
Flink 特性 | Flink 1.14 新特性预览
简介 流批一体 Checkpoint 机制 性能与效率 Table / SQL / Python API 总结
 GitHub 地址
GitHub 地址 此文章为 8 月 7 日的分享整理,1.14 版本最新进展请注意文中的注释说明。
一、简介
1.14 新版本原本规划有 35 个比较重要的新特性以及优化工作,目前已经有 26 个工作完成;5 个任务不确定是否能准时完成;另外 4 个特性由于时间或者本身设计上的原因,会放到后续版本完成。[1]

Wiki:https://cwiki.apache.org/confluence/display/FLINK/1.14+Release
Jira:https://issues.apache.org/jira/projects/FLINK/versions/12349614
[1] 截至到 8 月 31 日,确定进入新版本的是 33 个,已全部完成。
二、流批一体
需要维护两套系统,相应的就需要两组开发人员,人力的投入成本很高;
另外,两套数据链路处理相似内容带来维护的风险性和冗余;
最重要的一点是,如果流批使用的不是同一套数据处理系统,引擎本身差异可能会存在数据口径不一致的问题,从而导致业务数据存在一定的误差。这种误差对于大数据分析会有比较大的影响。
对于无限的数据流,统一采用了流的执行模式。流的执行模式指的是所有计算节点是通过 Pipeline 模式去连接的,Pipeline 是指上游和下游计算任务是同时运行的,随着上游不断产出数据,下游同时在不断消费数据。这种全 Pipeline 的执行方式可以:
通过 eventTime 表示数据是什么时候产生的;
通过 watermark 得知在哪个时间点,数据已经到达了;
通过 state 来维护计算中间状态;
通过 Checkpoint 做容错的处理。
下图是不同的执行模式:
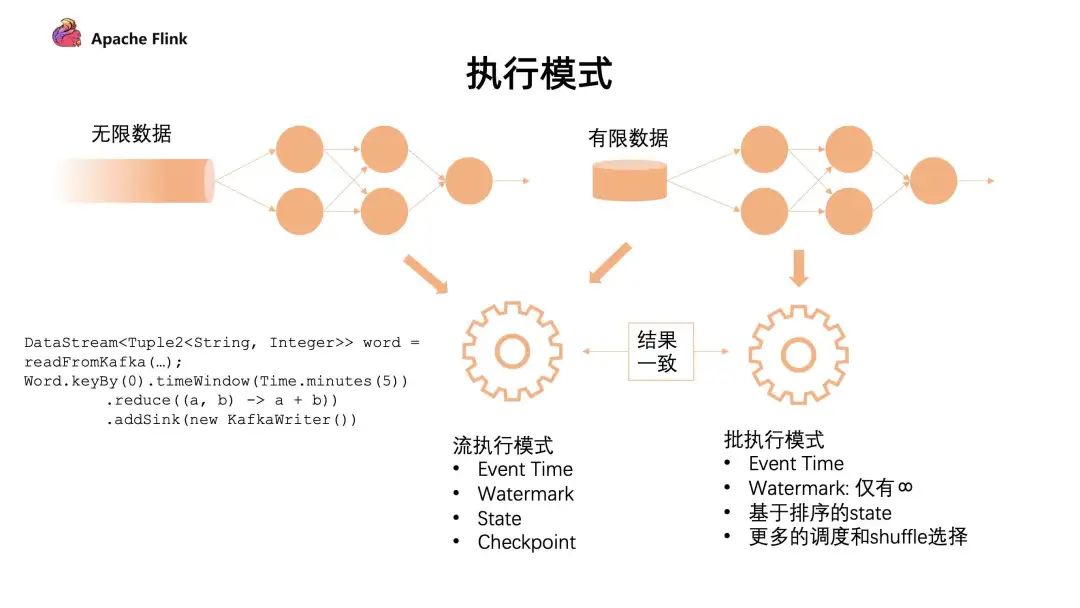
对于有限的数据集有 2 种执行模式,我们可以把它看成一个有限的数据流去做处理,也可以把它看成批的执行模式。批的执行模式虽然也有 eventTime,但是对于 watermark 来说只支持正无穷。对数据和 state 排序后,它在任务的调度和 shuffle 上会有更多的选择。
流批的执行模式是有区别的,最主要的就是批的执行模式会有落盘的中间过程,只有当前面任务执行完成,下游的任务才会触发,这个容错机制是通过 shuffle 进行容错的。
这 2 者也各有各的执行优势:
对于流的执行模式来说,它没有落盘的压力,同时容错是基于数据的分段,通过不断对数据进行打点 Checkpoint 去保证断点恢复;
然而在批处理上,因为要经过 shuffle 落盘,所以对磁盘会有压力。但是因为数据是经过排序的,所以对于批来说,后续的计算效率可能会有一定的提升。同时,在执行时候是经过分段去执行任务的,无需同时执行;在容错计算方面是根据 stage 进行容错。
这两种各有优劣,可以根据作业的具体场景来进行选择。
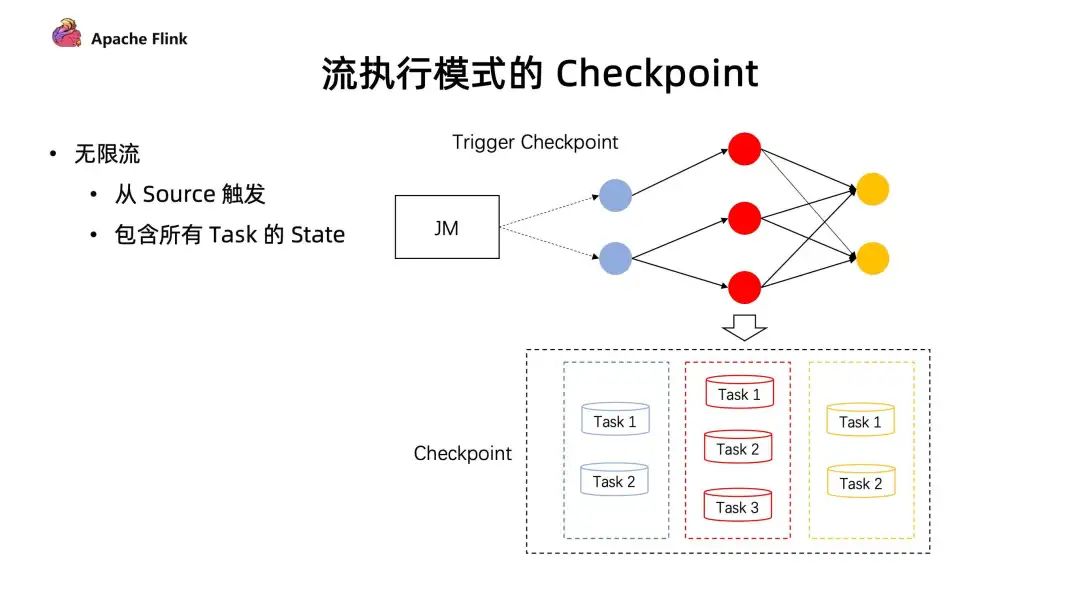
■ 在流的执行模式下的 Checkpoint 机制
对于无限流,它的 Checkpoint 是由所有的 source 节点进行触发的,由 source 节点发送 Checkpoint Barrier ,当 Checkpoint Barrier 流过整个作业时候,同时会存储当前作业所有的 state 状态。
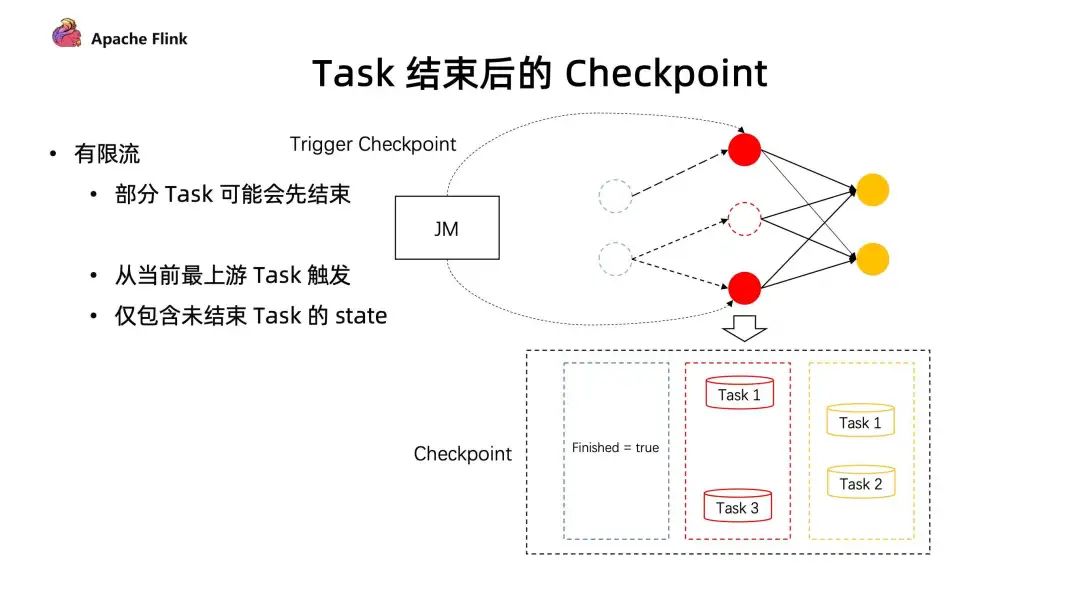
而在有限流的 Checkpoint 机制中,Task 是有可能提早结束的。上游的 Task 有可能先处理完任务提早退出了,但下游的 Task 却还在执行中。在同一个 stage 不同并发下,有可能因为数据量不一致导致部分任务提早完成了。这种情况下,在后续的执行作业中,如何进行 Checkpoint?
在 1.14 中,JobManager 动态根据当前任务的执行情况,去明确 Checkpoint Barrier 是从哪里开始触发。同时在部分任务结束后,后续的 Checkpoint 只会保存仍在运行 Task 所对应的 stage,通过这种方式能够让任务执行完成后,还可以继续做 Checkpoint ,在有限流执行中提供更好的容错保障。
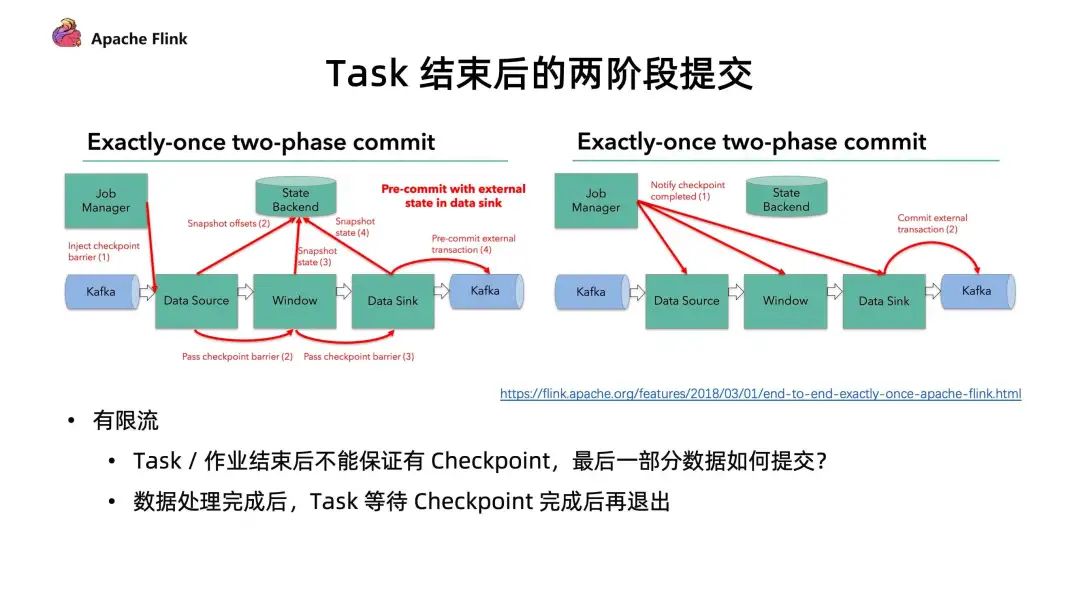
■ Task 结束后的两阶段提交
三、checkpoint 机制
1. 现有 Checkpoint 机制痛点
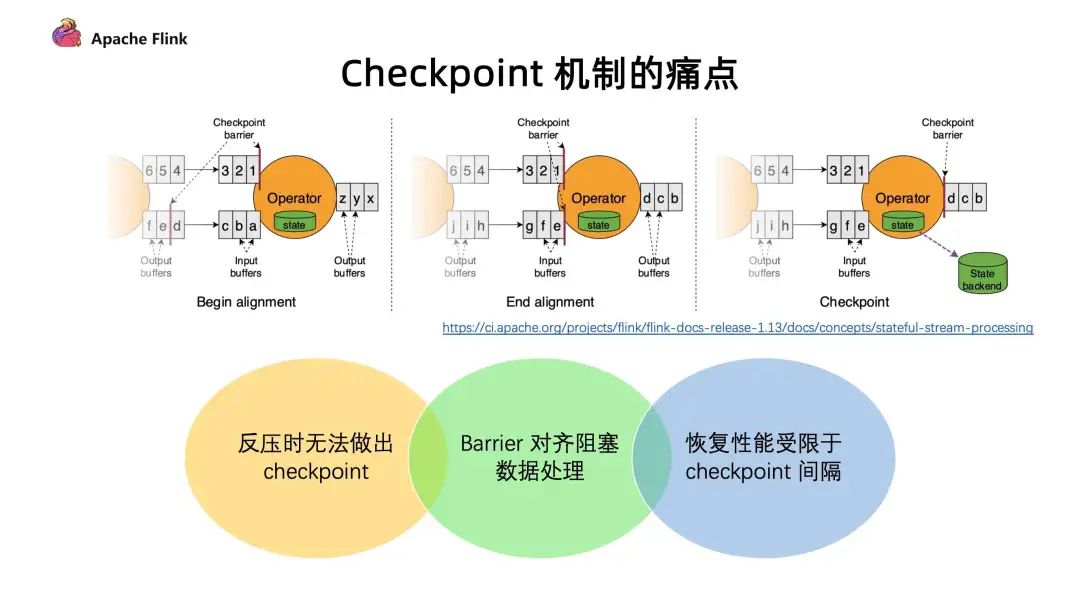
反压时无法做出 Checkpoint :在反压时候 barrier 无法随着数据往下游流动,造成反压的时候无法做出 Checkpoint。但是其实在发生反压情况的时候,我们更加需要去做出对数据的 Checkpoint,因为这个时候性能遇到了瓶颈,是更加容易出问题的阶段;
Barrier 对齐阻塞数据处理 :阻塞对齐对于性能上存在一定的影响;
恢复性能受限于 Checkpoint 间隔 :在做恢复的时候,延迟受到多大的影响很多时候是取决于 Checkpoint 的间隔,间隔越大,需要 replay 的数据就会越多,从而造成中断的影响也就会越大。但是目前 Checkpoint 间隔受制于持久化操作的时间,所以没办法做的很快。
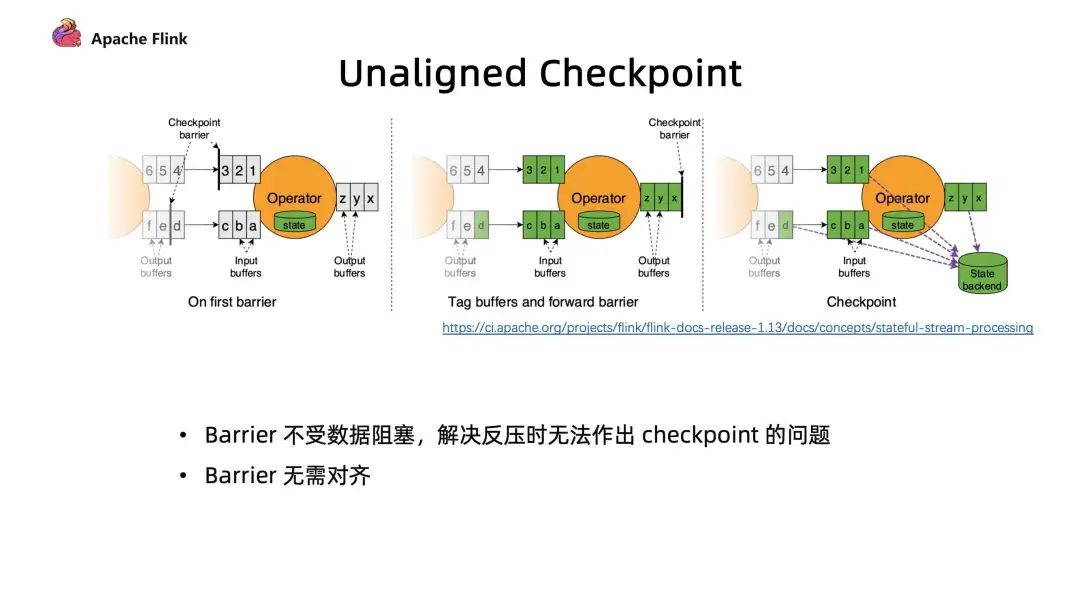
2. Unaligned Checkpoint
 3. Generalized Incremental Checkpoint [2]
3. Generalized Incremental Checkpoint [2]
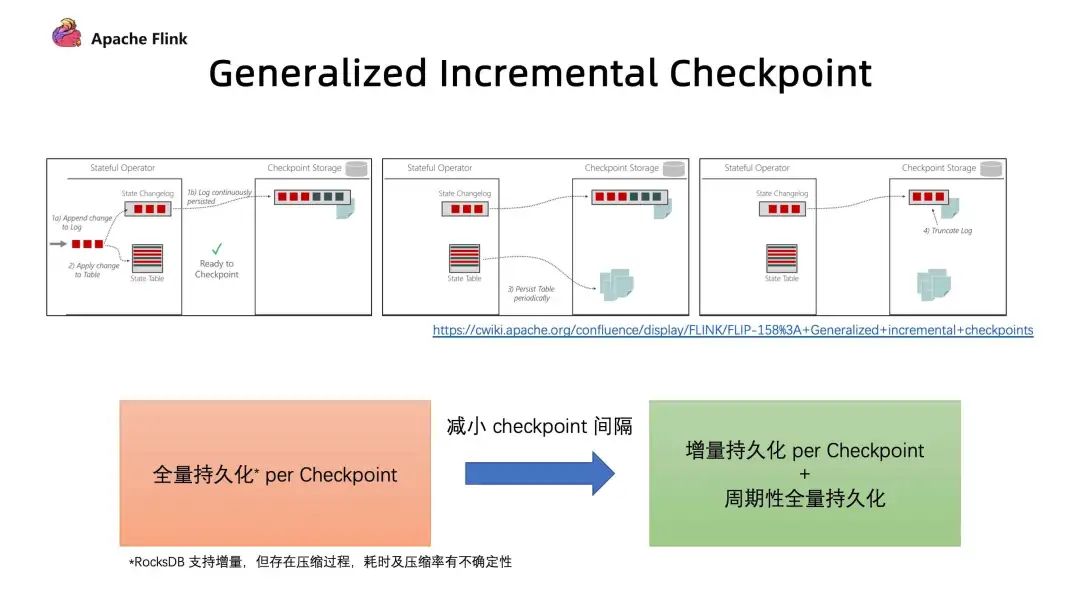
第一个问题是 RocksDB 的 Incremental Checkpoint 是依赖它自己本身的一些实现,当中会存在一些数据压缩,压缩所消耗的时间以及压缩效果具有不确定性,这个是和数据是相关的;
第二个问题是只能针对特定的 StateBackend 来使用,目前在做的 Generalized Incremental Checkpoint 实际上能够保证的是,它与 StateBackend 是无关的,从运行时的机制来保证了一个比较稳定、更小的 Checkpoint 间隔。
[2] Generalized Incremental Checkpoint 最终在 1.14 中没有完成。
四、性能与效率
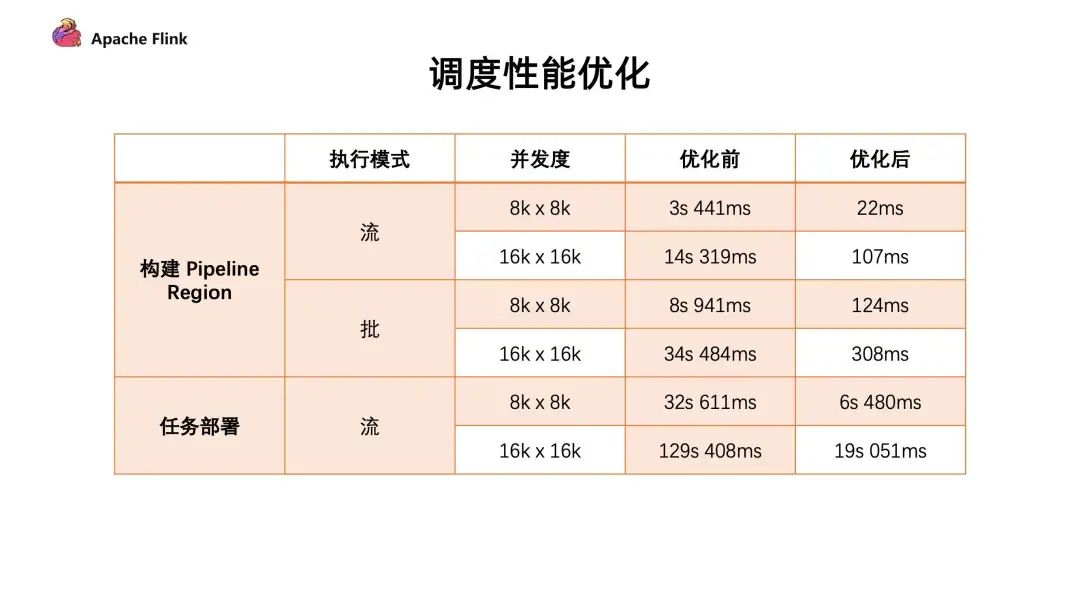
1. 大规模作业调度的优化
构建 Pipeline Region 的性能提升:所有由 pipline 边所连接构成的子图 。在 Flink 任务调度中需要通过识别 Pipeline Region 来保证由同一个 Pipline 边所连接的任务能够同时进行调度。否则有可能上游的任务开始调度,但是下游的任务并没有运行。从而导致上游运行完的数据无法给下游的节点进行消费,可能会造成死锁的情况
任务部署阶段:每个任务都要从哪些上游读取数据,这些信息会生成 Result Partition Deployment Descriptor。
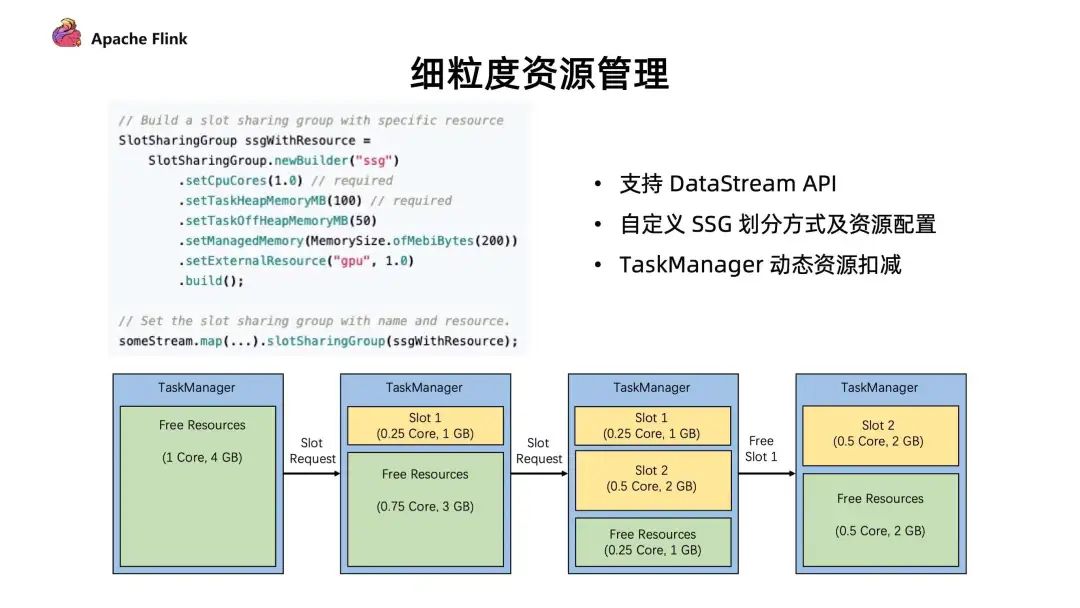
2. 细粒度资源管理
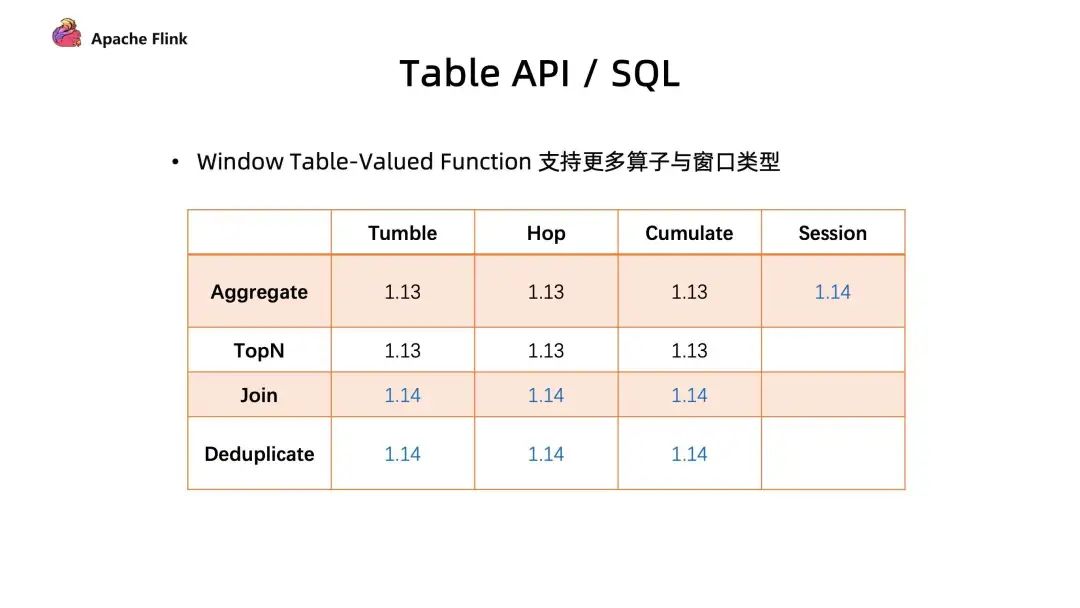
五、Table / SQL / Python API
■ 1.1 支持声明式注册 Source/Sink
Table API 支持使用声明式的方式注册 Source / Sink 功能对齐 SQL DDL;
同时支持 FLIP-27 新的 Source 接口;
new Source 替代旧的 connect() 接口。

■ 1.2 全新代码生成器
■ 1.3 移除 Flink Planner
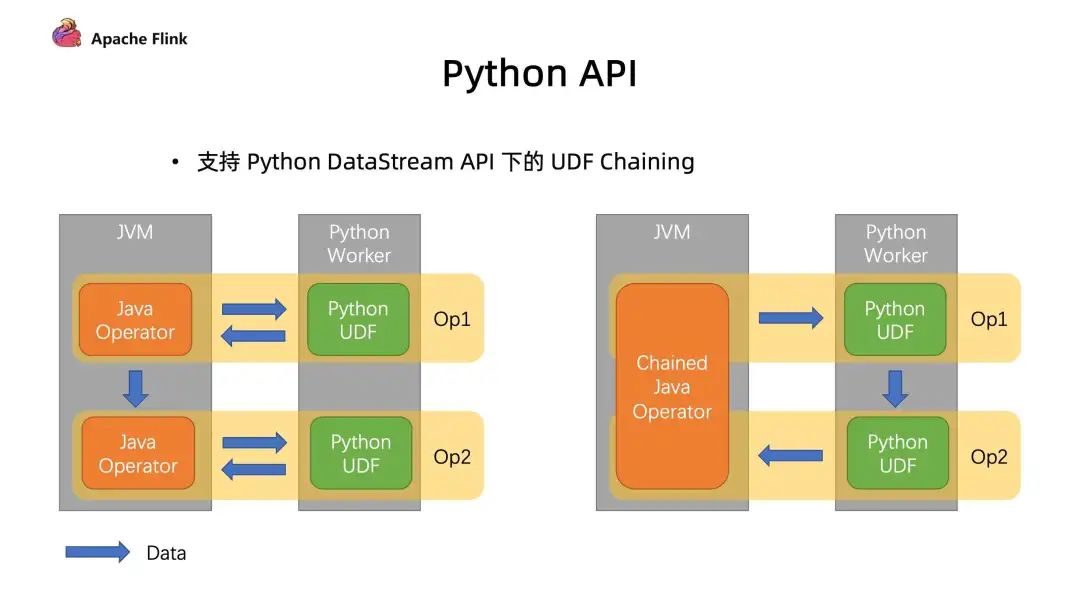
2. Python API
3. 支持 LoopBack 模式
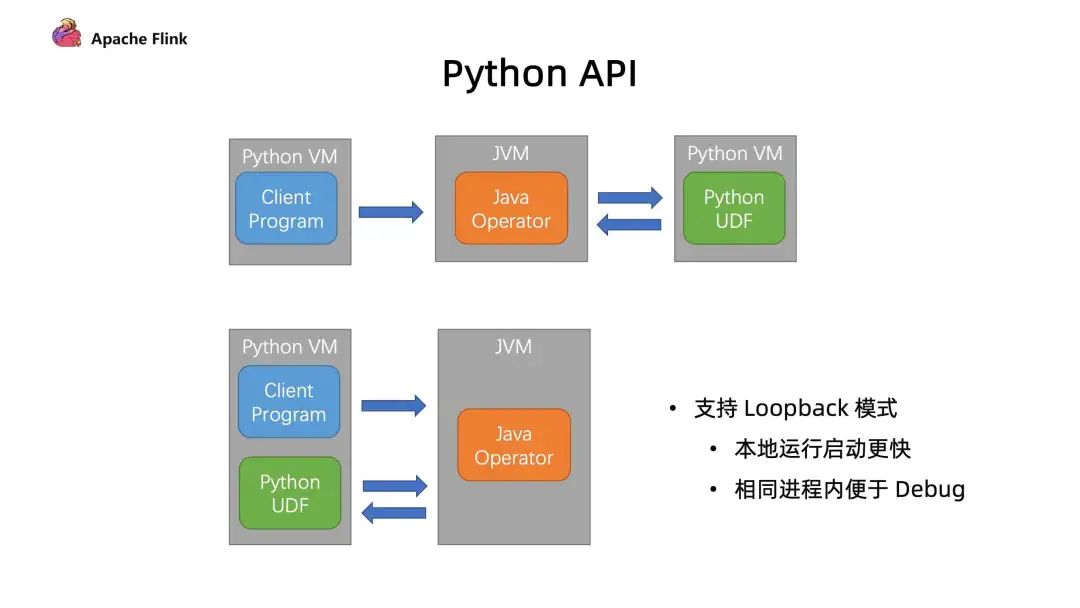
首先是避免了启动额外进程所带来的开销;
最重要的是在本地调试中,我们可以在同一个进程内能够更好利用一些工具进行 debug,这个是对开发者体验上的一个提升。
六、总结
首先介绍了目前社区在批流一体上的工作,通过介绍批流不同的执行模式和 JM 节点任务触发的优化改进更好的去兼容批作业;
然后通过分析现有的 Checkpoint 机制痛点,在新版本中如何改进,以及在大规模作业调度优化和细粒度的资源管理上面如何做到对性能优化;
最后介绍了 TableSQL API 和 Pyhton上相关的性能优化。
第三届 Apache Flink 极客挑战赛 伴随着海量数据的冲击,数据处理分析能力在业务中的价值与日俱增,各行各业对于数据处理时效性的探索也在不断深入,作为主打实时计算的计算引擎 - Apache Flink 应运而生。
为给行业带来更多实时计算赋能实践的思路,鼓励广大热爱技术的开发者加深对 Flink 的掌握,Apache Flink 社区联手阿里云、英特尔、阿里巴巴人工智能治理与可持续发展实验室 (AAIG)、Occlum 联合举办 "第三届 Apache Flink 极客挑战赛暨 AAIG CUP" 活动,即日起正式启动。
▼ 扫描图中二维码,了解更多赛事信息 ▼

 戳我,回顾作者分享视频!
戳我,回顾作者分享视频!