
英特尔推出云端AI芯片Gaudi2,性能达英伟达A100两倍!还有16核5GHz酷睿HX处理器和2亿亿次超级计算机
北京时间5月10日晚间,在英特尔On产业创新峰会(Intel Vision)上,英特尔公布了在芯片、软件和服务方面取得的多项进展,展示了英特尔如何通过整合技术和生态系统,面向目前以及未来,为客户释放商业价值。英特尔通过一系列实际案例强调了这些价值,其中包括:改进业务成果和洞察力、减少总体拥有成本、加快产品上市时间和价值实现,以及产生积极的全球影响。
英特尔CEO帕特·基辛格表示:“全球市场正处于最具活力的时代。企业目前面临的挑战错综复杂且相互关联,而成功的关键取决于企业快速采用和最大化利用领先技术和基础设施的能力。今天,我们倍感兴奋地分享在当下复杂的环境中,英特尔如何运用其规模、资源、芯片、软件及服务,帮助客户及合作伙伴加速数字化转型。”

最高16核5GHz,全新第12代英特尔酷睿HX处理器发布
在此次会议上,英特尔宣布推出全新第12 代英特尔酷睿 HX 处理器,完善了第12代酷睿产品家族。7款新品在移动平台封装中采用了媲美台式机的芯片,为CAD、动画和视觉特效等专业工作负载提供迅猛性能。HX处理器覆盖酷睿i5、酷睿i7和酷睿i9不同型号,均带来开箱即用的未锁频性能。

其中,英特尔酷睿i9-12900HX处理器是全球性能出众的移动工作站平台,最多拥有16个核心和高达5 GHz的时钟频率,专为那些需要极致性能和出色灵活性的专业人士打造,帮助他们轻松驾驭多样工作负载。

具体来说,第12代英特尔酷睿HX处理器,通过更多的核心数、更大内存和I/O支持,把多线程工作负载的性能提升64%,同时借助英特尔®硬件线程调度器来充分释放性能核和能效核蕴含的迅猛性能,让专业人士可以在办公室、家中或旅途中以超高效率进行创作、编程、渲染和工作。除了作为工作的得力助手,第12代酷睿HX处理器还是游戏平台强者,为骨灰级游戏玩家以更高帧率畅玩熟知且喜爱的游戏。
第12代英特尔酷睿HX处理器家族在创新的移动设备中,能够提供满足生产力、协作、内容创建、游戏和娱乐体验等方面的真实场景应用需求:
●最多16核心(8个性能核和8个能效核)和24线程,处理器基础功率为55W。
●16条处理器直连PCIe Gen 5.0通道,和4x4专用平台控制器集线器(PCH)的PCIe Gen 4.0通道,增加了带宽并加快了数据传输速度。
●业界率先全线未锁频和可超频处理器。
●支持高达128GB的DDR5/LPDDR5(高达4800MHz/5200MHz)和DDR4内存(高达3200MHz/LPDDR4 4267MHz),支持纠错码(ECC)功能。
●采用英特尔®Wi-Fi 6/6E(Gig+)②,实现更好的连接性能,并支持全新的6GHz频段。
戴尔、惠普、联想等众多OEM厂商,预计将在今年推出10余款搭载第12代英特尔酷睿HX处理器的工作站和游戏设备。
AI性能达英伟达A100两倍,英特尔Habana Gaudi2发布
在英特尔On产业创新峰会上,英特尔正式发布了新一代的高性能深度学习AI训练处理器Habana Gaudi2。

早在2019年12月,英特尔就以20亿美元收购了为数据中心提供可编程深度学习加速器的厂商Habana Labs,进一步增强了英特尔的人工智能产品组合。
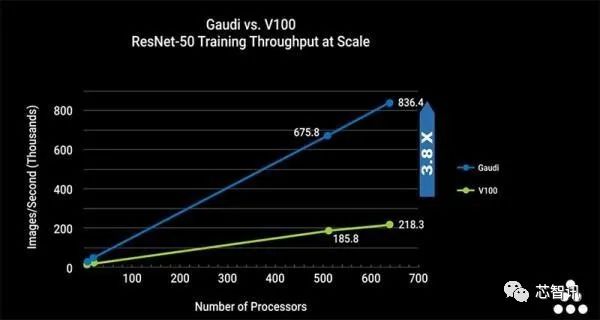
Habana Labs的第一代Gaudi处理器是一款可编程且可定制的AI处理器,搭载基于第二代Tensor处理核 (TPC) 并集成开发工具、库和编译器。基于ResNet-50,Gaudi可以提供每秒1650张的图片处理能力——这是在业界单一处理器中最高的计算能力。同时,Gaudi的创新架构可以实现训练系统性能的近线性扩展,即使是在较小Batch Size的情况下,也能保持高计算力。这意味着,基于Gaudi处理器的训练性能可以实现从单一设备扩展至由数百个处理器搭建的大型系统的线性扩展。
和英伟达的V100相比,基于ResNet-50基准测试,Gaudi所表现出来的计算性能、功耗比和延迟时间仍然相当出色,在速度上要比V100快3.8倍。比如,在性能方面,V100单卡大概每秒处理600多张图片,而Gaudi单卡则可以处理1600多张;在功耗方面,V100处理600多张图片的功耗达到了300瓦,而Gaudi处理1600多张图片的功耗只有150瓦左右。
除了性能,Gaudi处理器片上集成了 RDMA over Converged Ethernet (RoCE v2) 功能,能够让人工智能系统使用标准以太网扩展至任何规模。
此次发布的Habana Gaudi2,在深度学习实现重大飞跃:专用于高性能深度学习AI训练的Gaudi处理器,能够让客户以较低成本进行更多训练。

虽然英特尔并未公布Habana Gaudi2的细节参数,但是根据英特尔展示的性能对比数据来看,Habana Gaudi2在RestNet50 Training Throughput和BERT Tralning Throughput等视频及自然语言处理的模型测试中,性能都达到了NVIDIA A100的2倍左右。

英特尔表示,此次发布的Habana Gaudi2和Greco AI加速器是基于Synapse AI软件栈开发的,能够通过支持多样化架构,让终端用户充分利用处理器的高性能和高能效。
“阿波罗计划”让企业更易于部署AI
此外,在AI领域,英特尔还宣布携手埃森哲启动“阿波罗计划”,旨在通过为企业提供经过优化设计的愈30种开源AI解决方案,让其能够在本地、云端亦或是边缘环境中都更易于部署AI。“阿波罗计划”的首批套件预计将在未来几个月内发布。
英特尔数据中心和AI部门主管SandraRivera表示,未来五年,AI芯片市场规模预计将以每年25%的速度增长,达到500亿美元左右。她表示:“我们打算投资和创新,以引领这个市场。”
第四代英特尔®至强®可扩展处理器正式出货
英特尔还宣布正式出货了代号为Sapphire Rapids的第四代英特尔至强可扩展处理器的初始SKU。紧随其后,预计在今年还会有更多出货。

Sapphire Rapids基于Intel 7制程工艺技术,采用英特尔全新的性能核微架构,并将自家的嵌入式多芯片互连桥接(EMIB)封装技术引入了其中。此前的资料显示,Sapphire Rapids内部的四个芯片模块当中,每一个芯片模块内部最多拥有14核心(外加一个可能隐藏的),借助于EMIB封装技术,组成总计56核心。

Sapphire Rapids支持DDR5和PCIe 5.0总线,同时封装集成HBM2e高带宽内存,四个芯片模块每个最大容量16GB,合计最多64GB,带宽高达1TB/s。DDR5内存、HBM2e内存可以并行使用,支持缓存、混合多种模式。Sapphire Rapids还提供了一个单一、平衡的统一内存访问架构,借助CXL 1.1等技术,每个线程均可完全访问缓存、内存和I/O等所有单元上的全部资源,由此实现整个SoC具有一致的低时延和高横向带宽。此外,该产品亦具备针对电信网络的新功能,可以为虚拟无线接入网(vRAN)部署,提供高达两倍的容量增益。
Sapphire Rapids还配备了新的内置加速器引擎包括:英特尔®加速器接口架构指令集(AIA)——支持对加速器和设备的有效调度、同步和信号传递;英特尔®高级矩阵扩展(AMX),可为深度学习算法核心的Tensor处理提供大幅加速。其可以在每个周期内进行2000次 INT8运算和1000次 BFP16运算,实现计算能力的大幅提升。
以IPU加码未来数据中心
在此次的英特尔On产业创新峰会上,英特尔还公布了其到2026年的IPU产品路线图,其中包括基于全新FPGA和英特尔架构平台的代号为Hot Springs Canyon的产品,Mount Morga(MMG)ASIC,以及下一代800 GB产品。IPU是具有强化加速功能的专用产品,旨在满足基础设施计算需求,使企业能够高效处理任务和解决问题。

英特尔数据中心GPU发布
英特尔还面向多媒体转码、视觉图形处理和云端推理的单一GPU解决方案:代号为 Arctic Sound-M(ATS-M)的英特尔数据中心 GPU ,是英特尔在该领域首款配备 AV1 硬件编码器的独立 GPU。

据介绍,ATS-M 是一颗支持高质量转码和高性能的强大GPU,能够提供每秒 150 万亿次运算(150 TOPS)。

开发人员可以利用 oneAPI 支持的开放软件堆栈,轻松地开展面向 ATS-M 的设计工作。

ATS-M 将拥有两种不同的产品外形设计,并将获得超过 15 款来自戴尔、Supermicro、思科、HPE、浪潮和新华三等合作伙伴的系统设计。ATS-M 将于 2022 年第三季度发布。
软件基础设施计划Endgame项目
英特尔认为用户希望随时随地灵活调用计算资源。于是,在今年年初的投资者会议上宣布,将推出新的基于其独立显卡的软件基础设施计划Project Endgame。
英特尔表示,Endgame将允许用户通过云服务访问Intel Arc GPU,提供低延迟的计算解决方案,而无需自己拥有所需的硬件。这听起来非常像Nvidia基于订阅的GeForce Now服务,允许用户模拟GPU用于游戏目的,提供高达RTX 3080。
在此次峰会上,英特尔首次进行了其软件基础设施计划Endgame项目的概念演示。
英特尔表示,应用程序可以充分利用这个软件基础设施层,使设备能利用网络中其他设备的计算资源,从而提供始终可用、低时延、连续的计算服务。例如,在一台设备上运行要求苛刻的GPU工作负载时,可以感知并利用来自更高性能计算设备上的额外图形处理算力,以增强用户体验。Endgame项目正在开发中,英特尔在今年开始该技术的beta测试。
在今天宣布的消息中,还预览了英特尔的一项新举措,旨在为整个生态系统启用新的服务模式。Intel On Demand服务的推出,可以满足企业不断变化的工作负载需求,实现产品可持续发展,并把握在靠近数据的地方扩展系统的机会。目前,英特尔推出了一种新型消费商业模式,以使客户能将其基础设施与业务需求相匹配,并通过包括如HPE GreenLake、联想TruScale和PhoenixNAP的裸机云在内的精选合作伙伴提供服务。
200亿亿次超级计算机Aurora
在今天的开幕主题演讲中,英特尔联合阿贡国家实验室的计算、环境和生命科学实验室主任Rick Stevens,首次展示了支持超过200亿亿次计算(E级)的极光(Aurora)超级计算机的安装情况,并深入解析它将如何助力解决人类面临的疑难问题,如更准确地预测气候以及发现应对癌症的新疗法,同时让百亿亿次计算(E级)广泛应用于研发和创新活动。


极光(Aurora)超级计算机之所以能够提供每秒超过200亿亿次的双精度峰值计算性能,主要是因为其采用了内置高带宽内存(HBM)的代号为Sapphire Rapids的英特尔至强处理器和代号为Ponte Vecchio的英特尔数据中心显卡。
此外,英特尔oneAPI也为开发者提供无缝的系统集成。

英特尔携手博世打造机密AI解决方案
在一个日益动态变化的监管环境中,全球企业在决定如何使用受监管的数据来有效地训练和开发神经网络时,必须着手处理多种需要考虑的事情。基于此,为了在公有云中训练自有神经网络的过程保持工作负载的机密性,博世携手英特尔在一个研究项目中打造了一个机密AI解决方案。

为进一步大规模应用此方案,博世企业研究部开发了一个机密AI平台级框架。该框架使用了第三代英特尔 至强 可扩展平台上搭载的英特尔 软件防护扩展技术。
利用专用无线网络实现农业自动化
智能边缘解决方案能够帮助农民提高农作物产量及运营效率,同时解决由劳动力短缺和人为失误带来的问题,从而有望改变农作物的种植方式。此外,基于数据分析获得的洞察不仅能够帮助农民提高农作物产量,还可以让农作物更加健康地生长,同时减少资源消耗。
Blue White Robotics(以色列农业机器人公司)开发了一款新型自动化农业解决方案,能够将种植者的现有设备转变为与互联网管理平台连接的自动化拖拉机车队。

在英特尔和Federated Wireless的帮助下,Blue White Robotics 将其打造为一款基于英特尔®智能边缘和英特尔®至强® D处理器的可扩展解决方案。通过边缘计算和共享频谱功能,该解决方案能够在任意农场中创建专用无线网络。
无接触零售体验
新冠肺炎疫情改变了人们的购物方式,许多人更青睐那些非接触式或自助结账的商店。Nourish + Bloom Market正在着手设计一种无接触购物体验,在不取代工作岗位的情况下实现购物自动化。

为了实现这一目标,Nourish + Bloom Market与英特尔和领先的转型解决方案公司UST合作,利用共同的技术知识进行创新,例如正在设计采用计算机视觉技术的下一代自助结账系统,以实现充分自主的商店购物。
人才培养与净零排放
英特尔与整个生态系统合作,为子孙后代推动积极的全球变化,例如进一步减少直接和间接的温室气体排放,通过英特尔AI嘉年华这样的计划以及与隐藏天才项目和Autodesk的合作,来确保未来人才拥有光明的未来和新一代技能。

在绿色发展方面,近日,英特尔承诺到 2040 年实现全球业务的温室气体净零排放,并制订具体目标,以提升英特尔产品和平台的能源效率并降低碳足迹,同时与客户和行业伙伴合作,制订各项解决方案,以降低整个技术生态系统的温室气体足迹。
气候变化的影响是一项迫在眉睫的全球威胁。要保护地球,就需要我们立即采取行动,并重新思考世界的运作方式。作为全球领先的半导体设计和制造公司,英特尔处于一个独特的位置,不仅在我们自己的运营中发挥作用,也在发挥影响力使客户、合作伙伴和整个价值链更容易采取有意义的行动。
编辑:芯智讯-浪客剑
突发!复工仅20天,特斯拉上海工厂再度停产!或因线束供应中断所致
安谋中国“内斗”接近尾声:新任CEO已入主深圳办公室,并夺回IT系统控制权!
德州仪器裁撤中国区MCU研发团队,原产品线研发迁往印度!背后原因揭秘
政府机构及国企将全面采用国产PC,两年内完成!数量或达5000万台
2021年全球十大功率半导体厂商:英飞凌稳居第一,安世升至第八
突发!传美国将升级对海康威视制裁!官方回应:希望获得公平公正的对待
行业交流、合作请加微信:icsmart01
芯智讯官方交流群:221807116