
如何设计一个无状态应用
概述
无状态应用 (服务) 是一种微服务架构设计原则,通过将服务的业务逻辑与状态数据进行分离来提高应用本身的扩展性,保证应用以更可靠的方式运行,同时降低了业务功能实现复杂度。
状态隔离
保持服务内部逻辑简单 (例如只做计算并返回结果数据),将服务中和状态相关的数据保存到服务的实例之外 (例如用户购物车),这样每个服务实例都可以处理所有的请求。
不可变对象
使用不可变的数据结构来表达语义,确保请求中的相关数据不会发生变化且全局唯一。
常见的不可变对象:
-
RequestId: 请求 ID
-
EventId: 事件 ID
-
TransactionId: 订单 ID
-
LogId: 日志 ID
-
TraceId: 链路 ID
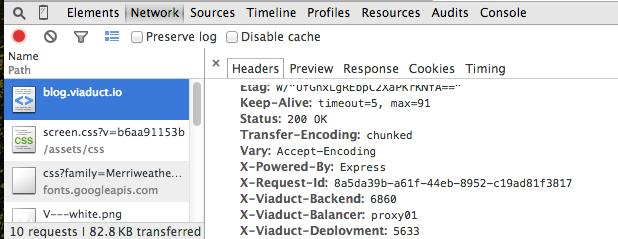
RequestId 示例
Auth
使用基于令牌 Token 的身份验证机制 (例如 JWT),这样每个服务都可以验证用户的单个请求,不需要维护用户相关状态信息。
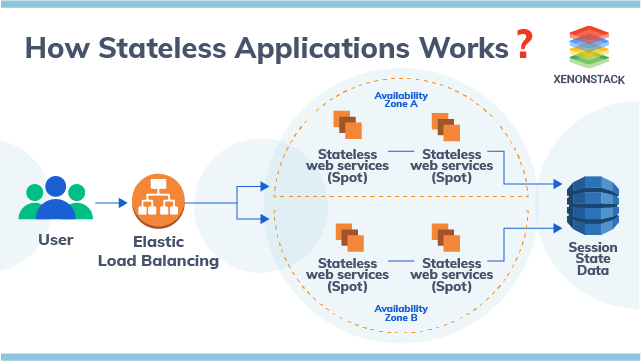
图片来源: https://www.xenonstack.com/insights/stateful-and-stateless-applications
水平伸缩
将应用设计为可以水平伸缩,每个实例可以独立运行并接收处理请求,并且各实例之间没有依赖的共享资源或全局会话 (例如传统的 Session 机制)。对于缓存数据,可以有专用的集群供单个服务组中所有实例使用,对于缓存中的热点数据,每个实例可以单独在本地存储一份。
幂等
确保服务 API 操作是幂等的,这样调用方因为网络问题请求失败时,可以直接重新发起请求。
常见的保证幂等性的方法:
-
唯一的 RequestId (请求 ID): 每个请求都应该有一个唯一的请求 ID, 在发起重复请求的时候,服务方可以根据该标志符确认操作是否已经完成
-
操作事务性执行: 将多个操作组合成事务,如果其中的某个操作在事务中执行失败,可以使用回滚机制
-
乐观锁并发控制: 调用方请求更新资源时必须提供类似 “版本号机制” 中的版本号字段,服务方只有在版本号匹配时才会执行操作
-
操作日志: 将已经处理的请求和操作写入日志,重复请求时可以查找以避免重复处理
业务组件与代码分离
将服务的基础组件 (例如日志、监控、链路追踪) 与服务实例进行分离,例如使用 Prometheus 监控整个集群中的所有服务。
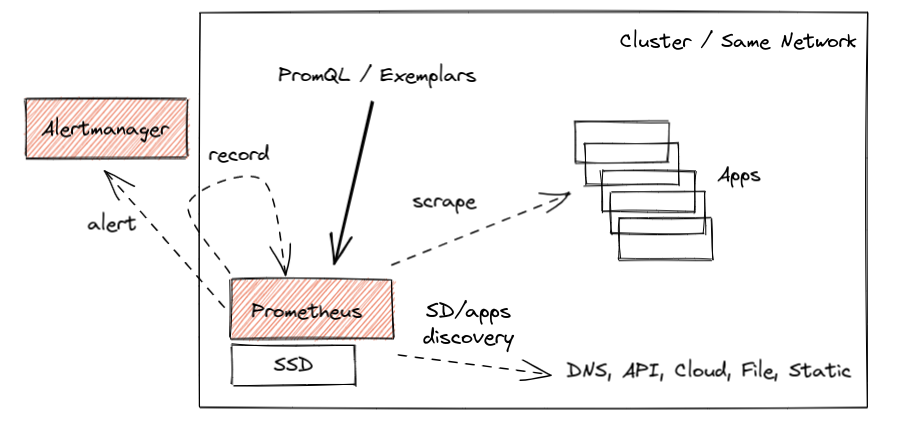
图片来源: https://prometheus.io/blog/2021/11/16/agent/
基于消息的通信
使用消息队列作为服务间的事件通知方式,解耦服务间的耦合并使服务间通信变为异步方式。
配置和代码分离
将服务的代码和配置进行分离,这样可以分别进行管理,服务内部可以定时拉取配置实现热更新,配置数据修改后不需要重新部署服务。常见的实现方案为建立专用的服务配置中心 (如 etcd),或者使用 Kubernetes 中的 ConfigMap 实现热更新[1]。
静态资源分离
将服务中所有静态资源直接通过 CDN 进行分发。
Kubernetes 中的无状态
Kubernetes 推崇尽可能将服务应该尽可能设计为无状态,因为:
-
容器重启后数据会丢失
-
调度会引发 Pod 的 IP 和主机名发生变化
-
节点故障后,该节点上面所有的 Pod 的数据都会丢失
-
等等 ...
Kubernetes 官网提供了一个 无状态的留言板示例应用[2]。
扩展阅读
-
Stateful and Stateless Applications and its Best Practices[3]
-
Stateful vs. Stateless Web App Design[4]
-
Cloud Native Application Architecture[5]
链接
实现热更新: https://dbwu.tech/posts/k8s/best_practice/base/
[2]无状态的留言板示例应用: https://kubernetes.io/zh-cn/docs/tutorials/stateless-application/guestbook/
[3]Stateful and Stateless Applications and its Best Practices: https://www.xenonstack.com/insights/stateful-and-stateless-applications
[4]Stateful vs. Stateless Web App Design: https://blog.dreamfactory.com/stateful-vs-stateless-web-app-design/
[5]Cloud Native Application Architecture: https://medium.com/walmartglobaltech/cloud-native-application-architecture-a84ddf378f82