
如何设计一个消息中心

如今的内容型产品,不管提供的是什么类型的内容,在其主功能之外,不可避免的会有另一个十分重要的功能——消息中心。
而无论是信息流、论坛、信箱,还是私聊、群聊、通知,推拉模型是内容型(包括:社交型)产品架构的核心。做出正确选择的关键在于对产品形态和系统组件清晰的认识。
今天我们将重心放在消息中心上,聊一聊如何设计一个消息中心。
需求分析
消息中心通常会有两个功能(如下图所示):
用户通知(点赞、评论、关注、@等)
官方通知
接下来我们将会对这两类通知进行一个简单的抽象。
首先,可以确定的是,对于用户通知,每个用户都不一样(我的点赞列表和你的点赞列表肯定是不一样的),因此对于每个人我们都需要维护一个「收件箱」。
当 A 点赞了 B 的内容,后端系统在收到了这一个点赞消息后,会将点赞信息写入 B 的 「收件箱」,并标明这是 A 在 xxx 时点赞的 xxx 内容。这是一个系统将消息 推送 给 B 的过程。
而对于官方通知,每个人(几乎)都是一样的(用户有可能设置了屏蔽,系统也可能指定了发送人群),并且官方通知是由系统自然下发的,因此对于系统来说需要维护一个系统「发件箱」。
发件箱维护了官方想给用户的通知,每次打开消息中心时,用户都会主动来系统「拉取」官方最新的消息,并和用户自己的「收件箱」里的官方通知进行比较,以确认是否已读该条通知。这是一个用户主动从系统「拉取」通知的过程。
推拉模型
其实到这里就已经点出了这两个场景背后的一套模型——推拉模型。而之所以在这两种场景选择不同的运行机制,其实背后牵扯到的是读写扩散的问题。
推模型
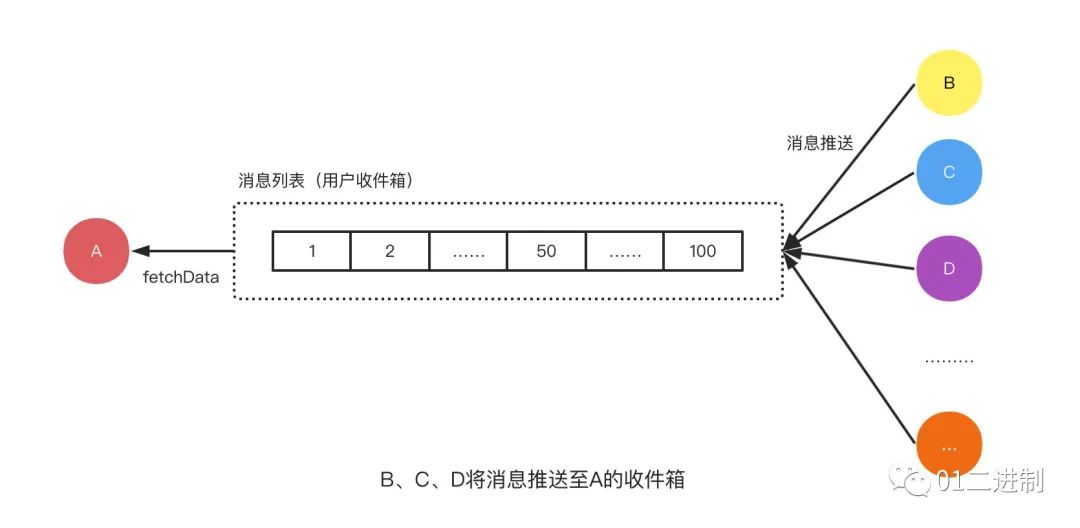
先看推模型,对于任何一个内容创作者来说,最开心的事情莫过于打开软件会有一堆点赞/评论的小红点。对于大 V 来说,打开 App 查看点赞消息的频率根本比不过别人给你点赞的频率,这是一个很典型的读少写多的场景。每当有一个用户点赞该大 V 时,都会将索引信息(一般为内容 ID、类型、发表时间等索引数据)写到用户的收件箱中。
优点:读很轻。仅需要读取消息列表即可。
缺点:写很重。一旦用户的内容质量很高,可能会收到大量的点赞/评论,会有大量的写入操作。
拉模型
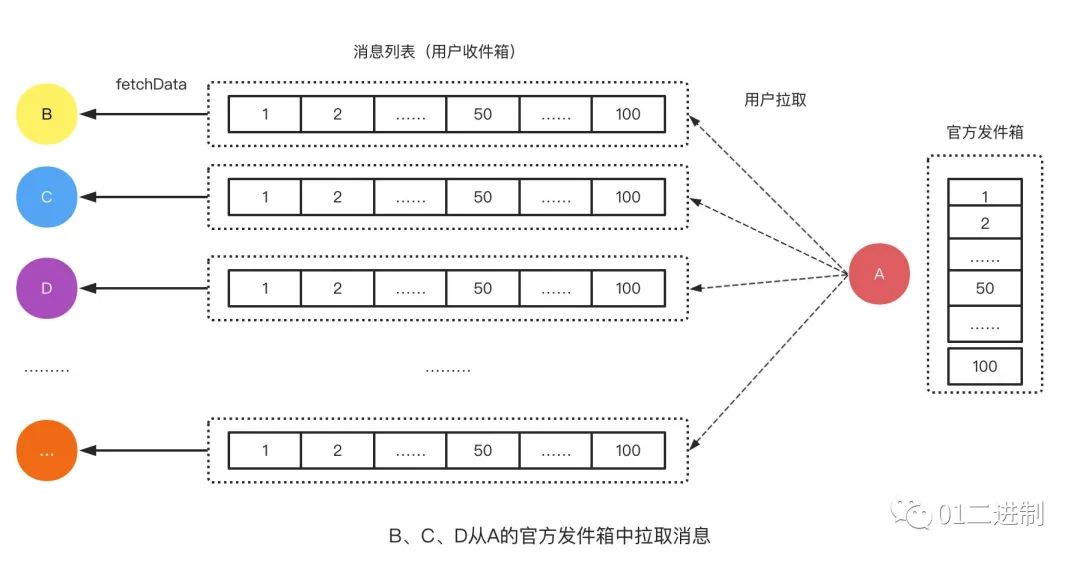
再看拉模型,以官方通知为例,一般官方通知是由运营人员发布的,一个月可能也不会有几条,但是每次用户进入 App 时都会看看是否有新的官方通知进来,这是一个很典型的读多写少的场景。
优点:写很轻,节省空间。系统只需维护一个属于自己的消息列表即可。
缺点:读很重,计算量大。假设可以发送官方通知的生产者较多(例如淘宝里的一系列官方业务),则每次都需要从这些消息生产者里拉取最新的内容。
流程设计
用户通知
对于用户通知,流程设计如下:
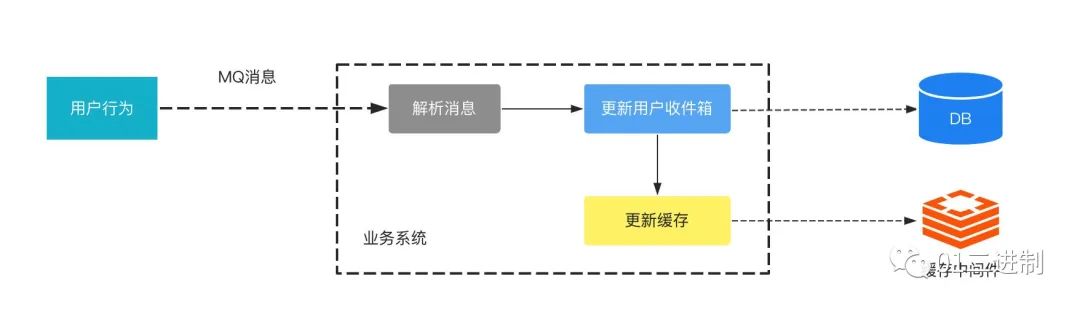
对于该流程,有几点需要注意的:
异步发送
当用户出发了点赞/关注/评论行为时,被点赞/评论/关注的用户,其实不需要立即感知,因此也不需要立即将互动信息写入该用户的收件箱中,因此可以考虑以消息队列的方式通知出去,缓解系统压力。
缓存前置
写入消息时,如果直接写入用户收件箱,可能会导致用户在请求消息列表时,将请求全部打到 DB,造成系统故障,因此通常会在更新用户收件箱时双写用户缓存。
官方通知

相较于用户通知,官方通知由于引入官方运营这一角色,操作上会稍微复杂一些(如上图所示),因此整个系统的设计也会稍微复杂一些。
官方运营发送通知到「发件箱」中,「发件箱」中保留所有在线的通知列表。用户查看通知列表时,从官方「发件箱」中获取到未读通知,从自己的「收件箱」中查询历史通知。即:
运营写发件箱
用户读发件箱
用户写收件箱
流程示意图如下
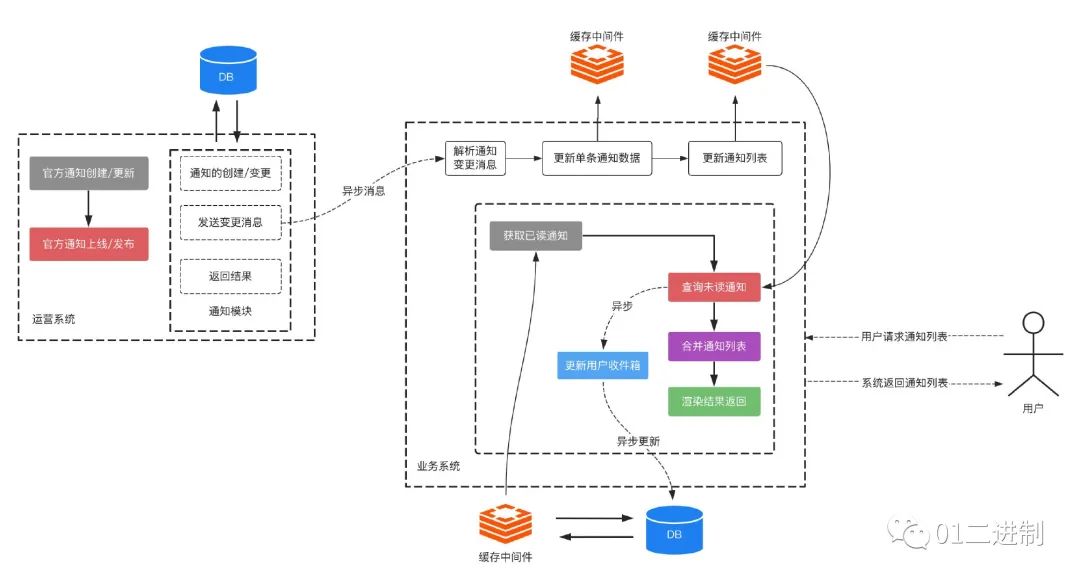
官方运营在运营后台进行通知的编辑和发布,发布的通知更新到数据库中进行持久化存储。(这里选择 mysql 数据库进行数据持久化,下一章节将会提到)
通知发生变更时,会发送通知变更消息。基于该消息更新单条通知的缓存,并更新官方发件箱列表(供前台查询)。
用户查看通知列表时,若为第一页,需要从官方发件箱队列查看是否有未读的通知。
若有未读通知,则和历史通知第一页合并,返回给用户。同时异步写入用户的收件箱中。
持久化方案
说完了核心的业务流程后,接下来要面临的问题就是,数据存在哪?
上文有提到会将官方通知的发件箱利用 mysql 持久化,因为官方通知的数量较少,且官方通知是一个拉模型,重读轻写,压力多半由缓存来扛,所以底层数据存储在 mysql 中并无大碍。
重难点主要在用户的「收件箱」。
之前有提过,用户收件箱的逻辑是一个重写轻读的推模型,一旦大 V 的内容更新,他的收件箱可能在一瞬间涌入大量的写流量。另外,对于几个头部大 V 来说,收到几千万的点赞并不是什么难事,每一个点赞信息都要写入到该用户的收件箱中,这就要求了底层存储需要能支持海量数据。
基于以上情景,MySQL 可能并不是一个合适的持久化方案。此时,我们可以尝试使用 HBase。

MySQL 与 HBase
MySQL 和 HBase 是我们日常应用中常用的两个数据库,分别解决应用的在线事务问题和大数据场景的海量存储问题。
综合对比
MySQL:是常用的数据库,采用行存储模式,底层是 binlog,用来存储业务数据,数据存储量较小。
HBase:列式数据库,底层是 hdfs,可以存储海量的数据,主要用来存储海量的业务数据和日志数据。
从引擎结构看差异
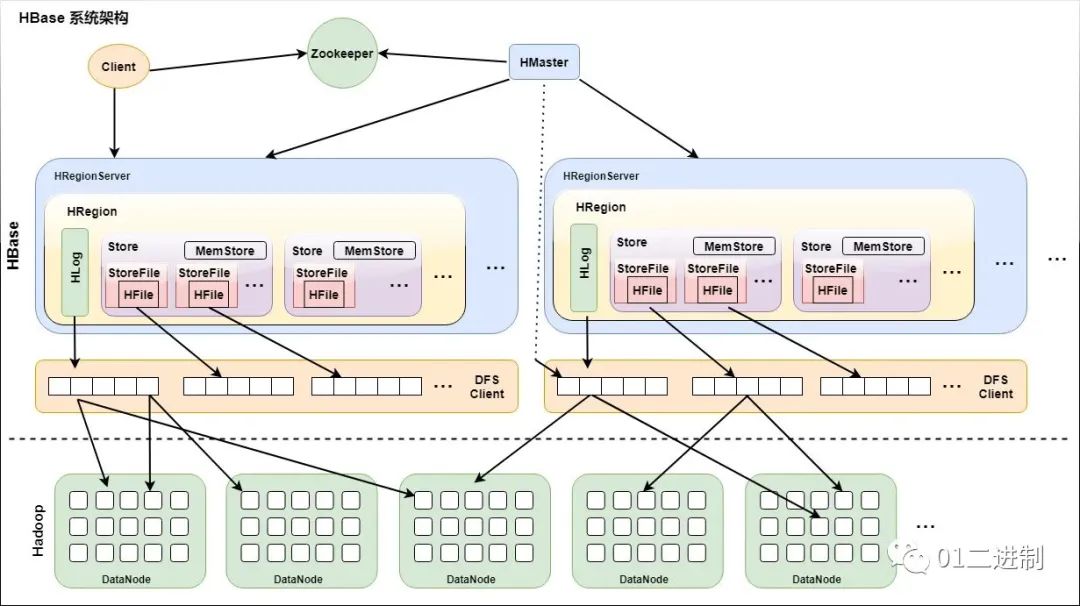
HBase 和 MySQL 的核心差异在于底层的数据结构,HBase 使用 LSM(Log-Structure Merge)树,Innodb 使用 B+树。
LSM 树,即日志结构合并树(Log-Structured Merge-Tree)。其实它并不属于一个具体的数据结构,它更多是一种数据结构的设计思想。
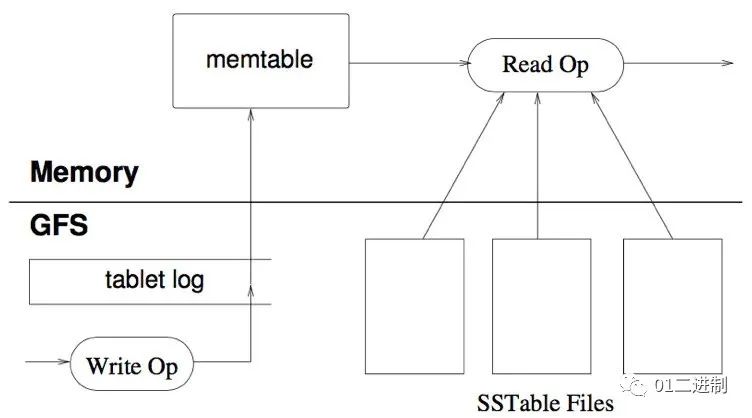
它的核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到最后多之后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾 (因为所有待排序的树都是有序的,可以通过合并排序的方式快速合并到一起)。
LSM 具有批量特性,存储延迟。当写读比例很大的时候(写比读多),LSM 树相比于 B 树有更好的性能。因为随着 insert 操作,为了维护 B 树结构,节点分裂。读磁盘的随机读写概率会变大,性能会逐渐减弱。多次单页随机写,变成一次多页随机写,复用了磁盘寻道时间,极大提升效率。
因此,由引擎结构(B+Tree vs LSM Tree)看到的能力差异:
MySQL:读写均衡、存在空间碎片
HBase:侧重于写、存储紧凑无浪费、Io 放大、数据导入能力强
从架构对比看差异
相比 MySQL,HBase 的架构特点:
完全分布式(数据分片、故障自恢复)
底层使用 HDFS(存储计算分离)。
由架构看到的能力差异:
MySQL:运维简单(组件少)、延时低(访问路径短)
HBase:扩展性好、内置容错恢复与数据冗余
总结
本文我们讲述了如何从官方通知和用户通知两个方面切入,设计一个 App 的常见功能——消息中心。但该方案仍然有很多潜在的问题:如果官方通知的来源很多呢?如何解决写扩散带来的成本问题?这些都是值得探索的问题。
事实上,消息中心虽然是一个十分常见的功能,但背后涉及到的东西非常复杂,发布/订阅、推拉模型、读写扩散等问题都会影响到我们的架构设计。
架构设计的过程,就是取舍的过程,而如何取舍,则是一门学问。对于现在纷繁复杂的互联网业务,永远没有最好的架构,只有最适合的架构。
 最近我开通了
最近我开通了
 关注公众号回复「
关注公众号回复「
对线
」
即可免费领取《对线面试官》系列电子书
。
点击
阅读原文
跳转至Java开源消息推送平台项目仓库