
专攻芯片设计,英伟达推出定制版大语言模型ChipNeMo!

新智元报道
新智元报道
【新智元导读】英伟达:大语言模型或将全面加持芯片设计全流程!
在刚刚开幕的ICCAD 2023大会上,英伟达团队展示了用AI模型测试芯片,引发了业界关注。
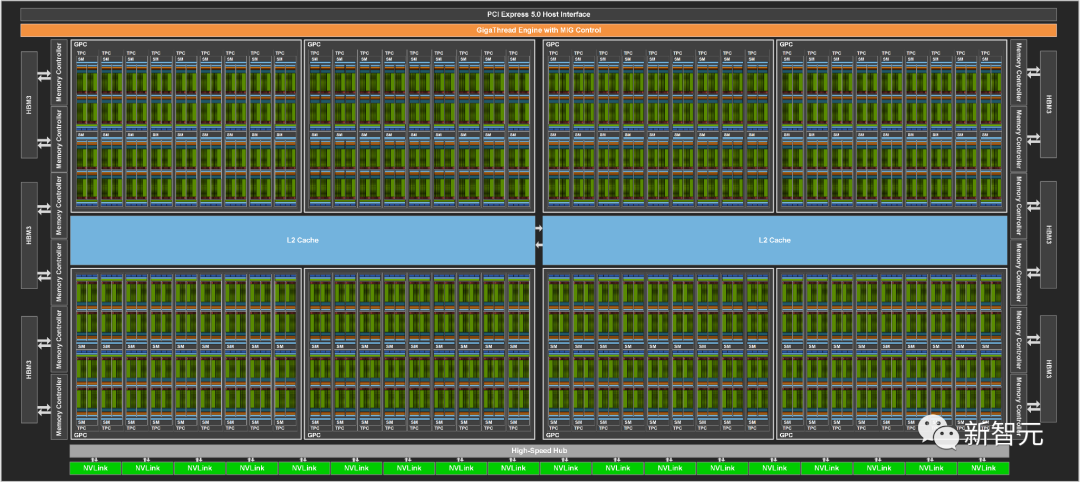
ChipNeMo:英伟达版「芯片设计」大模型

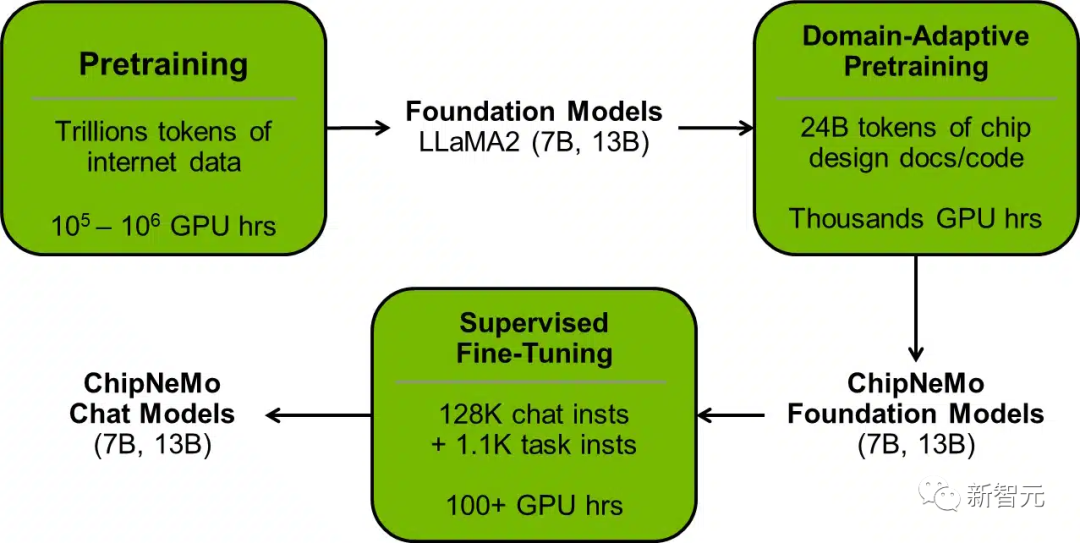


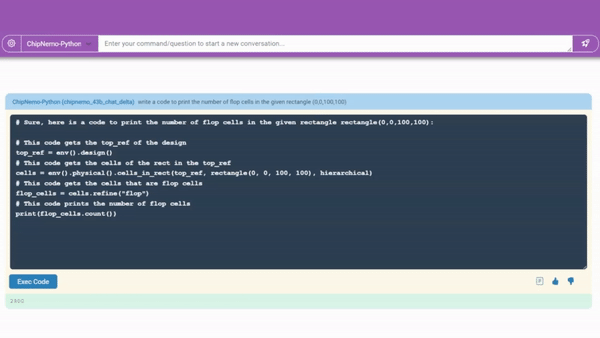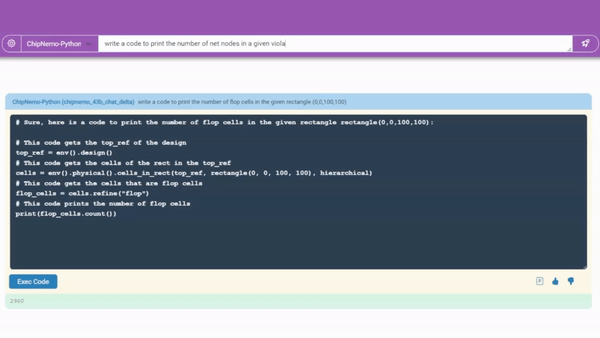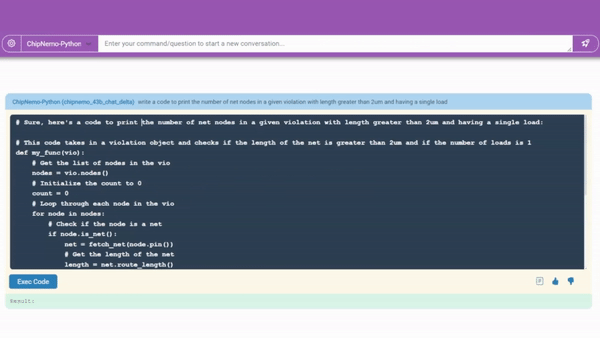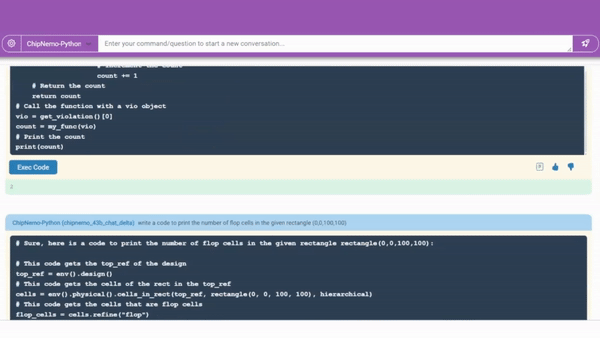


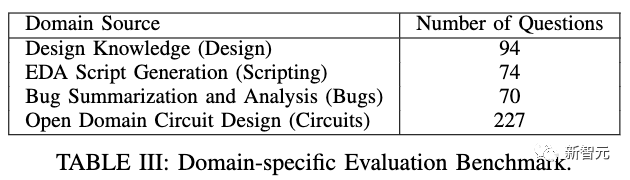
数据
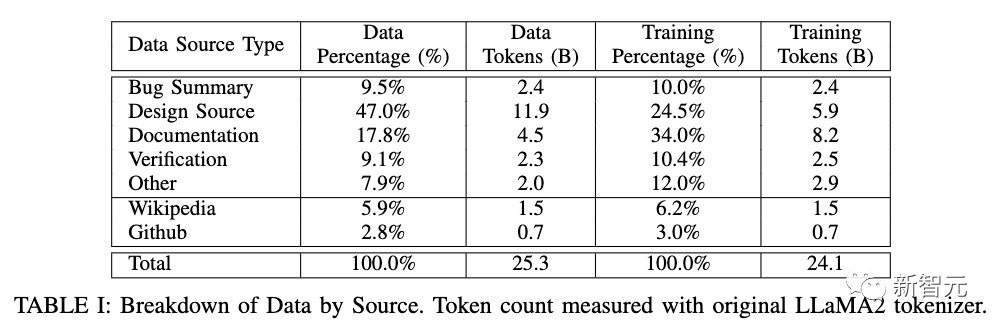
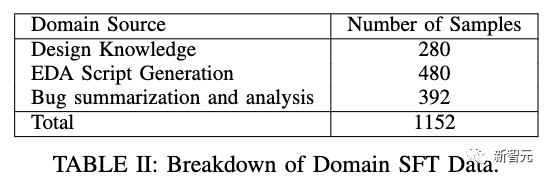
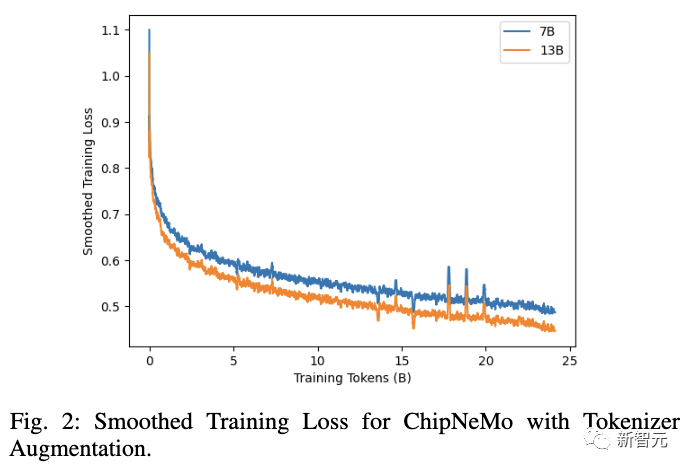
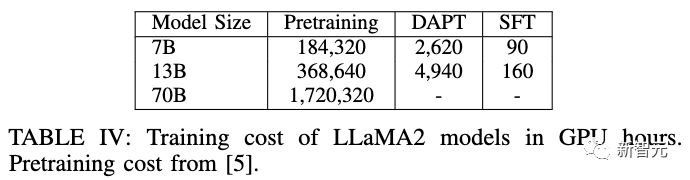
训练
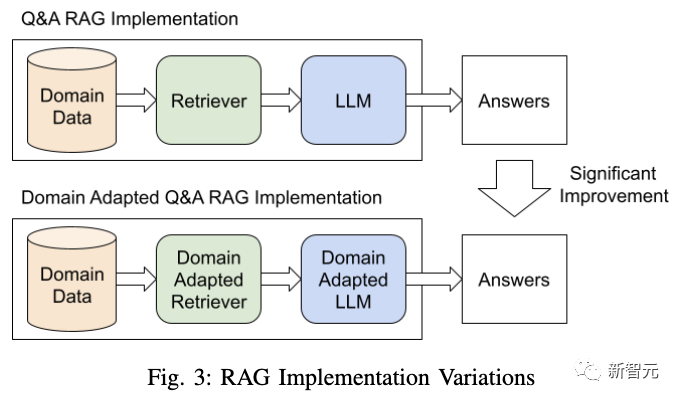
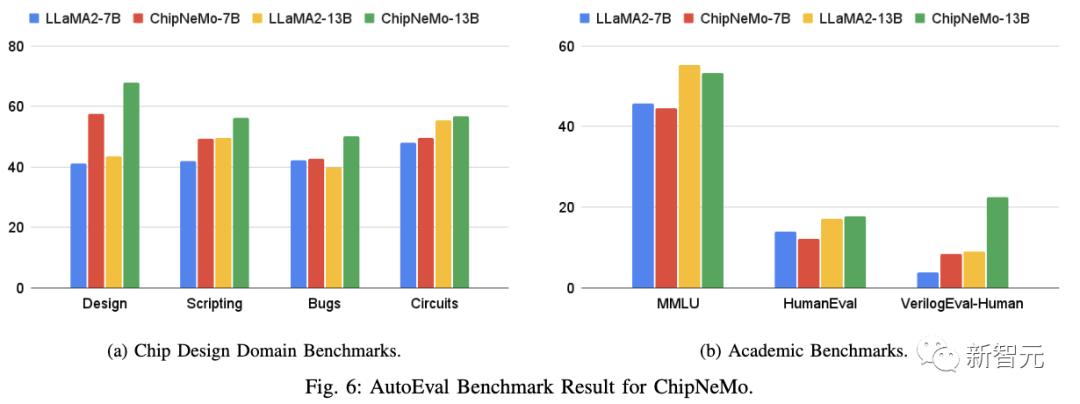
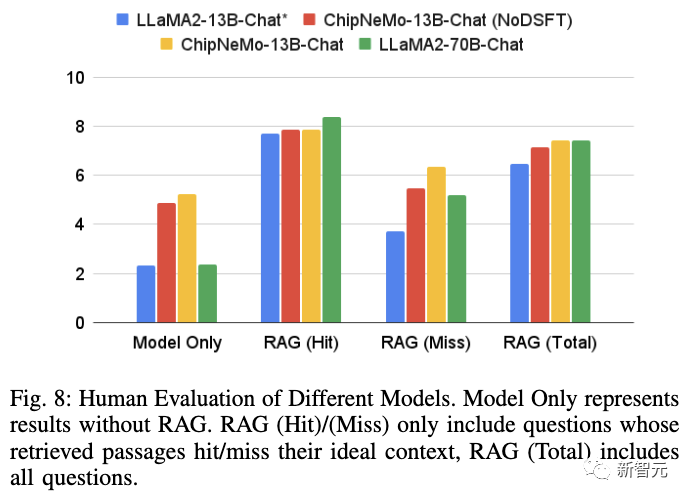
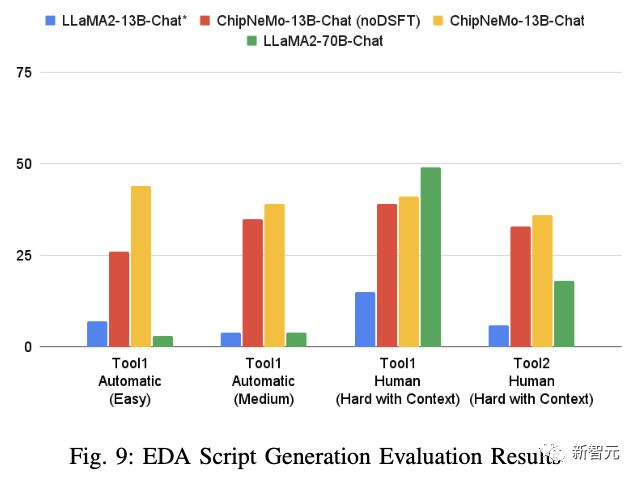
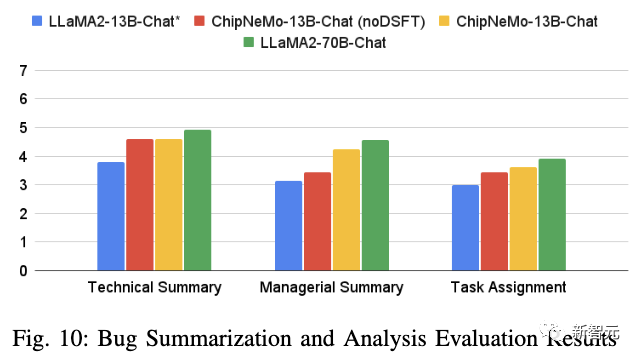
结果
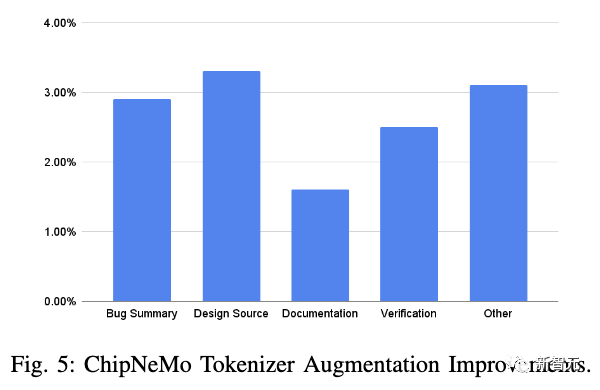
讨论



评论