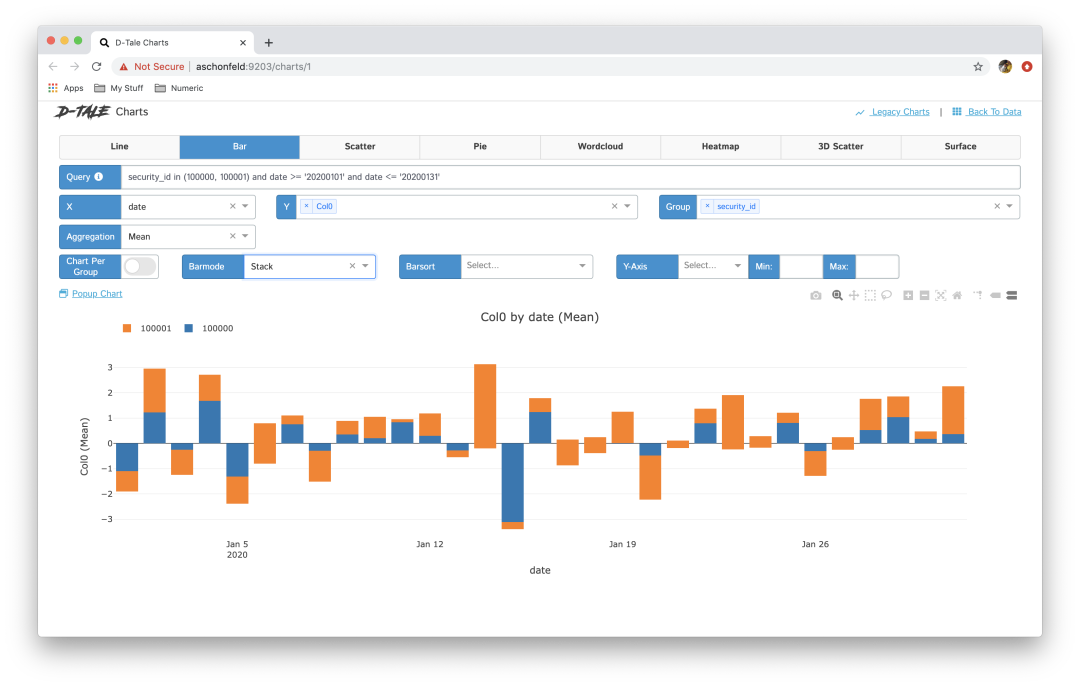 这个工具非常方便,与使用传统的机器学习库(如 pandas、matplotlib 等)相比,它探索性数据分析更快。
这个工具非常方便,与使用传统的机器学习库(如 pandas、matplotlib 等)相比,它探索性数据分析更快。
2、Pandas Profiling
 它是一个用 python 编写的开源库,生成交互式 HTML 报告并描述数据集的各个方面。关键功能包括处理缺失值、数据集的统计数据(如平均值、众数、中位数、偏度、标准差等),以及直方图和相关性等图表。
它是一个用 python 编写的开源库,生成交互式 HTML 报告并描述数据集的各个方面。关键功能包括处理缺失值、数据集的统计数据(如平均值、众数、中位数、偏度、标准差等),以及直方图和相关性等图表。
安装
pip install pandas-profiling
让我们深入研究使用这个库的探索性数据分析。使用示例数据集从 pandas 分析开始:
#importing required packages
import pandas as pd
import pandas_profiling
import numpy as np
#importing the data
df = pd.read_csv('sample.csv')
#descriptive statistics
pandas_profiling.ProfileReport(df)
下面是上述代码输出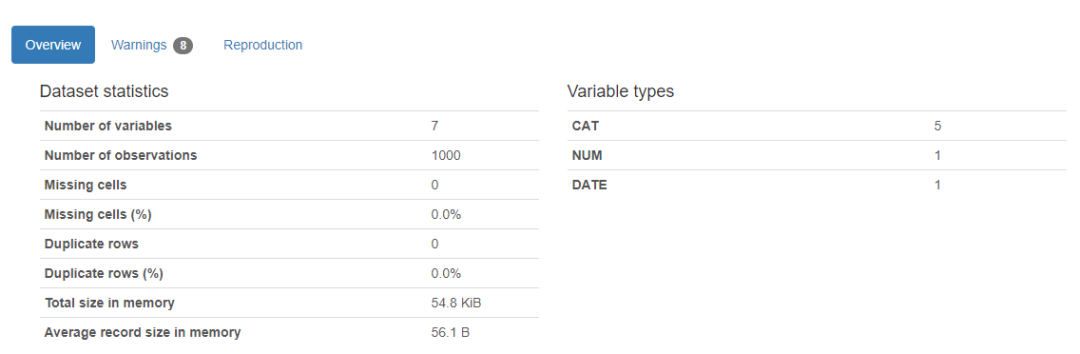
这是一个数据分析报告,它返回数据集中的变量数量、行数、数据集中缺失的单元格、缺失单元格的百分比、重复行的数量和百分比。缺失和重复的单元格数据对于我们的分析非常重要,因为它描述了数据集的更广泛情况。该报告还显示内存的总大小。
变量部分显示特定列的分析。例如对于分类变量,将出现以下输出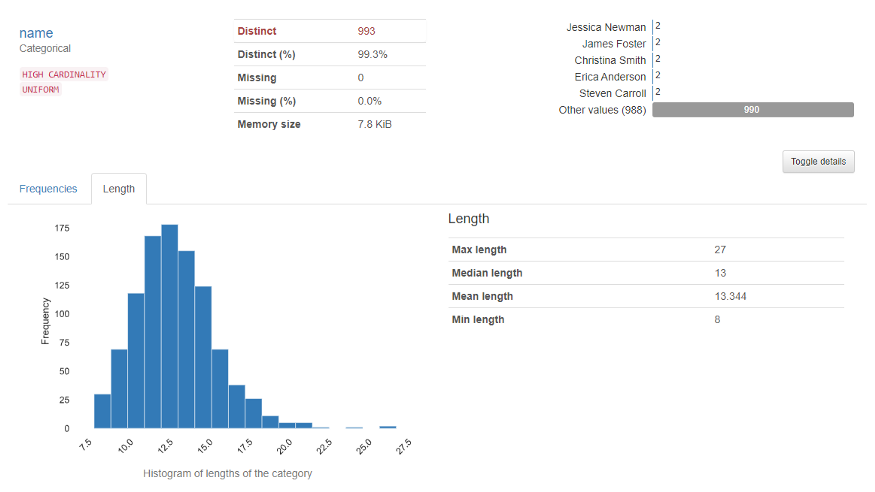
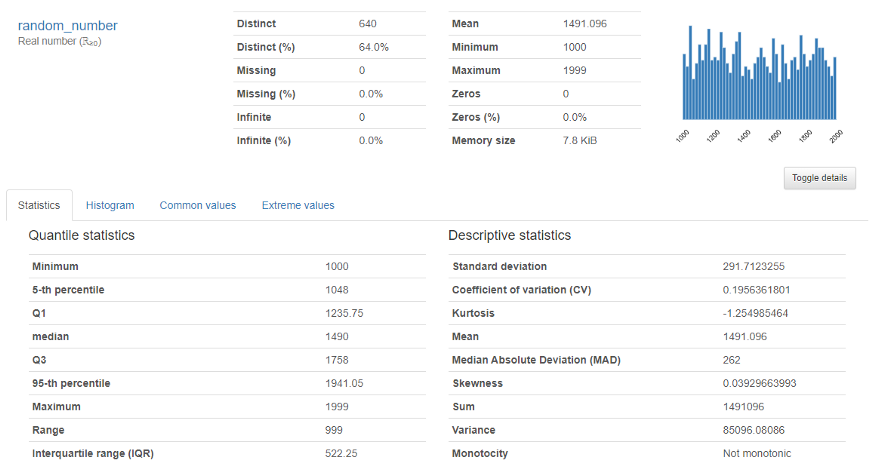 它提供对数值变量的深入分析,例如分位数、均值、中位数和、方差、单调性、范围、峰度、四分位间距等等。
它提供对数值变量的深入分析,例如分位数、均值、中位数和、方差、单调性、范围、峰度、四分位间距等等。
描述变量如何相互关联,这些数据对于数据科学家来说是非常必要的。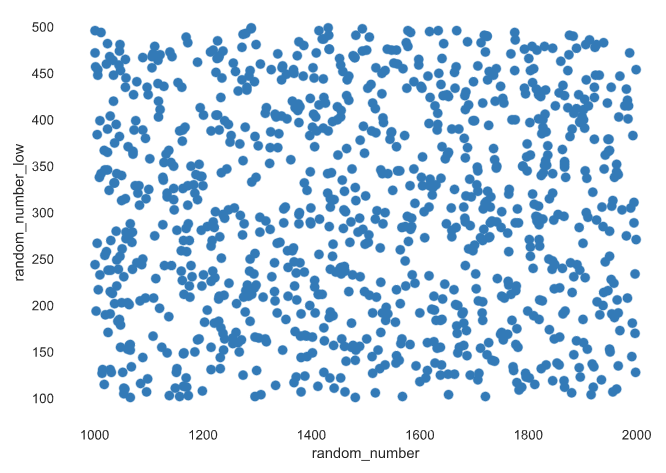
3、Sweetviz
Sweetviz 是一个开源的 Python 库,用于获得可视化效果,只需几行代码即可用于探索性数据分析。该库可用于可视化变量和比较数据集。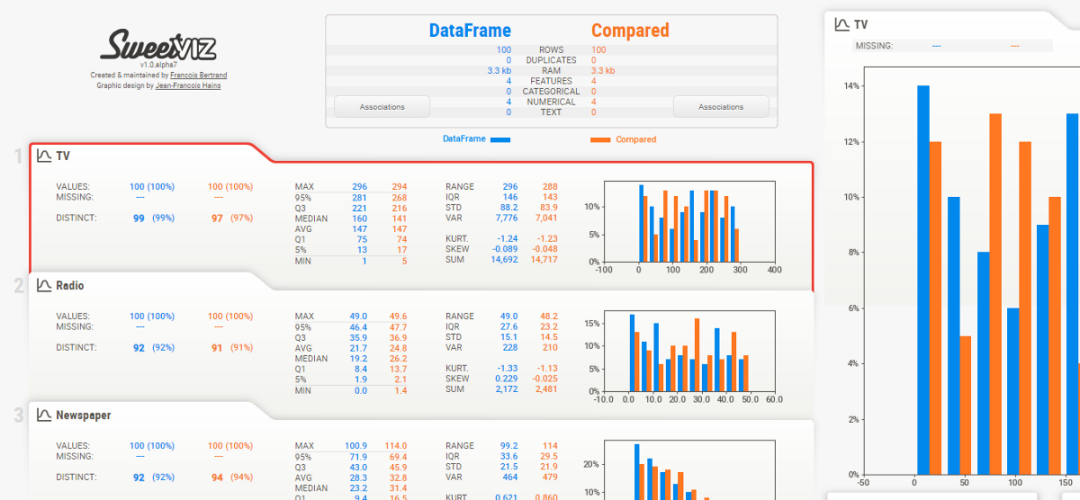
安装
pip install sweetviz
让我们深入研究使用这个库的探索性数据分析,使用示例数据集开始
import sweetviz
import pandas as pd
df = pd.read_csv('sample.csv')
my_report = sweetviz.analyze([df,'Train'], target_feat='SalePrice')
my_report.show_html('FinalReport.html')
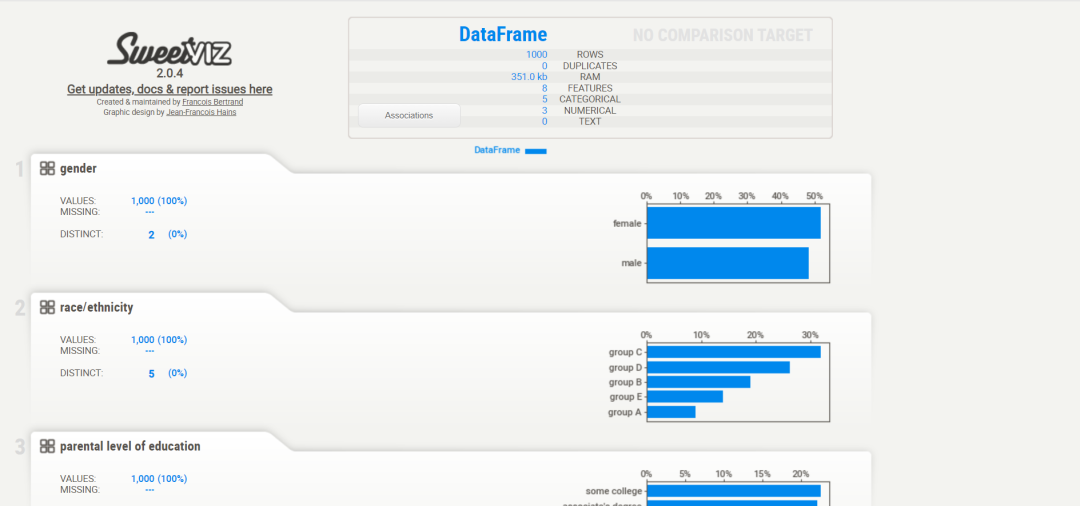
4、Autoviz
Autoviz 代表自动可视化,只需几行代码,就可以使用任意大小的数据集进行可视化。 安装
安装
pip install autoviz
可视化
from autoviz.AutoViz_Class import AutoViz_Class
AV = AutoViz_Class()
df = AV.AutoViz('sample.csv')
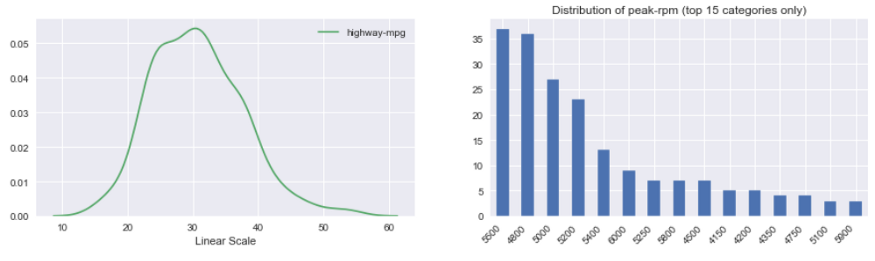
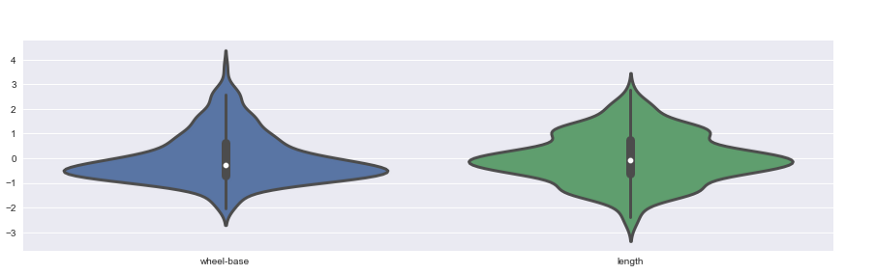
我们的文章到此就结束啦~记得点赞
如何找到我: