
阿里云AI发女朋友啦!
点击上方蓝色“程序猿DD”,选择“设为星标”
回复“资源”获取独家整理的学习资料!

你,要不要摆脱技术人单身率高的魔咒?
这里有一份相亲战斗力评估指数,阿里云帮你测一测以后还能不能找到对象。
据说是借助哥伦比亚大学多年研究相亲找对象的心血,通过几个简单的特征来做评估。
具体模(yuan)型(fen)的测试页面扫下方二维码即可试玩~
在正式开始实验之前,我们需要寻找一个简单好用方便上手的工具,这里我推荐一波阿里云的PAI-DSW探索者版,它对于个人开发者是免费的,还有免费GPU资源可以使用,实验的数据更会免费保存30天。
点击这里(链接:https://dsw-dev.data.aliyun.com/#/)只要登陆就可直接使用。今天,我们就会通过这个工具来探索人性的奥秘,走进两性关系的神秘空间,嘿嘿嘿。
整个实验的数据收集于一个线下快速相亲的实验。(链接:https://faculty.chicagobooth.edu/emir.kamenica/documents/genderDifferences.pdf)这个实验中,参与者被要求参加多轮与异性进行的快速相亲,每轮相亲持续4分钟,在4分钟结束后,参与者双方会被询问是否愿意与他们的对象再见面。只有当双方都回答了“是”的时候,这次相亲才算是配对成功。
同时,参与者也会被要求通过以量化的方式从外观吸引力,真诚度,智商,风趣程度,事业心,兴趣爱好这六个方向来评估他们的相亲对象。
这个数据集也包含了很多参加快速相亲的参与者的其他相关信息,比如地理位置,喜好,对于理想对象的偏好,收入水平,职业以及教育背景等等。关于整个数据集的具体特征描述可以参考这个文件。(链接:https://pai-public-data.oss-cn-beijing.aliyuncs.com/speed_dating/Speed%20Dating%20Data%20Key.doc)
本次我们实验的目的主要是为了找出,当一个人在参加快速相亲时,到底会有多高的几率能够遇到自己心动的人并成功牵手。
在我们建模分析探索人性的秘密之前,让我们先读入数据,来看看我们的数据集长什么样。
import pandas as pd
df = pd.read_csv('Speed Dating Data.csv', encoding='gbk')
print(df.shape)
通过观察,我们不难发现,在这短短的两年中,这个实验的小酒馆经历了8000多场快速相亲的实验。由此我们可以非常轻易的推断出,小酒馆的老板应该赚的盆满钵满(大雾)
然后从数据的宽度来看,我们会发现一共有接近200个特征。
关于每个特征的具体描述大家可以参考这篇文档链接:https://pai-public-data.oss-cn-beijing.aliyuncs.com/speed_dating/Speed%20Dating%20Data%20Key.doc。
然后我们再观察数据的完整度,看看是否有缺失数据。
percent_missing = df.isnull().sum() * 100 / len(df)
missing_value_df = pd.DataFrame({
'column_name': df.columns,
'percent_missing': percent_missing
})
missing_value_df.sort_values(by='percent_missing')通过以上代码,我们不难发现,其实还有很多的特征是缺失的。这一点在我们后面做分析和建模的时候,都需要关注到。因为一旦一个特征缺失的数据较多,就会导致分析误差变大或者模型过拟合/精度下降。看完数据的完整程度,我们就可以继续往下探索了。
然后第一个问题就来了,在这8000多场的快速相亲中,到底有多少场相亲成功为参加的双方找到了合适的伴侣的?带着这个问题,我们就可以开始我们的第一个探索性数据分析。
# 多少人通过Speed Dating找到了对象
plt.subplots(figsize=(3,3), dpi=110,)
# 构造数据
size_of_groups=df.match.value_counts().values
single_percentage = round(size_of_groups[0]/sum(size_of_groups) * 100,2)
matched_percentage = round(size_of_groups[1]/sum(size_of_groups)* 100,2)
names = [
'Single:' + str(single_percentage) + '%',
'Matched' + str(matched_percentage) + '%']
# 创建饼图
plt.pie(
size_of_groups,
labels=names,
labeldistance=1.2,
colors=Pastel1_3.hex_colors
)
plt.show()
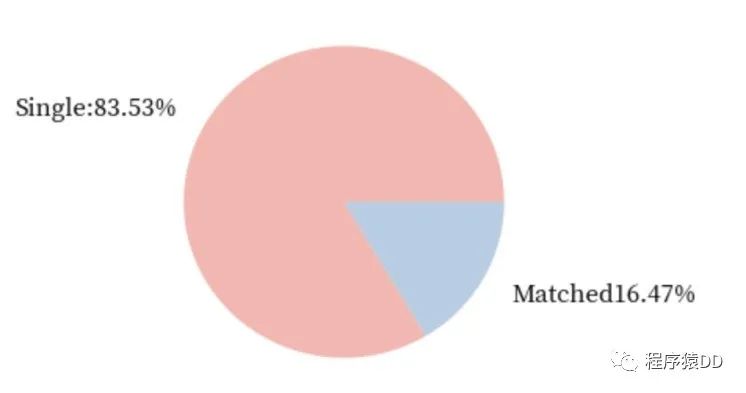
从上边的饼图我们可以发现,真正通过快速相亲找到对象的比率仅有16.47%。
然后我们就迎来了我们的第二个问题,这个比率和参加的人的性别是否有关呢?这里我们也通过Pandas自带的filter的方式
df[df.gender == 0]
来筛选数据集中的性别。通过阅读数据集的文档,我们知道0代表的是女生,1代表的是男生。然后同理,我们执行类似的代码
# 多少女生通过Speed Dating找到了对象
plt.subplots(figsize=(3,3), dpi=110,)
# 构造数据
size_of_groups=df[df.gender == 0].match.value_counts().values # 男生只需要吧0替换成1即可
single_percentage = round(size_of_groups[0]/sum(size_of_groups) * 100,2)
matched_percentage = round(size_of_groups[1]/sum(size_of_groups)* 100,2)
names = [
'Single:' + str(single_percentage) + '%',
'Matched' + str(matched_percentage) + '%']
# 创建饼图
plt.pie(
size_of_groups,
labels=names,
labeldistance=1.2,
colors=Pastel1_3.hex_colors
)
plt.show()
来找出女生和男生分别在快速相亲中找到对象的几率的。
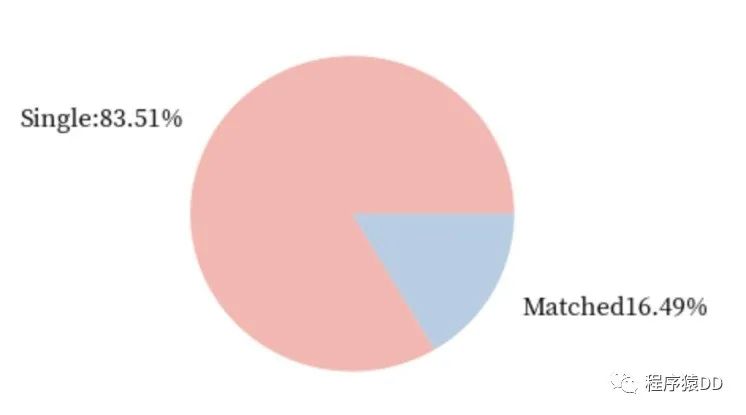
女生的几率:
男生的几率:
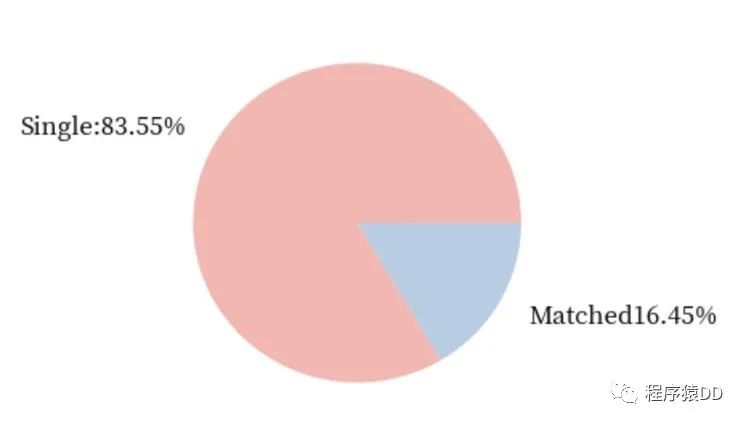
不难发现,在快速相亲中,女生相比于男生还是稍微占据一些优势的。女生成功匹配的几率比男生成功匹配的几率超出了0.04。
然后第二个问题来了:是什么样的人在参加快速相亲这样的活动呢?真的都是大龄青年(年龄大于30)嘛?这个时候我们就可以通过对参加人群的年龄分布来做一个统计分析。
# 年龄分布
age = df[np.isfinite(df['age'])]['age']
plt.hist(age,bins=35)
plt.xlabel('Age')
plt.ylabel('Frequency')
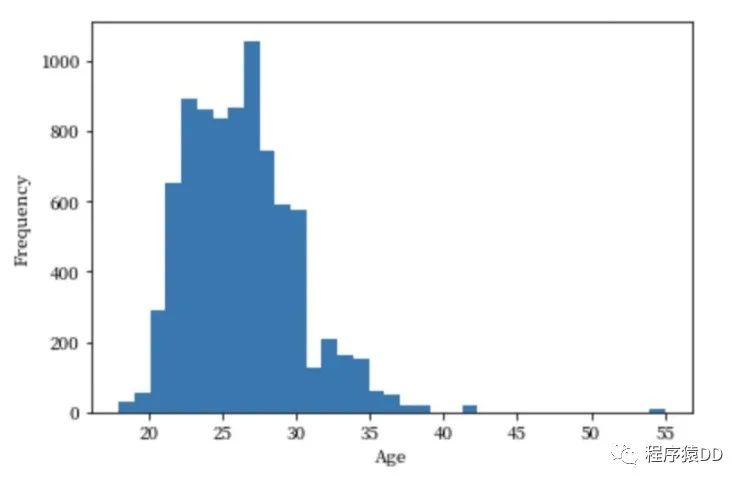
不难发现,参加快速相亲的人群主要是22~28岁的群体。这点与我们的预期有些不太符合,因为主流人群并不是大龄青年。接下来的问题就是,年龄是否会影响相亲的成功率呢?和性别相比,哪个对于成功率的影响更大?这两个问题在本文就先埋下一个伏笔,不一一探索了,希望阅读文章的你能够自己探索。
但是这里可以给出一个非常好用的探索相关性的方式叫做数据相关性分析。通过阅读数据集的描述,我已经为大家选择好了一些合适的特征去进行相关性分析。这里合适的定义是指:1. 数据为数字类型,而不是字符串等无法量化的值。2.数据的缺失比率较低
date_df = df[[
'iid', 'gender', 'pid', 'match', 'int_corr', 'samerace', 'age_o',
'race_o', 'pf_o_att', 'pf_o_sin', 'pf_o_int', 'pf_o_fun', 'pf_o_amb',
'pf_o_sha', 'dec_o', 'attr_o', 'sinc_o', 'intel_o', 'fun_o', 'like_o',
'prob_o', 'met_o', 'age', 'race', 'imprace', 'imprelig', 'goal', 'date',
'go_out', 'career_c', 'sports', 'tvsports', 'exercise', 'dining',
'museums', 'art', 'hiking', 'gaming', 'clubbing', 'reading', 'tv',
'theater', 'movies', 'concerts', 'music', 'shopping', 'yoga', 'attr1_1',
'sinc1_1', 'intel1_1', 'fun1_1', 'amb1_1', 'attr3_1', 'sinc3_1',
'fun3_1', 'intel3_1', 'dec', 'attr', 'sinc', 'intel', 'fun', 'like',
'prob', 'met'
]]
# heatmap
plt.subplots(figsize=(20,15))
ax = plt.axes()
ax.set_title("Correlation Heatmap")
corr = date_df.corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
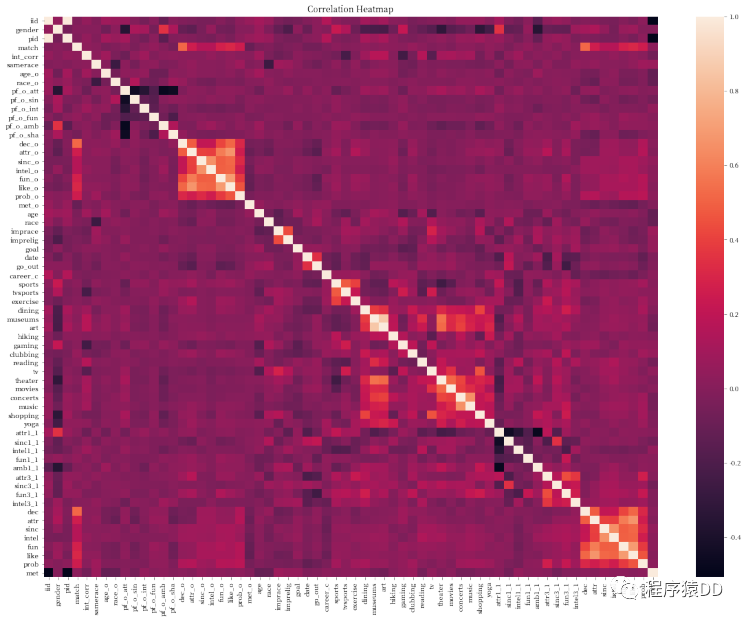
通过上面这张图这张相关性分析的热力图,我们可以先关注一些特别亮的和特别暗的点。比如我们可以发现,在 pf_o_att这个表示相亲对象给出的外观吸引力这个特征上,和其他相亲对象给出的评分基本都是严重负相关的,除了pf_o_fun这一特征。由此我们可以推断出两个点:
大家会认为外观更加吸引人的人在智商,事业心,真诚度上表现会相对较差。换句话说,可能就是颜值越高越浪
幽默风趣的人更容易让人觉得外观上有吸引力,比如下面这位幽默风趣的男士(大雾):

然后我们再看看我们最关注的特征 match,和这一个特征相关性比较高的特征是哪几个呢?不难发现,其实就是'attr_o','sinc_o','intel_o','fun_o','amb_o','shar_o'这几个特征,分别是相亲对方给出的关于外观,真诚度,智商,风趣程度,事业线以及兴趣爱好的打分。接下来我们就可以根据这个来进行建模了。首先我们将我们的特征和结果列都放到一个Dataframe中,然后再去除含有空值的纪录。最后我们再分为X和Y用来做训练。当然分为X,y之后,由于我们在最开始就发现只有16.47%的参与场次中成功匹配了,所以我们的数据有严重的不均衡,这里我们可以用SVMSMOTE(链接:https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.SVMSMOTE.html)来增加一下我们的数据量避免模型出现过度拟合。
# preparing the data
clean_df = df[['attr_o','sinc_o','intel_o','fun_o','amb_o','shar_o','match']]
clean_df.dropna(inplace=True)
X=clean_df[['attr_o','sinc_o','intel_o','fun_o','amb_o','shar_o',]]
y=clean_df['match']
oversample = imblearn.over_sampling.SVMSMOTE()
X, y = oversample.fit_resample(X, y)
# 做训练集和测试集分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y)
数据准备好之后,我们就可以进行模型的构建和训练了。通过以下代码,我们可以构建一个简单的逻辑回归的模型,并在测试集上来测试。
# logistic regression classification model
model = LogisticRegression(C=1, random_state=0)
lrc = model.fit(X_train, y_train)
predict_train_lrc = lrc.predict(X_train)
predict_test_lrc = lrc.predict(X_test)
print('Training Accuracy:', metrics.accuracy_score(y_train, predict_train_lrc))
print('Validation Accuracy:', metrics.accuracy_score(y_test, predict_test_lrc))
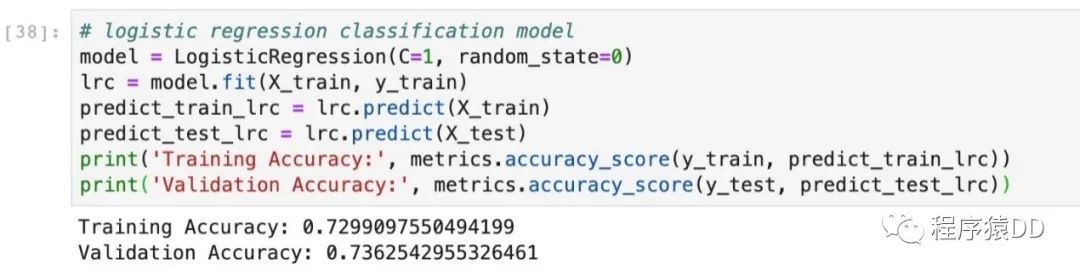
我们可以看到结果为0.83左右,这样我们就完成了一个预测在快速相亲中是否能够成功配对的机器学习模型。
针对这个模型,数据科学老司机我还专门制作了一个小游戏页面),来测试你的相亲战斗力指数。快来体验吧:
https://tianchi.aliyun.com/specials/promotion/dsw-hol?referFrom=mvp