
NNI — 微软开源的一个自动帮你做机器学习调参的神器

NNI 自动机器学习调参,是微软开源的又一个神器,它能帮助你找到最好的神经网络架构或超参数,支持各种训练环境。
它常用的使用场景如下:
想要在自己的代码、模型中试验不同的机器学习算法。
想要在不同的环境中加速运行机器学习。
想要更容易实现或试验新的机器学习算法的研究员或数据科学家,包括:超参调优算法,神经网络搜索算法以及模型压缩算法。
它支持的框架有:
PyTorch
Keras
TensorFlow
MXNet
Caffe2
Scikit-learn
XGBoost
LightGBM
基本上市面上所有的深度学习和机器学习的框架它都支持。
下面就来看看怎么使用这个工具。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,可以访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器,它有许多的优点:Python 编程的最好搭档—VSCode 详细指南。
请选择以下任一种方式输入命令安装依赖:
1. Windows 环境 打开 Cmd (开始-运行-CMD)。
2. MacOS 环境 打开 Terminal (command+空格输入Terminal)。
3. 如果你用的是 VSCode编辑器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install nni2.运行示例
让我们运行一个示例来验证是否安装成功,首先克隆项目:
git clone -b v2.6 https://github.com/Microsoft/nni.git如果你无法成功克隆项目,请在Python实用宝典后台回复 nni 下载项目。
运行 MNIST-PYTORCH 示例,Linux/macOS:
nnictl create --config nni/examples/trials/mnist-pytorch/config.ymlWindows:
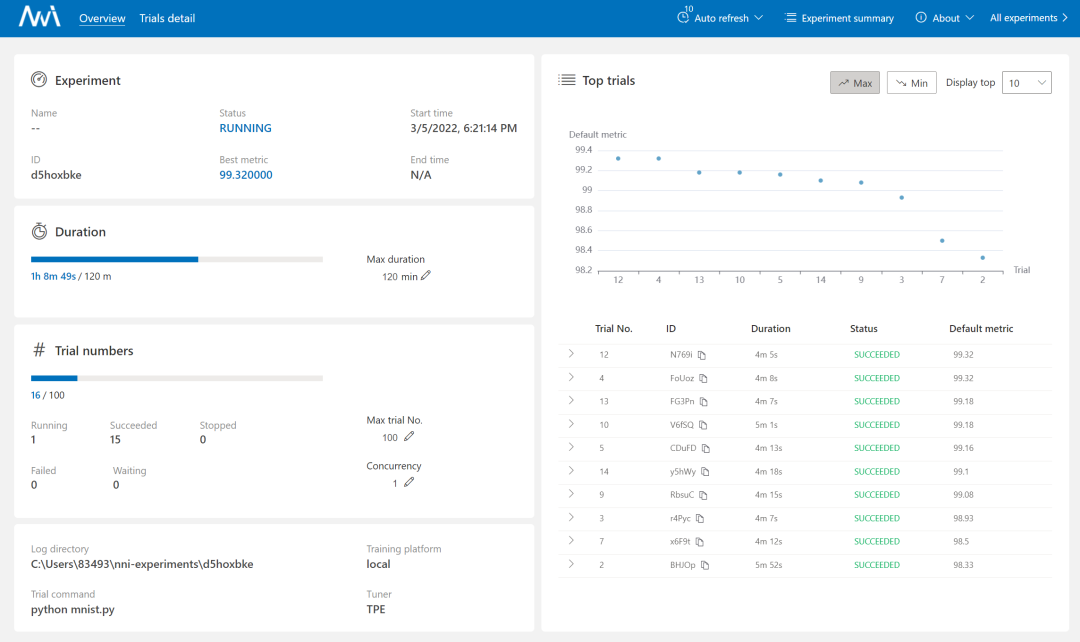
nnictl create --config nni\examples\trials\mnist-pytorch\config_windows.yml出现这样的界面就说明安装成功,示例运行正常:

访问 http://127.0.0.1:8080 可以配置运行时间、实验次数等:
3.模型自动调参配置
那么如何让 NNI 和我们自己的模型适配呢?
观察 config_windows.yaml 会发现:
searchSpaceFile: search_space.json
trialCommand: python mnist.py
trialGpuNumber: 0
trialConcurrency: 1
tuner:
name: TPE
classArgs:
optimize_mode: maximize
trainingService:
platform: local我们先看看 trialCommand, 这很明显是训练使用的命令,训练代码位于 mnist.py,其中有部分代码如下:
def get_params():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument("--data_dir", type=str,
default='./data', help="data directory")
parser.add_argument('--batch_size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument("--batch_num", type=int, default=None)
parser.add_argument("--hidden_size", type=int, default=512, metavar='N',
help='hidden layer size (default: 512)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--no_cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--log_interval', type=int, default=1000, metavar='N',
help='how many batches to wait before logging training status')
args, _ = parser.parse_known_args()
return args如上所示,这个模型里提供了 10 个参数选择。也就是说 NNI 可以帮我们自动测试这10个参数。
那么这些参数在哪里设定?答案是在 searchSpaceFile 中,对应的值也就是 search_space.json:
{
"batch_size": {"_type":"choice", "_value": [16, 32, 64, 128]},
"hidden_size":{"_type":"choice","_value":[128, 256, 512, 1024]},
"lr":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]},
"momentum":{"_type":"uniform","_value":[0, 1]}
}这里有4个选项,NNI 是怎么组合这些参数的呢?这是 tuner 参数干的事,为了让机器学习和深度学习模型适应不同的任务和问题,我们需要进行超参数调优,而自动化调优依赖于优秀的调优算法。NNI 内置了先进的调优算法,并且提供了易于使用的 API。
在 NNI 中,Tuner 向 trial 发送超参数,接收运行结果从而评估这组超参的性能,然后将下一组超参发送给新的 trial。
下表简要介绍了 NNI 内置的调优算法。
| Tuner | 算法简介 |
|---|---|
| TPE | Tree-structured Parzen Estimator (TPE) 是一种基于序列模型的优化方法。SMBO方法根据历史数据来顺序地构造模型,从而预估超参性能,并基于此模型来选择新的超参。 |
| Random Search (随机搜索) | 随机搜索在超算优化中表现出了令人意外的性能。如果没有对超参分布的先验知识,我们推荐使用随机搜索作为基线方法。 |
| Anneal (退火) | 朴素退火算法首先基于先验进行采样,然后逐渐逼近实际性能较好的采样点。该算法是随即搜索的变体,利用了反应曲面的平滑性。该实现中退火率不是自适应的。 |
| Naive Evolution(朴素进化) | 朴素进化算法来自于 Large-Scale Evolution of Image Classifiers。它基于搜索空间随机生成一个种群,在每一代中选择较好的结果,并对其下一代进行变异。朴素进化算法需要很多 Trial 才能取得最优效果,但它也非常简单,易于扩展。 |
| SMAC | SMAC 是基于序列模型的优化方法 (SMBO)。它利用使用过的最突出的模型(高斯随机过程模型),并将随机森林引入到SMBO中,来处理分类参数。NNI 的 SMAC tuner 封装了 GitHub 上的 SMAC3。参考论文注意:SMAC 算法需要使用 pip install nni[SMAC] 安装依赖,暂不支持 Windows 操作系统。 |
| Batch(批处理) | 批处理允许用户直接提供若干组配置,为每种配置运行一个 trial。 |
| Grid Search(网格遍历) | 网格遍历会穷举搜索空间中的所有超参组合。 |
| Hyperband | Hyperband 试图用有限的资源探索尽可能多的超参组合。该算法的思路是,首先生成大量超参配置,将每组超参运行较短的一段时间,随后抛弃其中效果较差的一半,让较好的超参继续运行,如此重复多轮。参考论文 |
| Metis | 大多数调参工具仅仅预测最优配置,而 Metis 的优势在于它有两个输出:(a) 最优配置的当前预测结果, 以及 (b) 下一次 trial 的建议。大多数工具假设训练集没有噪声数据,但 Metis 会知道是否需要对某个超参重新采样。参考论文 |
| BOHB | BOHB 是 Hyperband 算法的后续工作。Hyperband 在生成新的配置时,没有利用已有的 trial 结果,而本算法利用了 trial 结果。BOHB 中,HB 表示 Hyperband,BO 表示贝叶斯优化(Byesian Optimization)。BOHB 会建立多个 TPE 模型,从而利用已完成的 Trial 生成新的配置。参考论文 |
| GP (高斯过程) | GP Tuner 是基于序列模型的优化方法 (SMBO),使用高斯过程进行 surrogate。参考论文 |
| PBT | PBT Tuner 是一种简单的异步优化算法,在固定的计算资源下,它能有效的联合优化一组模型及其超参来最优化性能。参考论文 |
| DNGO | DNGO 是基于序列模型的优化方法 (SMBO),该算法使用神经网络(而不是高斯过程)去建模贝叶斯优化中所需要的函数分布。 |
可以看到本示例中,选择的是TPE tuner.
其他的参数比如 trialGpuNumber,指的是使用的gpu数量,trialConcurrency 指的是并发数。trainingService 中 platform 为 local,指的是本地训练。
当然,还有许多参数可以选,比如:
trialConcurrency: 2 # 同时运行 2 个 trial
maxTrialNumber: 10 # 最多生成 10 个 trial
maxExperimentDuration: 1h # 1 小时后停止生成 trial不过这些参数在调优开始时的web页面上是可以进行调整的。
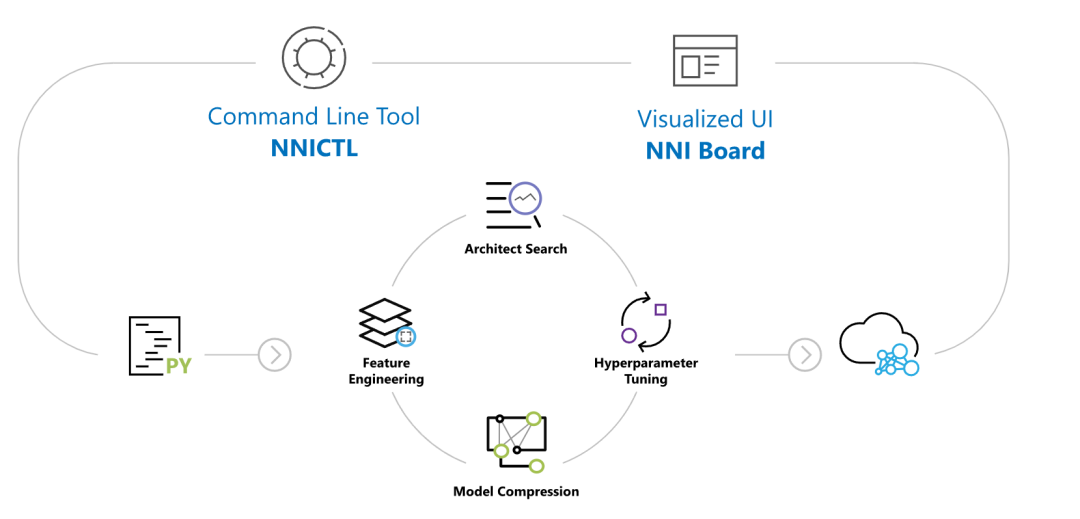
所以其实NNI干的事情就很清楚了,也很简单。你只需要在你的模型训练文件中增加你想要调优的参数作为输入,就能使用NNI内置的调优算法对不同的参数进行调优,而且允许从页面UI上观察调优的整个过程,相对而言还是很方便的。
不过,NNI可能不太适用一些数据量极大或模型比较复杂的情况。比如基于DDP开发的模型,在NNI中可能无法实现大型的分布式计算。
当然,绝大多数情况下的训练任务,NNI都可以用得上。大家有兴趣深入使用的可以阅读NNI官方文档:
https://nni.readthedocs.io/

