
系统设计面试:如何设计一个 Pastebin
今天分享一下如何设计一个类 Pastebin 的 web 服务,用户可以存储纯文本,然后获得一个随机生成的 URL,其他人可以通过这个 URL 来访问文本内容,这很像一个在线共享粘贴板的服务,如果你还没有使用过,可以访问 pastebin.com 来试用。
1.为什么需要 pastebin ?
一开始,pastebin 主要用来分享代码,程序员写完代码后想给别人看,直接把代码粘贴至 pastebin,然后把 url 发给其他人,其他人点开链接就可以直接看到代码,代码的缩进格式会保持不变,代码评审人员看起来会比较舒服。实际上,任何纯属文本数据都可以通过 pastebin 来共享,比如以下应用场景:
用做一个在线的纯文本文档。 突破限制,发一些长推文。比如 twitter 限制只能发 140 个字符的推文,这样我们将长推文写在 pastebin 上,然后在 twitter 上发 url 即可。 上传源代码用于代码评审和合作。 重新发表一些被主流网站删除的文章。 垃圾邮件/网站的促销活动,因为内容是一个链接,可以绕过反垃圾、反广告系统。 分享一些黑色的网站,宣传一些隐私的活动或其他敏感信息,因为生成的 url 是不可猜测的。
我承认后面的 4、5、6 的用途有点坏,目前 pastebin 的 FAQ 页面已禁止发表以下内容:
email 地址或者密码 登陆信息 被偷的源代码、数据 涉及版权的信息 银行卡信息 垃圾广告信息 个人隐私
pastebin 的初衷是对用户友好的,无需注册或者登陆即可使用,而且可以分享超长文本,让用户分享文本变得更容易,目前 pastebin 每月有 1700 万活跃用户。
2.需求及系统目标
我们的 Pastebin 服务需要满足以下需求
功能性需求:
用户可以上传他们的数据并获得一个唯一的,可以访问数据的 url。 用户只能上传文本。 数据和链接会在默认的时间后过期,用户可以指定过期时间。 用户可以指定一个自定义格式的 url。
非功能需求:
服务是高可靠、高可用的,用户上传的文本数据不能丢失,保证可以随时访问上传的数据。 用户可以实时访问链接中的数据,延迟低。 生成的 url 是不可猜测的。
扩展需求:
数据分析需求,比如一个 url 被访问了多少次。 我们的服务可以被其他服务以 REST API 的访问。
3.一些设计考虑
Pastebin 和前文如何设计一个短链接系统有着相似的需求,但是也有一些额外的设计考虑:
用户一次提交的文本数量应该限制为多少?我们可以限制用户提交的 文本总大小不能超过 10 MB,防止服务被滥用。
是否应该限制自定义 url 的大小?由于我们的服务支持自定义网址,因此用户可以选择他们喜欢的任何 URL,但并非必须提供自定义URL。对自定义网址施加大小限制是合理的,以便我们拥有相对一致的网址数据库。
4.容量估算和约束
我们的服务将是读繁重的,与新生成的文本相比,会有更多的读取文本的请求。这里可以假设读写之间的比例为 5:1。
流量估算
Pastebin 服务的流量不会类似于 Twitter 或 Facebook,假设在这里,我们每天将 100 万个新文本添加到我们的系统中。这样,每天的读操作就是 500 万次。也就是每秒新增 12 个文本,58 次访问:
1M / (24 hours * 3600 seconds) ~= 12 pastes/sec
5M / (24 hours * 3600 seconds) ~= 58 reads/sec
存储估算
用户可以提交的内容最多为 10 MB,一般使用类 Pastebin 服务的文本基本是源代码、配置信息、日志等,这类文本都不大,假设每一个文本的平均大小为 10 KB,这样,系统每天会消耗 10 GB 的存储空间来存储新增的文本:
1M * 10KB => 10 GB/day
如果这些数据需要保存 10 年,那么总共需要 36 TB 的存储空间。每天有 100 万个新文本,对应 100 万个新的 url,10 年会产生 36 亿个 url,使用 base64 编码的话,至少需要 6 个字符,那么 36 亿个 url 需要的存储空间为 22 GB。
3.6B * 6 => 22 GB
22 GB 相比 36 TB 是可以忽略不计的,考虑到系统要预留一些存储防止存储爆满,设计存储空间会比需要的多一些,比如让系统使用的存储占比永不超过 70 %,那么我们总共就需要 36/0.7 = 51.4 TB。
带宽估算
对于写操作的频率为 12次/秒,每次文本平均 10 KB,那么写操作占用的带宽约为 120 KB/s。
对于读操作,频率为 58次/秒,读操作占用服务器的带宽约为 58 * 10 KB = 0.6 MB/s。
尽管总入口和出口并不大,但在设计服务时应当应牢记这些数字。
内存估算
我们应该缓存一些经常被访问的热点数据,根据 80/20 法则,20% 的数据承担了 80% 的访问流量,因此我们缓存这些 20% 的数据,由于每天有 500 万次访问,那么我们需要缓存 500 * 20% = 100 万的文本数据,占用内存的大小为 100 M * 10 KB = 10 GB。
5.系统 API
我们可以使用 SOAP 或 REST API 来开放我们的服务。以下是用于创建/检索/删除粘贴的 API 的样例:
addPaste(api_dev_key, paste_data, custom_url=None, user_name=None, paste_name=None, expire_date=None)
其中 api_dev_key 是为注册用户生成的一个 key,可用于限流或其他与用户相关的业务管理。如果调用成功,函数返回一个可用于访问提交文本(paste)的 url,如果失败,则返回错误代码。
类似的,检索 API 如下:
getPaste(api_dev_key, api_paste_key)
其中 api_paste_key 标识提交的文本,在数据库中对应着文本的主键。
删除 API 如下:
deletePaste(api_dev_key, api_paste_key)
删除成功返回 True,失败则返回 False。
6.数据库设计
我们要存储的数据有以下性质:
我们需要存储数十亿条记录。 我们存储的每个元数据对象都将很小(小于 100 个字节)。 我们存储的文本对象的大小都可以是中等大小(可以是几 MB)。 记录之间没有关系,除非我们要存储哪个用户创建了什么粘贴。 查询任务比写入任务繁重。
数据库架构:
我们需要两个表,一个表用于存储有关粘贴的信息 Paste,另一个表用用户相关的数据 User。表字段如下
Paste:
pasteId:主键 urlHash:代表访问文本的 url 的字符串 content:存储文本的内容 createAt:创建时间 expireAt:过期时间 userId:对应的用户id
User:
userId:主键 name:用户名/姓名 email:邮箱 createAt:创建日期 lastLogin:上次登陆时间
7.顶层设计
在更高层级上,我们需要一个应用程序层来满足所有的读取和写入请求。应用层通过与存储层进行交互来存储和检索数据。我们可以用数据库来隔离存储层,一个数据库存储每个文本、用户等相关的元数据,而另一个数据库存储文本对象的内容,可以存储在一些对象存储服务器,例如 Amazon S3。这种数据划分可以对他们分别进行扩展。
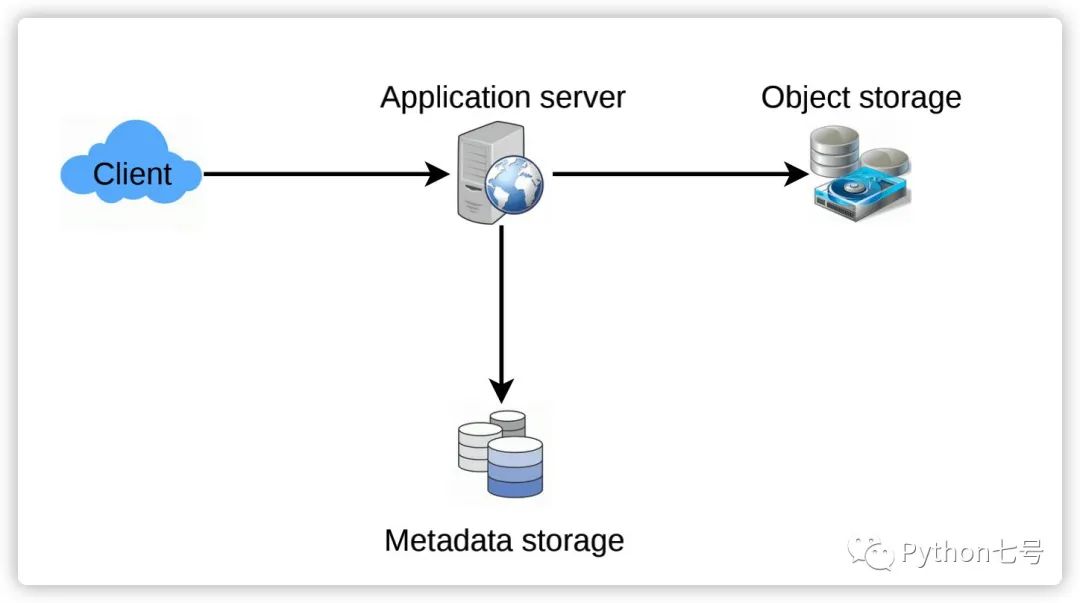
8.模块设计
a.应用层
应用层通过访问后端存储处理所有的请求,那么如何处理一个写请求呢?收到写入请求后,我们的应用程序服务器将生成一个六个字母的随机字符串,它将用作文本 url 的键(如果用户未提供自定义键)。然后,应用程序服务器将文本内容和生成的 key 存储在数据库。成功插入后,服务器可以将 key 返回给用户。一种可能的问题是,由于 key 是随机生成的字符串,可能会因为重复而导致插入失败,在这种情况下,我们应该重新生成一个 key,然后重试,直到不重复为止,如果用户提供的自定义 key 已经存在于我们的数据库中,同样提醒用户重新自定义 key。
上述问题的另一种解决方案是运行独立的 key 生成服务(KGS),可以预先随机生成六个字母字符串,并将其存储在数据库中(我们称其为 key 数据库)。每当我们要存储一个新的文本时,我们就从 KGS 中获取一个已经生成的 key 并使用它。这种方法将使事情变得非常简单和快捷,因为我们不必担心重复或碰撞。KGS 将确保插入到 key 数据库中的所有 key 都是唯一的。KGS 可以使用两个表存储 key ,一个用于尚未使用的 key ,另一个用于所有已使用的 key 。只要 KGS 给应用程序服务器的某些 key ,它可以将这些 key 移到“已使用 key ”表中。KGS 可以随时保持内存中的某些 key ,以便服务器在需要时可以快速提供它们。一旦 KGS 将一些 key 加载到内存中,就将它们移动到使用过的 key 表中,这样我们可以确保每个服务器都有唯一的 key 。如果 KGS 在使用内存中加载的所有 key 之前死亡,我们将浪费那些钥匙。鉴于我们拥有大量 key ,这些小概率的浪费是可以接受的。
KGS 存在单点故障吗?是的。为了解决这个问题,我们可以有一个 KGS 的备机,只要主服务器死了,它就可以接管生成并提供 key 。
每个应用服务器都可以从 key-DB 缓存一些 key 吗?是的,这肯定可以加快速度。虽然在这种情况下,如果应用服务器在使用所有 key 之前就死了,那么我们最终将丢失这些 key 键。这是可以接受的,因为我们有 680 亿个唯一的六个字母的键,这一点点的浪费可以忽略不计。
如何处理读取请求?收到读请求后,应用程序服务层访问数据存储区。数据存储区搜索 key ,如果找到 key ,则返回粘贴的内容。否则,将返回错误代码。
a.数据存储层
元数据比较小,而文本内容可能会比较大,为了便于扩展数据库,我们可以将数据存储层分为两层:
元数据数据库:可以使用关系数据库,例如 MySQL 或分布式键值,像 Dynamo 或 Cassandra,占用空间比较小,基本不需要扩展。 对象存储:可以将内容存储在类似于 Amazon S3 的对象存储中。每当占用空间要达到内容存储的全部容量时,可以轻松增加存储空间。
9.清除或数据库清理
请参阅 如何设计一个短链接系统
10.数据分区和复制
请参阅 如何设计一个短链接系统
11.缓存和负载平衡器
请参阅 如何设计一个短链接系统
12.安全性和权限
请参阅 如何设计一个短链接系统
最后的话
系统设计的思路都是一致的,从需求分析、资源估算、API 设计、数据库设计、顶层设计、分模块设计、数据清理、数据分区、缓存、负载均衡、安全和权限等步骤,基本上包括了 IT 系统建设和运维的各个环节,即要从全局考虑,也不能忽略重要的细节,系统设计能力体现了程序员处理复杂问题的能力,如果觉得有帮助,请点赞、在看、关注支持。
推荐阅读: