
都给我开口说话!MakeItTalk的神奇魔法让你和蒙娜丽莎对话

新智元报道
新智元报道
编辑:卫民、白峰
【新智元导读】最近,麻省大学Amherst分校的Yang Zhou博士和他的团队提出了一种具有深度结构的新方法「MakeItTalk」。给定一个音频语音信号和一个人像图像作为输入,模型便会生成说话人感知的有声动画图。
富有表现力的动画谁都想要!
面部动画在很多领域都是一项关键技术,比如制作电影、视频流、电脑游戏、虚拟化身等等。

尽管在技术上取得了无数的成就,但是创造逼真的面部动画仍然是计算机图形学的挑战。
一是整个面部表情包含了完整面部各部分之间的相互关系,面部运动和语音之间的协同是一项艰巨的任务,因为面部动态在高维多重影像中占主导地位,其中头部姿势最为关键。
二是多个说话人会有不同的说话方式,控制嘴唇一致,不足以了解说话的人的性格,还要表达不同的个性。
针对上述问题,Yang Zhou博士和他的团队提出了一种具有深度结构的新方法「 MakeItTalk」。
这是一种具有深度架构的新方法,只需要一个音频和一个面部图像作为输入,程序就会输出一个逼真的「说话的头部动画」。
下面,我们就来看看,MakeItTalk的是如何让图片「说话」的。
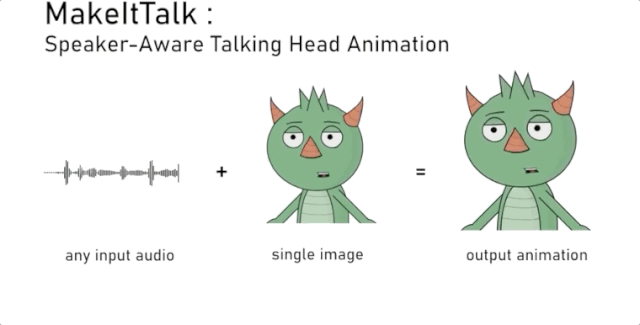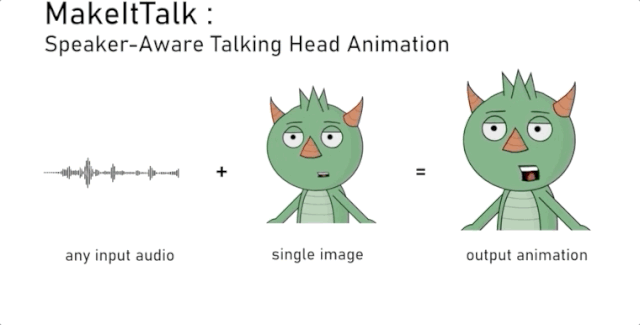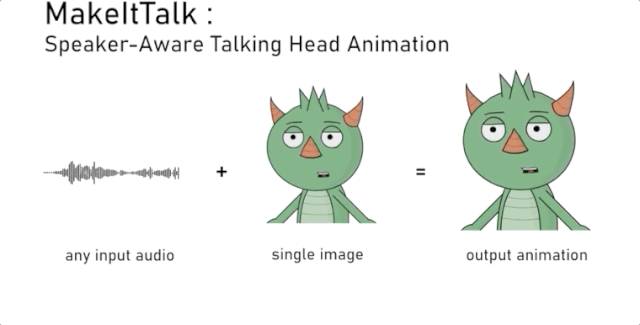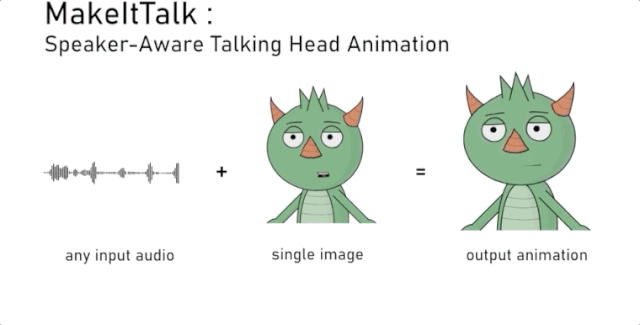
都给我开口说话!神奇的 MakeItTalk 是什么?
都给我开口说话!神奇的 MakeItTalk 是什么?
MakeItTalk是一个新的深度学习为基础的架构,能够识别面部标志、下巴、头部姿势、眉毛、鼻子,并切能够通过声音的刺激使嘴唇发生变化。
模型以LSTM 和 CNN 为基础,可以根据说话人的音调和内容,让面部表情和头部产生随动。

本质上, MakeItTalk将输入音频信号中的内容和说话人分离出来,从产生的抽象表示中提取出对应的动画。
而嘴唇和相邻面部的协同也尤为重要。说话者的信息被用来获取其他面部表情和头部动作,而这些对于生成富有表现力的头部动画是必需的。
MakeItTalk模型既可以生成逼真的人脸说话图像,也可以生成非逼真的卡通说话图像。

声音+图像=「开口说话」?MakeItTalk是如何做到的?
声音+图像=「开口说话」?MakeItTalk是如何做到的?
下面的图表显示了生成逼真的说话头像的完整方法和途径:
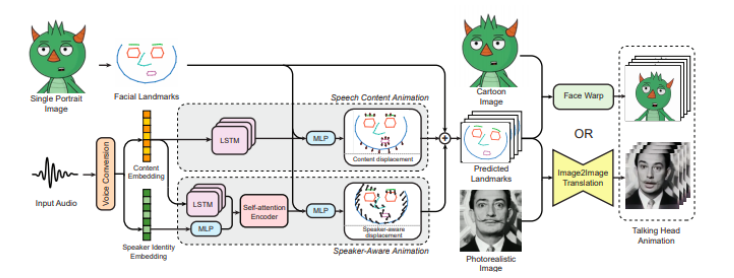
(1)一个音频剪辑和一个单一的面部图像可以制作一个与音频协调的,能感知说话者的头部动画。
(2)在训练阶段,使用现成的人脸检测器对输入的视频进行预处理,提取标记,从输入的音频中训练基础模型,实现语音内容转动画和标记的精确提取。
(3)为了获得高精度的运动,通过对输入音频信号的分离内容和说话人嵌入来检测标记点的估计。为此,采用语音转换神经网络对语音内容进行提取,发现语音内容。
(4)内容与说话者无关,并且捕获了嘴唇和相邻部位的常见运动,其中说话内容调节了动作的特征和说话者头部动作的剩余部分。

(5)嘴唇的大小和形状随着眼睛、鼻子和头部的运动而扩大,这取决于谁说了这个词,也就是说话人身份。
(6)最后,为了生成转换后的图像,MakeItTalk采用了两种算法进行标记到图像的合成:
对于非真实感的图像,如画布艺术或矢量艺术,一个特定的畸变方法是在 Delaunay triangulation 的基础上部署;
对于真实感图像,构建一个图像到图像的转换网络(与 pix2pix 相同) ,直接转换自然人脸。
最后,混合所有的图像帧和音频共同生成头部动画。
作者简介
该项目的作者本科毕业于上海交通大学电子工程系,然后在乔治亚理工学院获得了硕士学位,现在是马萨诸塞大学阿默斯特分校计算机图形学科学研究小组的一名计算机科学博士生。

Yang Zhou在计算机图形学和机器学习领域工作。主要致力于用深度学习技术来帮助艺术家、造型师和动画师做出更好的设计。
如果也想给你的设计加点AI的基因,Yang Zhou的论文列表绝对是个不错的选择,有很多关于动画生成和多模态深度学习的研究。
参考链接:
https://github.com/yzhou359/MakeItTalk

