
ICCV 2021 旷视入选论文创新点解读!含目标检测、行人重识别、姿态估计等!
近日,两年一度的国际计算机视觉大会 ICCV 2021( IEEE International Conference on Computer Vision)公布了最终的接收论文决定。在官方公布中,旷视研究院共有9 篇论文(含2篇Oral)被成功收录。
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
来源:旷视研究院
作为计算机视觉领域三大顶级会议之一的ICCV,每次都会吸引众多 AI 研究人员参会。今年,由于疫情影响,原定在加拿大蒙特利尔举办的ICCV 2021 已改为线上举行,时间定为 10 月 11 到 17 日。
不同于在美国每年召开一次的CVPR和只在欧洲召开的ECCV,ICCV在世界范围内每两年召开一次。与此同时,ICCV论文录用率非常低,在今年的 6236 篇有效提交论文中,有 1617 篇被接收,接收率约为 25.9%。下面是旷视入选论文的亮点解读,enjoy~
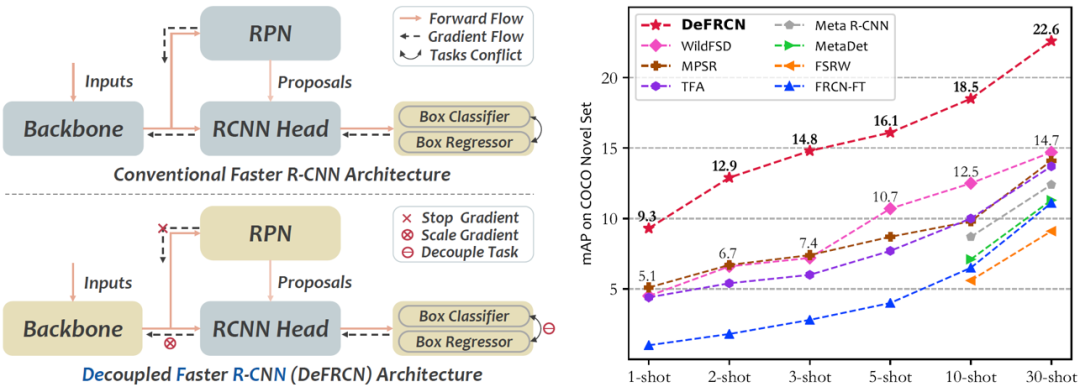
1、论文题目:DeFRCN: Decoupled Faster R-CNN for Few-Shot Object Detection
中文题目:DeFRCN:用于小样本目标检测的解耦Faster-RCNN
小样本目标检测是一个从包含极少数标注信息的新类别中快速检测新目标的视觉任务。目前大部分研究采用Faster RCNN 作为基础检测框架,均未考虑到两阶段目标检测范式在小样本场景下的固有矛盾,即多阶段矛盾(RPN vs. RCNN)和多任务矛盾(分类 vs. 定位)。为此,我们提出了一种简单而有效的小样本目标检测架构,通过提出用于多阶段解耦的梯度解耦层和用于多任务解耦的原型校准模块来扩展 Faster RCNN。在多个Benchmark上的大量实验表明,本文所提框架显著提升了小样本目标检测的性能并跻身业界前列。
所属领域:目标检测
关键词:小样本学习/解耦/迁移学习
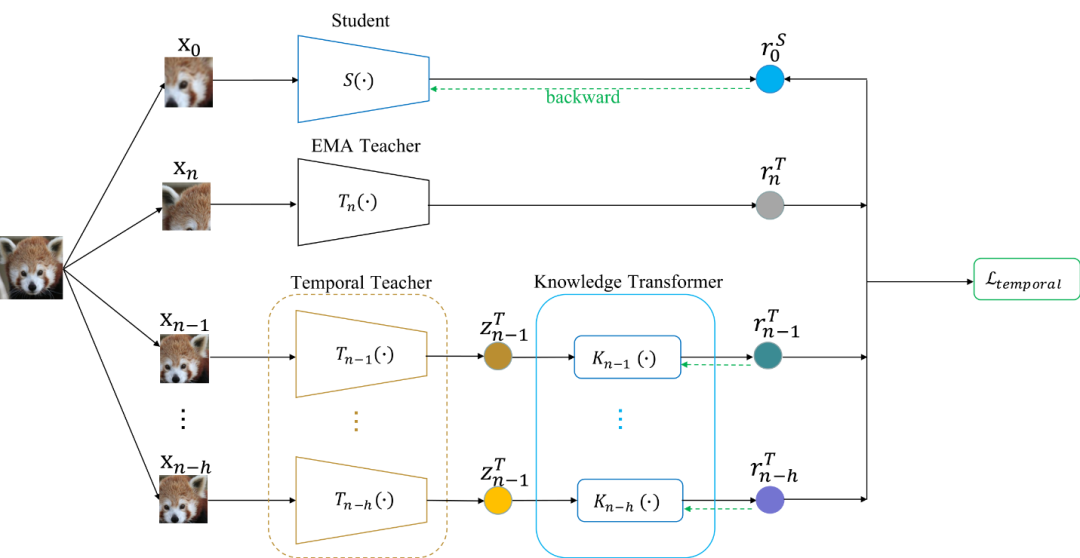
2、论文题目:Temporal Knowledge Consistency for Unsupervised Visual Representation Learning
中文题目:用于非监督视觉表达学习的时序知识一致性
自监督学习算法中主流的对比学习方法通常可以被视为教师-学生结构。教师网络在同一样本上的输出会随训练周期的推移发生明显变化,这将引入大量噪声并导致灾难性遗忘。本文首次提出将实例时间一致性嵌入到当前的自监督学习范式中,并提出一种新颖的算法TKC(Temporal Knowledge Consistency)。TKC使用多个时序教师来代替原有的教师网络,同时设计知识迁移模块自适应地从多个教师网络中学习表征。TKC在标准的线性评估及各类下游任务上相对于基线方法均有明显提升。
所属领域:自监督学习
关键词:表征学习、时空一致性、知识蒸馏
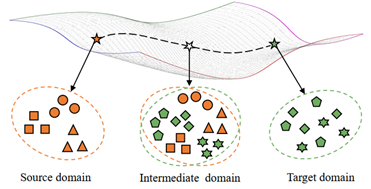
3、论文题目:IDM: Intermediate Domain Module for Domain Adaptive Person Re-ID
中文题目:IDM:用于域自适应行人重识别的跨域模块
针对ReID的跨域问题,本文提出了一种即插即用的IDM模块。该模块可以生成合理的中间域特征以起到桥接源域和目标域的作用,更好地将源域的知识迁移到目标域并提升行模型在目标域的判别力。受流型学习的启发,我们假设源域和目标域存在于流型空间,存在于源域和目标域测地线上的中间域可以起到很好地桥接作用,在学习的过程中可以自适应地减小源域和目标域的领域差异。我们的方法在当前跨域ReID任务上远远优于其它最先进的方法。
所属领域:行人重识别、领域自适应
关键词:中间域、流型学习
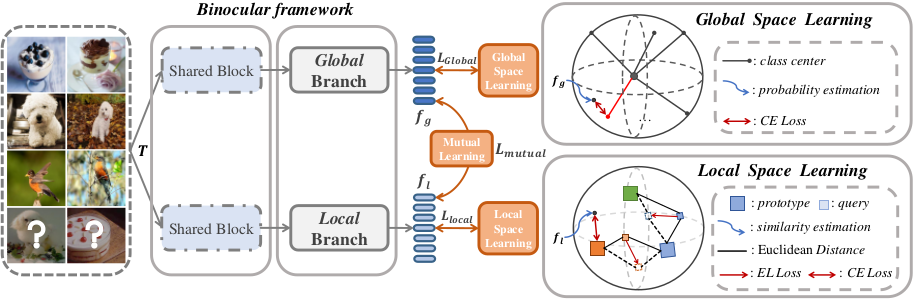
4、论文题目:Binocular Mutual Learning for Improving Few-shot Classification
中文题目:改进少样本分类的双目互学习
现有的小样本学习范式以元学习和迁移学习为主。本文从基类类别空间可见度的角度重新解释了元学习和迁移学习范式的异同,并在此基础上构建了一种双目互学习新范式BML。BML形式更加统一,其具备两个平行的视图空间(全局视图 vs 局部视图),模拟了“双目系统”。于此同时,弹性损失和视图间互学习进一步平衡了“双目视差”。我们的方法在多个公开基准数据集上超越了现有最先进方法,并且对数据粒度变化更加鲁棒。
所属领域:分类
关键词:小样本学习/互学习
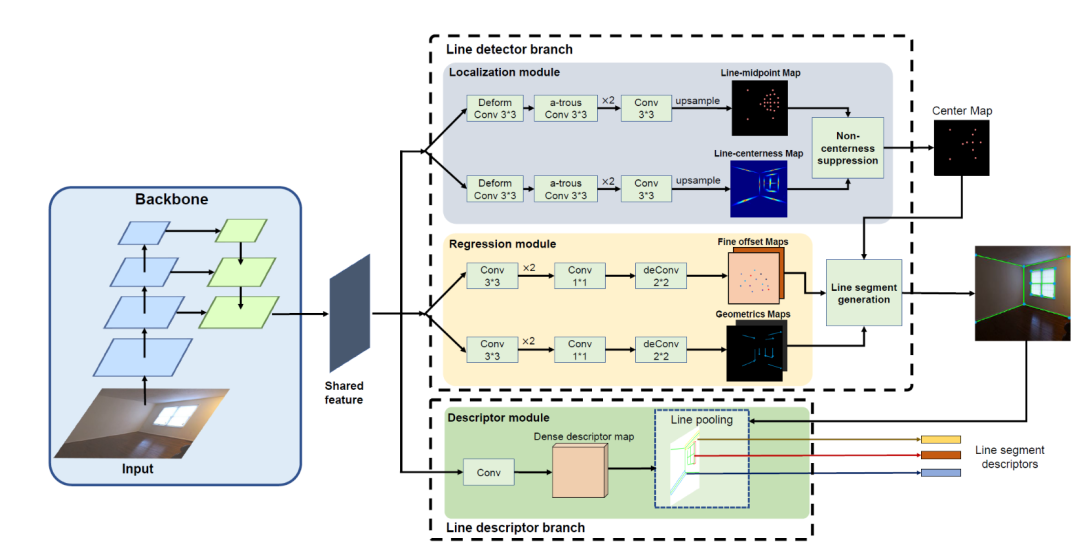
5、论文题目:ELSD: Efficient Line Segment Detector and Descriptor
中文题目:ELSD:高效线段检测器与描述器
对复杂环境进行高效描述是计算机视觉感知的一个重要问题。考虑到人工环境里存在大量的直线段特征,这些特征为上游的计算机视觉应用提供了重要的结构化信息,如3D场景重建、视觉重定位、SLAM等。在这篇论文中,我们提出了一种高效的方法来同时检测线特征和提取描述子,通过改进的一阶段直线段检测与自监督的描述子学习,我们的方法在精度和速度方面均优于其他最先进的方法,在对线特征进行精确检测和描述的同时,也可以达到实时的速度。
所属领域:图像特征提取
关键词:直线段检测、描述子提取
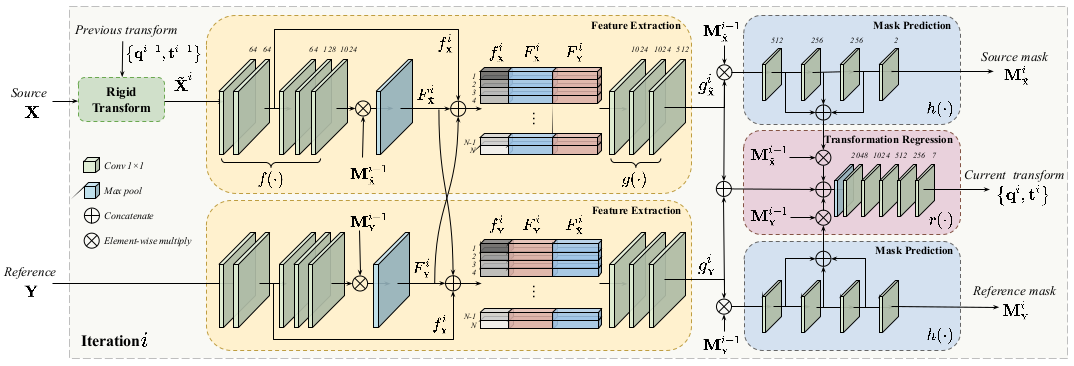
6、论文题目:OMNet: Learning Overlapping Mask for Partial-to-Partial Point Cloud Registration
中文题目:OMNet:用于部分重叠点云配准的点云重叠掩模学习
3D点云配准是3D计算邻域的基础任务之一。现有的方法仅使用了点云稀疏的局部信息或者是没有考虑可能存在的部分重叠的点云输入。为解决这一问题,我们提出了一个基于点云重叠区域预测的迭代式3D刚体变换估计的框架。我们的贡献主要有3点:(1)设计了点云重叠区域预测的模块以屏蔽非重叠区域对于3D刚体变换估计的影响;(2)发现了ModelNet40数据集应用于配准任务时的过拟合问题,并提出了一种更合理的数据生成方式;(3)与多个最新的研究工作相比,我们的方法取得了最优的性能,同时对于噪声和不同的数据集具有较好的鲁棒性。
所属领域:3D点云配准
关键词:3D点云配准,重叠掩模学习
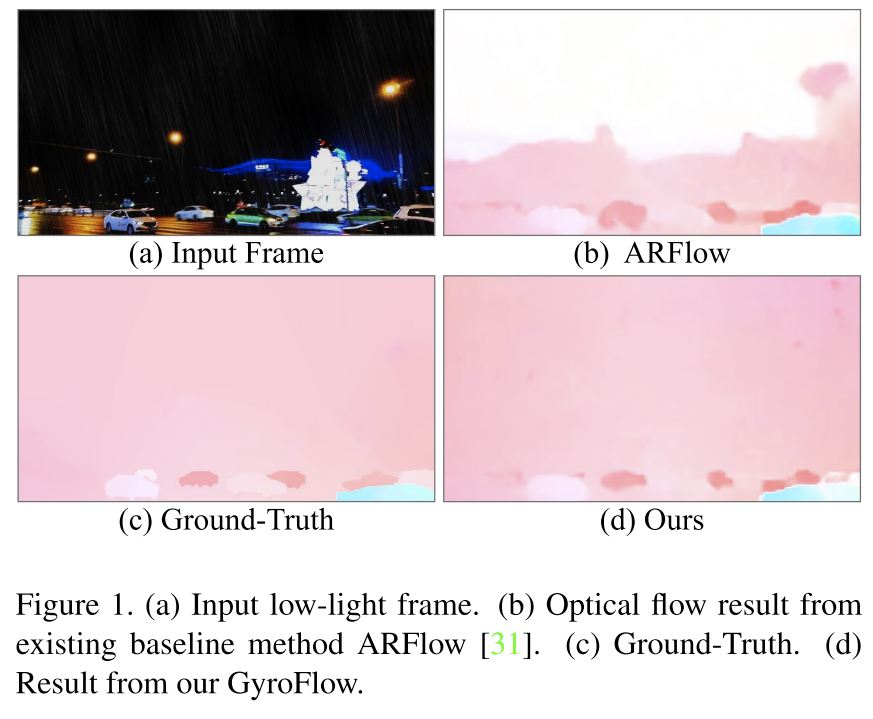
7、论文题目:GyroFlow: Gyroscope-Guided Unsupervised Optical Flow Learning
中文题目:GyroFlow:陀螺仪引导的无监督光流学习
现有的光流估计算法在雾天、雨天、夜景等困难场景中是容易出错的,主要原因是光流估计中的基本假设被打破,比如亮度恒定和梯度恒定。为了解决这个问题,我们提出了一个将陀螺仪信息融合到无监督光流估计的框架。我们的贡献主要有3点:1)第一个基于深度学习融合陀螺仪信息和图像信息来实现无监督光流学习的框架;2)一个自引导模块来融合陀螺仪信息和光流信息;3)一个囊括多种困难场景的光流数据集。
所属领域:图像对齐/配准
关键词:无监督光流,陀螺仪,图像对齐
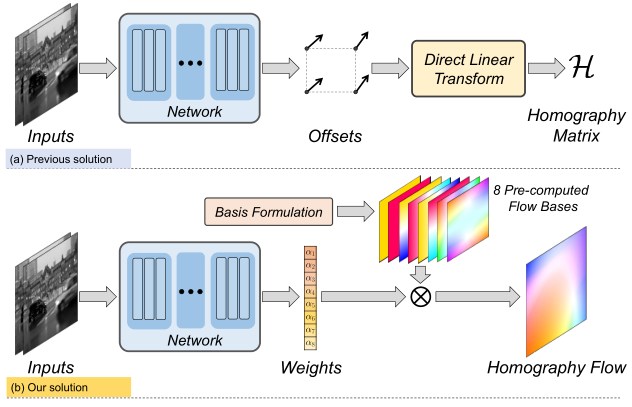
8、论文题目:Motion Basis Learning for Unsupervised Deep Homography Estimation with Subspace Projection
中文题目:用于带有子空间投影的非监督深度变换估计的运动基向量学习
本文介绍了一种新的无监督单应估计框架。我们的贡献主要有3点:(1)提出了一种单应流表示法,可以通过8个预定义单应流基的加权和来表示单应性;(2)考虑到单应性仅包含8个自由度,远小于网络中间特征的秩,我们提出了一种低秩表示模块来实现特征降秩,从而保留与主导相机运动相对应的特征,并提高对于其它噪声的鲁棒性;(3)我们提出了一种特征恒等损失来强制网络学习到具有warp等变性的图像特征,这意味着如果warp操作和特征提取的顺序互换,最后的结果是相同的。
所属领域:图像对齐/配准
关键词:图像对齐,光流基,无监督单应性学习
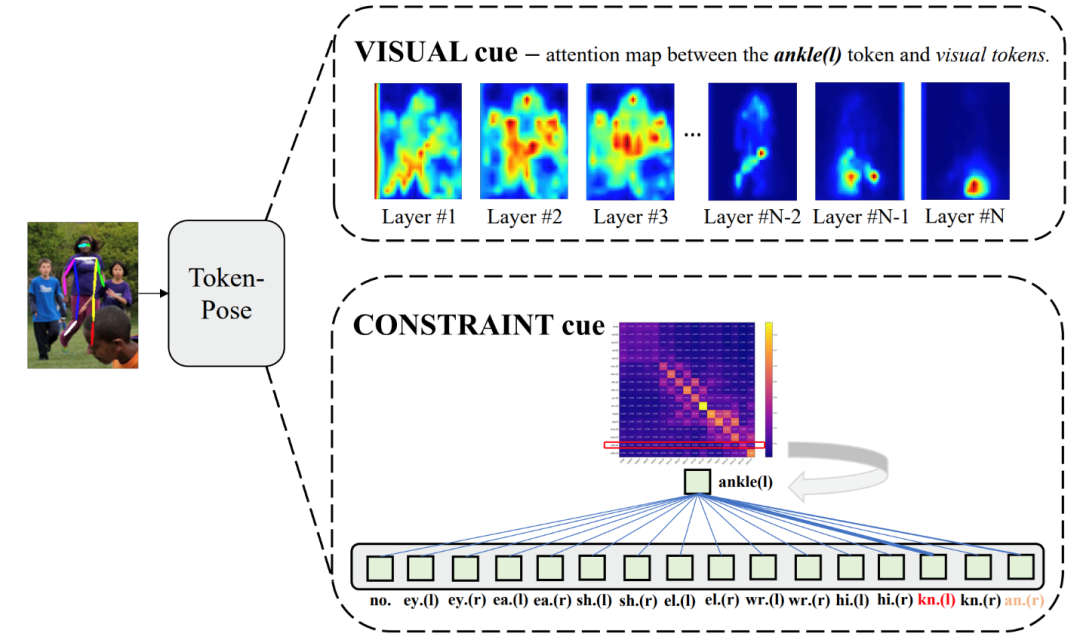
9、论文题目:TokenPose: Learning Keypoint Tokens for Human Pose Estimation
中文题目:TokenPose:用于人体姿态估计的关键点标记学习
人体姿态估计是一个高度依赖视觉线索和肢体约束关系来定位关键点的任务。现有的基于CNN的方法在提取视觉表示方面已经做得很好,但缺乏显式地学习关键点之间约束关系的能力。在这篇论文中,我们提出了一种基于令牌(token)表示的新方法用于姿态估计。每个关键点表示成独立的token,从图像中捕捉视觉线索并学习关键点之间的约束关系。我们的模型较于主流模型,以更少的参数量和计算复杂度取得了出色的表现性能。
所属领域:人体姿态估计
关键词:人体姿态估计、Token表征、Transformer、关键点约束关系学习
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
