
阿里云这个AI神器杀疯了!
点击下方 卡片 ,关注“ CVer ”公众号
AI/CV重磅干货,第一时间送达
2023年是AIGC大爆发的一年!尤其是视频生成(Video Generation)领域已经成为当前各大公司、高校发力的重点目标。
视频生成之所以如此重要,是因为它能够帮助人们快速创建各种类型的视频内容,在教育、娱乐、自动驾驶、元宇宙等行业都能发挥出强大作用。 2023年视频生成商用级代表性产品有 :Runway公司的Gen-2(当前明星产品)、Pika Labs推出的Pika1.0(2023年大黑马) 、Stability AI 开源的Stable Video Diffusion(正式从图片生成进军到视频生成)、谷歌于2023年底发布的VideoPoet视频生成大语言模型,能够执行各种视频生成任务。 

 重磅!Animate Anyone上线啦 就在最近,阿里云通义千问APP正式上线了Animate Anyone! 上传一张真人、动漫、卡通等角色照片,即可免费生成一段舞蹈视频。目前该功能创作的视频正在国内外各大社交平台上刷屏(今天还看到很多好友在朋友圈分享用通义千问APP生成的"魔性视频")。 该如何使用?你可以直接在手机应用商店中下载通义千问APP,然后在APP内输入回复「通义舞王」、「全民舞王」或者「Animate Anyone」关键词后,即可进入体验页面。
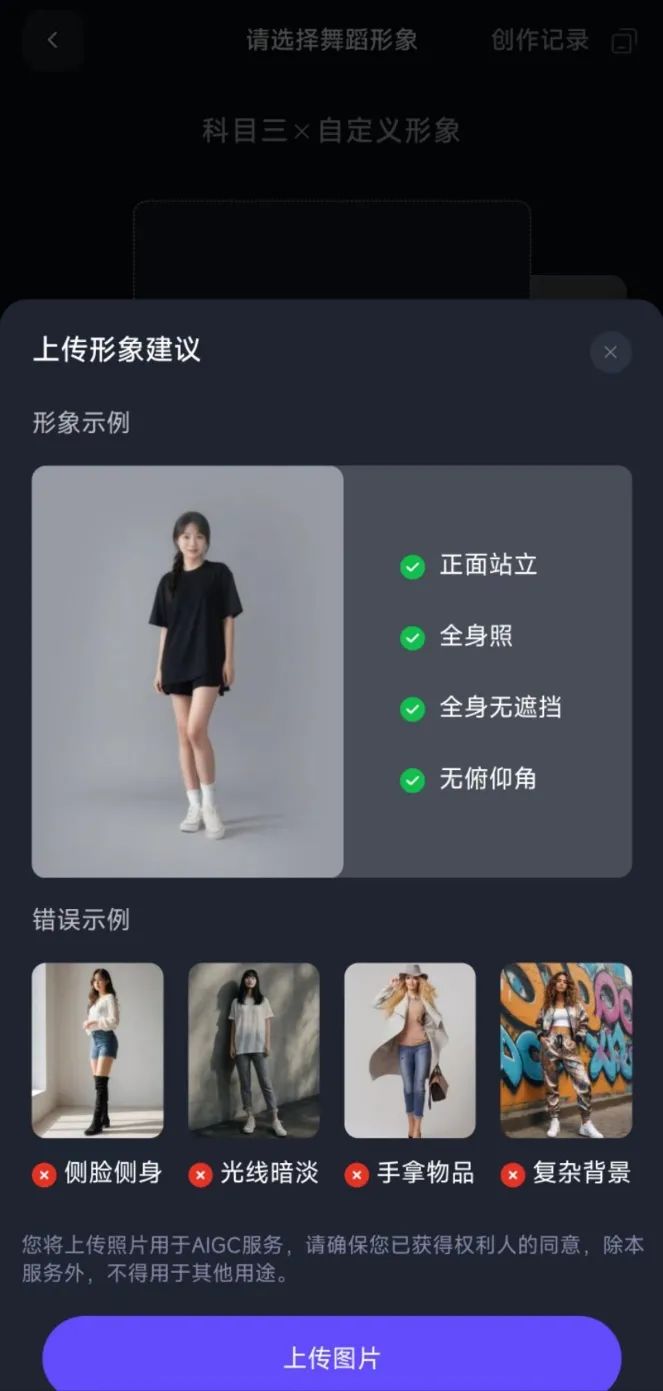
重磅!Animate Anyone上线啦 就在最近,阿里云通义千问APP正式上线了Animate Anyone! 上传一张真人、动漫、卡通等角色照片,即可免费生成一段舞蹈视频。目前该功能创作的视频正在国内外各大社交平台上刷屏(今天还看到很多好友在朋友圈分享用通义千问APP生成的"魔性视频")。 该如何使用?你可以直接在手机应用商店中下载通义千问APP,然后在APP内输入回复「通义舞王」、「全民舞王」或者「Animate Anyone」关键词后,即可进入体验页面。  通义千问目前为用户提供了12种热门舞蹈模板 ,包括现在爆火全网的科目三,还有DJ慢摇、鬼步舞、兔子舞等等。当你选择目标舞蹈模板后,按照官方【上传形象建议】上传照片,然后耐心等待,即可生成逼真的舞蹈视频。
通义千问目前为用户提供了12种热门舞蹈模板 ,包括现在爆火全网的科目三,还有DJ慢摇、鬼步舞、兔子舞等等。当你选择目标舞蹈模板后,按照官方【上传形象建议】上传照片,然后耐心等待,即可生成逼真的舞蹈视频。 温馨提示:现在试用该功能的人很多,生成时间会比较长,所以你上传照片后,可以离开生成页面,当后台处理好后,会自动给你发通知。
 正常真人照片的测试应该很常见了,这里我直接从网上找了一张兵马俑的照片,让我们来看看测试效果究竟如何?
正常真人照片的测试应该很常见了,这里我直接从网上找了一张兵马俑的照片,让我们来看看测试效果究竟如何? 

蕾姆手办测试图片
蕾姆手办跳【爱你】视频演示 来看看龙珠中的孙悟空跳兔子舞: 龙珠孙悟空测试图片 孙悟空跳【兔子舞】视频演示 再看看火影忍者中的鸣人跳秧歌舞:
龙珠孙悟空测试图片 孙悟空跳【兔子舞】视频演示 再看看火影忍者中的鸣人跳秧歌舞: 

Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
主页链接:
https://humanaigc.github.io/animate-anyone/
代码链接:
https://github.com/HumanAIGC/AnimateAnyone
论文链接:
https://arxiv.org/abs/2311.17117
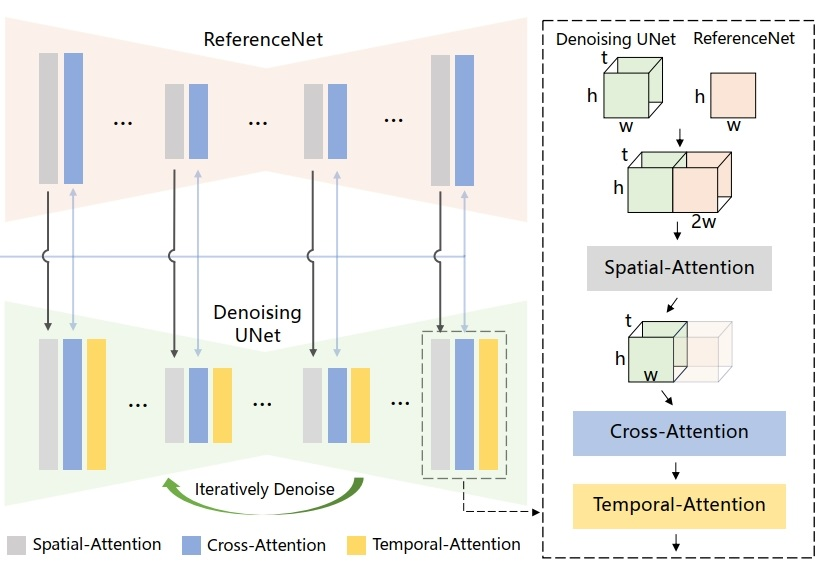
简单来说,本工作继承了来自Stable Diffusion的网络设计和预训练权重,并修改去噪U-Net以适应多帧输入。与之前的工作相比,首先,它有效地保持了视频中人物外观的空间和时间一致性。其次,它生成的高清视频不会出现时间抖动或闪烁等问题。第三,它能够将任何角色图像动画化为视频,不受特定领域的限制。 整体网络结构如下图所示,姿态序列最初使用Pose Guider进行编码,并与多帧噪声融合,然后由去噪UNet进行视频生成的去噪过程。去噪UNet的计算块由空间注意力、交叉注意力和时间注意力组成,如下图右侧虚线框所示。参考图像的整合涉及两个方面。首先,通过ReferenceNet提取细节特征,并将其用于空间注意力。其次,通过CLIP图像编码器提取语义特征进行交叉注意力。时间注意力在时间维度上运作。最后,VAE解码器将结果解码为视频片段。 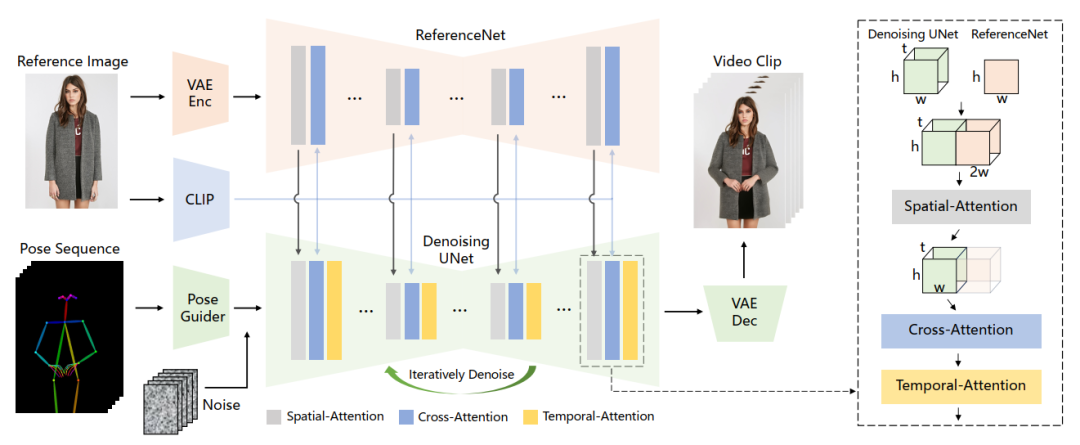
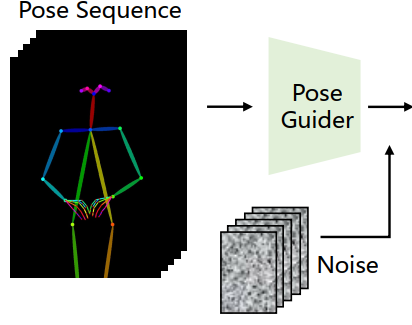
注:这里的姿态序列是利用DWPose提取的。
 Temporal layer 为了实现时间稳定性,本工作引入时间层(Temporal layer)来对多个帧之间的关系进行建模,从而在模拟连续且平滑的时间运动过程的同时保留视觉质量的高分辨率细节。时间层在Res-Trans块内的空间注意力和交叉注意力分量之后被整合。 时间层的设计灵感来自AnimateDiff。具体来说,对于特征图x∈R^b×t×h×w×c,首先将其reshape为x∈R^(b×h×w)×t×c,然后进行时间注意力,即沿着维度t的自注意力。来自时间层的特征通过残差连接被合并到原始特征中。这种设计与下面要介绍的训练方法相一致。时间层仅应用于去噪UNet的Res-Trans块内。对于ReferenceNet,它计算单个参考图像的特征,并且不参与时间建模。由于姿势引导器实现了角色连续运动的可控性,实验表明,时间层确保了时间的平滑性和外观细节的连续性,从而无需复杂的运动建模。 训练策略 训练过程分为两个阶段。
Temporal layer 为了实现时间稳定性,本工作引入时间层(Temporal layer)来对多个帧之间的关系进行建模,从而在模拟连续且平滑的时间运动过程的同时保留视觉质量的高分辨率细节。时间层在Res-Trans块内的空间注意力和交叉注意力分量之后被整合。 时间层的设计灵感来自AnimateDiff。具体来说,对于特征图x∈R^b×t×h×w×c,首先将其reshape为x∈R^(b×h×w)×t×c,然后进行时间注意力,即沿着维度t的自注意力。来自时间层的特征通过残差连接被合并到原始特征中。这种设计与下面要介绍的训练方法相一致。时间层仅应用于去噪UNet的Res-Trans块内。对于ReferenceNet,它计算单个参考图像的特征,并且不参与时间建模。由于姿势引导器实现了角色连续运动的可控性,实验表明,时间层确保了时间的平滑性和外观细节的连续性,从而无需复杂的运动建模。 训练策略 训练过程分为两个阶段。 第一阶段 ,使用单独的视频帧来执行训练。在去噪UNet中,暂时排除temporal layer,模型以单帧噪声作为输入。ReferenceNet和Pose Guider在此阶段训练。参考图像是从整个视频片段中随机选择的。基于来自Stable Diffusion的预训练权重来初始化去噪UNet和ReferenceNet的模型。Pose Guider使用高斯权重进行初始化,但最终投影层使用零卷积。VAE的编码器和解码器以及CLIP图像编码器的权重都保持不变。该阶段的优化目标是使模型能够在给定参考图像和目标姿态的条件下生成高质量的动画图像。 第二阶段 ,将temporal layer引入第一阶段训练好的模型中,并使用来自AnimateDiff的预训练权重对其进行初始化。该模型的输入包括一个24帧的视频片段。在第二阶段,只训练temporal layer,同时固定网络其余部分的权重。 实验结果 在两个特定的基准中评估了Animate Anyone的性能:UBC时装视频合成(Fashion Video Synthesis)和TikTok人体舞蹈生成(Human Dance Generation)。采用SSIM、PSNR和LPIPS指标对于图像级质量进行定量评估,采用FVD指标对视频级进行定量评估。
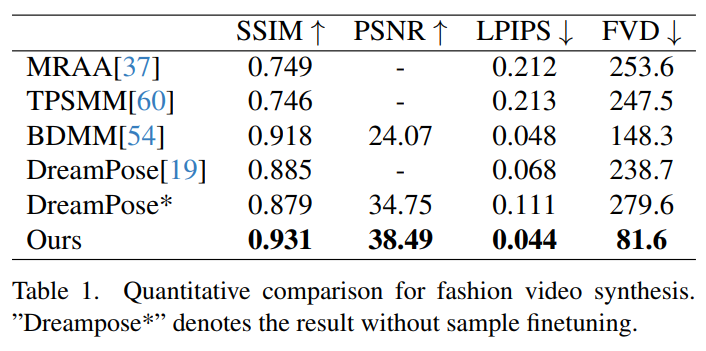
在UBC时装视频合成(Fashion Video Synthesis)基准上的性能如Table 1所示。 Animate Anyone的实验结果优于其他方法,特别是在FVD指标方面表现出显著领先。定性比较如Figure 4所示,DreamPose和BDMM生成的视频未能保持服装细节的一致性,在颜色和精细结构元素方面出现了明显的错误。相比之下,Animate Anyone产生的结果有效地保持了服装细节的一致性。
 在TikTok人体舞蹈生成(Human Dance Generation)基准上的性能如Table 2所示。 Animate Anyone同样取得了最好的结果。另外值得一提的是:Animate Anyone的训练仅在TikTok数据集上进行,产生的结果优于DisCo。定性比较如Figure 5所示,Animate Anyone即使没有利用人体掩码(mask)的外显学习,也可以从主体的运动中掌握前景-背景关系。此外,在复杂的舞蹈序列中,Animate Anyone在整个动作中保持视觉连续性方面表现突出,并在处理不同角色外观方面表现出更强的稳健性。
在TikTok人体舞蹈生成(Human Dance Generation)基准上的性能如Table 2所示。 Animate Anyone同样取得了最好的结果。另外值得一提的是:Animate Anyone的训练仅在TikTok数据集上进行,产生的结果优于DisCo。定性比较如Figure 5所示,Animate Anyone即使没有利用人体掩码(mask)的外显学习,也可以从主体的运动中掌握前景-背景关系。此外,在复杂的舞蹈序列中,Animate Anyone在整个动作中保持视觉连续性方面表现突出,并在处理不同角色外观方面表现出更强的稳健性。 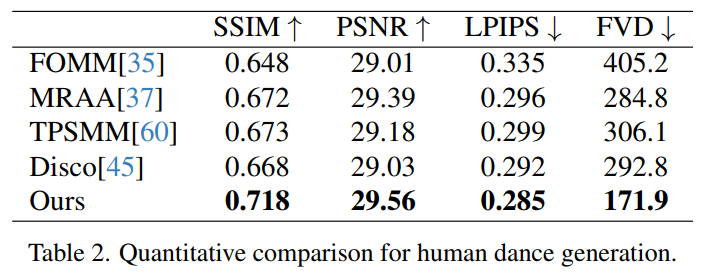
 由上可知,Animate Anyone的性能表现遥遥领先!该工作可以作为角色视频创作的基础解决方案,激发更多创新和创意应用的开发。 期待 Animate Anyone 具备十分优秀的视频生成性能和用户体验,达到了真正的“上手即用”。而通义大模型家族更是在不断丰富,已经全面覆盖了文本、语音及图像等模态。在此,我非常期待阿里云自研大模型“通义千问”支持更多的功能、插件。 最后希望国产AIGC、大模型发展越来越好!给每个人带来便利!
由上可知,Animate Anyone的性能表现遥遥领先!该工作可以作为角色视频创作的基础解决方案,激发更多创新和创意应用的开发。 期待 Animate Anyone 具备十分优秀的视频生成性能和用户体验,达到了真正的“上手即用”。而通义大模型家族更是在不断丰富,已经全面覆盖了文本、语音及图像等模态。在此,我非常期待阿里云自研大模型“通义千问”支持更多的功能、插件。 最后希望国产AIGC、大模型发展越来越好!给每个人带来便利! 整理不易,请点赞和在看![]()
评论