
Flink 特性 | Flink 1.12 资源管理新特性回顾
内存管理 资源调度 扩展资源框架 未来规划 总结
 GitHub 地址
GitHub 地址 一、内存管理
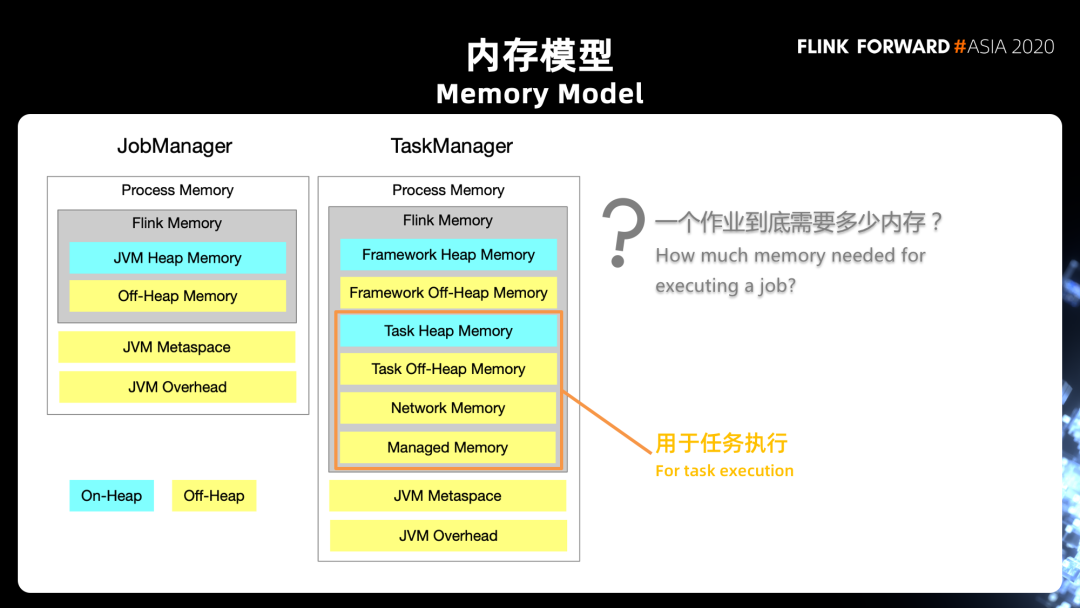

1. 本地内存(Managed Memory)
一方面是 slot 级别的预算规划,它可以保证作业运行过程中不会因为内存不足,造成某些算子或者任务无法运行;也不会因为预留了过多的内存没有使用造成资源浪费。同时 Flink 能保证当任务运行结束时准确将内存释放,确保 Task Manager 执行新任务时有足够的内存可用。
另一方面,资源适应性也是托管内存很重要的特性之一,指算子对于内存的需求是动态可调整的。具备了适应性,算子就不会因为给予任务过多的内存造成资源使用上的浪费,也不会因为提供的内存相对较少导致整个作业无法运行,使内存的运用保持在一定的合理范围内。
当然,在内存分配相对比较少情况下,作业会受到一定限制,例如需要通过频繁的落盘保证作业的运行,这样可能会影响性能。
RocksDB 状态后端:在流计算的场景中,每个 Slot 会使用 State 的 Operator,从而共享同一底层 的 RocksDB 缓存; Flink 内置算子:包含批处理、Table SQL、DataSet API 等算子,每个算子有独立的资源预算,不会相互共享; Python 进程:用户使用 PyFlink,使用 Python 语言定义 UDF 时需要启动 Python 的虚拟机进程。
2. Job Graph 编译阶段
■ 2.1 作业的 Job Graph 编译阶段
第一个问题是:slot 当中到底有哪些算子或者任务会同时执行。这个问题关系到在一个查询作业中如何对内存进行规划,是否还有其他的任务需要使用 management memory,从而把相应的内存留出来。在流式的作业中,这个问题是比较简单的,因为我们需要所有的算子同时执行,才能保证上游产出的数据能被下游及时的消费掉,这个数据才能够在整个 job grep 当中流动起来。但是如果我们是在批处理的一些场景当中,实际上我们会存在两种数据 shuffle 的模式。
一种是 pipeline 的模式,这种模式跟流式是一样的,也就是我们前面说到的 bounded stream 处理方式,同样需要上游和下游的算子同时运行,上游随时产出,下游随时消费。
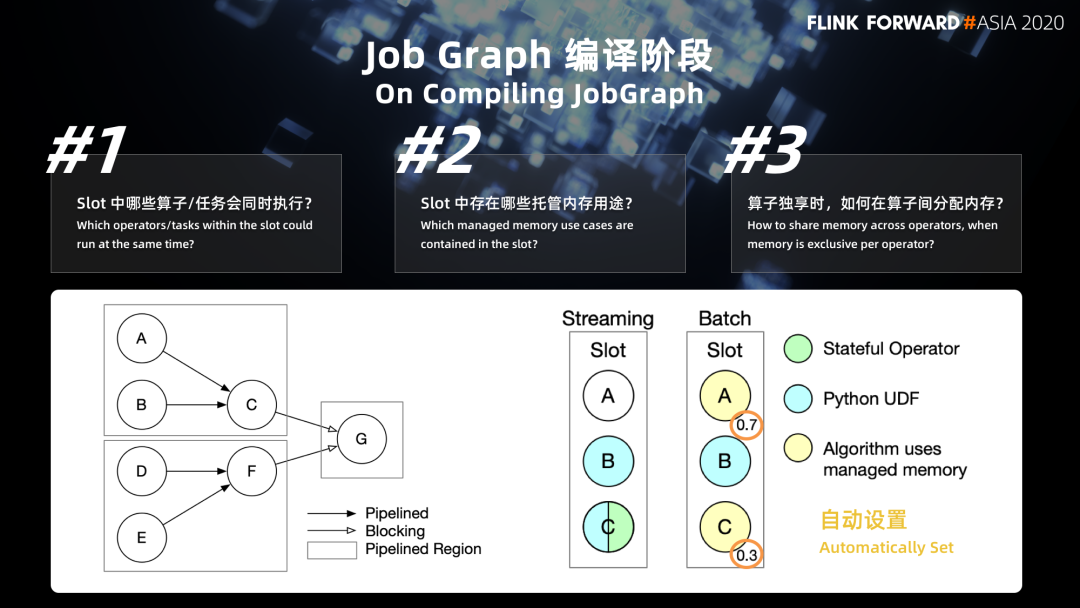
另外一种是所谓的 batch 的 blocking的方式,它要求上游把数据全部产出,并且落盘结束之后,下游才能开始读数据。
这两种模式会影响到哪些任务可以同时执行。目前在 Flink 当中,根据作业拓扑图中的一个边的类型 (如图上)。我们划分出了定义的一个概念叫做 pipelined region,也就是全部都由 pipeline 的边锁连通起来的一个子图,我们把这个子图识别出来,用来判断哪些 task 会同时执行。
第二个问题是:slot 当中到底有哪些使用场景?我们刚才介绍了三种 manage memory 的使用场景。在这个阶段,对于流式作业,可能会出现 Python UDF 以及 Stateful Operator。这个阶段当中我们需要注意的是,这里并不能肯定 State Operator 一定会用到 management memory,因为这跟它的状态类型是相关的。
如果它使用了 RocksDB State Operator,是需要使用 manage memory 的;
但是如果它使用的是 Heap State Backend,则并不需要。
第三个问题:对于 batch 的作业,我们除了需要清楚有哪些使用场景,还需要清楚一件事情,就是前面提到过 batch 的 operator。它使用 management memory 是以一种算子独享的方式,而不是以 slot 为单位去进行共享。我们需要知道不同的算子应该分别分配多少内存,这个事情目前是由 Flink 的计划作业来自动进行设置的。
然而,作业在编译的阶段,其实并不知道状态的类型,这里是需要去注意的地方。
■ 2.2 执行阶段
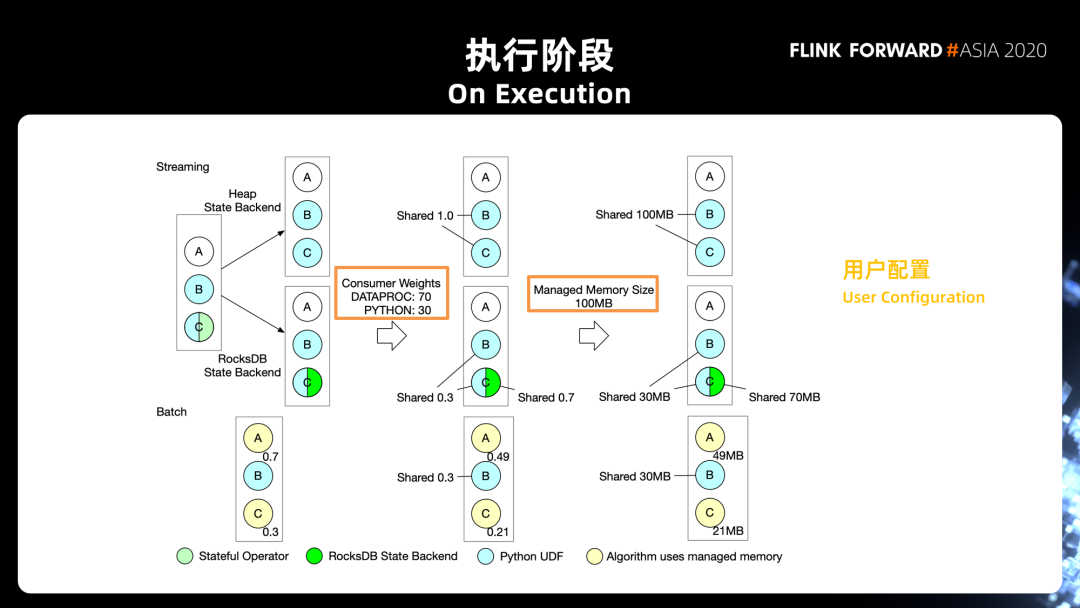
其中一个是 RocksDB State Backend,有了第一步的判断之后,第二步我们会根据用户的配置,去决定不同使用方式之间怎么样去共享 slot 的 management memory。
在这个 Steaming 的例子当中,我们定义的 Python 的权重是 30%,State Backend 的权重是 70%。在这样的情况下,如果只有 Python,Python 的部分自然是使用 100% 的内存(Streaming 的 Heap State Backend 分支);
而对于第二种情况(Streaming 的 RocksDB State Backend 分支),B、C 的这两个 Operator 共用 30% 的内存用于 Python 的 UDF,另外 C 再独享 70% 的内存用于 RocksDB State Backend。最后 Flink 会根据 Task manager 的资源配置,一个 slot 当中有多少 manager memory 来决定每个 operator 实际可以用的内存的数量。
3. 参数配置
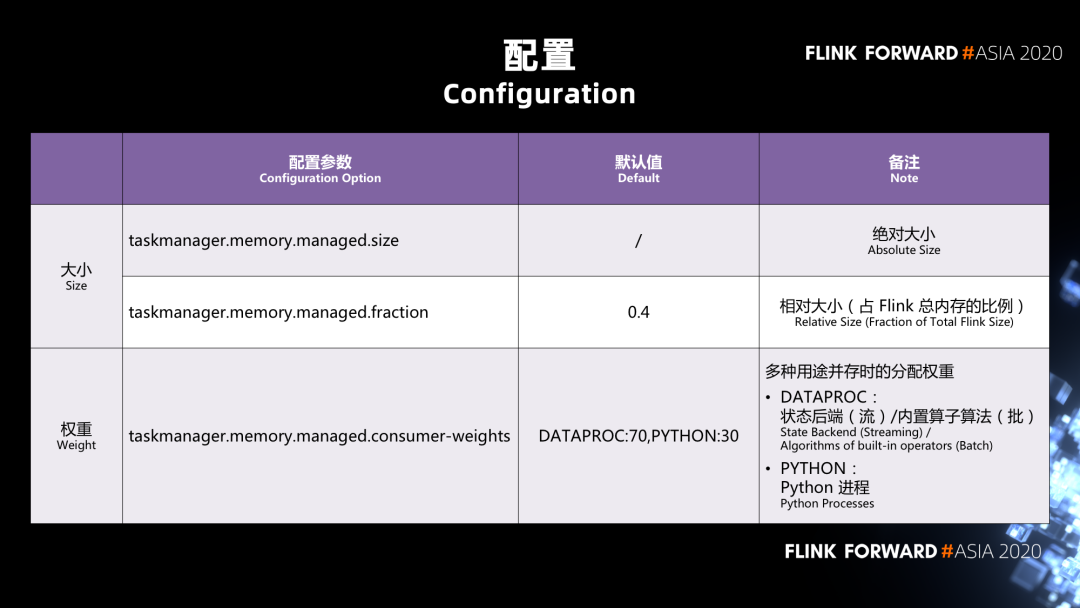
| 配置参数 | 默认值 | 备注 | |
|---|---|---|---|
| 大小 | taskmanager.memory.managed.size | / | 绝对大小 |
| 权重 | taskmanager.memory.managed.fraction | 0.4 | 相对大小(占用Flink)总内存比例 |
| taskmanager.memory.managed.consumer-weight | DATAPROC:70,PYTHON:30 | 多种用途并存时候分配权重 |
一种是绝对值的配置方式;
还有一种是作为 Task Manager 总内存的一个相对值的配置方式。
taskmanager.memory.managed.consumer-weight 是一个新加的配置项,它的数据类型是 map 的类型,也就是说我们在这里面实际上是给了一个 key 冒号 value,然后逗号再加上下一组 key 冒号 value 的这样的一个数据的结构。这里面我们目前支持两种 consumer 的 key:
一个是 DATAPROC, DATAPROC 既包含了流处理当中的状态后端 State Backend 的内存,也包含了批处理当中的 Batch Operator;
另外一种是 Python。
二、 资源调度
部分资源调度相关的 Feature 是其他版本或者邮件列表里面大家询问较多的,这里我们也做对应的介绍。
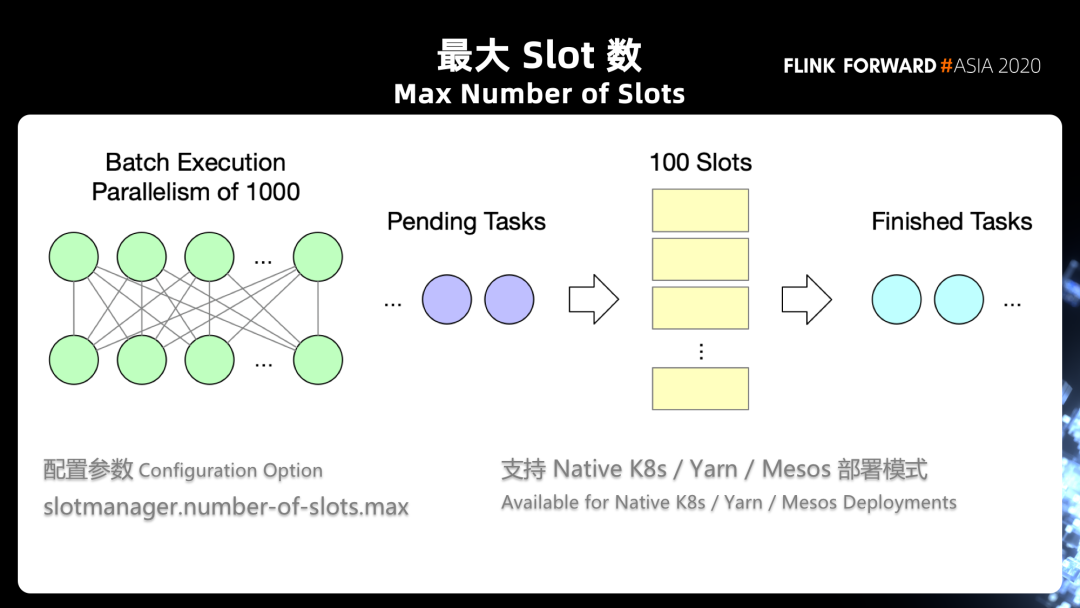
1. 最大 Slot 数
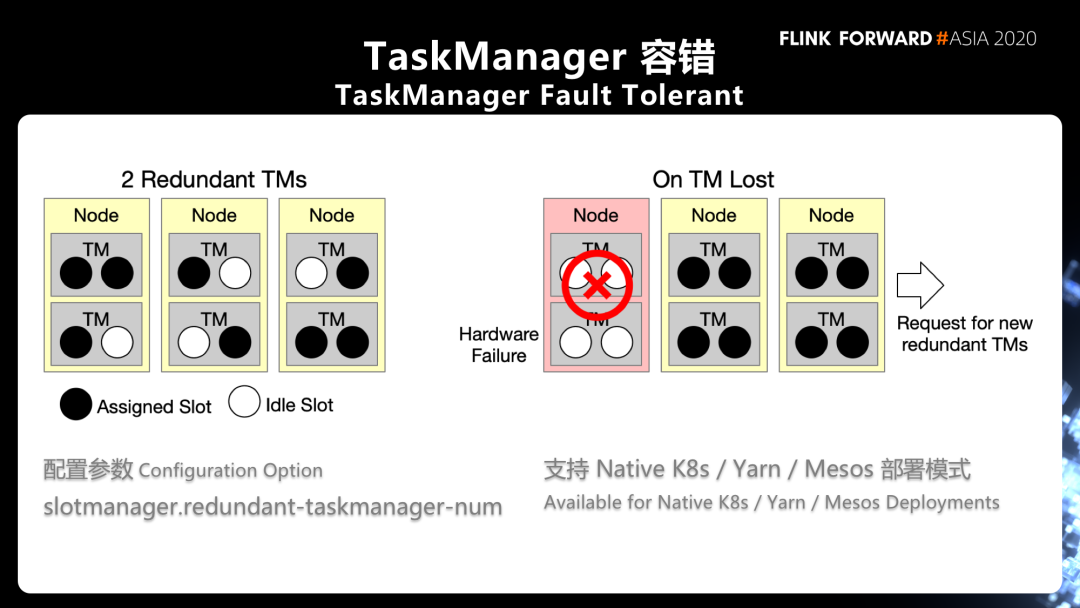
2. TaskManager 容错
3. 任务平铺分布

第一,这个参数我们只针对 Standalone 模式,因为在 yarn 跟 k8s 的模式下,实际上是根据你作业的需求来决定起多少 task manager 的,所以是先有了需求再有 TaskManager,而不是先有 task manager,再有 slot 的调度需求。
在每次调度任务的时候,实际上只能看到当前注册上来的那一个 TaskManager,Flink 没办法全局的知道后面还有多少 TaskManager 会注册上来,这也是很多人在问的一个问题,就是为什么特性打开了之后好像并没有起到一个很好的效果。
第二个需要注意的点是,这里面我们只能决定每一个 TaskManager 上有多少空闲 slot,然而并不能够决定每个 operator 有不同的并发数,Flink 并不能决定说每个 operator 是否在 TaskManager 上是一个均匀的分布,因为在 flink 的资源调度逻辑当中,在整个 slot 的 allocation 这一层是完全看不到 task 的。
三、扩展资源框架
1. 背景
一个是 Flink AI Extended 的项目,是基于 Flink 的深度学习扩展框架,目前支持 TensorFlow、PyTorch 等框架的集成,它使用户可以将 TensorFlow 当做一个算子,放在 Flink 任务中。
另一个是 Alink,它是一个基于 Flink 的通用算法平台,里面也内置了很多常用的机器学习算法。
2. 使用扩展资源
需要支持该类扩展资源的配置与调度。用户可以在配置中指明对这类扩展资源的需求,如每个 TaskManager 上需要有一块 GPU 卡,并且当 Flink 被部署在 Kubernetes/Yarn 这类资源底座上时,需要将用户对扩展资源的需求进行转发,以保证申请到的 Container/Pod 中存在对应的扩展资源。
需要向算子提供运行时的扩展资源信息。用户在自定义算子中可能需要一些运行时的信息才能使用扩展资源,以 GPU 为例,算子需要知道它内部的模型可以部署在那一块 GPU 卡上,因此,需要向算子提供这些信息。
3. 扩展资源框架使用方法
首先为该扩展资源设置相关配置;
然后为所需的扩展资源准备扩展资源框架中的插件;
最后在算子中,从 RuntimeContext 来获取扩展资源的信息并使用这些资源。
■ 3.1 配置参数
# 定义扩展资源名称,“gpu”external-resources: gpu# 定义每个 TaskManager 所需的 GPU 数量external-resource.gpu.amount: 1# 定义Yarn或Kubernetes中扩展资源的配置键external-resource.gpu.yarn.config-key: yarn.io/gpuexternal-resource.gpu.kubernetes.config-key: nvidia.com/gpu# 定义插件 GPUDriver 的工厂类。external-resource.gpu.driver-factory.class:org.apache.flink.externalresource.gpu.GPUDriverFactory
对于任何扩展资源,用户首先需要将它的名称加入 "external-resources" 中,这个名称也会被用作该扩展资源其他相关配置的前缀来使用。示例中,我们定义了一种名为 "gpu" 的资源。
在调度层,目前支持用户在 TaskManager 的粒度来配置扩展资源需求。示例中,我们定义每个 TaskManager 上的 GPU 设备数为 1。
将 Flink 部署在 Kubernetes 或是 Yarn 上时,我们需要配置扩展资源在对应的资源底座上的配置键,以便 Flink 对资源需求进行转发。示例中展示了 GPU 对应的配置。
如果提供了插件,则需要将插件的工厂类名放入配置中。
■ 3.2 前置准备
在 Standalone 模式下,集群管理员需要保证 GPU 资源对 TaskManager 进程可见; 在 Kubernetes 模式下,需要集群支持 Device Plugin[6],对应的 Kubernetes 版本为 1.10,并且在集群中安装了 GPU 对应的插件; 在 Yarn 模式下,GPU 调度需要集群 Hadoop 版本在 2.10 或 3.1 以上,并正确配置了 resource-types.xml 等文件。
■ 3.3 扩展资源框架插件
public interface ExternalResourceDriverFactory {/*** 根据提供的设置创建扩展资源的Driver*/ExternalResourceDriver createExternalResourceDriver(Configuration config) throws Exception;}public interface ExternalResourceDriver {/*** 获取所需数量的扩展资源信息*/Set<? extends ExternalResourceInfo> retrieveResourceInfo(long amount) throws Exception;}
4. GPU 插件
当调用脚本时,所需要的 GPU 数量将作为第一个参数输入,之后为用户自定义参数列表; 若脚本执行正常,则输出 GPU Index 列表,以逗号分隔; 若脚本出错或执行结果不符合预期,则脚本以非零值退出,这会导致 TaskManager 初始化失败,并在日志中打印脚本的错误信息。
5. 在算子中获取扩展资源信息
public class ExternalResourceMapFunction extends RichMapFunction<String, String> {private static finalRESOURCE_NAME="gpu";public String map(String value) {Set<ExternalResourceInfo> gpuInfos = getRuntimeContext().getExternalResourceInfos(RESOURCE_NAME);List<String> indexes = gpuInfos.stream().map(gpuInfo -> gpuInfo.getProperty("index").get()).collect(Collectors.toList());// Map function with GPU// ...}}
6. MNIST Demo
class MNISTClassifier extends RichMapFunction<List<Float>, Integer> {public void open(Configuration parameters) {//获取GPU信息并且选择第一块GPUSet<ExternalResourceInfo> externalResourceInfos = getRuntimeContext().getExternalResourceInfos(resourceName);final Optional<String> firstIndexOptional = externalResourceInfos.iterator().next().getProperty("index");// 使用第一块GPU的index初始化JCUDA组件JCuda.cudaSetDevice(Integer.parseInt(firstIndexOptional.get()));JCublas.cublasInit();}}
class MNISTClassifier extends RichMapFunction<List<Float>, Integer> {public Integer map(List<Float> value) {// 使用Jucblas做矩阵算法JCublas.cublasSgemv('n', DIMENSIONS.f1, DIMENSIONS.f0, 1.0f,matrixPointer, DIMENSIONS.f1, inputPointer, 1, 0.0f, outputPointer, 1);// 获得乘法结果并得出该图所表示的数字JCublas.cublasGetVector(DIMENSIONS.f1, Sizeof.FLOAT, outputPointer, 1, Pointer.to(output), 1);JCublas.cublasFree(inputPointer);JCublas.cublasFree(outputPointer);int result = 0;for (int i = 0; i < DIMENSIONS.f1; ++i) {result = output[i] > output[result] ? i : result;}return result;}}
四、未来计划
除了上文介绍的这些已经发布的特性外,Apache Flink 社区也正在积极准备更多资源管理方面的优化特性,在未来的版本中将陆续和大家见面。
被动资源调度模式:托管内存使得 Flink 任务可以灵活地适配不同的 TaskManager/Slot 资源,充分利用可用资源,为计算任务提供给定资源限制下的最佳算力。但用户仍需指定计算任务的并行度,Flink 需要申请到满足该并行度数量的 TaskManager/Slot 才能顺利执行。被动资源调度将使 Flink 能够根据可用资源动态改变并行度,在资源不足时能够 best effort 进行数据处理,同时在资源充足时恢复到指定的并行度保障处理性能。 细粒度资源管理:Flink 目前基于 Slot 的资源管理与调度机制,认为所有的 Slot 都具有相同的规格。对于一些复杂的规模化生产任务,往往需要将计算任务拆分成多个子图,每个子图单独使用一个 Slot 执行。当子图间的资源需求差异较大时,使用相同规格的 Slot 往往难以满足资源效率方面的需求,特别是对于 GPU 这类成本较高的扩展资源。细粒度资源管理允许用户为作业的子图指定资源需求,Flink 会根据资源需求使用不同规格的 TaskManager/Slot 执行计算任务,从而优化资源效率。
五、总结
首先从本地内存、Job Graph 编译阶段、执行阶段来解答每个流程的内存管理以及内存分配细节,通过新的参数配置控制 TaskManager的内存分配; 然后从大家平时遇到资源调度相关问题,包括最大 Slot 数使用,如何进行 TaskManager 进行容错,任务如何通过任务平铺均摊任务资源; 最后在机器学习和深度学习领域常常用到 GPU 进行加速计算,通过解释 Flink 在 1.12 版本如何使用扩展资源框架和演示 Demo, 给我们展示了资源扩展的使用。再针对资源利用率方面提出 2 个社区未来正在做的计划,包括被动资源模式和细粒度的资源管理。
六、附录

 戳我,查看更多技术干货~
戳我,查看更多技术干货~